




一部手机能能分析的数据,是大还是小?
为了体验我DuckDB外聚合的强大,我在Mate60 Pro上用DuckDB做了TPC_H SF 100测试。
那什么是?TPC_H SF 100测试
,
• 数据以CSV保存有100GB
• 8张表模拟了供应链数据库
• 单表最大6亿行
• 涵盖了22个标准SQL查询,有聚会、过滤、多表关联
这算大数据还是小数据?如果说是大数据,为啥一个手机就可以搞定?如果说是小数据,各位,你们经常在工作中见到这样体量的数据吗?
也许你会问,不管工作,还是生活,又有多少人会用手机来做这种体量的数据分析,那么我们看看一台普通笔记本,是如何处理450GB的选票数据的?
一台普通的笔记本能处理、分析450GB数据?
• 作者的运行环境为 WSL,配置如下:
• 16GB DDR4 内存
• 第 12 代英特尔酷睿 i7 处理器
• 1TB NVMe 固态硬盘
• 作者2个半小做了哪些工作:
• 将 50万个 TSV 文件转换为 Parquet 格式
• 过滤和清理数据
• 隔离投票及其属性
• 计算 OLAP 多维数据集的指标
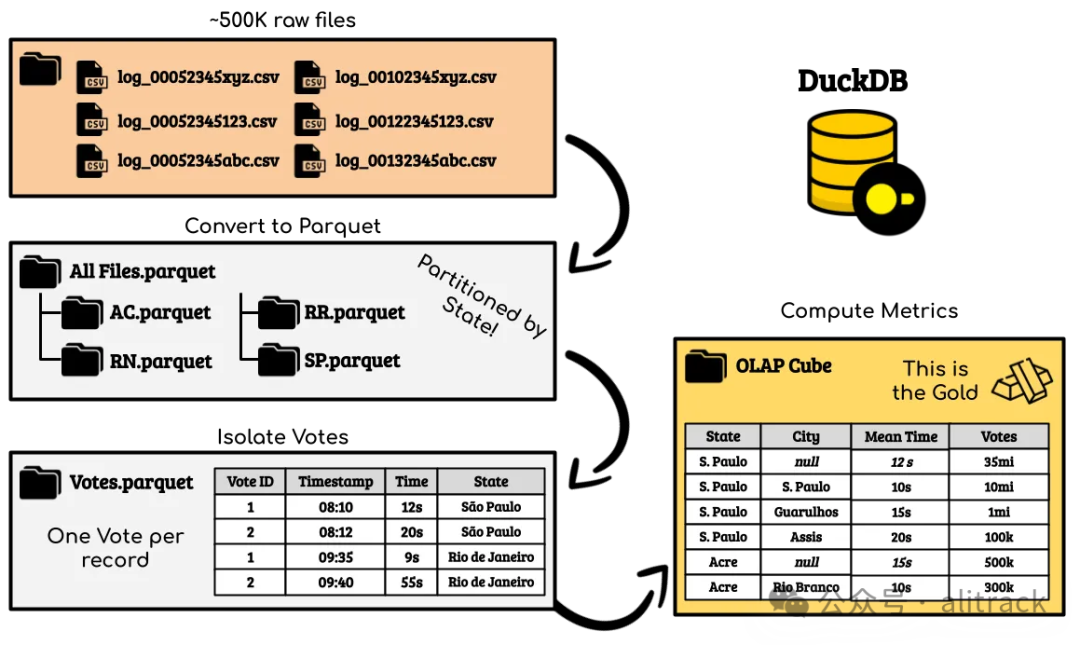
在以前,一台笔记本处理450GB数据,这是不能想象的?那么450GB数据,算大数据,还是小数据?DuckDB让这一切变得模糊了起来。
DuckDB强大如斯,也许你会问,DuckDB到底能处理多大数据集,1TB, 10TB 还是 100TB?看看这里有没有你要找的答案:DuckDB 到底能处理多大的数据?
其实这个问题,随着时间的变化,也许会发生很大的变化,因为在过去三年中,DuckDB 的速度提升了 3-25 倍,未来三年又会发生什么?
我是2019年关注DuckDB的,那时候的DuckDB还很稚嫩,却很强悍,让我看到了单机处理大数据的可能,2020年的时候看到过另外一个宣言, 名字也很有意思:小大数据宣言, 有兴趣的可以看看, 这个宣言最早发布于7年之前。
大数据的定义,由时间、由技术发生变化,年初宣布大数据已死的Jordan Tigani,其创立的MotherDuck公司这次又发起了小数据运动宣言。
是时候 “以小见大” 了
我们相信小数据带来的简单乐趣。
现在你终于可以把大数据掌握在手中。
这是大数据还是小数据?由你来判断。
本地优先的开发方式比你想象中更强大。
现代硬件性能极其强劲。
小模型也能产生巨大的影响。
小数据,智能 AI。
以小见大,本地开发,快乐交付。
更多数据 ≠ 更好的结果。
数据遵循“边际效益递减”规律。
我们使用的大部分数据都是最新的。
最新的数据是最有价值的。
更大的数据意味着机会成本:时间。
处理大数据的机器学习成本高昂,而小模型同样能带来显著影响。
少即是多。
单机高效又强大。
简洁可以扩展,而混乱和复杂却无法扩展。
向上扩展的工作流程非常高效,如今的内存容量是十年前的 400 倍。
我们应该专注于提升用户体验,而不是被复杂的基础设施拖累。
分布式计算应当在真正需要时才使用。
单机 依然强大。
本地开发,就是这么顺手。
本地开发可以立即见效,而结合边缘计算则带来更强的体验。
当不需要时,抛开复杂的分布式架构。
不是所有的开发都必须依赖效率低下的容器或反复回传到云端。
现代硬件和笔记本的性能已经提高了 100 倍,但我们却常常忽视了这些强大的计算能力。
我们提倡在本地开发,并用同样的软件部署到生产环境。
让我们一起,摆脱云计算的“后遗症”,支持本地分析。
小数据和 AI 的价值远超你的想象。
小数据的时代正在到来
Small Data SF 是一个让开发者和数据从业者齐聚一堂的活动,大家一起讨论如何利用“小数据”来构建有用且有意义的分析与 AI 体验。
如今的计算机性能比大数据风潮初期提升了百倍。让我们充分发挥笔记本、云计算和边缘计算的潜力,创造简单而可扩展的分析工作流、应用和机器学习模型。
小数据运动已经开始,你准备好加入了吗?
P.S. TPC-H SF 100
TPC-H (Transaction Processing Performance Council Benchmark H) 是一个广泛使用的基准测试,用于衡量决策支持系统(DSS)的性能。它由多个复杂的SQL查询和更新组成,模拟了实际商业环境中常见的场景。SF 100 是 TPC-H 的一个规模因子(Scale Factor),表示基准测试所使用的数据集的大小。
TPC-H SF 100 的具体介绍
1. 数据规模
• SF 100 表示基准测试中的数据量为100GB。TPC-H的SF因子直接控制数据集的大小,例如,SF 1代表1GB的数据集,SF 100代表100GB的数据集。随着规模因子增大,数据库中的行数和表的大小成比例增长。
2. 表结构 TPC-H基准测试包含8个主要表,它们在不同的规模因子下会有不同数量的行:对于 SF 100,
LINEITEM
表大约包含6亿行,而ORDERS
表有1亿5000万行左右。•
LINEITEM
: 包含订单明细,通常是最大的表。•
ORDERS
: 订单信息。•
CUSTOMER
: 客户信息。•
SUPPLIER
: 供应商信息。•
PART
: 商品信息。•
PARTSUPP
: 商品和供应商的关系表。•
NATION
: 国家信息。•
REGION
: 地区信息。3. 查询 TPC-H 包含22个标准化的 SQL 查询,专注于复杂的分析操作。查询涉及以下内容:这些查询模拟了典型商业环境中的关键场景,例如:
• 分析供应链效率。
• 预测趋势。
• 计算市场份额等。
• 大量数据的聚合与过滤。
• 多表关联(join)操作。
• 日期和范围查询。
• 对不同的数据维度进行分组汇总。
4. 性能测试 在 TPC-H SF 100 的环境下,执行这些查询的时间和系统资源的使用将成为性能的主要评估指标。TPC-H 的主要指标包括:
• QphH (Queries per hour TPC-H): 每小时处理的查询数量,用来衡量系统的吞吐量。
• TpmH (Transactions per minute TPC-H): 每分钟处理的事务数量。
5. 存储与索引 由于 SF 100 数据量较大,通常需要使用大规模的存储系统,并在查询时高效地利用索引、视图以及并行处理技术。数据库系统需要有能力处理数亿行的大表,同时保证查询的响应时间在可接受范围内。
6. 硬件需求 TPC-H SF 100 对系统的硬件资源有较高要求,通常测试在多核处理器、大量内存、高速存储(如SSD阵列)以及高效的网络环境中进行,以确保能在合理的时间内完成所有查询和更新操作。
7. 应用场景 TPC-H 测试的数据和查询场景能够模拟企业的数据仓库和OLAP(在线分析处理)场景,例如:
• 财务报告。
• 市场分析。
• 产品定价与采购决策。
