前言
若有未涉及的 Redis 面试考点请后台留言联系他或者添加wx进行补充,赠人玫瑰,手有余香,感谢!
Memcache 和 Redis 区别 ⭐
支持简单数据类型;
不支持数据持久化存储;
不支持主从;
不支持分片;
Memcached是多线程,非阻塞 IO 复用的网络模型;
Redis 使用单线程的多路 IO 复用的网络模型;
速度快:10w QPS,数据存在内存,C 语言编写,线程模型为单线程;
持久化:对数据的更新将异步保存到磁盘上;
多种数据结构:String / Blobs / Bitmaps 位图、HashTables、LinkedLists、Sets、SortedSets、HyperLogLog 超小内存唯一值计数、GEO 地理信息定位;
支持多种编辑语言:Java、Php、Python、Ruby、Lua、Node 等;
功能丰富:发布订阅、Lua 脚本、事务、pipeline;
简单:2w3行代码量、不依赖外部库、单线程模型;
Redis Replication 支持主从复制;
Redis Sentinel(2.8)支持高可用,Redis Cluster(3.0)支持分布式;
Redis 性能
完全基于内存,绝大部分请求时纯粹的内存操作,执行效率高;
数据结构简单,对数据操作也简单;
采用单线程,单线程也能处理高并发请求,多核也可启动多实例;
使用多路 I/O 复用模型,非阻塞 I/O;
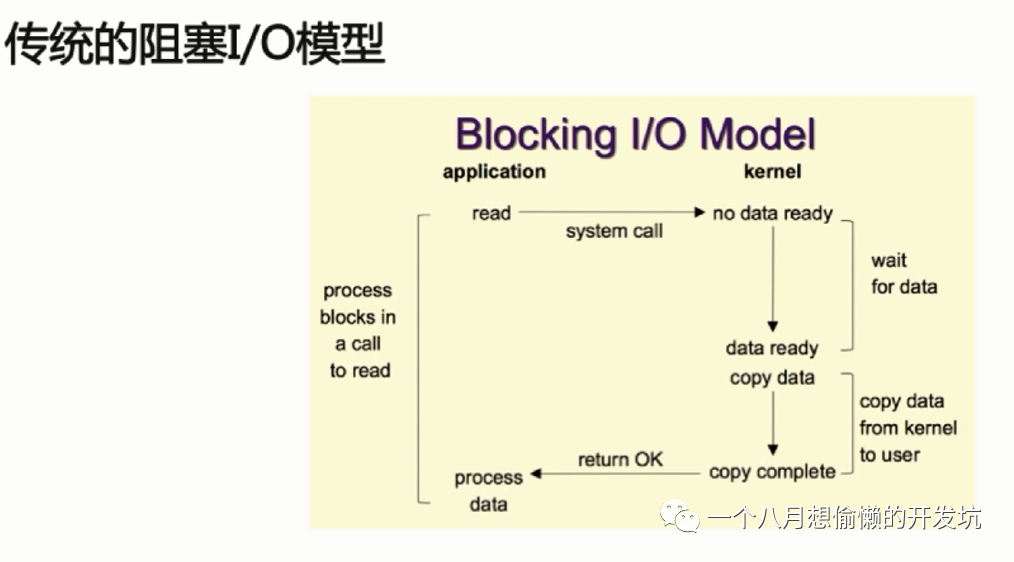
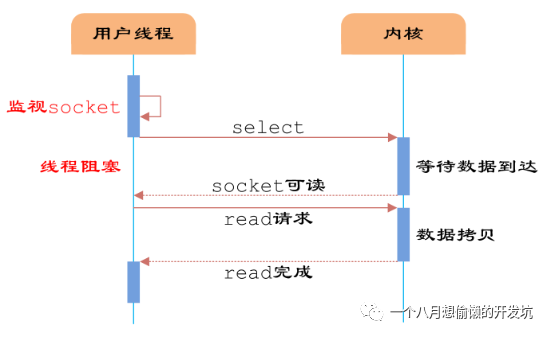
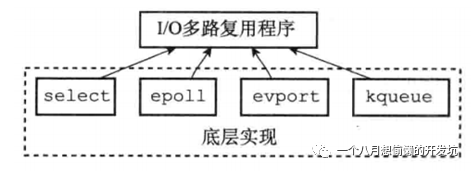
Redis 采用 I/O 多路复用函数,通过包装常见的
select,epoll,evport 和 kqueue 这些 I/O 多路复用函数库来实现的:
优先选择时间复杂度为 O(1) 的 I/O 多路复用函数作为底层实现;
以时间复杂度为 O(n) 的 select 作为保底;
基于 react 设计模式监听 I/O 事件;
Redis 通用命令 ⭐
keys 、keys [ pattern ]:遍历所有 key,O(n),不要在生产使用;
dbsize:计算 key 总数,O(1);
exists key:检查 key 是否存在,存在则返回1,O(1);
del key [ key ... ]:删除指定 key-value,成功返回1,O(1);
expire key seconds:key 在 seconds 秒后过期,O(1);
ttl key:查看 key 剩余过期时间,-2代表 key 已经不存在,-1代表 key 存在并且没有过期时间,O(1);
persist key:去掉 key 的过期时间,O(1);
type key:返回 key 的类型,O(1);
Redis 数据类型 ⭐
最基本的数据类型 key-value,value 不仅可以是 string,也可以是数字,也可以是一个 JSON 字符串,还可以是序列化对象,并且是二进制安全,最大能存储 512MB;
可用于常规计数,如微博数,粉丝数,分布式 Id 生成器等;
常用命令:set,get,decr,incr(原子操作),mget 等;
优点:编程简单,直观;缺点:可能存在序列化开销,内存占用较大,key 较为分散;
key - field - value,适合存储对象,如 user:1:info - age - 23、user:1:info - name - ronaldo、user:1:info - sex - 男;
特点:类似 Map 包含 Map 结构,field 不能相同,value 可以相同;
可用于存储用户信息,商品信息等;
常用命令:hget,hset,hgetall 等;
优点:直观,节省空间,支持部分更新;缺点:编程复杂,ttl 不好控制;
key - elements,如 user:1:message - a b c d e f,双向链表实现的列表,按照 string 元素插入顺序排序,可以将一个元素从列表的头部(左边)或者尾部(右边)插入或弹出;
特点:有序,可以重复,左右两边插入弹出;
可用于关注列表,粉丝列表,消息列表,下拉分页,时间轴 TimeLine 等;
常用命令:lpush,rpush,lpop,rpop,lrange 等;
Tips:
lrush + lpop = Stack;
lpush + rpop = Queue;
lpush + ltrim = Capped collection;
lpush + brpop = Message queue;
key - values,如 user:1:follow - it music his sports;
特点:无序,不可重复,支持集合间操作;
可用于共同关注,共同粉丝,共同喜好,标签,抽奖系统等;
常用命令:sadd,spop,smembers,sunion 等;
Tips:
sadd = Tagging;
spop / srandmember = Random item;
sadd + sinter = Social Graph;
key - score - value,如 user:ranking - 1 - kris、user:ranking - 91 - mike、user:ranking - 200 - frank;
特点:有序,不可重复,通过 score 来为集合中的成员进行从小到大的排序;
可用于排行榜,弹幕消息,在线用户列表等;
常用命令:zadd,zrange,zrem,zcard 等;
如字符串 big 对应的二进制,对位进行操作; 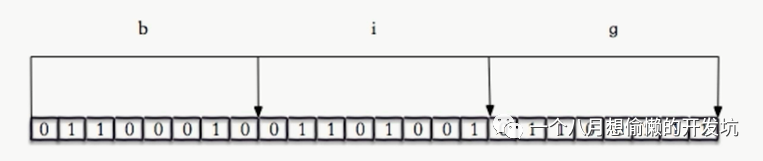

setbit key offset value:给位图指定索引设置值; getbit key offset:获取位图指定索引的值;
bitcount key [ start end ]:获取位图指定范围(start 到 end,单位为字节,如果不指定就获取全部)位值为1的个数;
bitop op destKey [ key... ]:做多个 Bitmap 的 and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存在 destKey 中;
bitpos key targetBit [ start ] [ end ]:计算位图指定范围(start 到 end,单位为字节,如果不指定就是获取全部)第一个偏移量对应的值等于 targetBit 的位置;
可用于独立用户统计(1亿用户,每日5千万独立访问),如 set 操作一个月需要6G,Bitmap 操作一个月需要375MB;
基于 HyperLogLog 算法:极小空间完成独立数量统计;
本质还是字符串;
三个命令:
pfadd key element [ element... ]:向 hyperloglog 添加元素;
pfcount key [ key... ]:计算 hyperloglog 的独立总数;
pfmerge destKey sourceKey [ sourceKey... ]:合并多个 hyperloglog;
每天百万独立用户统计的内存消耗:1天=15KB,1个月=450KB,1年=5MB;
使用经验:
容错率:0.81%;
是否需要单条数据;
是否需要很小内存解决问题;
GEO(地理信息定位):存储经纬度,计算两地距离,范围计算等;
使用场景:类似微信摇一摇、查询范围距离内数据;
geo key longitude latitude member [ longitude latitude member... ]:增加地理位置信息,如 geoadd cities:locations 116.28 39.55 bejing;
geopos key member [ member... ]:获取地理位置信息;
geodist key member1 member2 [ unit ]:获取两个地理位置的距离,unit:m(米)、km(千米)、mi(英里)、ft(尺);
Redis 3.2+ 提供 GEO,本质是 zset;
没有删除 API:zrem key member;
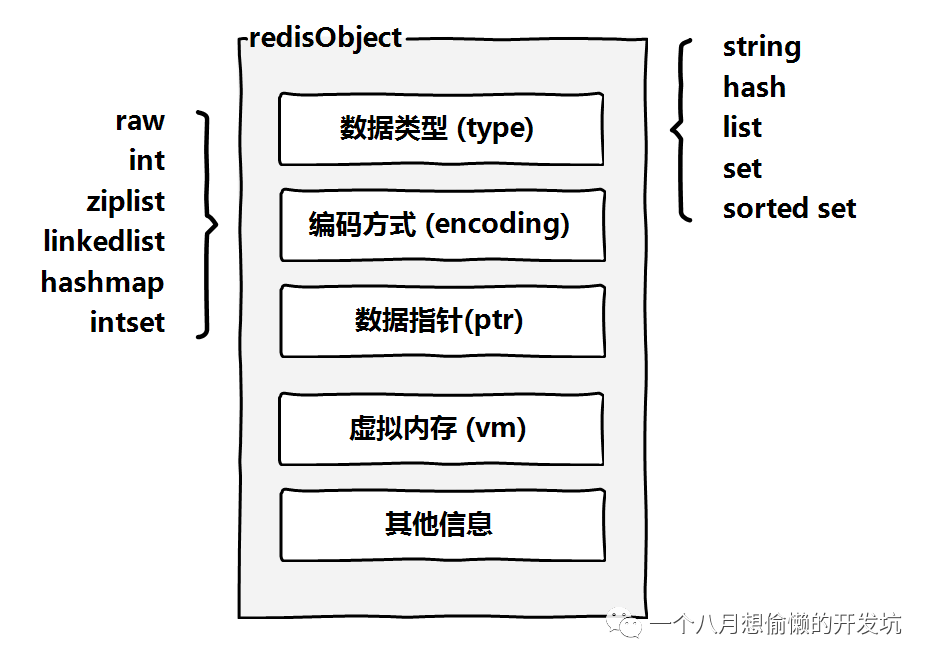
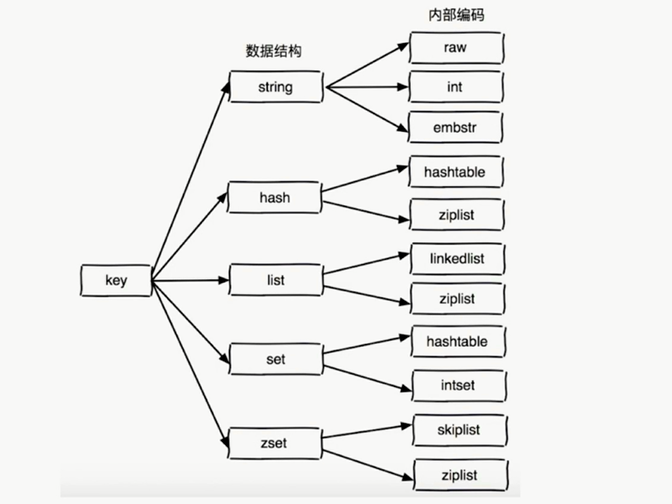
Redis 数据结构和内部编码
Redis pipeline ⭐
pipeline
又称流水线/管道,对命令进行批量打包,解决 n 次操作的网络时间,针对批量操作命令,一次 pipeline(n 条命令)= 1次网络时间 + n 次命令时间;注意:Redis 命令时间是微妙级别,pipeline 每次发送次数要控制(网络);
for(int i = 0; i < 100; i++) {Pipeline pipeline = jedis.pipelined();for(int j = i * 100; j < (i+1) * 100; j++) {pipeline.hset("hashkey:" + j, "field" + j, "value" + j);}pipeline.syncAndReturnAll();}
原生:1w hset = 50s,原子命令;
pipeline:1w hset = 0.7s,非原子命令;
注意每次 pipeline 携带数据量;
pipeline 每次只能作用在一个 Redis 节点上;
原生操作和 pipeline 区别;
Redis 慢查询 ⭐
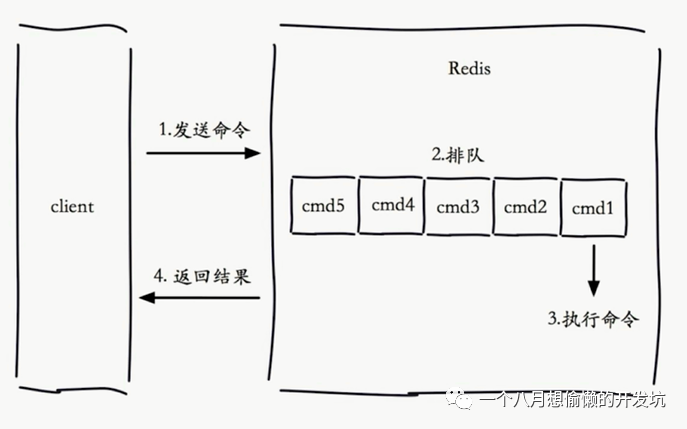
慢查询发生在第3个阶段; 客户端超时不一定慢查询,但慢查询是客户端超时的一个可能因素;
slowlog-max-len:当命令被标记为慢查询,则进入一个先进先出的慢查询队列,该参数设置固定长度,将命令保存在内存内,默认值是128; 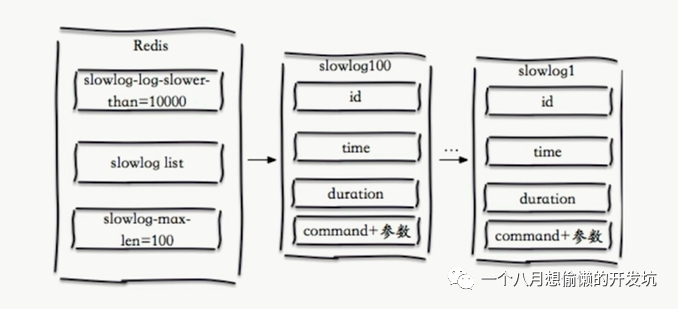
slowlog-log-slower-than:命令被标记为慢查询的阈值(微妙),slowlog-log-slower-than=0 时,记录所有命令;<0 时不记录任何命令,默认值是10秒; 支持动态配置,config set ...;
slowlog get [n]:获取慢查询队列;
slowlog len:获取慢查询队列长度;
slowlog reset:清空慢查询队列;
slowlog-max-len 不要设置过大,默认10ms,通常设置1ms;
slowlog-log-slower-than 不要设置过小,通常设置1000左右;
理解命令生命周期;
定期持久化慢查询;
Redis 分布式锁 ⭐
互斥性;
安全性;
死锁;
容错;
setnx、getset(原子性)、expire、del;
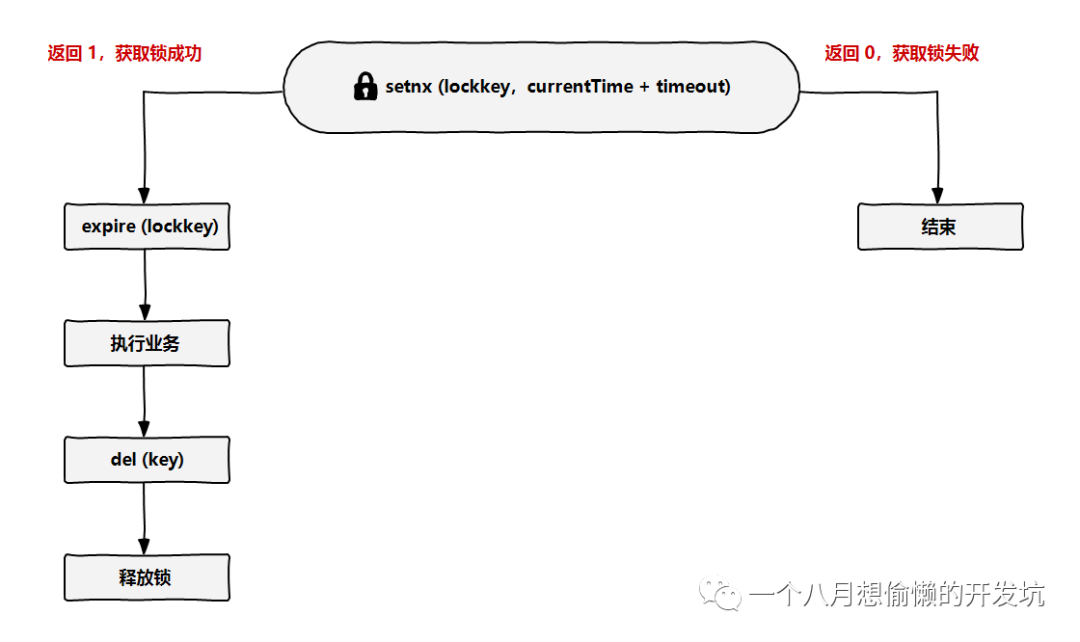
双重防死锁机制(被动过期和主动检查过期时间);
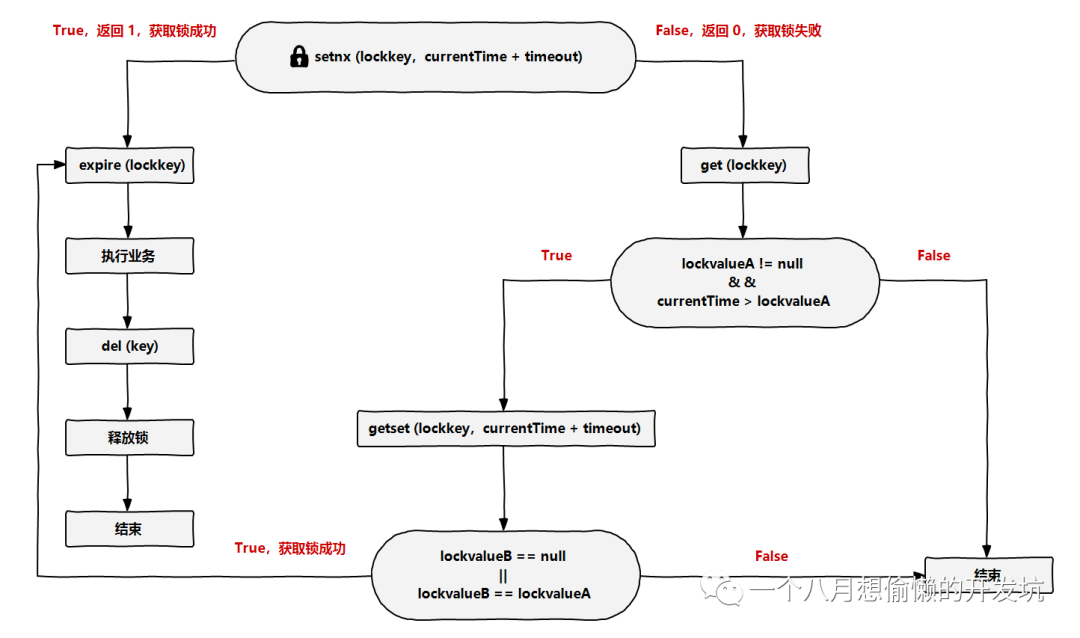
Redis 官方站提出了一种权威的基于 Redis 实现分布式锁的 Redlock: 安全特性:互斥访问,即永远只有一个 client 能拿到锁;
避免死锁:最终 client 都可能拿到锁,不会出现死锁的情况,即使原本锁住某资源的 client crash 了或者出现了网络分区;
容错性:只要大部分 Redis 节点存活就可以正常提供服务; Redis 2.6.2 后 setnx key value [Ex seconds] [PX milliseconds] [NX|XX] 是原子性的:
时间复杂度:O(1);
EX second:设置键的过期时间为 second 秒;
PX millisecond:设置键的过期时间为 millisecond 毫秒;
NX:只在键不存在时,才对键进行设置操作;
XX:只在键已存在时,才对键进行设置操作;
SET 操作成功完成时,返回 OK,否则返回 nil;
集中过期,由于清除大量的 key 很耗时,会出现短暂的卡顿现象;
解决方案:在设置 key 的过期时间时,给每个 key 加上随机值;
Redis 异步队列 ⭐
缺点:没有等待队列里有值就直接去消费;
弥补:可以通过在应用层引入 Sleep 机制去调用 LPOP 重试;
优化:BLPOP [key ...] timeout;
阻塞直到队列有消息或超时;
缺点:只能供一个消费者消费;
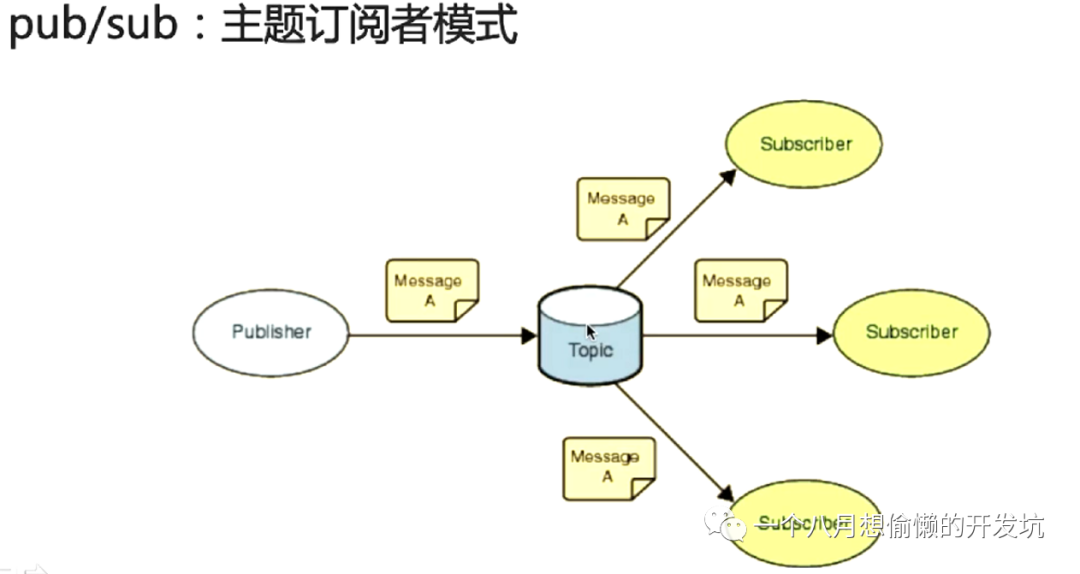
Redis 发布订阅 ⭐
发送者(pub)发送消息,订阅者(sub)接收消息;
订阅者可以订阅任意数量的频道;
publish channel message 发布消息,subscribe / unsubscribe channel [ channel … ] 订阅 / 退订消息;
psubscribe / punsubscribe [ pattern... ]:订阅 / 退订模式;
pubsub channels:列出至少有一个订阅者的频道;
pubsub numsub [ channel... ]:列出给定频道的订阅者数量;
pubsub numpat:列出被订阅模式的数量;
缺点:消息的发布时无状态的,无法保证可达,无法堆积消息,存在丢失情况;
Redis 事务
事务执行流程
开始事务(multi);
命令入队(操作命令会返回 queue);
执行事务(exec 并返回操作命令结果的数组);
原子性:在使用 multi 开启了一个事务之后,如果因为断线而没有成功执行 exec,那么事务中的所有命令都不会被执行;如果成功执行 exec,那么事务中的所有命令都会被执行;Redis 不支持事务的回滚机制,即使事务队列中的某个命令在执行期间出现错误,整个事务也会继续执行下去,直到将事务队列中的所有命令都执行完毕为止;不支持事务回滚是因为作者认为,Redis 事务的执行时错误通常都是编程错误造成的,这种错误通常只会出现在开发环境中,而很少会在实际的生产环境中出现,且 Redis 追求简单高效,因此生产环境不会出现错误命令而导致非原子性操作;
一致性:Redis 通过谨慎的错误检测和简单的设计来保证事务一致性;
隔离性:Redis 使用单线程的方式来执行事务(以及事务队列中的命令),并且服务器保证,在执行事务期间不会对事物进行中断,因此,Redis 的事务总是以串行的方式运行的,并且事务也总是具有隔离性的;
持久性:因为 Redis 事务不过是简单的用队列包裹起来一组 Redis 命令,没有为事务提供任何额外的持久化功能,所以 Redis 事务的耐久性由 Redis 使用的持久化模式(默认 RDB)决定;
multi:标记一个事务的开始 , 该命令返回 OK 提示信息,Redis 不支持事务嵌套,执行多次 multi 命令和执行一次是相同的效果,嵌套执行 multi 命令时,Redis 只是返回错误提示信息;
exec:标记一个事务的执行,事务中的命令序列将被执行(或者不被执行,比如乐观锁失败等),该命令将返回响应数组,其内容对应事务中的命令执行结果;
watch:开始执行乐观锁(Redis 事务提供 check-and-set (CAS)行为),该命令的参数是 key(可以有多个),Redis 将执行 watch 命令的客户端对象和 key 进行关联,如果其他客户端修改了这些 key,则执行 watch 命令的客户端将被设置乐观锁失败的标志,那么整个事务都会被取消, exec 返回 nil-reply 来表示事务已经失败;
该命令必须在事务开始前执行,即在执行 MULTI 命令前执行 WATCH 命令,否则执行无效,并返回错误提示信息;
unwatch:将取消当前客户端对象的乐观锁 key,该客户端对象的事务提交将变成无条件执行;
discard:将结束事务,事务队列会被清空,并且客户端会从事务状态中退出;
注意:exec 命令和 discard 命令结束事务时,会调用 unwatch 命令,取消该客户端对象上所有的乐观锁 key;
错误情况一:事务在执行 exec 之前,入队的命令可能会出错,比如,命令可能会产生语法错误(参数数量错误,参数名错误,等等),或者其他更严重的错误,比如内存不足(如果服务器使用 maxmemory 设置了最大内存限制的话);
情况一处理:
服务器端:在 Redis 2.6.5 以前,Redis 只执行事务中那些入队成功的命令,而忽略那些入队失败的命令;从 Redis 2.6.5 开始,服务器会对命令入队失败的情况进行记录,并在客户端调用 exec 命令时,拒绝执行并自动放弃这个事务;
客户端(Jedis):客户端以前的做法是检查命令入队所得的返回值,如果命令入队时返回 queue,那么入队成功,否则就是入队失败,那么大部分客户端都会停止并取消这个事务;
错误情况二:命令可能在 exec 调用之后失败,比如,事务中的命令可能处理了错误类型的键,比如将列表命令用在了字符串键上面等;
情况二处理:在 exec 命令执行之后所产生的错误,并没有对它们进行特别处理:即使事务中有某个 / 某些命令在执行时产生了错误,事务中的其他命令仍然会继续执行(开发环境才会出现这种错误);
Redis 中的脚本本身就是一种事务,所以任何在事务里可以完成的事, 在脚本里面也能完成,并且 使用脚本要更简单,速度更快;
因为脚本功能是 Redis 2.6 才引入的,而事务功能则更早之前就存在了,所以 Redis 才会同时存在两种处理事务的方法;
不过我们并不打算在短时间内就移除事务功能,因为事务提供了一种即使不使用脚本,也可以避免竞争条件的方法,而且事务本身的实现并不复杂;
海量数据里查询某个固定前缀的 key ⭐
摸清数据规模,即问清边界;
keys pattern:查找所有复合给定模式 pattern 的 key;
keys 指令一次性返回所有匹配的 key;
键的数量过大会使服务卡顿;
scan cursor [MATCH pattern] [COUNT count]:
基于游标的迭代器,需要基于上一次的游标延续之前的迭代过程;
以 0 作为游标开始一次新的迭代,直到命令返回游标 0 完成一次遍历;
不保证每次执行都返回某个给定数量的元素,支持模糊查询;
一次返回的数量不可控,只能是大概率符合 count 参数;
流言协议 Gossip
每个节点都随机地与对方通信,最终所有节点的状态达成一致;
种子节点定期随机向其他节点发送节点列表以及需要传播的消息;
不保证信息一定会传递给所有节点,但是最终会趋于一致;
(完)
识别二维码,关注我,不定时更