




设计良好的数据体系结构的主要目标是减少数据孤岛,最大限度地减少数据重复,并提高数据管理过程的整体效率。随着数据格局在过去几十年的演变,数据体系结构也在不断发展。让我们更详细地了解这种演变。
在新的消费模型的驱动下,分析数据经历了进化的过程,从支持商业决策的传统分析到增强ML的智能产品。
2、转换为以多维和时变表格格式表示的通用模式。
这种体系结构中,数据集市也开始发挥作用。它们是数据仓库之上的一个附加层(由一个或多个表组成),以特定的模式格式为特定的部门业务问题提供服务。如果没有数据集市,这些部门将不得不在仓库中探索和创建多个查询,以获得具有所需内容和格式的数据。
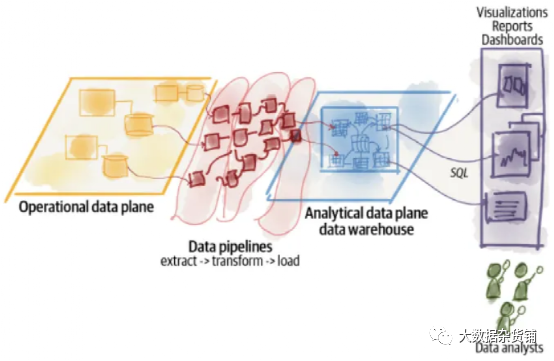
图2-数据仓库体系结构|来源:数据网格书
随着时间的推移,构建了数千个ETL作业、表和报告,只有专业团队才能理解和维护它们。
代工程实践如CI/CD不适用。
数据仓库的数据模型和模式设计过于僵化,无法处理来自多个来源的大量结构化和非结构化数据。
这将引导我们进入下一代数据体系结构。
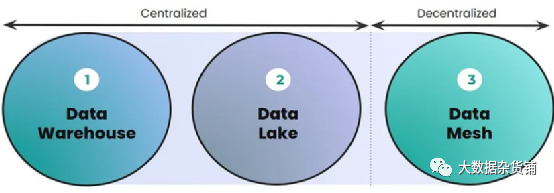
第二代:数据湖架构
这种数据体系结构旨在改善数据仓库所需的大量前期建模的无效性和摩擦性。前置转换是一个障碍,会导致数据访问和模型训练的迭代速度减慢。
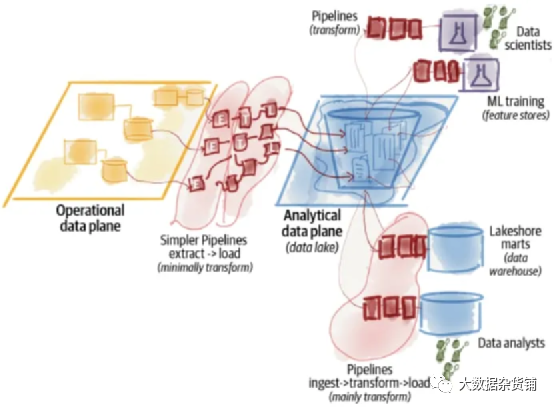
数据湖架构存在复杂性和退化,导致数据质量和可靠性较差。 批处理或流式作业的复杂管道需要由超专业数据工程师组成的中心团队操作。 创建了非托管数据集,这些数据集通常不受信任且不可访问,几乎没有价值。 数据沿袭和依赖关系很难跟踪。 没有广泛的前期数据建模会给在不同数据源之间建立语义映射带来困难,从而产生数据沼泽。
使用Kappa等架构支持流式传输,以实现近乎实时的数据可用性。 尝试将数据转换的批处理和流处理与Apache Beam等框架统一起来。 完全接受基于云的托管服务,并使用具有独立计算和存储的现代云原生实现。存储数据变得更加便宜。
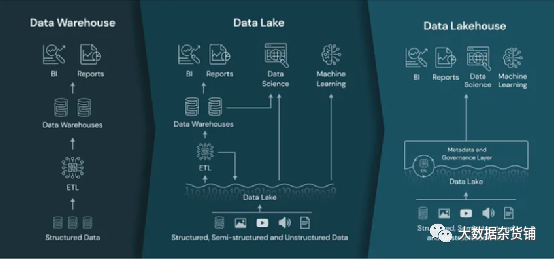
将仓库和lake融合为一种技术,要么扩展数据仓库以包括嵌入式ML训练,要么将数据仓库的完整性、事务性和查询系统构建到数据lake解决方案中。Databricks Lakehouse是一个具有类似仓库的事务和查询支持的传统湖泊存储解决方案的示例。
数据湖架构的管理仍然非常复杂,影响了数据质量和可靠性。 架构设计仍然是集中的,需要一支超专业的数据工程师团队。 需要很长时间才能获得真知灼见。数据消费者继续等待数月才能获得用于分析或机器学习用例的数据集。 数据仓库不再是通过数据复制真实世界,在探索数据的同时影响数据消费者的体验。
所有这些挑战使我们想到了第四代数据体系结构,在本文发表时,该体系结构仍处于早期阶段。
域。域是一个独立的业务单元,拥有并管理自己的数据。每个域都有明确的业务目的,并负责定义数据建模、实体、模式和策略来管理数据。这一概念不同于为营销或销售等不同团队设计的数据仓库架构中的数据集市。在数据网格体系结构中,销售可以有多个领域,这取决于团队可能拥有的不同重点/领域。 数据产品。数据产品是域产生的最终结果,可供其他域或应用程序使用。每个数据产品都有明确的商业目的。一个域可以处理多个数据产品。并非所有数据资产都将被视为数据产品或应接受数据产品处理(尽管在完美的世界中是这样)。数据产品是在组织中发挥关键作用的数据资产。 数据基础设施。数据基础设施包括管理域内数据所需的工具和技术,类似于软件应用程序的容器化微服务。这包括数据存储、处理和分析工具。 数据治理。数据治理由每个域管理。这是指管理数据质量、隐私和安全的一套程序。 网格API。就像微服务通过HTTP REST API公开所有内容一样,数据网格域将通过定义良好的接口公开所有内容,其他域和数据产品可以使用该接口。
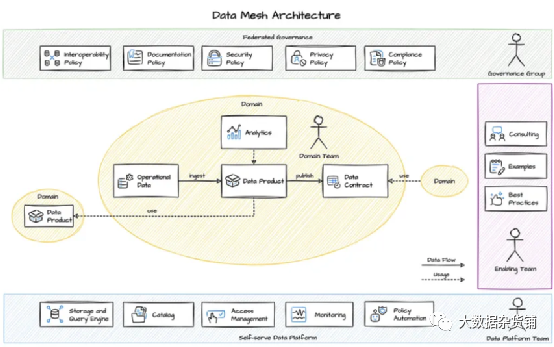
数据团队成为跨职能团队,专门从事一个或多个业务领域(而非技术),就像软件产品团队需要适应服务一样。 每个由一个或多个微服务组成的业务领域都有自己的OLAP数据库和分布式文件存储系统,就像微服务的任何部分都被容器化以独立工作一样。 数据产品A将被数据产品B消费,两者都将通过流或REST API与其他数据产品通信,就像应用程序微服务相互通信一样。 数据产品API之后将是传统的REST API文档,并且可以通过网格数据目录发现数据产品。
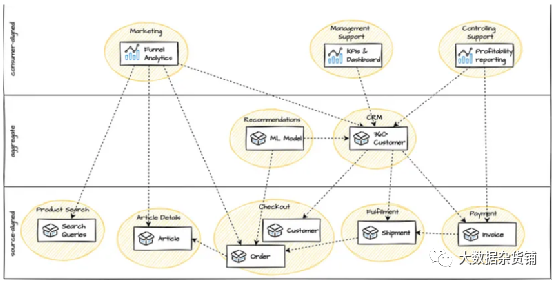
原文作者:Diogo Silva Santos
文章转载自大数据杂货铺,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
