




本期将分享近期全球知识图谱相关
行业动态、会议资讯、论文推荐
—--| 行业动态 |--—

三星电子近日宣布,已签署协议收购专门从事知识图谱技术的英国创业公司 Oxford Semantic Technologies。该公司由三位牛津大学教授于 2017 年创立,在知识表示和语义推理领域拥有卓越技术能力。
通过此次收购,三星将获得个人知识图谱的核心引擎。这些图谱整合了分散在各种服务和应用程序中的信息和上下文,通过越来越熟悉用户的偏好和使用情况来打造量身定制的用户体验。个人知识图谱技术与三星 Galaxy S24 系列等设备上的 AI 技术相结合,可促进超个性化的用户体验,同时确保敏感个人数据在设备上的安全。它将适用于三星的所有产品,从移动设备扩展到电视和家用电器。

BlackRock和 NVIDIA 的研究人员推出了一种名为 HybridRAG 的新方法。该方法整合了 VectorRAG 和基于知识图谱的 RAG (GraphRAG) 的优势,创建了一个更强大的从财务文档中提取信息的系统。通过结合这两种技术,HybridRAG 旨在提高信息检索的准确性并生成相关响应,从而提高财务分析的整体质量。
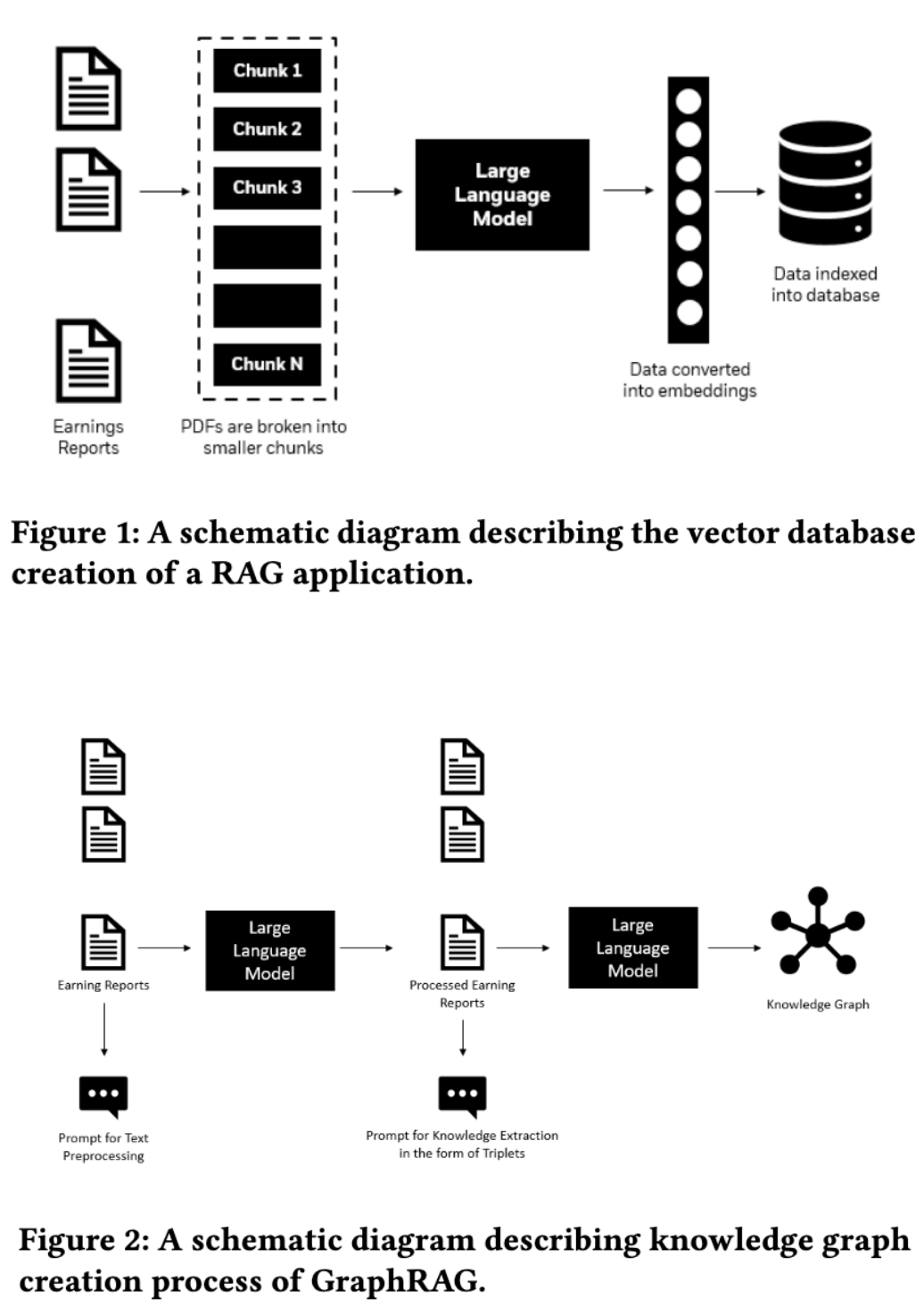
VLDB 2024


在线课程LLM Twin
开源的大语言模型孪生课程:构建面向生产应用的AI副本,该课程系统地介绍了使用LLMOps从数据收集到构建部署大语言模型的技术实践,并通过构建大模型孪生和部署大语言模型与检索增强(RAG )系统提供了端到端的框架。
本周推荐的是发表于SIGMOD 2024上的论文:Machine Unlearning in Learned Databases: An Experimental Analysis,通过实验研究了反学习算法对基于神经网络的数据库模型及其下游和上游任务的影响,作者来自华威大学和谷歌。

基于神经网络的机器学习模型在数据库社区中越来越受到关注,无论是在研究还是实践中。然而,一个重要的问题却被大大忽视了,即处理数据库固有的高度动态特性的问题,其中数据更新是基本且频繁的操作(与机器学习分类任务不同)。尽管一些近期研究已经解决了在新数据插入的情况下保持神经网络模型更新的问题,但数据删除(即“机器反学习”)的影响仍然是一个盲点。
该文中,作者提出并回答了以下关键问题:反学习算法对基于神经网络的数据库模型有什么影响?这些影响如何转化为对关键下游数据库任务(如基数/选择性估计(SE)、近似查询处理(AQP)、数据生成(DG))和上游任务(如数据分类(DC))的影响?应使用哪些指标来评估反学习算法在学习数据库中的影响和效果?数据库中的反学习问题(及其解决方案)与数据插入面临的机器学习问题有何不同?数据库中的反学习问题(及其解决方案)与机器学习文献中的反学习有何不同?反学习算法的开销和效率如何(相对于从头开始重新训练的简单解决方案)?反学习对批量删除操作的敏感性如何(以减少模型更新开销)?如果有一个合适的反学习算法(忘记旧知识),能否将其与处理数据插入(新知识)的算法结合起来,以解决学习数据库在面对数据插入和删除时的一般适应性/可更新性要求?
作者通过一系列综合实验、各种反学习算法、各种下游数据库任务(如SE、AQP和DG)和一个上游任务(DC),使用不同的神经网络,并在各种真实数据集上使用各种指标(模型内部和下游任务特定)回答了这些问题,这也是迈向学习数据库反学习基准的第一步。
该文源代码、数据和其他材料已在https://github.com/meghdadk/DB_unlearning.git上提供,感兴趣的读者可以关注。
更多链接
内容:程湘婷、袁知秋、王图图

诚邀您加入我们的gStore社区,我们将在群内解决使用问题,分享最新成果~
请在微信公众号图谱学苑发送“社区”入群~


微信社区群:请回复“社区”获取

