




背景
在当前架构的设计中,会基于 RabbitMQ 的 tracing 功能抓取经过 MQ 的消息,即使明确知道存在严重的性能问题(这个事情一直是我最为不满的槽点)
组内基于 shell 脚本实现 tracing 功能的使能和配置,但其中的处理逻辑让人看完就有一种“一定会存在问题”的预感,而这么实现的理由似乎是“觉得”其他实现方式会更麻烦
当前脚本实现
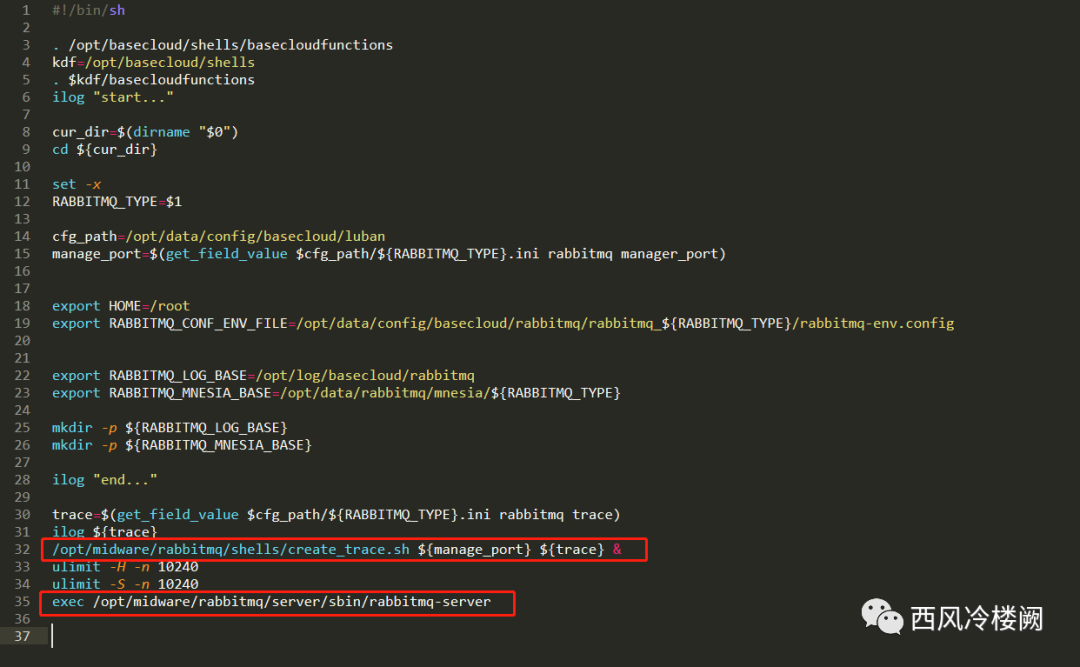
start.sh
能够看到该脚本的核心功能是启动 RabbitMQ
同时可以看到,在该脚本中还采用“后台运行”方式调用了 create_trace.sh 脚本
分析:
启动 RabbitMQ 和创建 trace 明显存在顺序上的先后关系
将创建 trace 的动作放在用于启动 RabbitMQ 的脚本中,似乎并不合适
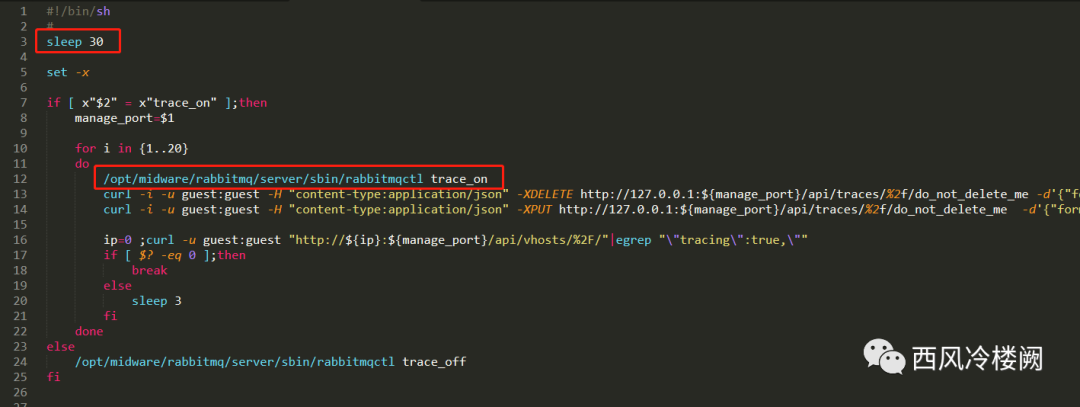
create_trace.sh
通过 sleep 30 延时来确保大部分情况下当前脚本会在 RabbitMQ 启动后才被执行
通过 for 循环 + sleep 3 延时,确保 tracing 功能的启用,以及 trace 规则的建立
分析:
直观上,这种实现逻辑就是“丑陋”的
细节上,实现中的做法采用了“粗放式”策略,只治标,不治本;假设 RabbitMQ 完全启动需要大约 18s ,但由于某种原因,RabbitMQ 启动后就会“挂掉”,之后再被重新拉起,反复 N 次才能运行正常,这种情况下,可能出现:
rabbitmqctl trace_on 卡住
curl 卡住
for 循环结束后,tracing 功能依然启动失败,trace 规则建立失败
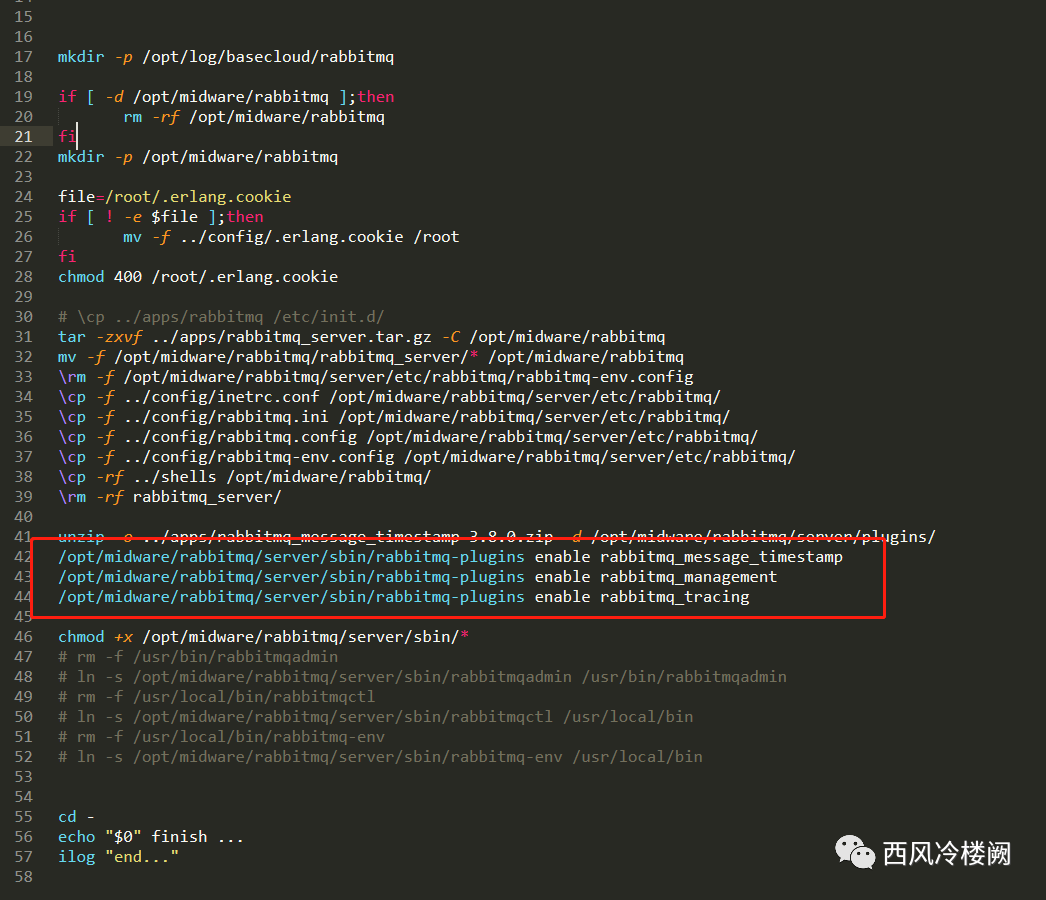
install.sh
主要负责 enable 各种插件
之所以能够在安装脚本中使用,源于该命令同时支持 on-line 和 off-line 两种变更方式,即当 RabbitMQ 尚未运行时,采用的是 off-line 方式完成变更,等 RabbitMQ 上线后再自动加载变更后的配置
思考
RabbitMQ tracing 功能的具体表现形式
RabbitMQ tracing 功能的使用场景
启用 tracing 功能后会导致的问题
使用 tracing 功能时最合理的配置和使能方式
关于 tracing 功能,我们还需要知道些什么
0x01 tracing 功能的具体表现形式
从以下几处信息可知
firehose 是作为 feature 由 RabbitMQ 内部直接提供的
rabbitmq_tracing 是作为一个 plugin 构建于 firehose 之上,同时提供了 GUI 方便管理员操作,并能够将 traced message 写入日志文件
RabbitMQ has a "firehose" feature, where the administrator can enable (on a per-node, per-vhost basis) an exchange to which publish- and delivery-notifications should be CCed.



0x02 tracing 功能的使用场景
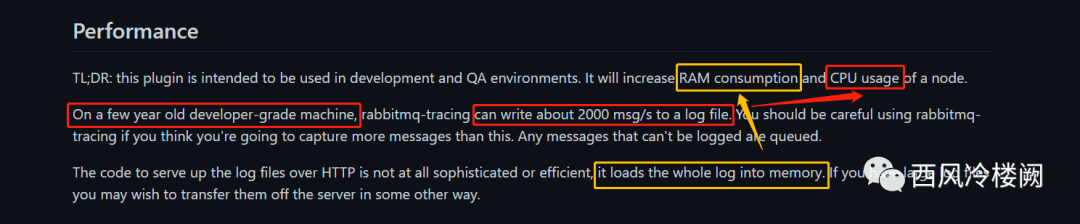
无论是关于 firehose 的介绍,还是对于 rabbitmq_tracing 插件的说明 ,均指出该功能仅适用于开发和调试阶段,以及开发和 QA 环境

0x03 启用 tracing 功能后会导致的问题
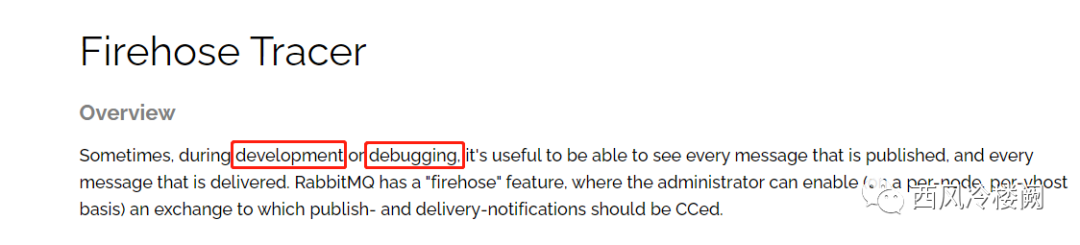
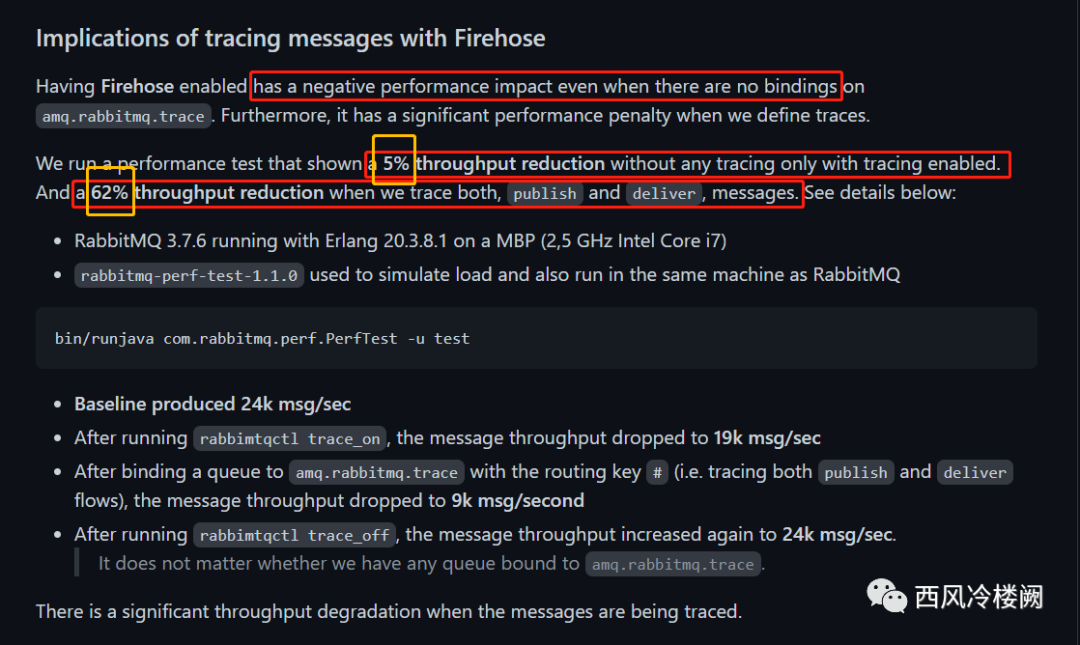
从 firehose 的角度,启用了该功能就会造成性能损失;

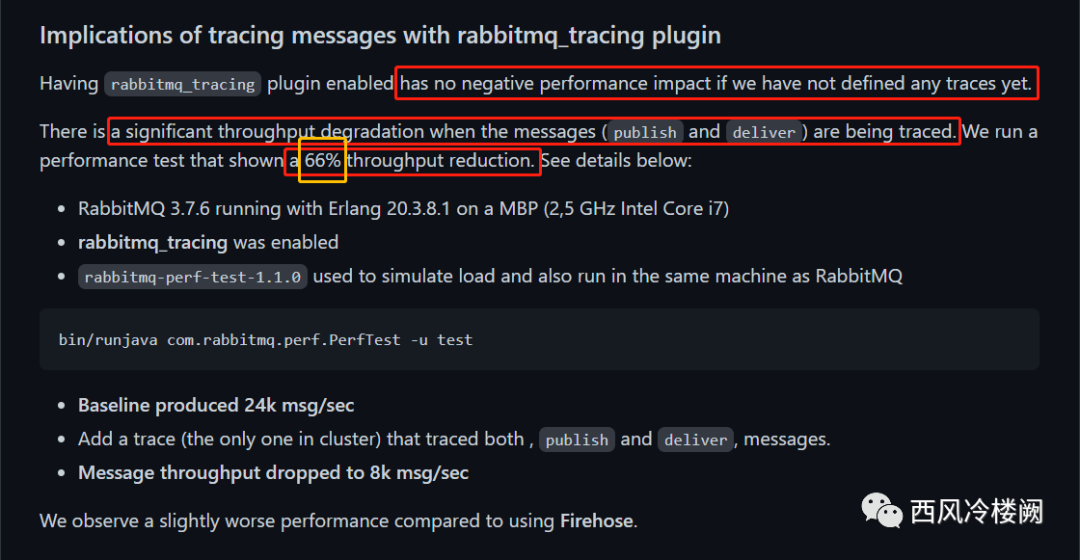
从 rabbitmq_tracing 的角度,使能插件并不造成性能下降,但一旦开始使用,则会对 RAM 和 CPU 造成极大影响
0x04 使用 tracing 功能时最合理的配置和使能方式
详见本文最后的“实验”内容
0x05 关于 tracing 功能,我们还需要知道些什么
tracing 的“使能”状态不是持久化的,重启后,默认恢复到 off 状态
Note that the firehose state is not persistent; it will default of off at server start time.
如果在使能了 firehose 后,又使能了 rabbitmq_tracing 插件,则当管理员停掉最后一个 trace 规则(也可以说成 trace 实例)后,tracing 功能同时会被 disable
TL;DR If rabbitmq_tracing plugin is also enabled and the administrator stops the last Trace, it will disable Firehose tracing entirely in addition to stopping the Trace instance.
只要启用了 firehose 功能,就会造成性能影响,即使并没有真正使用起来
Having Firehose enabled has a negative performance impact even when there are no bindings on amq.rabbitmq.trace. Furthermore, it has a significant performance penalty when we define traces.
如果你的 tracing 功能是基于 firehose 使用的,则不要忘记手动清理你所创建的 queue
Don't forget to clean up any queues that were used to consume events from the Firehose.
可以基于管理页面或 HTTP API 在集群中的任意 node 上创建 trace 规则
It is now possible to set up a tracer on any cluster node via management UI and HTTP API.GitHub issue: rabbitmq/rabbitmq-tracing#24
针对插件的 enable ,可以采用 on-line 和 off-line 两种方式,建议采用基于配置文件的 off-line 方式
Plugins are activated when a node is started or at runtime when a CLI tool is used. For a plugin to be activated at boot, it must be enabled. To enable a plugin, use the rabbitmq-plugins.
The rabbitmq-plugins command enables or disables plugins by contacting the running node to tell it to start or stop plugins as needed. It is possible to contact an arbitrary node -n option to specify a different node.
Having a node running before the plugins are enabled is not always practical or operator-friendly. For those cases rabbitmq-plugins provides an alternative way. If the --offline flag is specified, the tool will not contact any nodes and instead will modify the file containing the list of enabled plugins (appropriately named enabled_plugins) directly. This option is often optimal for node provisioning automation.
实验
该实验的前提是“由于目前的架构设计,导致不得不利用 RabbitMQ 的 tracing 功能干一些xxx事情”,因此,这里要探究的是,组内目前的脚本编写是否合理;
操作流程如下:
基于 docker-compose 启动 2-node RabbitMQ 集群
通过
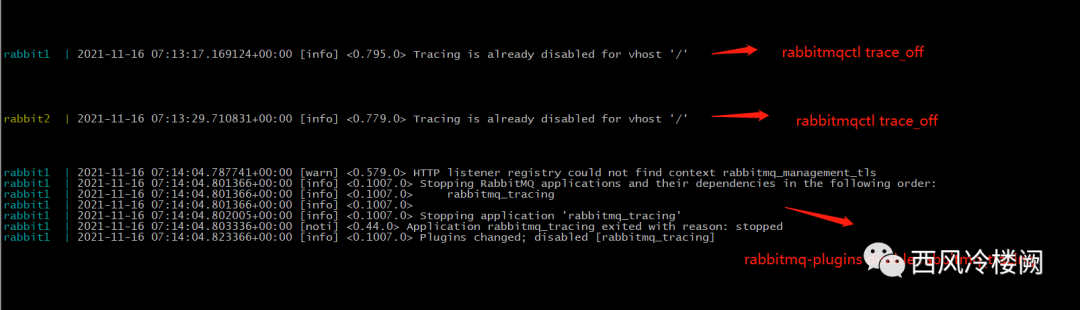
rabbitmqctl trace_off
命令将 rabbit1 和 rabbit2 上的 firehose 功能关掉(默认就是关的,这里是为了加强一下这个条件)
通过
rabbitmq-plugins disable rabbitmq_tracing
命令将 rabbit1 和 rabbit2 上的 rabbitmq_tracing 插件去使能
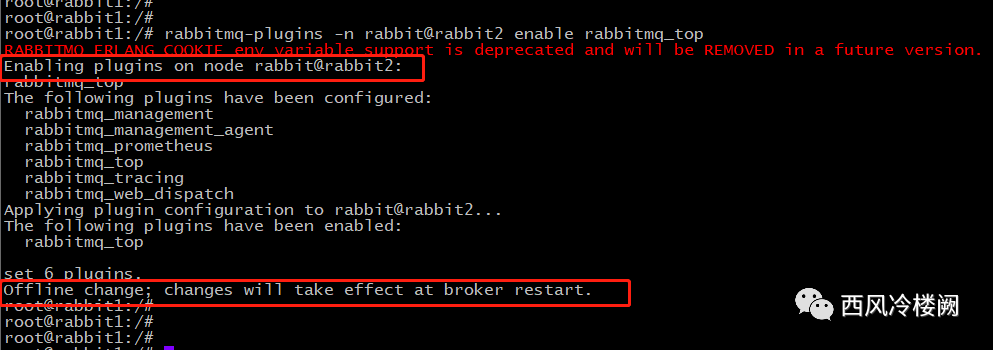
rabbit1 上执行

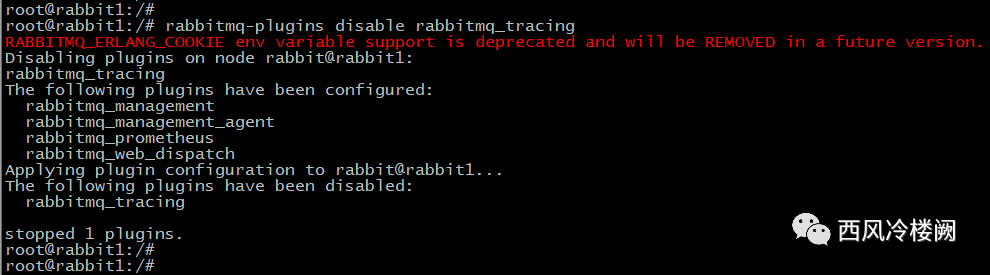
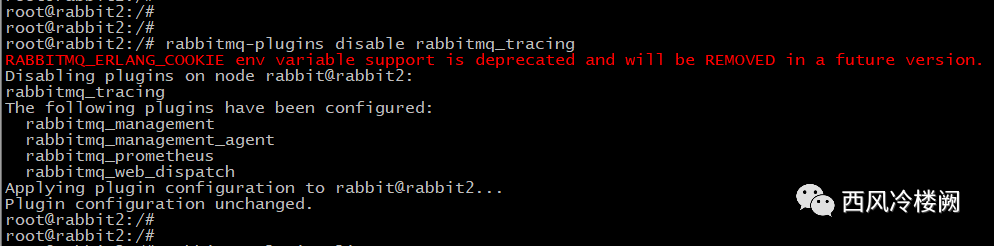
rabbit2 上执行

从 RabbitMQ 日志中可以看到
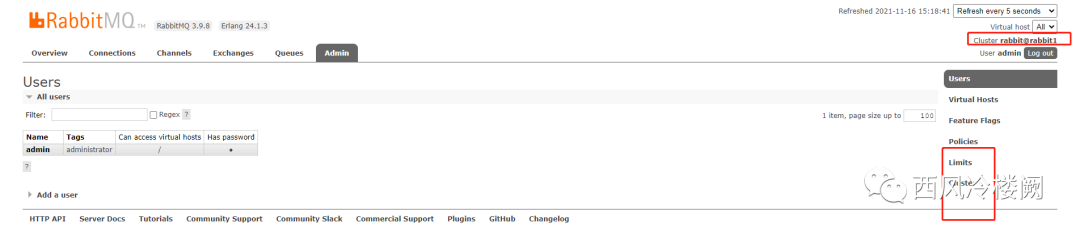
此时,从管理界面上看,节点 rabbit1 和 rabbit2 上显示的内容完全相同,以 rabbit1 为例

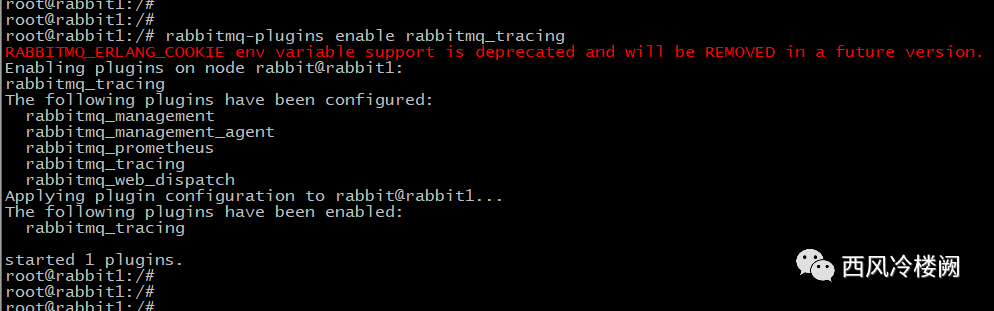
在 rabbit1 上 enable 插件 rabbitmq_tracing
server 日志输出如下

此时,从管理页面上可以看到,rabbit1 比 rabbit2 多了名为 tracing 的 tab
确认 rabbit2 上的插件状态,没有变化
页面上也没有变化
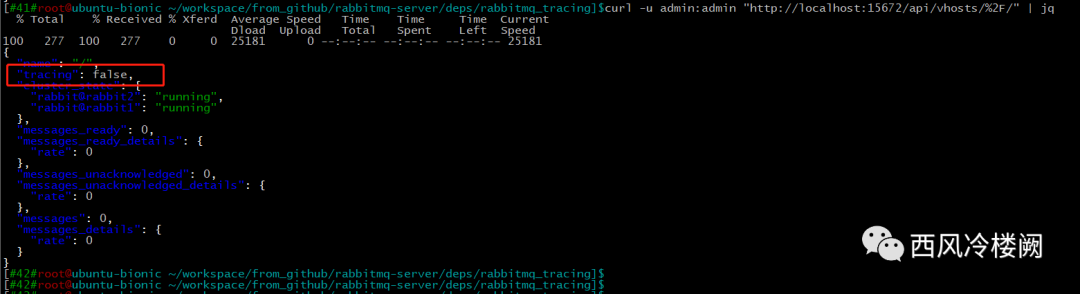
通过 curl 命令确认 tracing 功能是否已处于使能状态(可以看到,此时 tracing 值为 false,说明仅使能 rabbitmq_tracing 插件并未将 firehose 特性启用)
通过 curl 创建 trace 规则

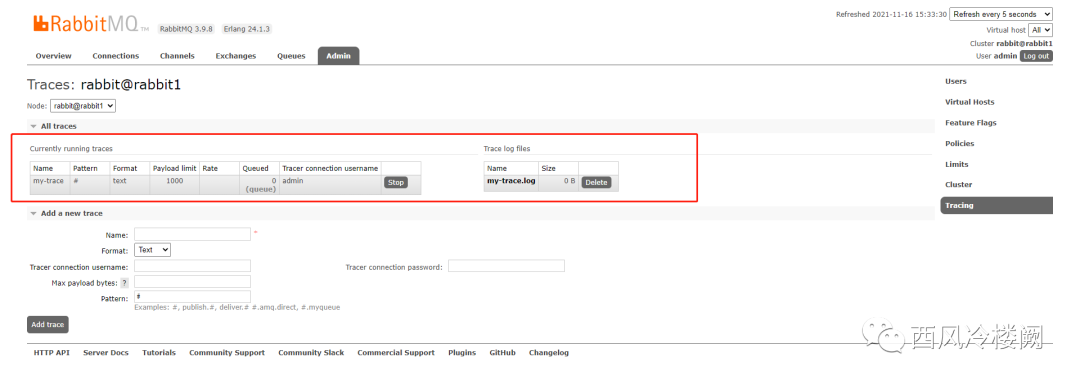
重新确认 tracing 状态,发现已经变成 true
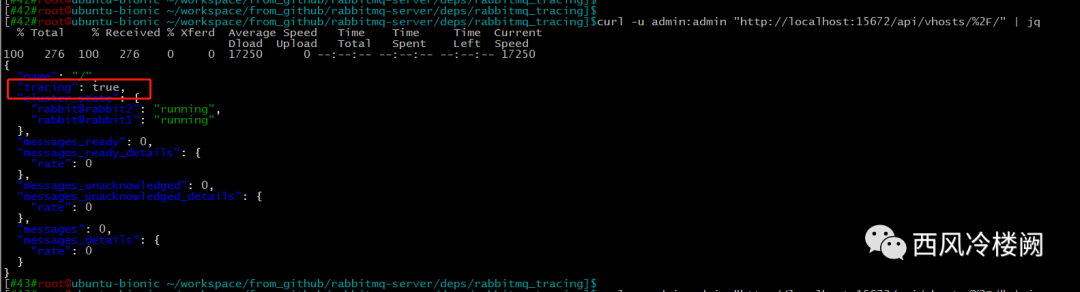
从 server 日志中也可以看出,创建 trace 规则后,会自动使能 tracing 功能

确认创建 trace 规则后,还有哪些变化
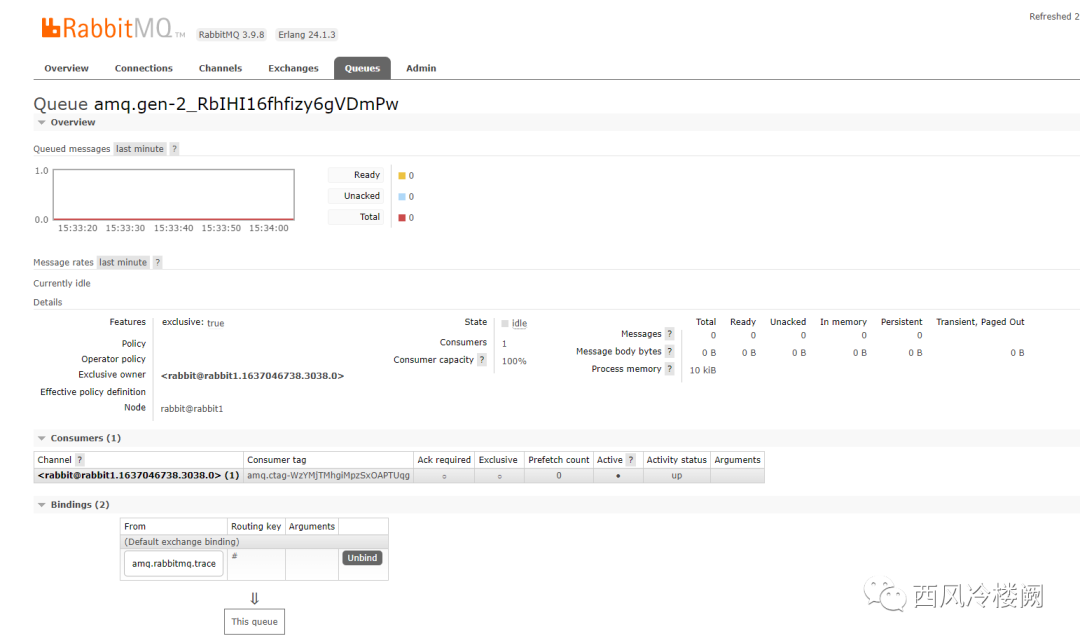
会自动创建一个独占 queue ,并绑定到 amq.rabbitmq.trace 这个 exchange 上
会自动创建一个特殊的 consumer ,从上面的独占 queue 中消费
会自动创建一个 trace log 文件
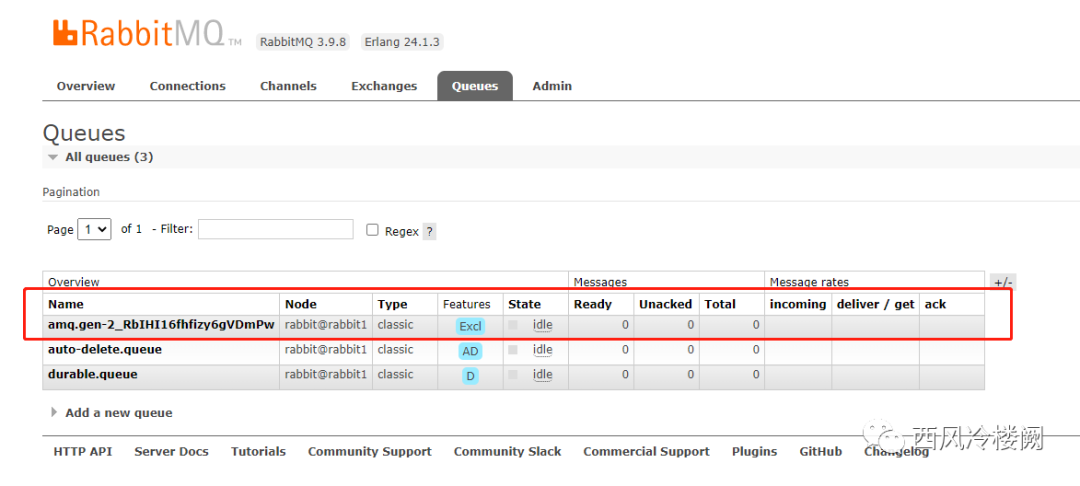
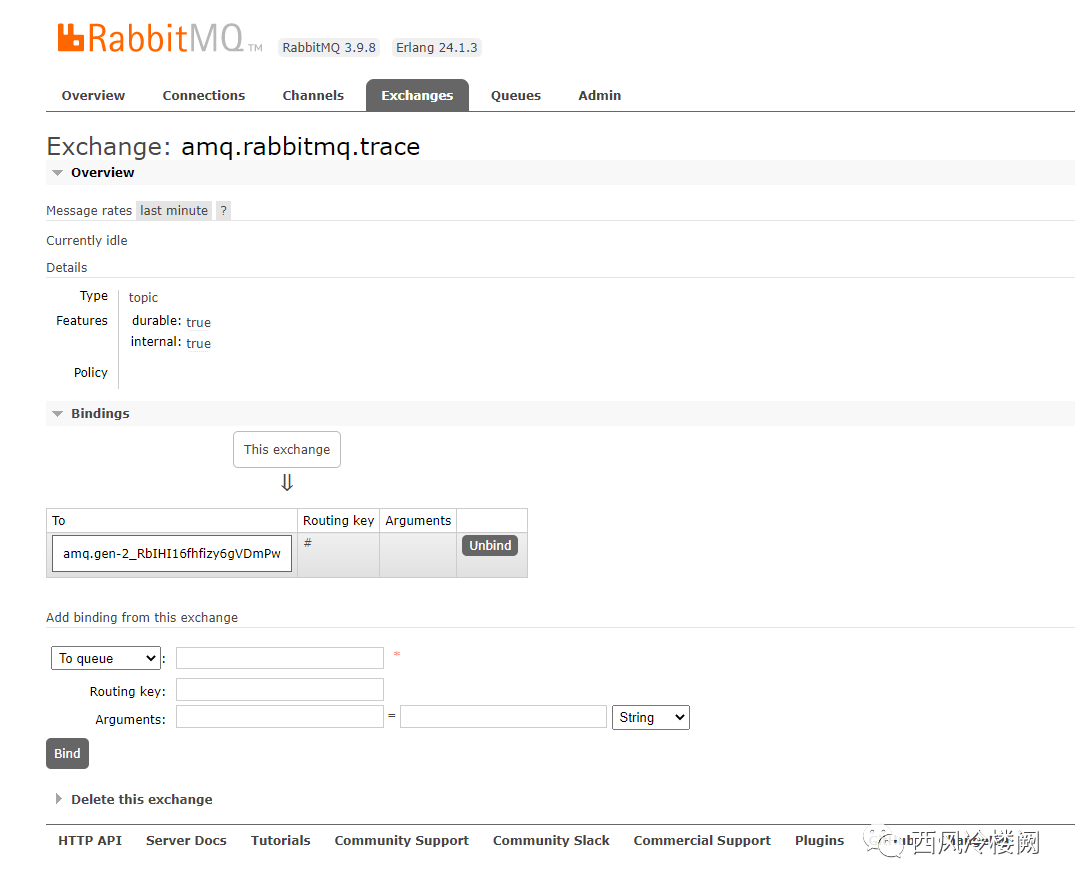
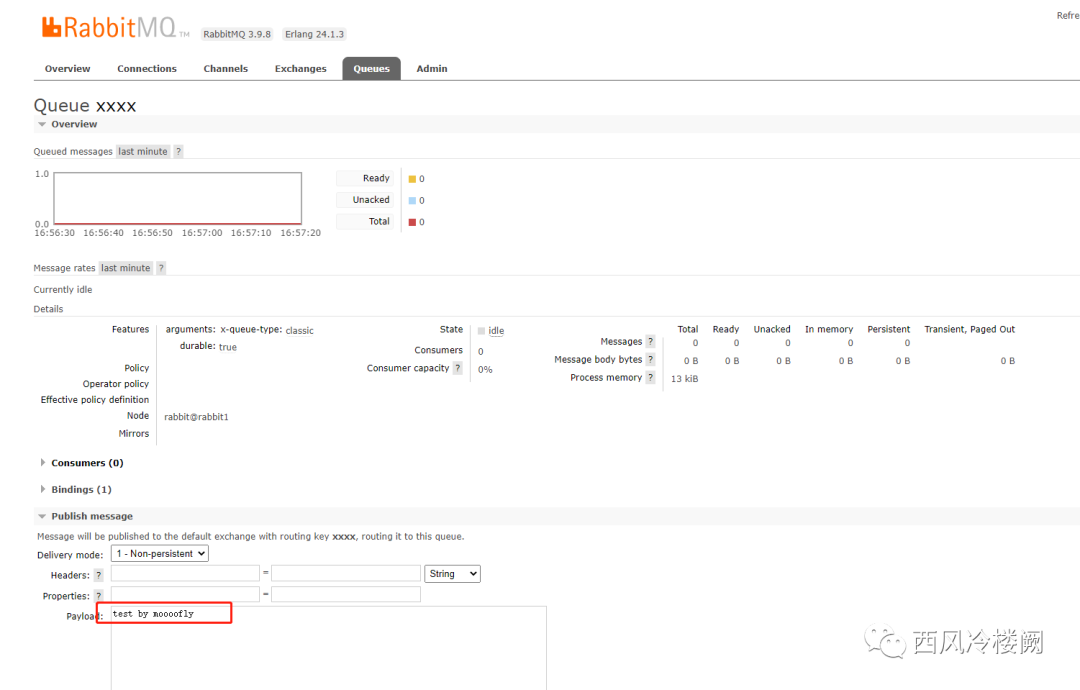
手动创建一个名为 xxxx 的测试 queue ,但不做任何 bind 操作,也不为其创建消费者
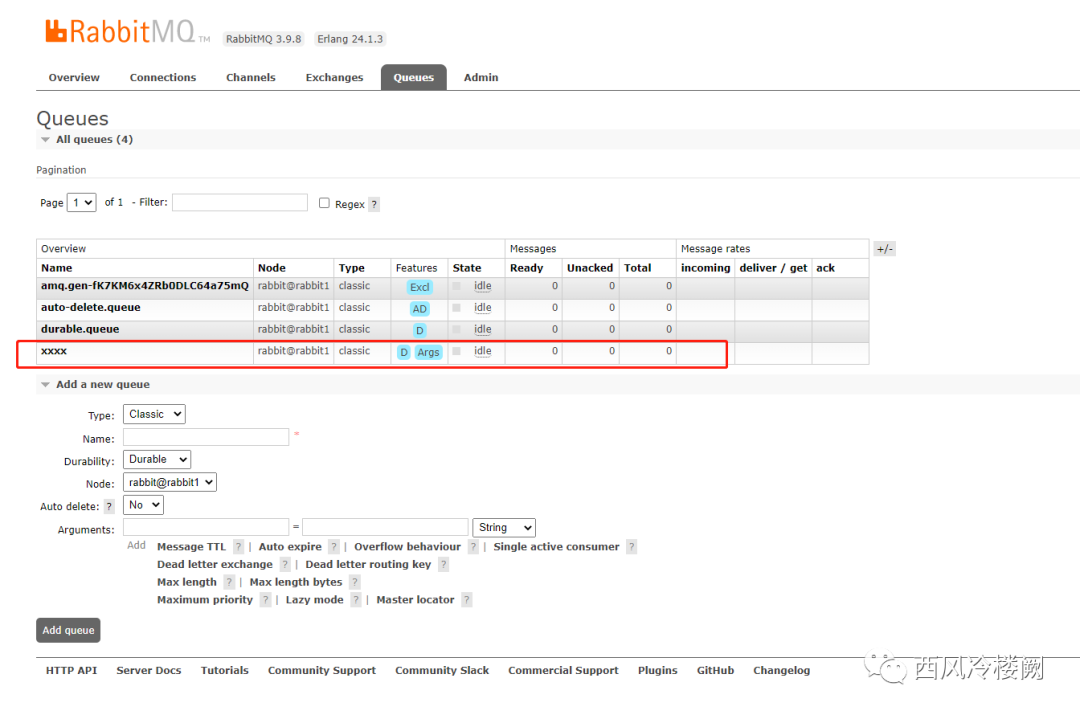
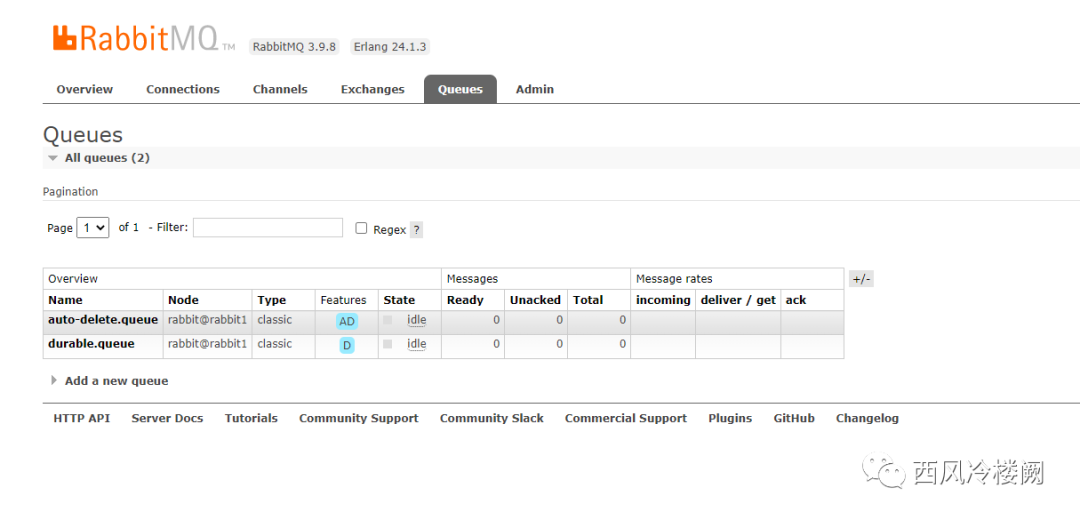
该 queue 状态如图所示
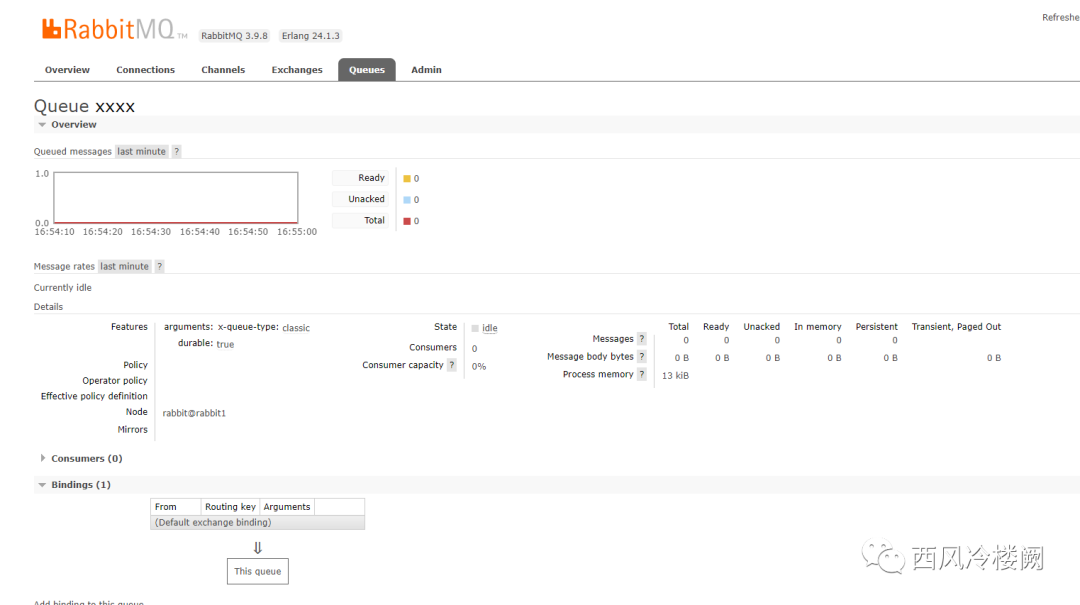
直接在管理页面上为该 queue 创建 trace 规则,可以看到,同样会像上面一样创建出所有的东西
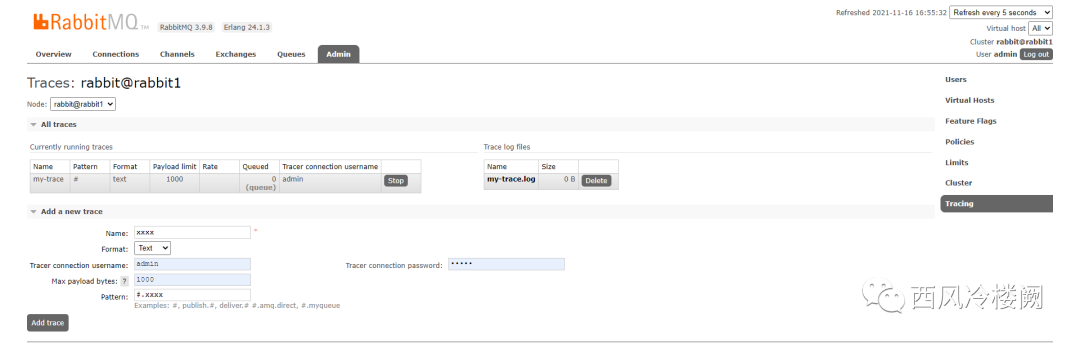
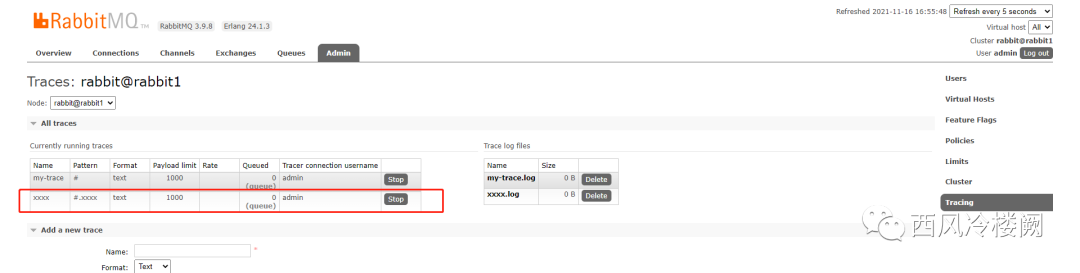
手动发消息到 xxxx queue 中测试 tracing 功能
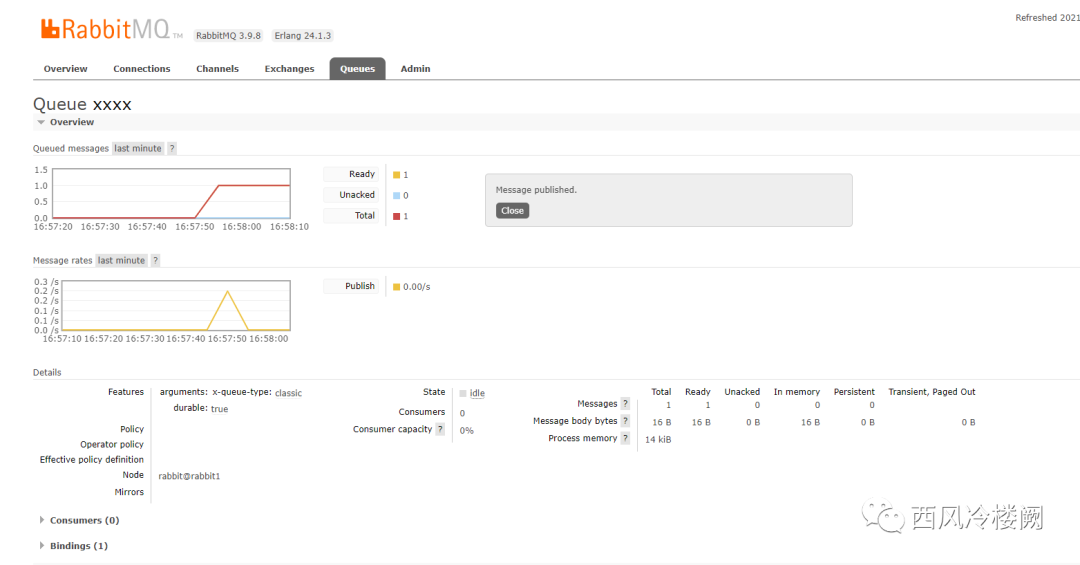
可以发现,trace 日志内容有了更新(这里由于 Pattern 配置的原因,trace log 仅被写入到了 my-trace.log 中)
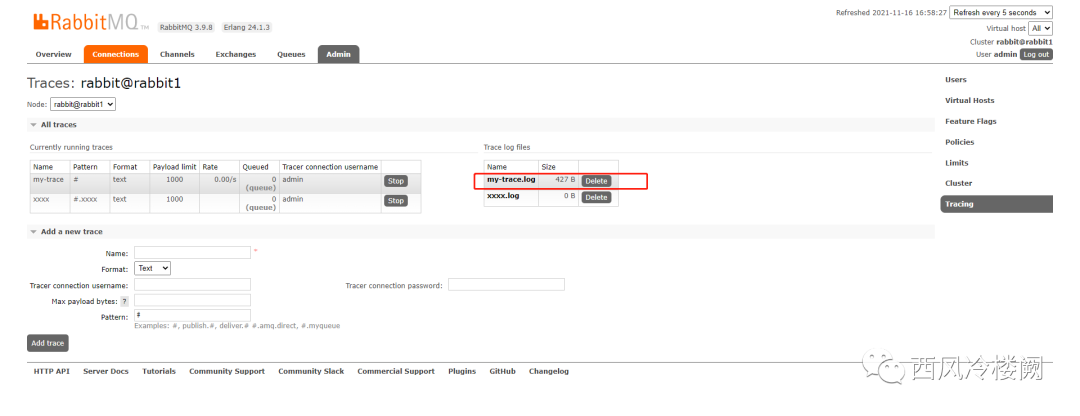
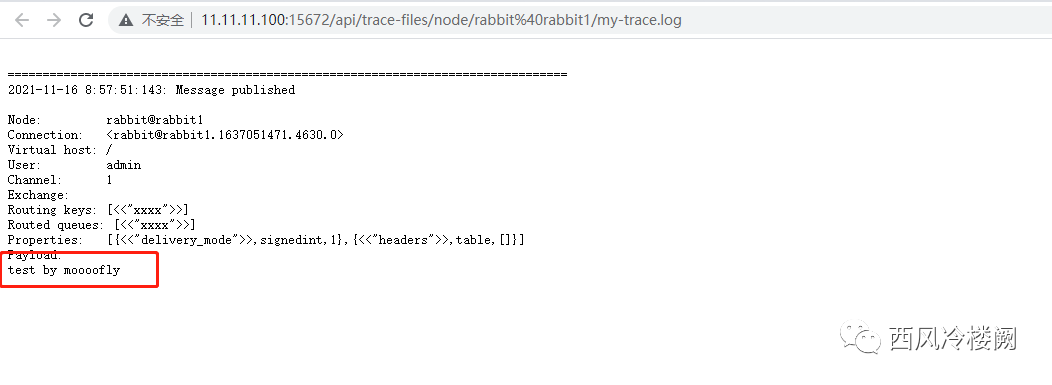
结论
折腾了这么多,结论如下
针对 tracing 功能的使用,其实完全可以跳过 firehose 这个点,这样就可以避免使用 rabbitmqctl 命令(该命令要求目标 node 必须处于 running 状态)
当基于 rabbitmq-plugins 命令(或 enabled_plugins 配置文件)使能插件后,后续可以直接通过 HTTP API 达成“在创建 trace 规则的时候自动使能 tracing 功能”和“在删除最后一个 trace 规则的时候自动去使能 tracing 规则”的效果
创建 trace 规则的动作,不应该放入 RabbitMQ 的启动脚本之中,更合理的实现,应该是有一个外部的服务,负责确认 RabbitMQ 是否已经处于正常运行状态,之后再完成各种规则的添加(已经其他需要完成的额外操作);
最后,官方已经非常明确的说了“tracing 功能不适合在生产环境中使用,可能导致 66% 左右的性能损耗”,然而,我们依然在这样用,并且不确定还会这样用多久,how pathetic ~
原创不易,添加关注,点赞,在看,分享是最好的支持, 谢谢~
更多精彩内容,欢迎关注微信公众号 西风冷楼阙

