





本文字数:6374;估计阅读时间:16分钟
作者:吴建超
原文链接:http://jackywoo.cn/ck-internal-how-clickhouse-do-aggregating/
Meetup活动
ClickHouse Guangzhou User Group第1届 Meetup火热报名中,详见文末海报!

聚合是ClickHouse最重要的算子,也是进行优化最多的算子,本文尝试分析ClickHouse聚合算子的内部实现,包括宏观算法和底层数据结构。
PS:本文的分析基于Clickhouse v24.7

ClickHouse中聚合算子实现有三个基本要素:第一是HashMap;第二是并行计算;第三是两阶段聚合。
如下图所示,T1 T2 T3是三个线程,每个线程接收数据,并独立的将数据进行初步聚合(pre-aggregate),聚合的数据存储在一个HashMap中,等所有的数据完成初步聚合后,将初步聚合的中间结果进行二次聚合(final-aggregate),考虑到并发问题,这一步需要在单线程中执行,并最终得到一个完全聚合的HashMap,也就是最终结果。
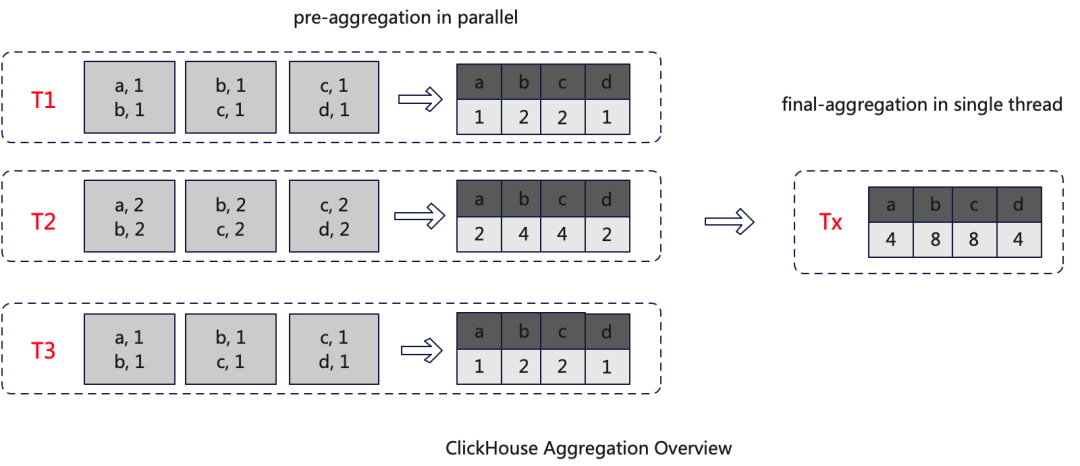
但是这种算法有性能问题。假设如下场景,pre-aggregate聚合度较低,聚合后数据条数基本没有减少,那么final-aggregate处理的数据与pre-aggregate基本相同,由于final-aggregate是在单线程内处理的,所以其处理的时间会很长,从而影响查询效率。
如何进行优化?一个直接的思路是将final-aggregate并行化,并行化会涉及到并发问题,这时候就轮到新的数据结构Two-level HashMap出场了。
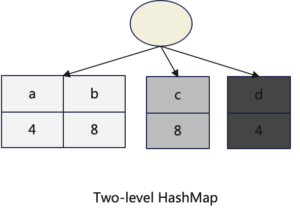
1.Two-level HashMap
相对于常规HashMap,Two-level HashMap是一个二层数据结构,数据首先映射到一个Bucket,这个Bucket是一个常规HashMap,然后再次将数据进行映射到常规HashMap的Bucket中,更多关于Two-level HashMap请参考下文。
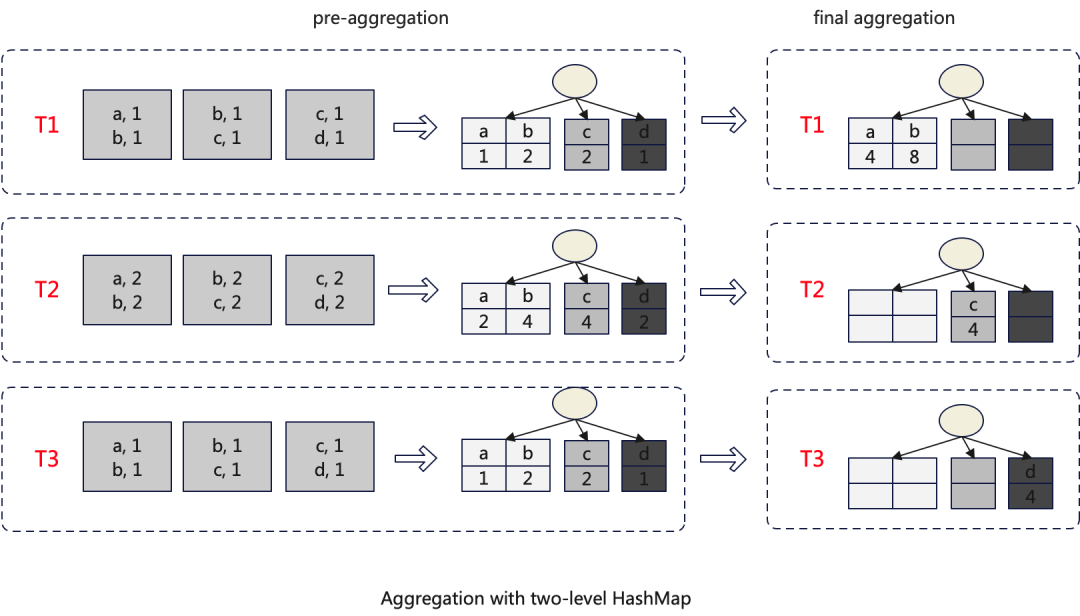
2.优化后的算法
使用Two-level HashMap后,整个聚合算法也需要进行调整,调整主要发生在final-aggregate阶段,每个子HashMap单独的在一个线程中处理,以避免并发问题,从而达到并行进行的处理目的。
3.如何选择聚合算法?
ClickHouse提供了一种运行时自适应的方式,在运行时选择选择聚合算法以及是否使用Two-level HashMap。
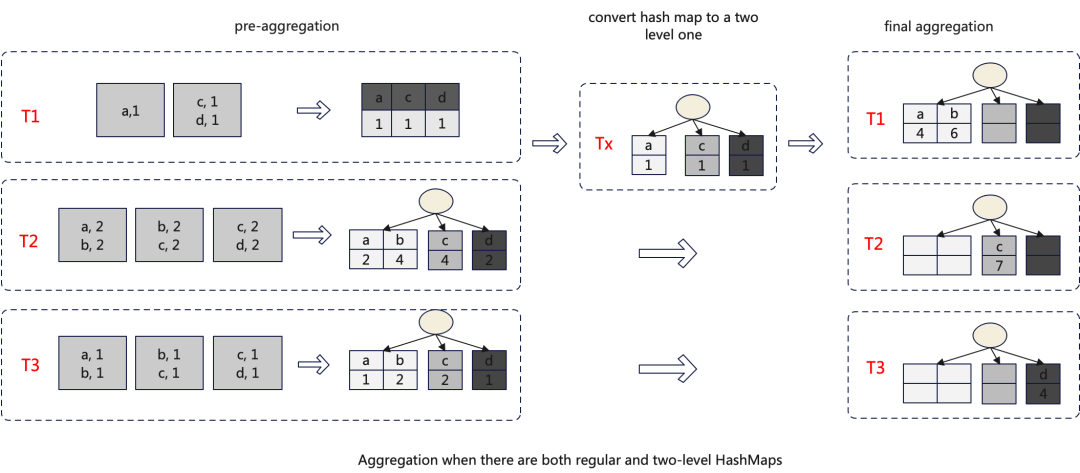
具体的策略是当pre-aggregate过程中,HashMap中的数据超过一定阈值,将其转换成Two-level HashMap。参考参数:group_by_two_level_threshold和group_by_two_level_threshold_bytes。
每个pre-aggregate线程独立选择是否是用Two-level HashMap的,那么在进行第二次聚合的时候输入可能既有常规HashMap也有Two-level Hashmap,对于这种情况会在final-aggregate前先将常规HashMap转换成Two-level的。整体的算法如下图所示:
目前HashMap向Two-level的转化是在单个线程中处理的,将其并行化明显会提升性能,这是一个潜在的优化点。
ClickHouse的计算引擎是一个面向列的计算引擎,运行时数据在内存中的存储与处理也是以面向列的,算子的每次输入被称为Block。Block是n个列组成的二维表,其内存layout如下图所示:
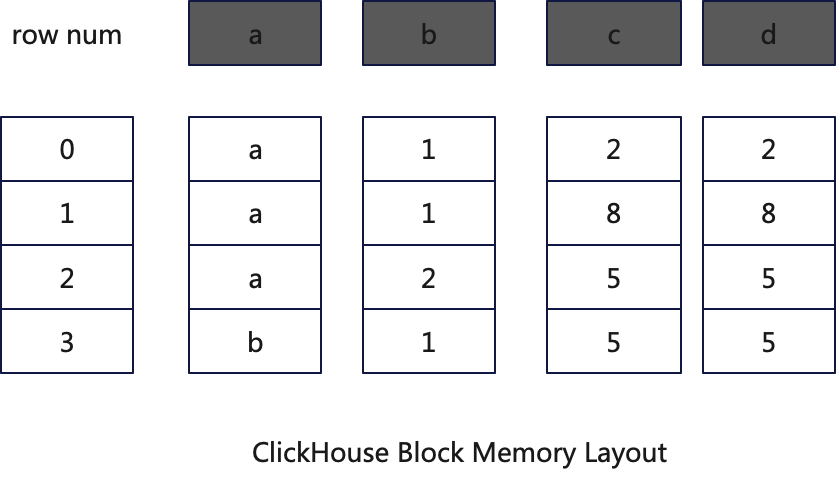
在pre-aggregate阶段ClickHouse会将Block生成HashMap,具体流程如下:
1.Build HashMap
对于每一行判断聚合key在HashMap中是否存在,不存在则将其插入到HashMap中,并通过Arena申请聚合函数状态需要的内存,并在内存中初始化聚合函数的状态对象的内存结构,注意这里只分配key对应value的内存空间,并不会执行聚合操作。
什么是聚合函数的状态对象?比如sum可能是一个Int64,uniqExact可能是一个HashSet等。
以下为Build HashMap阶段创建聚合函数状态对象的关键代码:
/// 1. 为聚合函数分配内存/// total_size_of_aggregate_states:表示查询中所有聚合函数状态存储的内存总和/// aggregates_pool:是一个Arena,用于分配内存/// place:是分配好的一块连续的内存空间AggregateDataPtr place = result.aggregates_pool->alignedAlloc(total_size_of_aggregate_states, align_aggregate_states);/// 2. 为每一个聚合函数状态创建对应的对象,比如sum函数可能为AggregateFunctionSumData<Int64>aggregate_functions[j]->create(place + offsets_of_aggregate_states[j]);
同时ClickHouse在内存中为Block中的每一行数据维护一个聚合函数状态对象的内存地址的指针,以便下一步能够快速通过行号找到对应的聚合函数状态数据地址。
下图展示了构建好的HashMap的内存机构:
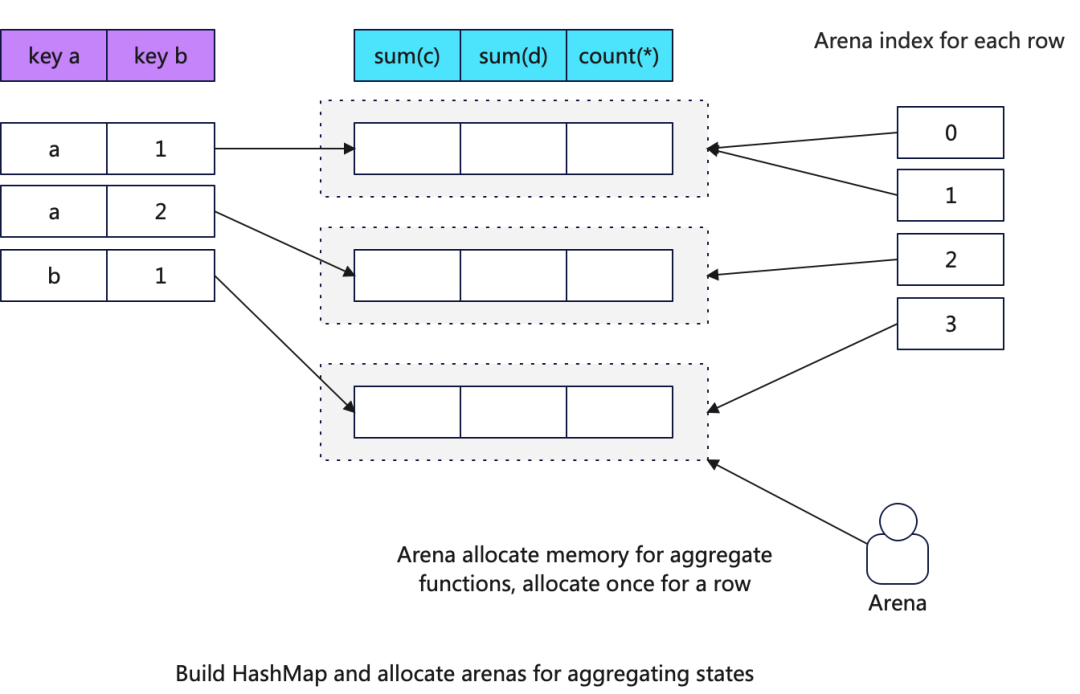
对于聚合函数的状态ClickHouse使用Arena来统一分配内存,而不是传统的new的方式,为什么?
因为聚合算子可能消耗大量的内存,大量的内存的使用需要监控和管理,比如限制查询的内存使用量或者当内存达到一定阈值的时候将状态spill到磁盘。
这一步完成后所有的key-value已经存在于HashMap中,只不过value是空的状态。
2.Execute Agregation
构建好HashMap后就可以执行聚合操作,这里根据聚合函数状态对象的地址索引快速定位到聚合函数的数据地址,然后应用每个聚合函数。下图展示了聚合后的HashMap
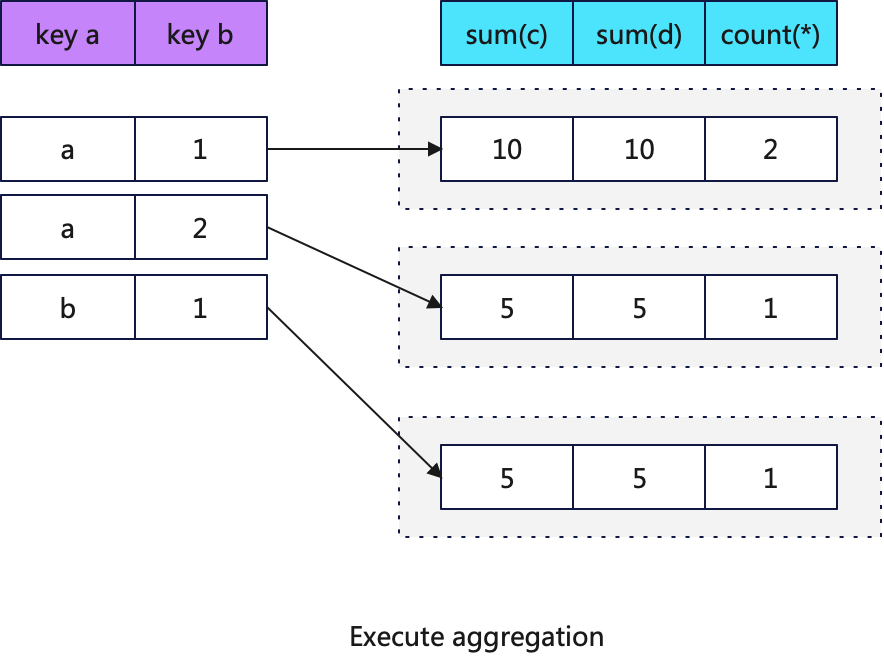
由于聚合操作的结果分布在多个不同的内存地址中,所以其是不能通过SIMD指令加速的,以下是聚合操作的关键代码:
/// 执行一个聚合函数void IAggregateFunctionHelper::addBatch( /// NOLINTsize_t row_begin,size_t row_end,AggregateDataPtr * places,size_t place_offset,const IColumn ** columns,Arena * arena,ssize_t if_argument_pos = -1) const override{for (size_t i = row_begin; i < row_end; ++i)if (places[i])static_cast<const Derived *>(this)->add(places[i] + place_offset, columns, i, arena);}
但是如果聚合的key都是常量值,那么结果只有一条数据,此时可以通过SIMD指令进行优化。
// Key都是常量,Sum函数使用SIMD指令优化聚合template <typename Value>void NO_INLINE AggregateFunctionSumData::addMany(const Value * __restrict ptr, size_t start, size_t end){#if USE_MULTITARGET_CODEif (isArchSupported(TargetArch::AVX512BW)){addManyImplAVX512BW(ptr, start, end);return;}if (isArchSupported(TargetArch::AVX512F)){addManyImplAVX512F(ptr, start, end);return;}if (isArchSupported(TargetArch::AVX2)){addManyImplAVX2(ptr, start, end);return;}if (isArchSupported(TargetArch::SSE42)){addManyImplSSE42(ptr, start, end);return;}#endifaddManyImpl(ptr, start, end);}
在上面的代码中使用了向量化指令转发器,以选择最优的向量化指令进行执行,具体参考:cpu-dispatch-in-clickhouse【https://clickhouse.com/blog/cpu-dispatch-in-clickhouse】
同时ClickHouse提供了JIT的方式对聚合进行优化,参数compile_aggregate_expressions可以控制是否开启聚合算子的JIT优化,新版本默认是打开的。
HashMap是聚合算子中最用重要的数据结构,其性能的好坏对查询有极大的影响。所以ClickHouse对HashMap进行了大量的优化。
ClickHouse在聚合场景中优化的思路是根据不同的聚合key的个数和数据类型选择不同的HashMap以及哈希函数,这种特例化的性能优化思路在ClickHouse中有大量的体现。
目前ClickHouse提供了30+不同的HashMap和哈希函数的组合,以应对不同的聚合key类型,具体可以参考:AggregatedData。
以下按照分类简单介绍下这些HashMap:
1.HashMap基本结构
ClickHouse使用开放地址法的HashMap,虽然C++标准库采用拉链法处理冲突,但是现代的HashMap更多采用开放地址法,开放地址法相对于拉链法的HashMap有如下优势:
CPU CacheLine友好,提供更高的缓存命中率
避免在插入数据的时候分配内存空间(分配内存空间的函数相对比较慢)
不需要链表中的指针,更节约内存
不需要处理链表,实现更简单
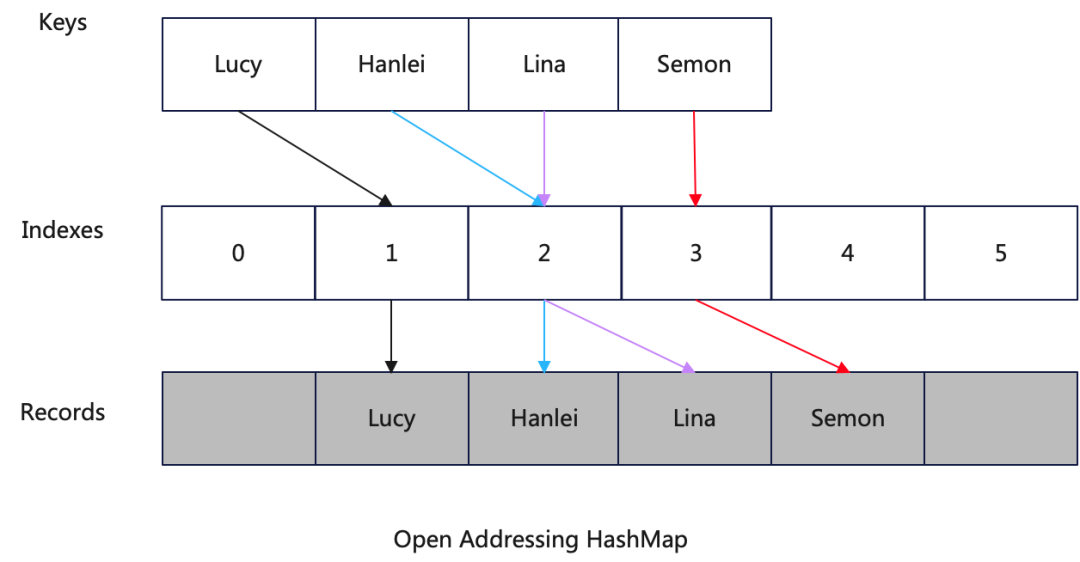
在聚合场景选择开放地址法的HashMap可能更多的是考虑到在final-aggregate阶段需要合并多个HashMap,这里涉及到遍历整个HashMap,而CPU CacheLine友好的HashMap能够带来更好的性能。
2.FixedHashMap
FixedHashMap用于单一聚合key,并且其数据类型为UInt8或者UInt16的查询,由于这两个数据类型的值空间大小是有限的,所以其内存结构是按照其值范围设置的固定的连续存储空间。
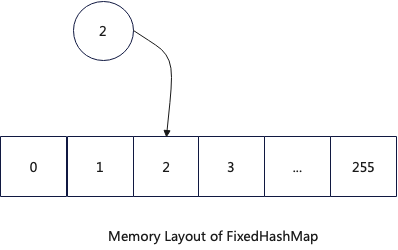
FixedHashMap具有以下优势:
哈希函数极其高效,因为可以使用数值直接作为哈希值
没有冲突,查找高效,因为哈希值跟数据是一对一映射
没有resize带来的开销,请求平稳
3.StringHashMap
StringHashMap用于存储String类型的数据,是一个非常常用的HashMap。其本身是一个复合型的数据结构,内置多个常规的HashMap,根据key的长度将数据路由到不同的HashMap中。
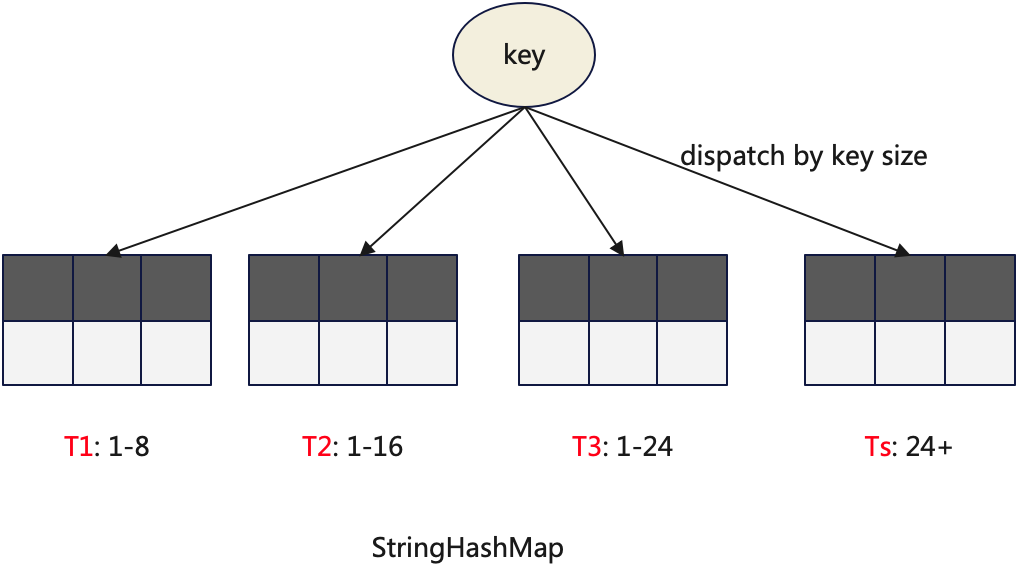
前三个子HashMap使用固定长度的key类型,比如T1的key是StringKey8(UInt64),T2的key是StringKey16(UInt128),以便使用更高效率的哈希函数。对于长度不足的字符串用0进行补位。
StringHashMap同样使用定制化的哈希函数,这些哈希函数主要通过SSE42的_mm_crc32_u64函数实现。
struct StringHashTableHash{#if defined(__SSE4_2__)size_t ALWAYS_INLINE operator()(StringKey8 key) const{size_t res = -1ULL;res = _mm_crc32_u64(res, key);return res;}size_t ALWAYS_INLINE operator()(StringKey16 key) const{size_t res = -1ULL;res = _mm_crc32_u64(res, key.items[0]);res = _mm_crc32_u64(res, key.items[1]);return res;}size_t ALWAYS_INLINE operator()(StringKey24 key) const{size_t res = -1ULL;res = _mm_crc32_u64(res, key.a);res = _mm_crc32_u64(res, key.b);res = _mm_crc32_u64(res, key.c);return res;}......#endifsize_t ALWAYS_INLINE operator()(StringRef key) const{return StringRefHash()(key);}};
4.TwoLevelHashMap
TwoLevelHashMap前文介绍过,它是final-aggregate可以并行化的主要数据结构。它的包含固定的256个子HashMap。值得注意的是当访问它的时候并不需要做两次哈希计算。通过哈希值的前8位来选择子HashMap剩余部分来选择子HashMap中的分桶。
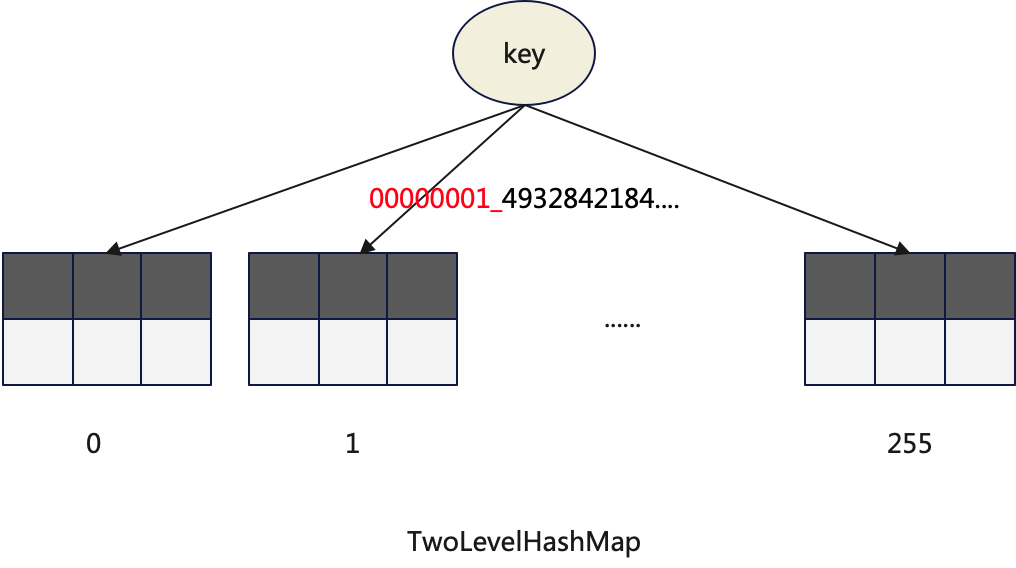
同时ClickHouse还提供了一个它的变种TwoLevelHashMapWithSavedHash,它的特点是将哈希值也保存起来,主要用于在合并HashMap的时候可以避免计算哈希值。
1.Aggregate By Partition
如果聚合查询的group by列于表的分区表达式列表的前缀匹配,那么聚合算法可以是使用一阶段的方式,直接省略final-aggregate。优化开关allow_aggregate_partitions_independently,默认是关闭的。
2.In-order优化
如果聚合查询的group by列与表的order by keys的前缀列匹配,那么可以根据数据的有序特性对聚合算子进行优化,优化开关:optimize_aggregation_in_order。详细参考ClickHouse内幕(6)基于有序的查询优化【http://jackywoo.cn/ck-internal-optimizations-based-on-index/】
本文尝试总结ClickHouse中聚合算子的算法和重要的优化方式,但其实在此之外还有很多优化,比如:
final-aggregate阶段按照什么顺序合并HashMap?
内存如不足的时候如何将算子的数据spill到磁盘?
遍历HashMap的时候是否需要做prefetch?
Pipeline执行引擎如何支持运行时变更执行计划?
编码层面如何做一些底层优化,比如:inline、__restrict?
文中的观点均来自于对ClickHouse源代码的阅读和作者的理解,如有疑问欢迎交流。

好消息:ClickHouse Guangzhou User Group第1届 Meetup 已经开放报名了,将于2024年8月25日在广州天河区林和中路6号 海航威斯汀酒店 5楼多功能3厅举行,扫码免费报名

征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


