




【
最近工作比较繁忙,几乎天天忙到半夜,公众号关于技术观点的内容也就少了,所以要给因此关注的朋友们道个歉。打工人就是一个螺丝钉,有时候连表达自己的观点的机会都很难得,所以非常感谢诸位朋友不离不弃的陪伴与期望。
今天又是一个不眠夜,只能分享一个以前的学习笔记,一个关于sysbench测试,以及性能问题分析的过程,用的是人大金仓的Kingbase v9,以及性能报告分析工具KWR和KDDM。虽然结果非常戏剧性,但是过程还是挺有意思的....这些工具也值得国产厂商学习/普及。
】
初始化1000万数据,【select_random_points】测试TPS都能上万,然而在【OLTP_INSERT】插入100万数据后,再执行TPS仅达到20。这是什么诡异的现象?
---
【select_random_points】,in 条件查询,随机10个值。

【OLTP_INSERT】 单行事务写入;

以下用KingBase为例进行分析。
sysbench 版本:sysbench 1.1.0 (using bundled LuaJIT 2.1.0-beta3)
愚蠢的分析过程
1,排除数据总量的影响,因为初始化2000万数据以后,直接【select_random_points】测试TPS也能上万。
2,排除执行计划变更,性能降低前后执行explain analyze SQL;执行计划不变,但执行时间明显发生变化;
3,然后,还去查阅了pg的一些存储page、buffer、tuple等等一系列数据结构;以及查询、写入的执行流程。
搞了两天,最终尝试验证都没有效果。于是在金仓社区和墨天轮都进行了问题描述,躺平、不干了!
柳暗花明,分析工具给出问题思路...
本来想放弃了,然后金仓社区有个朋友回复说金仓有KWR,类似ORACLE的awr报告,可以进行分析。
看了一下金仓的文档,除了kwr,还有ksh工具,了解ORACLE的应该知道这是一个什么工具。
另外还有一个kddm,直接提供问题分析结果和优化建议,于是跑了一下kddm,结果如下:
有些信息已经验证过没啥用,但有一条吸引了我的注意(直接看手动标黄的内容就可以)
sysbench=# SELECT * FROM perf.kddm_report(9,10);
kddm_report
------------------------------------------------------------------------------------
[建议列表]: +
+
数据库时间分解 +
CPU 相关建议 +
TOP SQL 建议 +
优化堆页面裁剪建议 +
等待相关建议 +
TOP 等待事件建议 +
IO 类等待事件 +
存储 IO 分解 +
Client 类等待事件 +
优化网络传输建议 +
完整 SQL 列表 +
+
+
[数据库时间分解]: +
+
Event DB Time Percent QueryID +
-------------------------------------------------------------------------------- +
OnCpu 99.98 % +
Cpu 99.98 % 100 % +
SELECT id, k, c, pad FROM sbtest1 W 98.09 % 98.19 % -1543846772187005012 +
SELECT * FROM perf.create_snapshot( 1.81 % 1.81 % 2821478114692794725 +
+
+
[TOP SQL 建议]: +
+
queryid | dbtime | parse | plan | execute +
-------------------------------------------------------------------------------- +
-1543846772187005012 | 98.09% | 0.00% | 0.01% | 97.87% +
+
SQL 语句: +
--------- +
-1543846772187005012 SELECT id, k, c, pad FROM sbtest1 WHERE k IN ($1, $2, $3, $4+
+
+
建议动作: +
--------- +
使用 SQL 优化建议,发现可能的优化建议: +
1) select perf.sql_tuning_advisor(queryid) 或者: +
2) select pg_catalog.sql_tuning_advisor(query) +
+
+
+
[优化堆页面裁剪建议]: +
+
建议依据: +
--------- +
可以通过减少堆页面剪枝操作的频率,来减少每次剪枝页面的 CPU 开销。该建议尤其 +
适合 TPCC 测试这种短语句场景。 +
+
建议动作: +
--------- +
优化 page_prune_frequency 参数,当前值:1,建议值:16; +
+
参考信息: +
--------- +
配置参数: +
page_prune_frequency: 1 +
+
+
+
[存储 IO 分解]: +
+
IO 速度和占比: +
实例 IO: 0.03 MB/s, 100.00 % +
共享块: 0.01 MB/s, 29.58 % +
本地块: 0.00 MB/s, 6.34 % +
临时块: 0.00 MB/s, 0.00 % +
W A L: 0.02 MB/s, 64.08 % +
+
IO 时间分解: +
IO Wait Event Total % FG DB % +
-------------------------------------------------------------------------------- +
StatFile 80.00 % 0.00 % +
StatFile 80.00 % 0.00 % +
StatFileRead 40.00 % 0.00 % +
StatFileWrite 40.00 % 0.0 % +
LockFile 20.00 % 0.0 % +
LockFile 20.00 % 0.0 % +
LockFileReCheckDataDirRead 20.00 % 0.0 % +
+
+
[优化网络传输建议]: +
+
建议依据: +
-------- +
客户端接收数据量较多。 +
+
建议动作: +
--------- +
1、配置 JDBC defaultRowFetchSize +
2、用户手动分页 +
3、使用Unix domain +
4、升级网络设备 +
+
参考信息: +
--------- +
前台 Clientwrite 时间占比:0% +
+
网卡利用率: +
+
Interface Link Speed Mbps Utility % +
---------------------------------------------------------------------- +
enp3s0 10000 2.72 +
+
+
关联 Sql: +
+
Query Id Query Sql Rows/Exec Rows % +
-------------------------------------------------------------------------------- +
-1543846772187005012 SELECT id, k, c, pad FROM sbtest1 15349 100.00 +
+
+
[完整 SQL 列表]: +
+
Query Id:2821478114692794725 +
SELECT * FROM perf.create_snapshot() +
+
Query Id:-1543846772187005012 +
SELECT id, k, c, pad FROM sbtest1 WHERE k IN ($1, $2, $3, $4, $5, $6, $7, $8, +
$9, $10) +
+
+
+
(1 行记录)
sysbench=#
然后又对比了一下两次测试(性能好和性能差)的kwr报告:
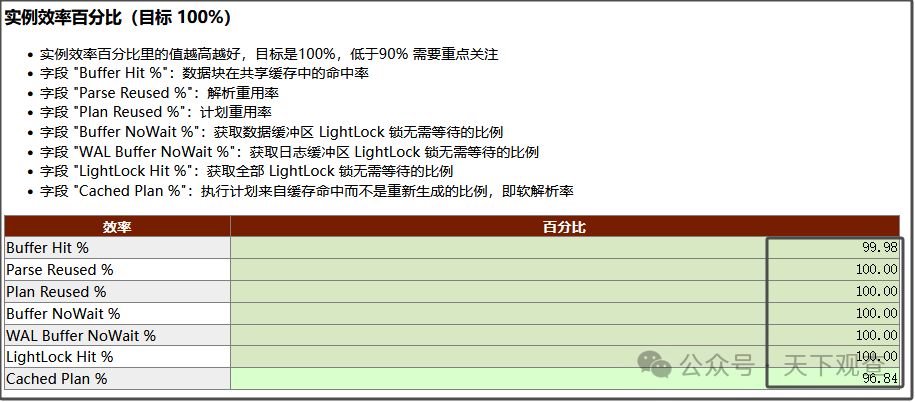
1,解析、计划、缓存重用率、命中率都几乎是100%,更确定不是执行计划的问题。
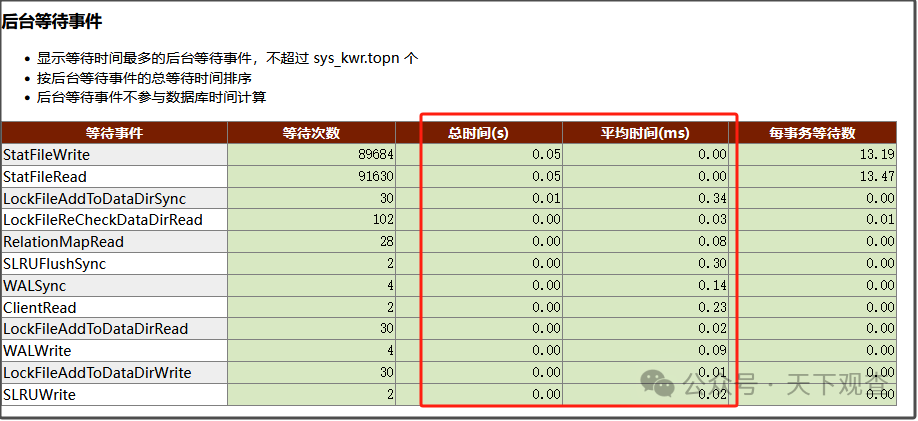
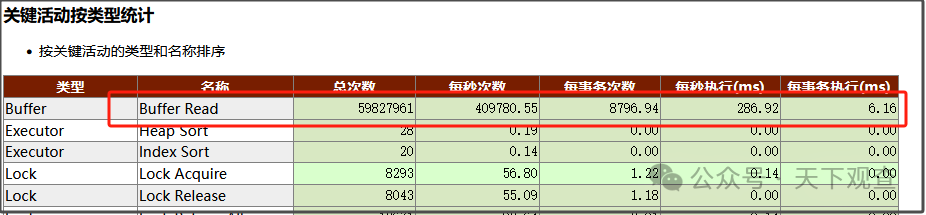
3,关键活动按类型统计,问题已经给出答案,就是buffer read占用了主要时间。
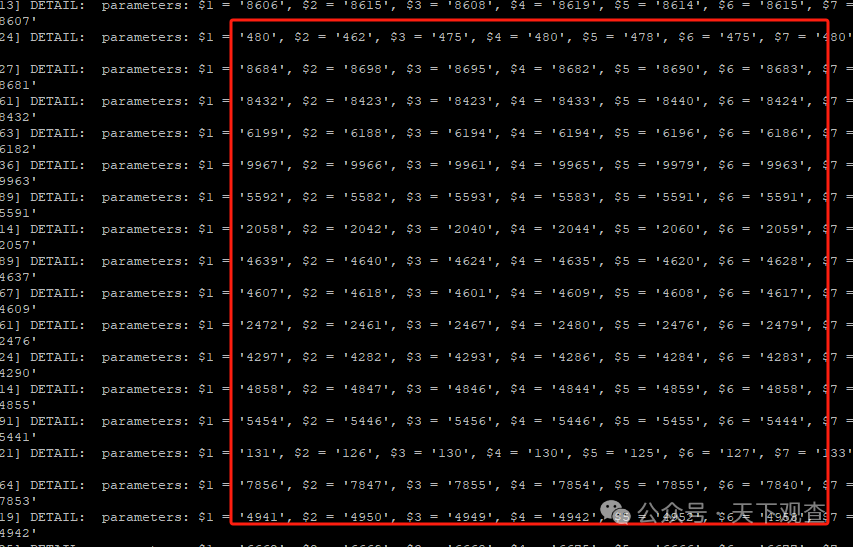
然后对比发现,跑的慢的,每次执行(查询)返回元组数(行)9561。

跑的快的时候(查询)仅返回10个元组(行),这就是问题差距了

通过Kwr和kddm分析结果看,
就是查询的数据集发生了骤增,导致TPS明显下降
WHY...
然后按照这个思路验证了一下,为什么执行【oltp_insert】之后,数据仅仅增长10%,in查询的结果集就多出了900倍!
从结果看,难道是sysbench的bug?不至于,出了问题首先要从自身找原因。
情况是这样的:
1,测试表中有一列为“k”,数值类型,如果是prepare初始化生成数据,假设指定生成1000万数据,那么这个k的值范围就是1-1000万,中间会有部分重复值,去重之后大概有600万数据;
这时候执行 k in($1,$2....)基本就返回10多行数据。
2,【oltp_insert】插入的数据,无论设置多少并发,新插入的k值的范围始终为1-10000,如果插入200万数据,那么K值就是这个范围(1-10000)重复了200多遍。
看着这一结果,想必了解sysbench工具的人已经知道原因了,轻点喷,确实犯了一个愚蠢的错误…
######清空表中数据
sysbench=# truncate table sbtest1;
######执行oltp_insert插入大约200万数据
######sysbench --config-file=config ./lua/oltp_insert.lua --tables=1 --threads=100 run
######查询数据
sysbench=# select max(k) v_max,min(k) v_min,count(*) v_count,max(cnt) c_max, min(cnt)c_min ,avg(cnt)c_avg from
(select k ,count(*) cnt from sbtest1 group by 1) t ;
v_max | v_min | v_count | c_max | c_min | c_avg
-------+-------+---------+-------+-------+----------------------
10000 | 1 | 10000 | 263 | 156 | 206.6248000000000000
(1 行记录)
###发现去重的k值只有1万个,平均每个k值重复了206次....
3【select_random_points】测试的时候,k in (随机10个值),因为这个错误,这10个值也全都是在【1-10000】这个范围,就导致【oltp_insert】插入的数据越多,【select_random_points】测试返回的结果集就越大,也就造成了性能以肉眼可见的情况急剧下降。
最后,厂商能够提供一些有效的工具对数据库的运维、优化、排查问题真的是太至关重要的!!
END
招投标 |单一来源!海外MPP逃出信创包围
招投标 |中信1100万采购4000节点大数据
招投标 |长安银行192.7万OB扩容采购公示
招投标 |厉害!银行一次性定向采40套MPP
DB |人大金仓2023年营收3.7亿,净利7523万!

点赞、在看、转发,也非常感谢~
