




今天分享的是由MIT发布的一篇论文:
PRompt Optimization in Multi-Step Tasks (PROMST): Integrating Human Feedback and Heuristic-based Sampling

文章链接:https://arxiv.org/pdf/2402.08702
代码链接:https://github.com/yongchao98/PROMST
论文摘要
这篇文章提出了一种针对大语言模型的多步骤任务优化prompt的新框架,名为PROMST。该框架旨在解决多步骤任务中提示词优化的挑战,这些挑战包括提示内容的复杂性增加、单个步骤效果评估困难以及不同用户对任务执行偏好的差异。
主要方法
LLM Based Agents for Multi-Step
首先,我们来了解下什么是多步任务。多步任务是指那些需要一系列连续动作或决策才能完成的任务。在涉及LLM的应用场景中,这类任务通常要求模型能够理解任务的目标,并逐步规划和执行一系列操作以达成最终目的。这些任务可能包括但不限于与软件或网站交互、规划机器人行动、或者调用外部工具来辅助完成特定目标。
例如,在使用LLM与软件或网站交互时,多步任务可能涉及登录账户、搜索信息、填写表单并提交等步骤。对于机器人行动规划,多步任务可能是让机器人移动到某个位置、拿起物品、将物品放置在另一个位置等。在使用外部工具的Agent场景下,多步任务则可能涉及检索信息、分析结果、执行特定操作等步骤。
PROMST框架
PROMST框架的结构如下图所示。
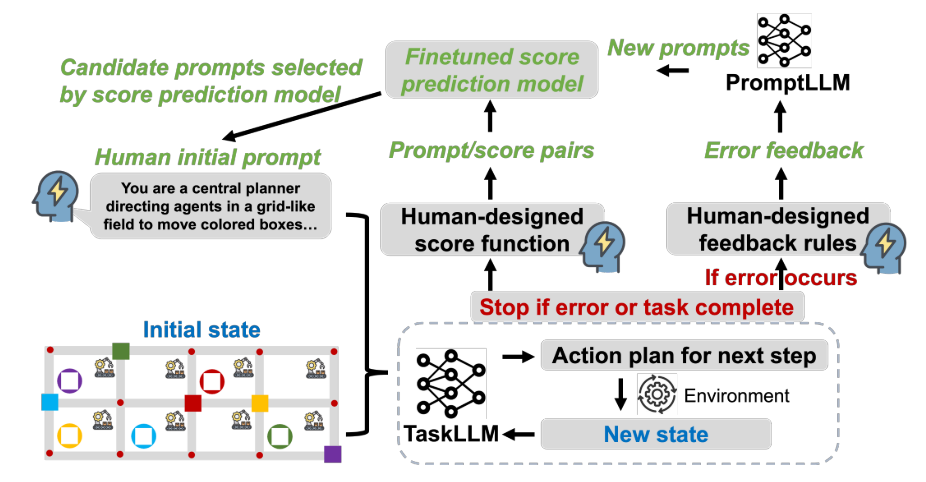
LLM组件:
TaskLLM:执行任务的当前候选提示词。
PromptLLM:根据当前提示在任务上的表现生成新的候选提示词。
单次执行:将一个任务测试案例中的单次执行称为一次“trial”。
TaskLLM:在每个试验(trial)中,TaskLLM会通过多轮与环境的交互来执行任务。每轮中,TaskLLM都会收到当前候选提示词及当前试验的执行历史,并据此生成下一步行动。任务执行会在检测到错误或任务完成时终止。
评分函数:候选提示词P会根据人类设计的评分函数获得一个分数。每个候选提示词会在多个试验中被评估,这些试验中环境的初始状态(如对象数量、代理数量等)会有变化。所有试验的平均分数构成了最终的平均得分。
p'进行预测。如果满足以下条件,则选择
p':
其中:
是五个模型对 p'
预测得分的均值是五个模型对 p'
预测得分的方差是五个得分模型的平均测试误差 是现有提示的最高得分
人工规定的反馈规则:TaskLLM在执行任务的过程中可能会遇到错误并导致任务终止。为了避免这种情况发生,PromptLLM需要有关于这些错误的信息,以便在生成新的提示词候选时考虑这些信息。然而,对于多步骤的任务来说,通过语言模型自动分析错误是很困难的,特别是当Agent陷入动作循环等复杂情况时。
因此,文中提出了一种解决方案,即使用人为设计的规则来自动合成反馈信息。这些规则可以根据不同的错误类型生成相应的反馈,从而指导PromptLLM生成更好的提示候选。这些规则的设计过程相对简单直观,不需要复杂的试错过程。
具体来说:
自动反馈规则:由于语言模型难以自动分析多步骤任务中的错误,系统采用了人为设计的规则来生成反馈。这些规则可以根据发生的错误类型自动合成反馈信息。 通用与特定反馈:反馈规则可以分为两类:一类是适用于所有任务的通用错误类型(例如语法错误),另一类则是针对特定任务的特定错误类型。 设计过程:设计这些反馈模板的过程相对简单直接,不需要大量的尝试和错误修正。 简而言之,当TaskLLM遇到错误时,系统使用预先定义的人为设计的规则来生成反馈信息,这些信息可以帮助PromptLLM更好地理解问题所在,并生成更有效的提示来解决这些问题。这种方法避免了通过复杂的自动分析来识别错误,而是依赖于简单的规则来提供有用的反馈。下图为人工设定的8个反馈规则的例子(机器人行动的例子)。

Syntactic Error:提示描述的语法错误。如果提示的格式不正确,那么就会给出这样的反馈。
Stuck in the Loop:提示可能导致LLM陷入循环。这里提供了前两轮的状态和动作,以及环境的反馈,然后指出LLM似乎陷入了重复回答相同答案的情况,任务也卡住了。
Collision:响应中的动作会导致碰撞。
Move Out of the Grid:响应中的动作会导致移动超出网格范围。
Wrong Picking Up Order:响应中的动作顺序不对,应按照goal_0、goal_1、goal_2等的顺序拾取物品。
Failure Over Query Time Limit:任务未在规定时间内完成。
Invalid Action:响应中的动作无效。
Wrong Object Action:响应中的动作试图引用不存在或不明确的车辆(卡车、飞机)。
具体的再生成流程如下,首先,使用一个语言模型(SumLLM)来总结反馈。为了鼓励探索更多样化的候选提示,随机选择10个反馈实例。这种随机选择也可能促进更频繁的错误出现。给定这些选定的反馈,SumLLM会产生一个总结,这个总结将作为背景信息提供给下一个步骤的GenLLM。第二步是使用另一个语言模型(GenLLM)来生成新的候选提示。GenLLM会使用SumLLM产生的总结作为背景信息来生成新的候选提示。
实验
实验设置
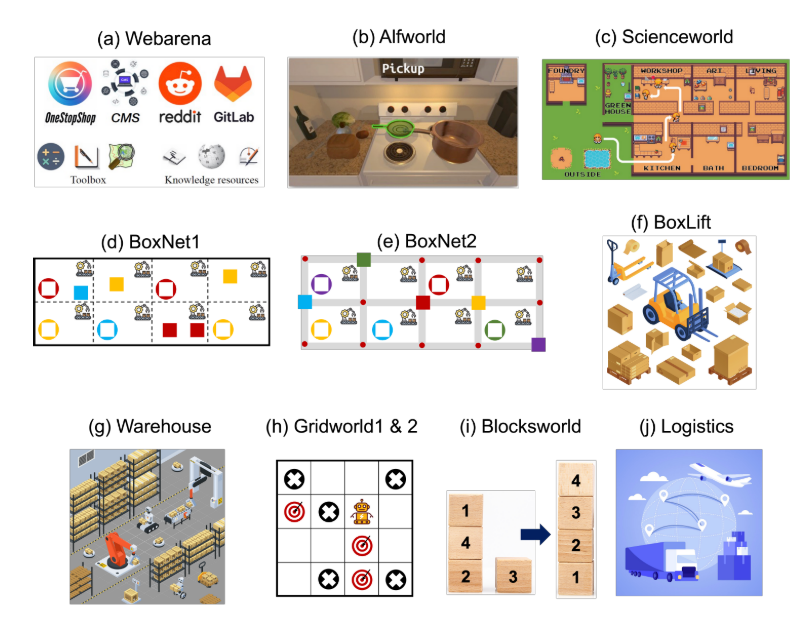
如下图所示,论文共测试了11个场景的任务。这些任务需要很强的逻辑、几何、科学和常识推理能力。每个任务都要求LLM代理在较大的离散操作空间中确定下一个操作。
为了确保公平比较不同方法的效果,作者采用以下这些设置:
GPT3.5作为TaskLLM+GPT4作为PromptLLM TaskLLM 和 PromptLLM 均使用GPT-4 TaskLLM 和 PromptLLM 均使用Claude 3 Opus (Anthropic, 2024) TaskLLM 和 PromptLLM 均使用Mixtral-8x7B (Jiang et al., 2024) TaskLLM 和 PromptLLM 均使用Mixtral-Large (Jiang et al., 2024)
使用一个状态-动作-反馈元组的历史记录的滑动窗口。历史记录超过窗口长度时,会裁剪掉较旧的部分。
k=5)当前提示作为父提示词行进一步的优化。如果最近三个级别的优化过程中没有观察到评分的提高,则搜索过程终止。在PROMST方法中,超参数
hyper_M被设置为0.8),用于过滤掉得分较低的提示。
实验结果分析
实验结果如下图所示:
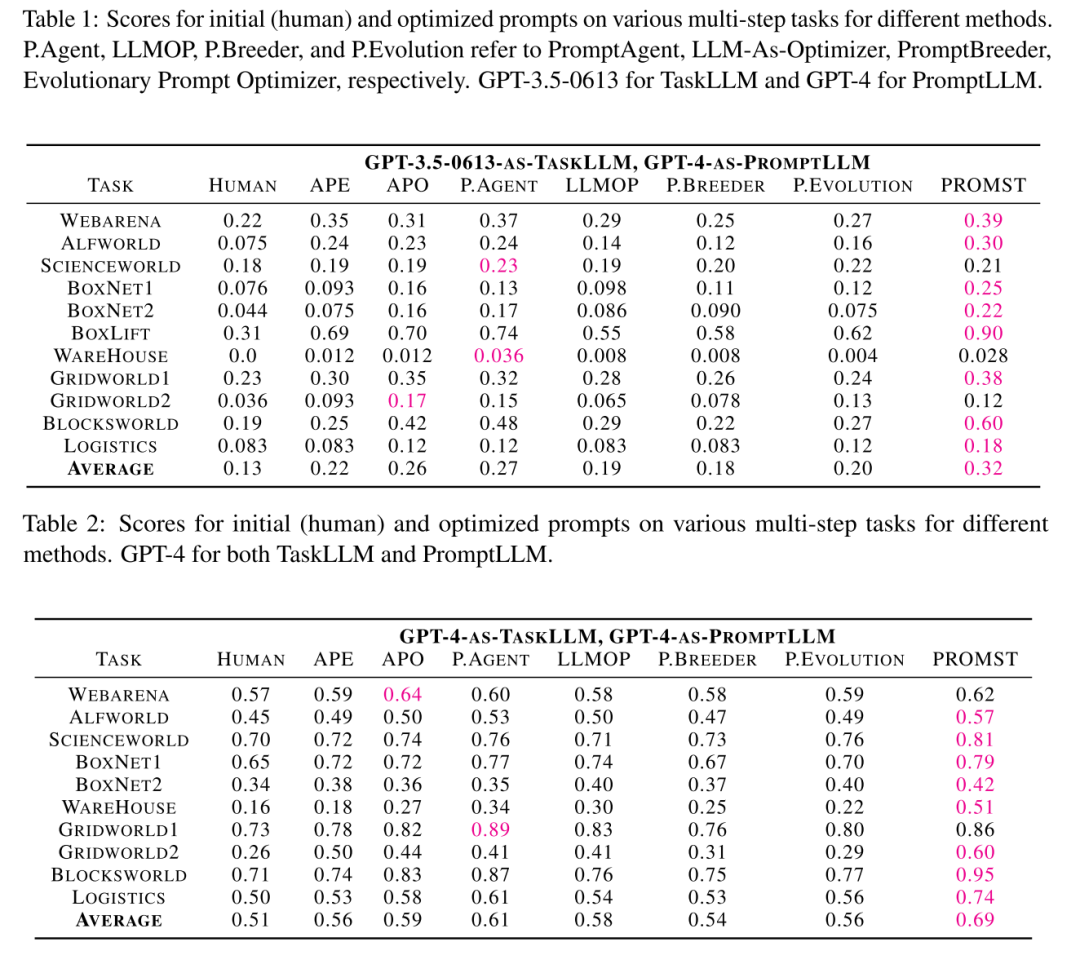
PROMST 性能表现最佳: 在大多数任务中,PROMST 的表现超过了最强的基线方法,例如使用 GPT-3.5-0613 和 GPT-4 作为 PromptLLM 时,PROMST 分别取得了 0.27 和 0.61 的分数,而最强基线分别得到了 0.32 和 0.69 的分数。 不同 LLM 生成编写的提示词 即使当使用 GPT-3.5-0613 和 GPT-4 训练的最佳提示词到不同的 TaskLLM 上时,这些提示的表现仍然超过人工编写的提示。这意味着自动优化的提示即使不是针对特定的 TaskLLM 优化,也能够展现出比人工编写更好的性能。 LLM 与提示词之间的匹配性: 每个 LLM 在使用针对其自身优化的提示时表现最好。例如,使用 GPT-3.5-0613 优化的提示词用于 GPT-4 时并不能带来进一步的性能提升,反之亦然。这说明了不同 LLM 之间存在一定的差异性,它们对特定类型的提示可能有不同的响应。 PROMST 不依赖于更强的 PromptLLM: 当 TaskLLM 和 PromptLLM 是同一个 LLM 时,PROMST 依然表现出色。这表明 PROMST 并不依靠更强的 PromptLLM 来向提示中传递额外的知识。这一点很重要,因为它避免了所谓的“作弊”行为——即利用更强的模型来生成提示,然后在较弱的模型上测试这些提示。
总结
本文提出了一个自动的提示词优化框架,并给出了详细的实验。在文章的附录中列举了大量生成的提示词和最初提示词的对比以及使用到的提示词、评分函数的分析。但作者也提到这篇工作的一些限制,总结如下:
资源密集型:自动提示优化过程需要大量的计算资源和 LLM API 调用来探索和评估不同的提示候选。由于这是一个基于搜索的过程,即使是经过优化的方法(如引入评分模型),也需要大约 100 个提示候选的探索,这对计算资源来说是一个很大的负担。
对硬件的要求:为了减少API的调用,本地训练了评分模型。但评分模型的训练增加了本地设备的计算负载,这意味着用户需要有足够的硬件能力来支持这一过程。
适应性问题:为了有效训练评分模型,通常需要大约 100 对提示-得分的数据点。这对于黑盒提示搜索来说是合理的,因为确实需要这么多的数据点来确保模型的性能。然而,如果将来出现更高效的搜索方法,使得所需的样本数量大大减少,那么现有的评分模型可能就不再适用了。
