




💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
💡本章重点
- 文生语音之ChatTTS的使用
🍞一. 概述
ChaTTS是一个功能强大的文本转语音系统,该模型使用了大量的的文本和语音数据进行相关模型的训练。目前该模型已经开源了训练之后的模型权重文件,以供程序员使用。本文将从TTS(Text-To-Speech)模型的角度讲解文生语音模型的原理,并以ChatTTS为例阐述部署模型和参数微调。
🍞二. 模型介绍
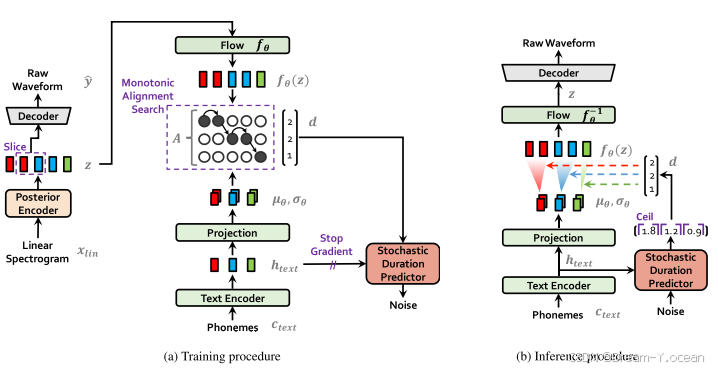
VITS由于采用对抗训练的模式,模型主要包括生成器和判别器两大块,判别器仅在训练时使用。具体实现上,生成器net_g由SynthesizerTrn实现,包括先验编码器、随机时长预测器、解码器和后验编码器;判别器net_d则由MultiPeriodDiscriminator实现,即HiFiGAN中的多周期判别器。
训练流程:
在训练阶段,音素可以被简单理解为文字对应的拼音或音标。它们经过文本编码(Text Encode)和映射后,生成了文本的表示形式。左侧的线性谱(Linear Sepctrogram)是从用于训练的音频中提取的 wav 文件的音频特征。这些特征通过后验编码器(Posteritor)生成音频的表示,然后通过训练对齐这两者。节奏也是表达的重要因素,因此还加入了一个随机持续时间预测器模块,根据音素和对齐结果对输出音频长度进行调整。具体的模块和步骤如下:
- 输入处理:
-
后验编码器: 输入为目标语音的线性谱图 (xlin)。
-
先验编码器: 输入为文本提取的音素序列 (ctext) 和通过单调对齐搜索 (MAS) 估计的音素与潜在变量之间的对齐矩阵 (A)。
-
持续时间预测器: 输入为文本提取的音素序列 (ctext)。
- 潜在变量编码:
-
后验编码器: 将输入的线性谱图 (xlin) 编码成潜在变量 z。
-
先验编码器: 将输入的音素序列 (ctext) 和对齐矩阵 (A) 编码成潜在变量 z 的先验分布参数。
- 解码器:
将潜在变量 z 解码成语音波形 (y)。
- 重建损失:
计算解码器输出语音波形 (y) 与目标语音波形之间的 L1 范数损失。
- KL 散度:
计算后验编码器输出潜在变量 z 的分布与先验编码器输出潜在变量 z 的先验分布之间的 KL 散度。计算公式如下:
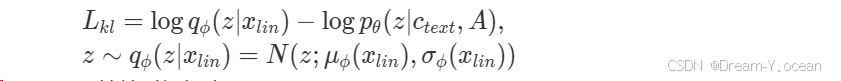
- 持续时间损失:
计算持续时间预测器输出音素持续时间分布与目标音素持续时间分布之间的变分下界。
- 对抗训练:
-
训练判别器 D 区分解码器输出语音波形 (y) 和目标语音波形。
-
训练解码器 G 生成更难以被判别器 D 区分的语音波形。
- 损失函数:
- 将重建损失、KL 散度、持续时间损失、对抗训练损失和特征匹配损失组合成总损失函数。
- 优化:
- 使用 AdamW 优化器更新模型参数。
🍞三.推理流程:
- 输入处理:
- 先验编码器: 输入为文本提取的音素序列 (ctext)。
- 潜在变量编码:
- 先验编码器: 将输入的音素序列 (ctext) 编码成潜在变量 z 的先验分布参数。
- 潜在变量采样:
- 从先验分布中采样潜在变量 z。
- 解码器:
- 将潜在变量 z 解码成语音波形 (y)。
- 持续时间预测:
- 使用持续时间预测器预测音素持续时间,并用于调整语音波形。
🍞四.部署方式
常规使用
import ChatTTS
import torch
import torchaudio
chat = ChatTTS.Chat()
chat.load(source='custom',custom_path='./path_to_config_path.yaml',device='cuda') # Set to True for better performance
texts = ["你好,我真的真的好喜欢你!"]
wavs = chat.infer(texts)
for i in range(len(wavs)):
torchaudio.save(f"basic_output{i}.wav", torch.from_numpy(wavs[i]).unsqueeze(0), 24000)
高级用法
import ChatTTS
import torch
import torchaudio
chat = ChatTTS.Chat()
chat.load(source='custom',custom_path='./path_to_config_path.yaml',device='cuda') # Set to True for better performance
texts = ["你好,我真的真的好喜欢你!"]
# 这部分代码从高斯分布中随机选取一个说话人特征(通常是一个嵌入向量)
torch.manual_seed(audio_seed_input=2) # 设置Audio Seed
rand_spk = chat.sample_random_speaker()
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb = rand_spk, # add sampled speaker
temperature = .3, # using custom temperature
top_P = 0.7, # top P decode
top_K = 20, # top K decode
)
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt='[oral_2][laugh_0][break_6]',
)
wavs = chat.infer(
texts,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code,
)
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wavs = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]).unsqueeze(0), 24000)
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】
