前言
若有未涉及的 Spring Cloud 面试考点请后台留言联系他或者添加wx进行补充,赠人玫瑰,手有余香,感谢!(本文内容基于 Spring Cloud Greenwish SR2 版本)
微服务
一系列微小的服务共同组成;
每个服务运行在自己的进程中;
每个服务为独立的业务开发;
服务间通信采用轻量级通信机制(通常用 HTTP 资源 API);
独立部署;
服务共用一个最小型的集中式的管理,服务可用不同语言开发,使用不同的数据存储技术;
单个服务更易于开发、维护;
单个微服务启动较快;
局部修改容易部署;
技术栈不受限;
按需伸缩;
运维要求高;
分布式固有的复杂性;
重复劳动;
领域驱动设计(Domain Driven Design)
面向对象(by name. / by verb.)
心得:职责划分和通用性划分;
分布式定义
旨在支持应用程序和服务的开发,可以利用物理架构,由多个自治的处理元素,不共享主内存,但通过网络发送消息合作;
Spring Cloud ⭐
Spring Cloud Eureka ⭐
服务注册发现,由 Eureka Server 注册中心和
Eureka Client 服务注册组成,支持心跳机制、健康检查、负载均衡等;
当 Eureka Client(服务提供者)向 Eureka Server 注册时,它提供自身的元数据 ,比如 IP 地址、端口,运行状况指示符 URL,主页等;
Eureka Client 会每隔30秒(默认情况下)发送一次心跳来续约;通过续约来告知 Eureka Server 该 Eureka Client 仍然存在,没有出现问题;正常情况下,如果 Eureka Server 在90秒没有收到 Eureka Client 的续约,它会将实例从其注册表中删除;
Eureka Client 从 Eureka Server 获取注册表信息,并将其缓存在本地;Eureka Client 会使用该信息查找其他服务,从而进行远程调用;该注册列表信息定期(每30秒钟)更新一次;每次返回注册列表信息如果与 Eureka Client 的缓存信息不同,Eureka Client 自动处理;Eureka Client 和 Eureka Server 可以使用 JSON / XML 格式进行通讯;
Eureka Client 在程序关闭时向 Eureka Server 发送取消请求;发送请求后,该客户端实例信息将从 Eureka Server 的实例注册表中删除;该下线请求不会自动完成,它需要调用以下内容:
DiscoveryManager.getInstance().shutdownComponent();
在默认的情况下,当 Eureka Client 连续90秒(3个续约周期)没有向 Eureka Server 发送服务续约,即心跳, Eureka Server 会将该服务实例从服务注册列表删除,即服务剔除;
Eureka Server 互相注册,Eureka Client 配置所有的 Eureka Server 连接,逗号隔开;
Eureka 通过心跳来判断服务健康,同时会定期删除超过90秒没有发送心跳的服务;导致 Eureka Server 接收不到心跳包的可能:一是微服务自身的原因(个别服务出现故障),二是微服务与 Eureka 之间的网络故障(大面积故障);
Eureka 设置了一个阀值,当判断挂掉的服务的数量超过阀值时,Eureka Server 认为很大程度上出现了网络故障,将不再剔除心跳过期的服务,会将所有好的数据(有效服务数据)和坏的数据(无效服务数据)都返回给 Eureka Client;当网络故障恢复后,Eureka Server 会退出服务保护模式;
通过全局配置文件
(eureka.server.enableSelfPreservation)来关闭服务保护模式,商业项目中不推荐关闭服务保护,因为网络不可靠很容易造成网络波动、延迟、断线的可能,如果关闭了,可能导致大量的服务反复注册、删除、再注册,导致效率降低;
在全局配置文件中配置
(endpoints.shutdown.enabled),通过 HTTP POST 请求的方式(http://ip:port/shutdown),通知 Eureka Client 优雅停服,这个请求一旦发送到 Eureka Client,那么 Eureka Client 会发送一个 shutdown 请求到 Eureka Server,Eureka Server 接收到这个 shutdown 请求后,会在服务列表中标记这个服务的状态为 down,同时 Eureka Client 应用自动关闭;
如果使用了优雅停服,则不需要再关闭
Eureka Server 的服务保护模式;
Spring Cloud Ribbon ⭐
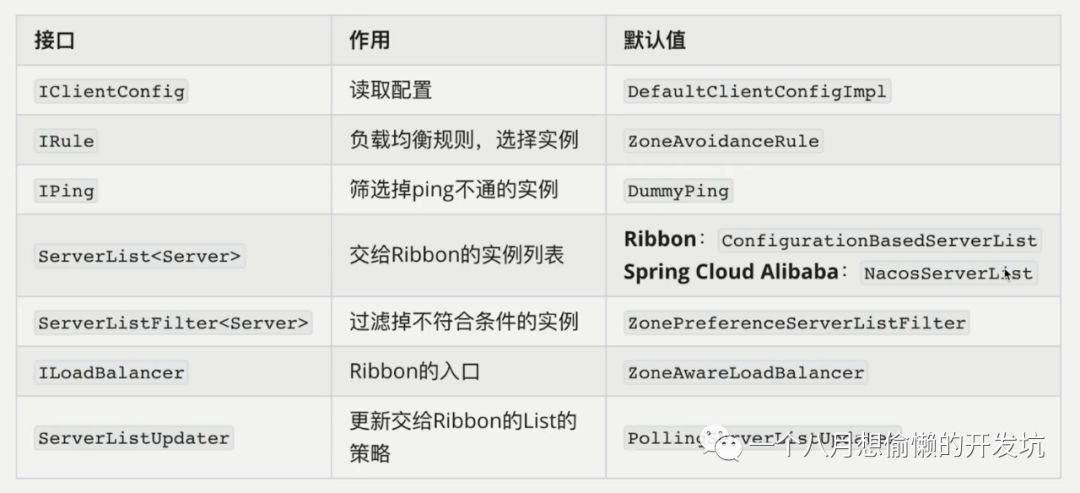
服务发现:LoadBalancerClient
(RibbonLoadBalancerClient 是实现类)在初始化的时候(execute 方法),会通过 ILoadBalance(BaseLoadBalancer 是实现类)向 Eureka 注册中心获取服务注册列表;
服务选择规则:通过 LoadBalancerInterceptor 进行拦截请求,并根据具体的 IRule 实现来进行负载均衡,默认轮询算法,并且可以更换默认的负载均衡算法,只需要在配置文件中做出修改;
RandomRule 随机策略;
RoundRobinRule 轮询策略;
WeightedResponseTimeRule 加权策略;
BestAvailableRule 请求数最少策略; 服务监听:每10s一次向 EurekaClient 发送 Ping,来判断服务的可用性,如果服务的可用性发生了改变或者服务数量和之前的不一致,则从注册中心更新或者重新拉取;

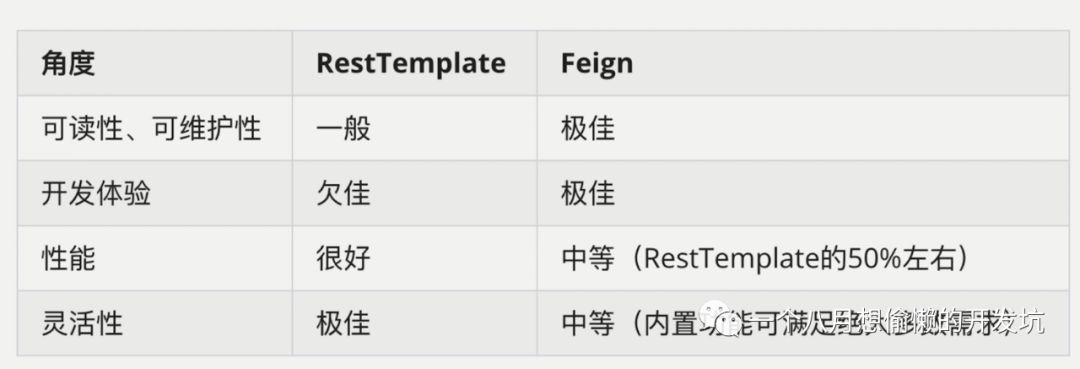
Spring Cloud Feign ⭐
可插拔的注解支持,包括 Feign 注解和 JAX-RS 注解;
支持可插拔的 HTTP 编码器和解码器;
支持 Hystrix 和它的 Fallback;
支持Ribbon的负载均衡;
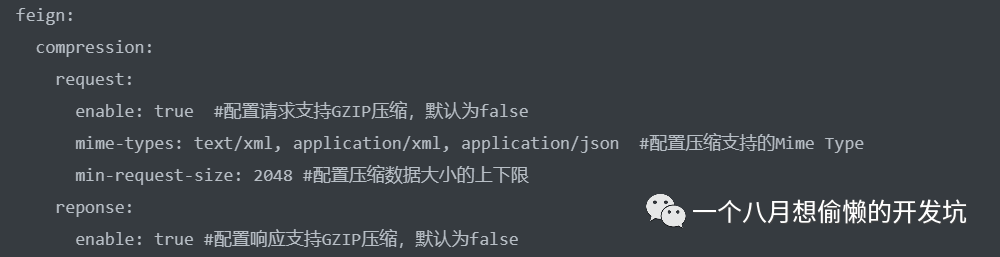
支持HTTP请求和响应的压缩;
启动时,程序会进行包扫描,扫描所有包下所有 @FeignClient 注解的类,并将这些类注入到 Spring IOC 容器中,当定义的 Feign 中的接口被调用时,通过 JDK 动态代理来生成 RequestTemplate;
RequestTemplate 中包含请求的所有信息,如请求参数,请求 URL 等;
RequestTemplate 生产 Request,然后将 Request 交给 Client 处理,这个 Client 默认是 JDK HTTPUrlConnection,也可以是 OKhttp、Apache HTTPClient 等;
最后 Client 封装成 LoadBaLanceClient,结合 Ribbon 负载均衡地发起调用;

代码配置;
属性配置文件;

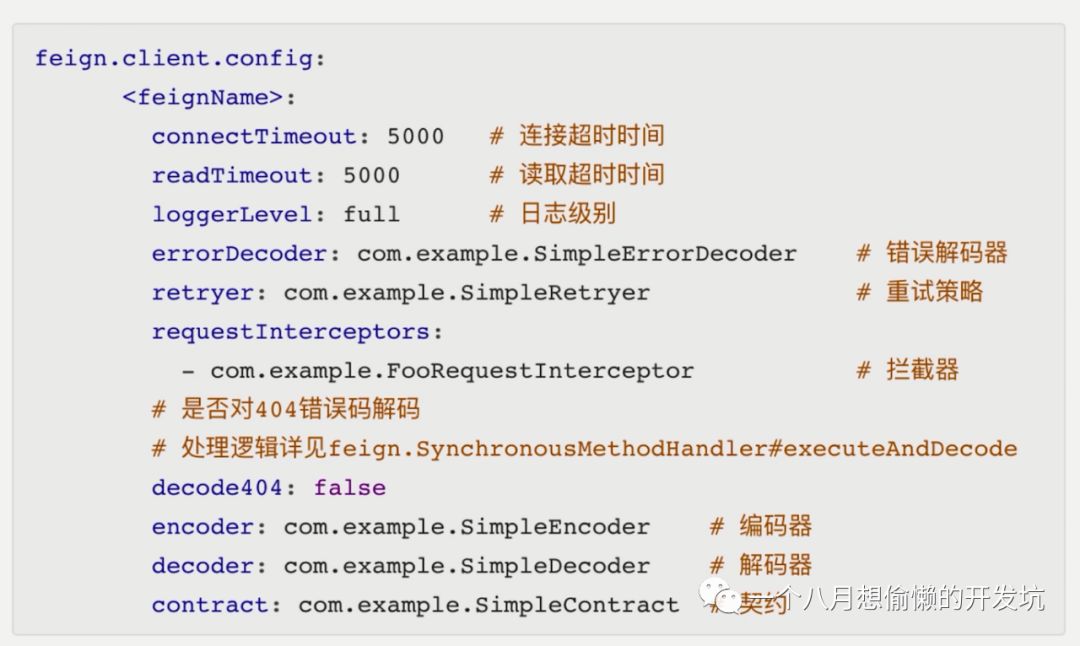
Spring Cloud Feign 优化(加分项)⭐
优化:生产日志级别设置:BASIC;
NONE(默认值):不记录任何日志;
BASIC:仅记录请求方法、URL、响应状态代码以及执行时间;
HEADERS:记录请求和响应的 header;
FULL:记录请求和响应的 header、body 和元数据;
方法一:通过 Feign 的 RequestInterceptor 中的 apply 方法,统一拦截转换处理 Feign 中的 GET 方法多参数;
方法二:Feign 接口方法入参使用 @SpringQueryMap User user;
方法三:Feign 接口方法入参使用
@RequestParam("id") Long id, @RequestParam("username") String username;
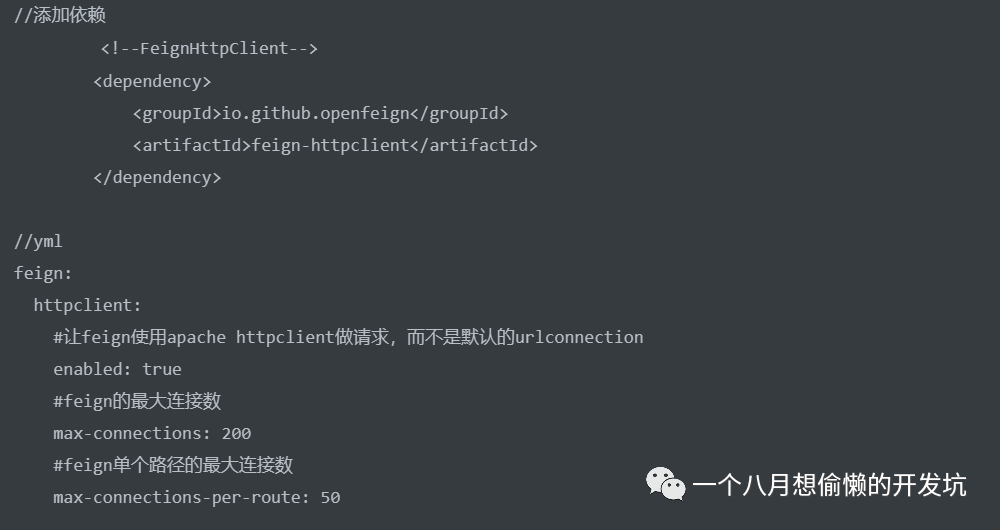

如果开启了 Hystrix,此时 Ribbon 的超时时间和 Hystrix 的超时时间的结合就是 Feign 的超时时间,当 Hystrix 发生了超时异常时,可以如下配置调整 Hystrix 的超时时间:
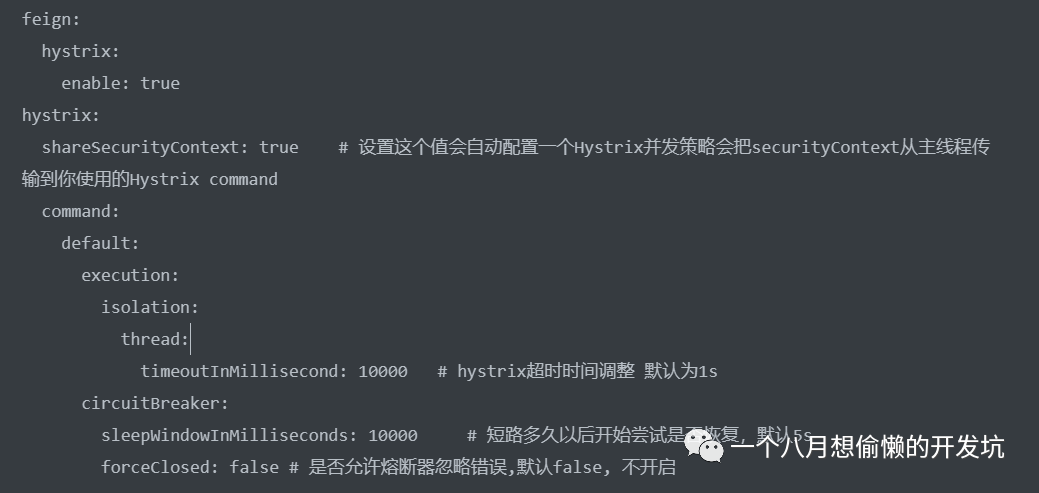
方法一:将 Hystrix 的超时时间尽量修改得长一点(有时 Feign 进行文件上传的时候,如果时间太短,可能文件还没有上传完就超时异常了,这个配置很有必要);
方法二:禁用 Hystirx 超时时间 :
hystrix.command.default.execution.timeout.enabled=false;
方法三:Feign 直接禁用 Hystrix(不推荐) : feign.hystrix.enabled=false;
方法四:Ribbon 配置饥饿加载(最佳):ribbon.eager-load.enabled: true,支持配置 eager load 实现在启动时就初始化 Ribbon 相关类;
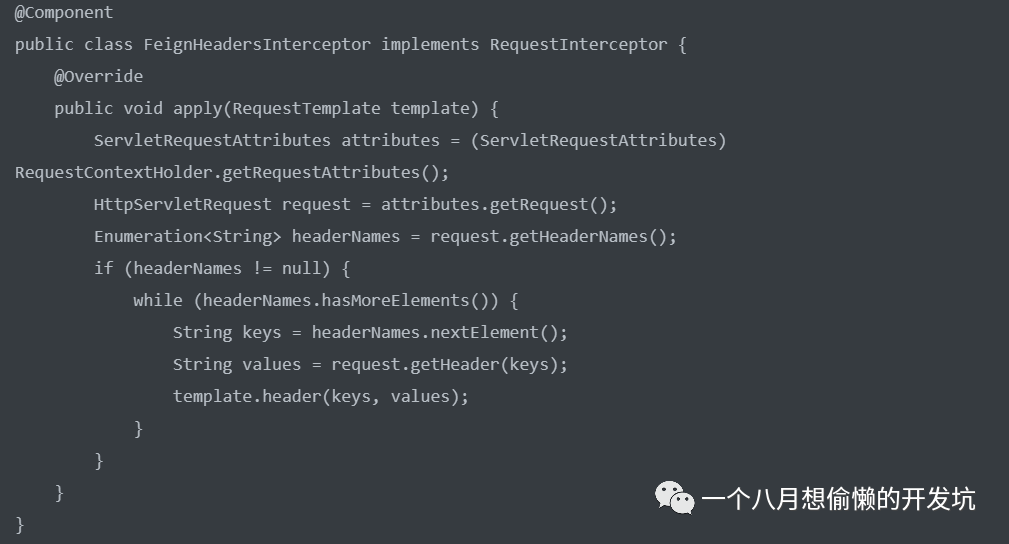
默认情况下,当通过 Feign 调用其他的服务时,Feign 不会带上当前请求的 headers 信息的;
Feign 本身已经整合 Hystrix,可直接使用
@FeignClient(value = "microservice-provider-user", fallback = XXX.class) 来指定 fallback 类,fallback 类继承 @FeignClient 所标注的接口即可;
但如需使用 Hystrix Stream 进行监控,默认情况下,访问
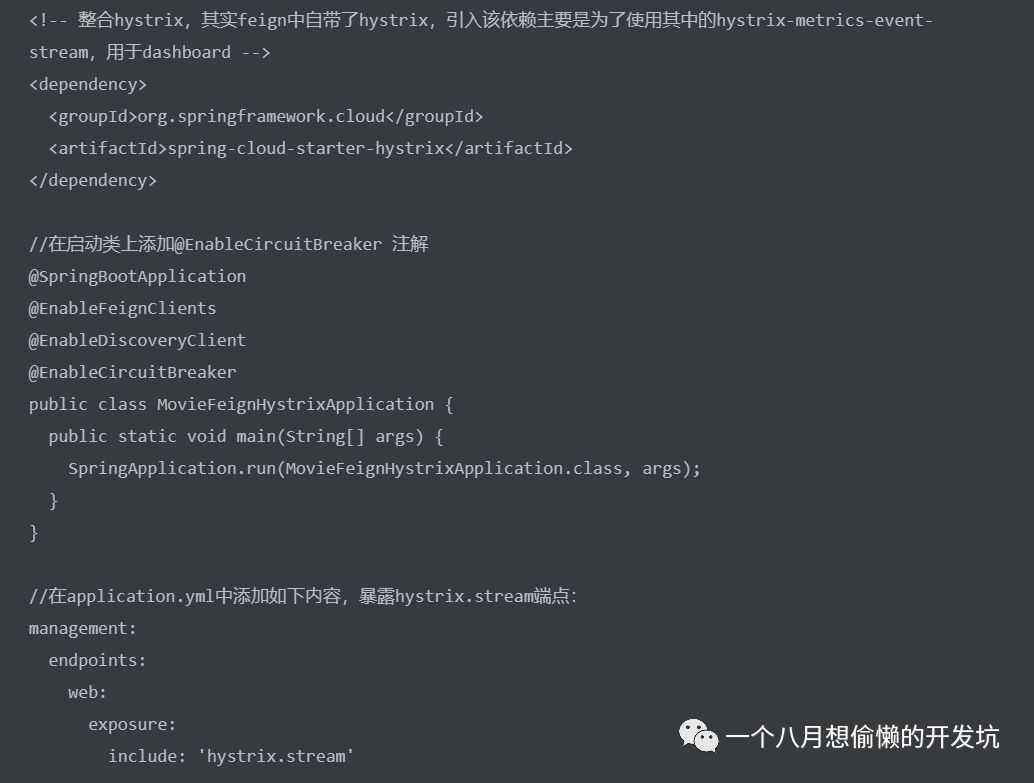
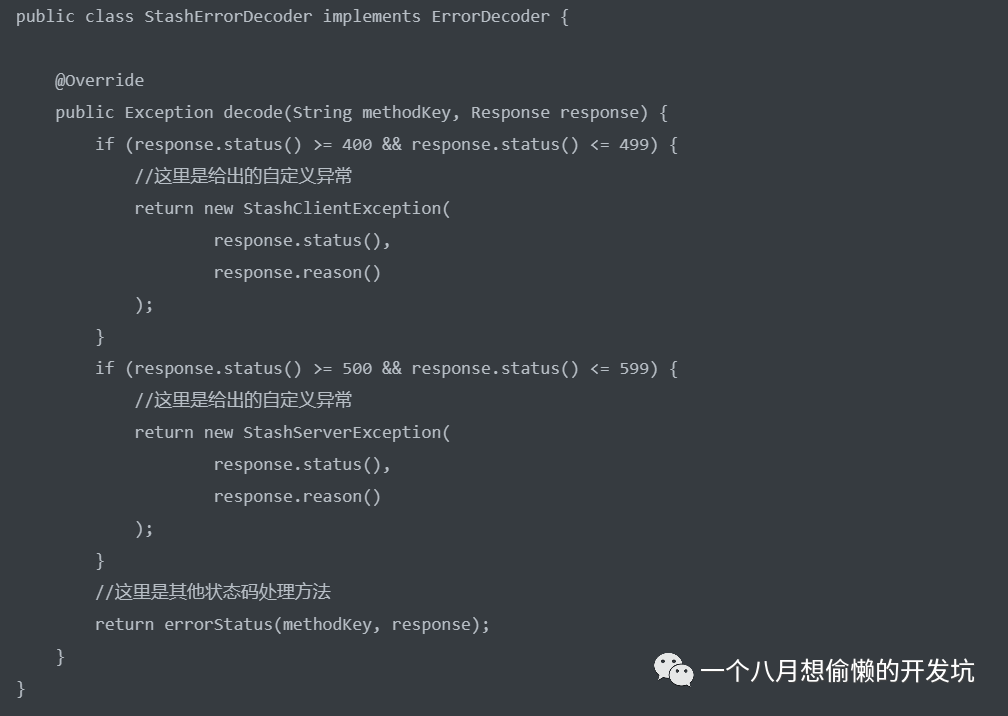
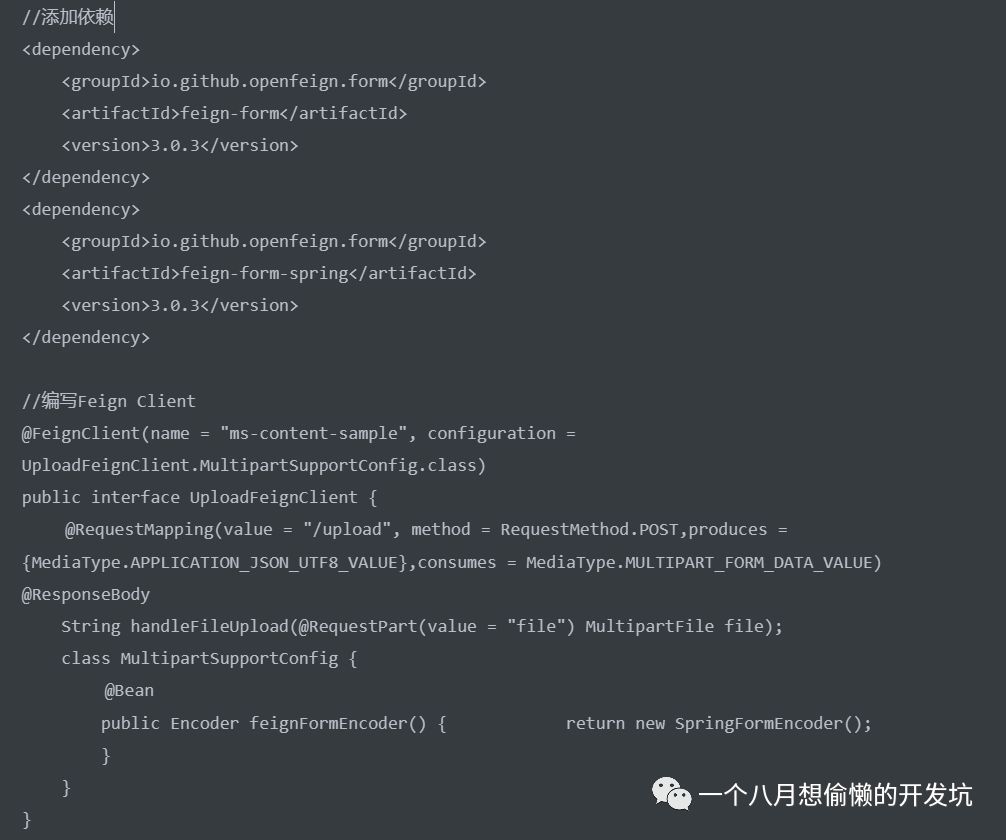
Spring Cloud Config
统一配置中心,集中管理所有微服务的配置,方便维护,支持配置内容安全与权限,支持无需重启更新项目配置;
Spring Cloud Bus
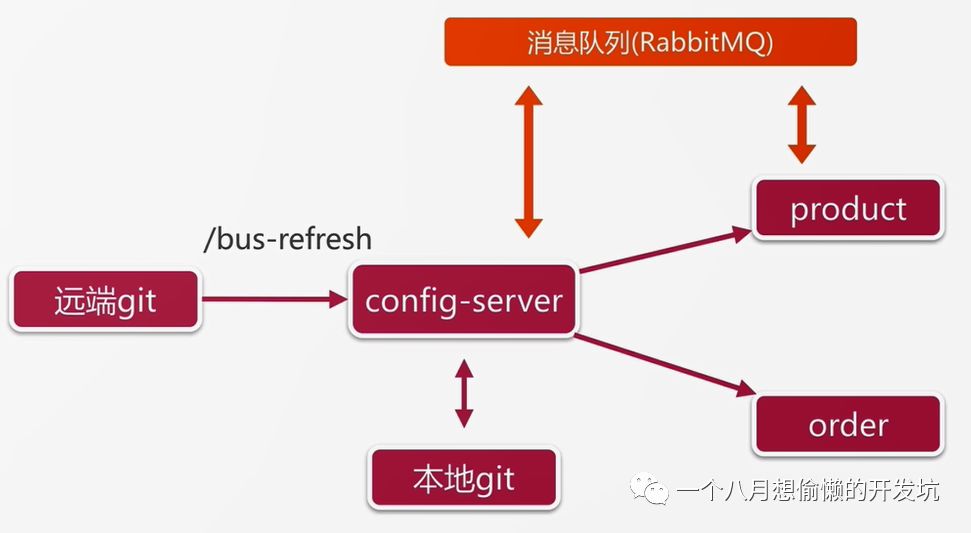
Spring Cloud Stream
消息中间件的封装,目前支持 RabbitMQ 和 Kafka;
Spring Cloud Zuul ⭐
前置(Pre):限流(令牌桶限流 Guava实现或开源的个人 ratelimit 实现)、鉴权、参数校验调整;
路由(Route)
后置(Post):统计、日志;
错误(Error)
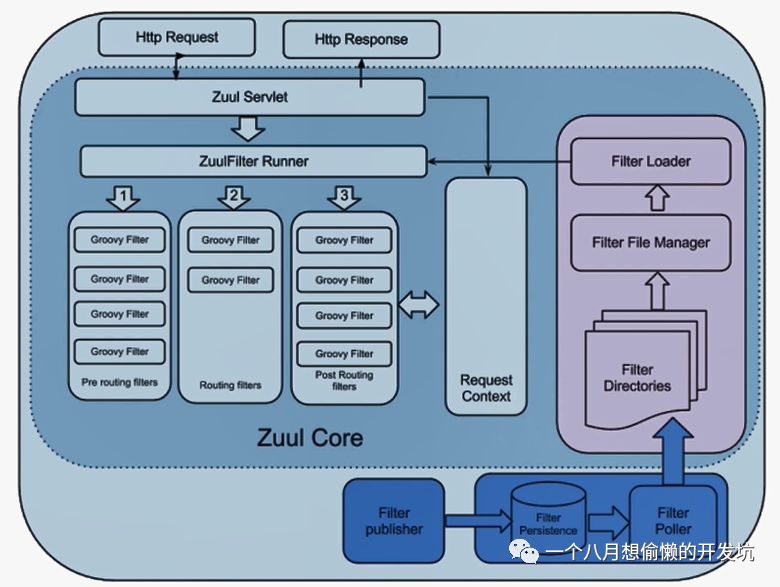
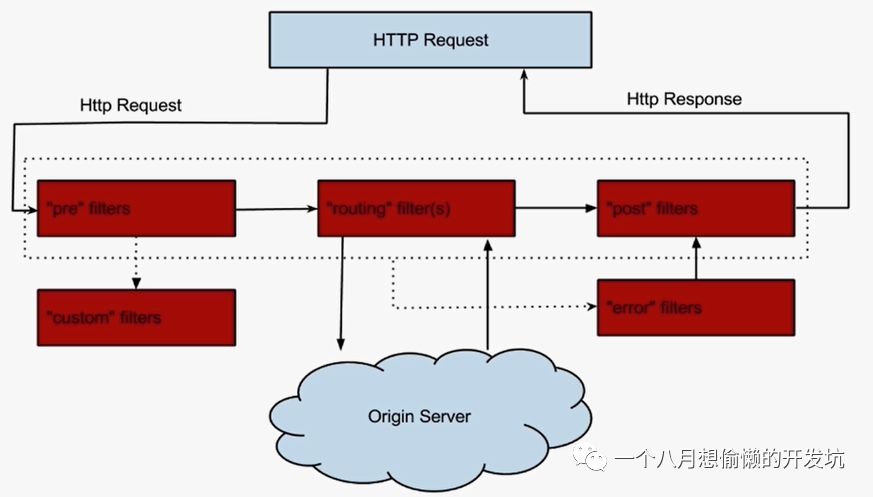
多个 Zuul 节点注册到 Eureka Server;
Nginx 和 Zuul 混搭;
在 Zuul 里增加 CorsFilter 过滤器;
默认情况下,像 Cookie、Set-Cookie 等敏感请求头信息会被 Zuul 屏蔽掉,可以将这些默认屏蔽去掉,当然,也可以添加要屏蔽的请求头;
Spring Cloud Gateway ⭐
SpringCloud 第二代网关,未来会取代第一代网关 Zuul;基于 Netty、Reactor 以及 WebFlux 构建;
基于 Spring Framework 5,Project Reactor 和 Spring Boot 2.0;
动态路由;
Predicates 和 Filters 作用于特定路由;
集成 Hystrix 断路器;
集成 Spring Cloud DiscoveryClient;
易于编写的 Predicates 和 Filters;
限流;
路径重写;
性能强劲:是 Zuul 1.x 的1.6倍;
功能强大:内置很多实用功能,如转发、监控、限流等;
设计优雅,易扩展;
依赖 Netty 与 Webflux,不是 Servlet 编程模型,有一定的适应成本;
不能在 Servlet 容器下工作,也不能构建 war 包;
不支持 SpringBoot 1.x;
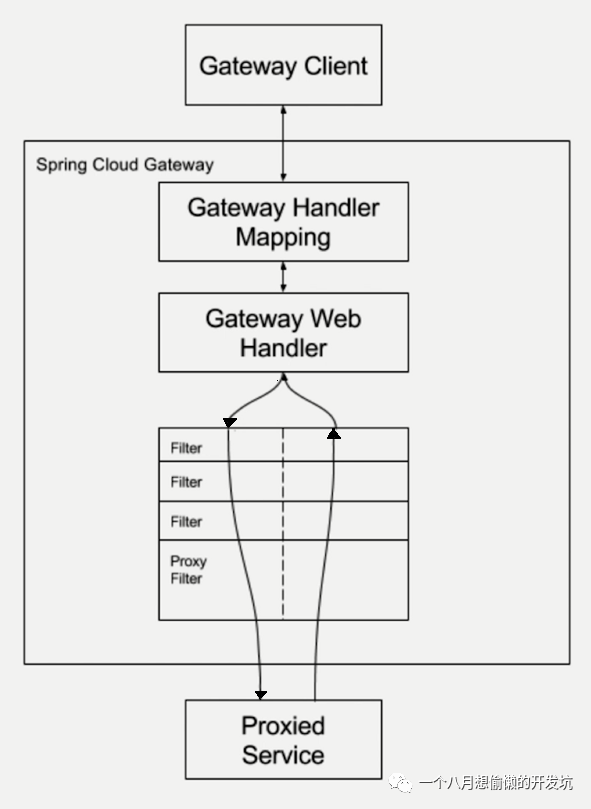
Route(路由):转发规则,包含:ID、目标 URL、Predicate 集合以及 Filter 集合;
Predicate(谓词):即 java.util.function.Predicate,使用 Predicate 实现路由的匹配规则;
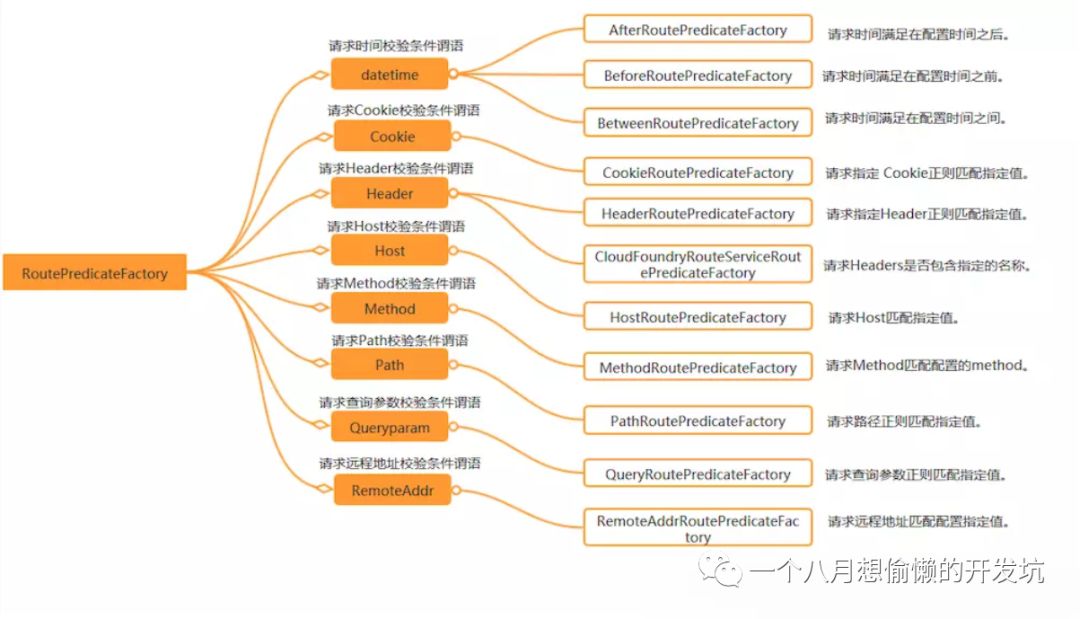
Filter(过滤器):修改请求和响应;过滤器执行
在 Pre 类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等;在 Post 类型的过滤器中可以做响应内容、响应头的修改,日志的输出,流量监控等;
Order 越小越靠前执行;
过滤器工厂的 Order 按配置顺序从1开始递增(filters 下的配置顺序);
如果配置了默认过滤器,则先执行所有配置相同 Order 的过滤器;
如需自行控制 Order,可返回 OrderGatewayFilter;
Spring Cloud Gateway 根据作用范围划分为 GatewayFilter 和 GlobalFilter,二者区别如下:
GatewayFilter : 需要通过 spring.cloud.routes.filters 配置在具体路由下,只作用在当前路由上或通过 spring.cloud.default-filters 配置在全局,作用在所有路由上;
GlobalFilter : 全局过滤器,不需要在配置文件中配置,作用在所有的路由上,最终通过 GatewayFilterAdapter 包装成 GatewayFilterChain 可识别的过滤器,它为请求业务以及路由的URI转换为真实业务服务的请求地址的核心过滤器,不需要配置,系统初始化时加载,并作用在每个路由上;
添加 Spring Boot Actuator( spring-boot-starter-actuator )的依赖,并将
Gateway 端点暴露,即可获得若干监控端点,监控 & 操作 Gateway 的方方面面;
内置的 RequestRateLimiterGatewayFilterFactory
提供限流的能力,基于令牌桶算法实现,它内置的 RedisRateLimiter ,依赖 Redis 存储限流配置,以及统计数据,当然也可以实现自己的 RateLimiter,只需实现 Gateway 提供的的 RateLimiter 接口,或者继承 Gateway 的 AbstractRateLimiter;
有一个水桶,水桶以一定的速度出水(以一定速率消费请求),当水流速度过大水会溢出(访问速率超过响应速率,就直接拒绝);
漏桶算法的两个变量:
水桶漏洞的大小:rate;
最多可以存多少的水:burst;
系统按照恒定间隔向水桶里加入令牌(Token),如果桶满了的话,就不加了;
每个请求来的时候,会拿走1个令牌,如果没有令牌可拿,那么就拒绝服务;
跨域
CORS Configuration,Gateway 是支持 CORS 的配置,可以通过不同的 URL 规则匹配不同的 CORS 策略;
Spring Cloud Hystrix ⭐
服务保护,将服务调用进行隔离,用快速失败来代替排队,阻止级联调用失败(服务雪崩);
服务降级:超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据,通过 HystrixCommand 注解指定,fallbackMethod 中具体实现降级逻辑,实现优先核心服务,非核心服务不可用或弱可用;
依赖隔离:包括线程池隔离和信号量隔离,限制调用分布式服务的资源使用,某一个调用的服务出现问题不会影响其他服务调用,Hystrix 自动实现依赖隔离;
服务熔断:CircuitBreaker 断路器,当失败率达到阀值自动触发降级(如因网络故障 / 超时造成的失败率高),熔断器触发的快速失败会进行快速恢复; 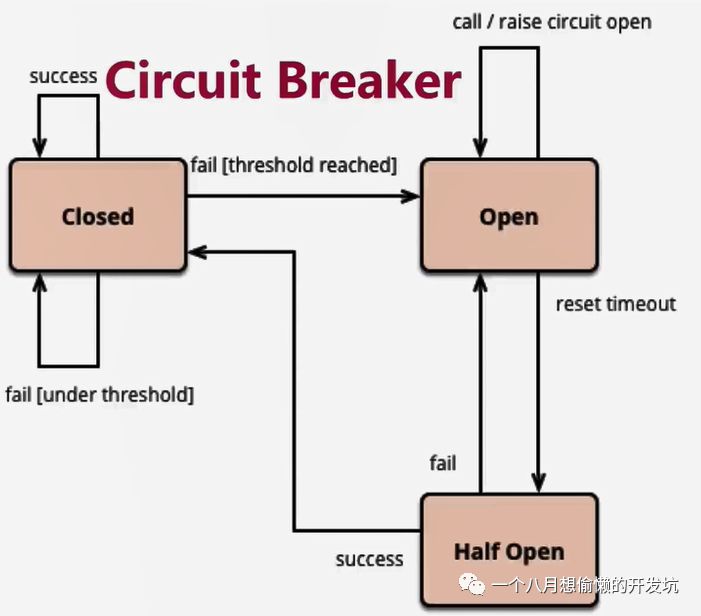
circuitBreaker.sleepWindowInMilliseconds:熔断时间窗口,结束后断路器将进入半开状态并尝试执行一次主逻辑,成功则断路器关闭,失败则断路器打开; circuitBreaker.requestVolumeThreshold:计算失败率的最小请求数;
circuitBreaker.errorThresholdPercentage:失败率;
熔断器处理流程:
开始时断路器处于关闭状态(Closed);
如果调用持续出错、超时或失败率超过一定限制,断路器打开进入熔断状态,后续一段时间内的所有请求都会被直接拒绝;
一段时间以后,保护器会尝试进入半熔断状态(Half-Open),允许少量请求进来尝试;如果调用仍然失败,则回到熔断状态,如果调用成功,则回到电路闭合状态; 缓存:提供了请求缓存、请求合并实现;
监控(Hystrix Dashboard)
Spring Cloud Sleuth
链路监控,是一个分布式跟踪解决方案,在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,就能调试和监控微服务;
span(跨度):基本工作单元,它用一个64位的 id 唯一标识,除 id 外,span 还包含其他数据,例如描述、时间戳事件、键值对的注解(标签)、spanID、span 父 ID 等;
trace(跟踪):一组 span 组成的树状结构;
Annotation(标注):
CS(Client Sent 客户端发送):客户端发起一个请求,该 annotation 描述了 span 的开始;
SR(Server Received 服务器端接收):服务器端获得请求并准备处理它;
SS(Server Sent 服务器端发送):该 annotation 表明完成请求处理(当响应发回客户端时);
CR(Client Received 客户端接收):span 结束的标识,客户端成功接收到服务器端的响应;
抽样收集
默认情况下,Sleuth 会使用
PercentageBasedSampler 实现的抽样策略,以请求百分比的方式配置和收集跟踪信息,默认值0.1(代表收集 10% 的请求跟踪信息),可以通过配置 spring.sleuth.sampler 来修改收集的百分比;
由于日志文件都分布在各个服务实例的文件系统上,如果链路上服务比较多,查看日志文件定位问题是一件非常麻烦的事情,所以需要一些工具来帮忙集中收集、存储和搜素这些跟踪信息。引入基于日志的分析系统,比如ELK平台,SpringCloudSleuth 在与 ELK 平台整合使用时,实际上只需要与负责日志收集的 Logstash 完成数据对接即可,所以需要为 logstash 准备 JSON 格式的日志输出(SpringBoot 应用默认使用 logback 来记录日志,而 logstash 自身也有对 logback 日志工具支持);
ELK 搭建可参考:
Zipkin
Twitter 开源的分布式跟踪系统,主要用来收集系统的时序数据,从而跟踪系统的调用问题;
Sleuth 搭配 Zipkin 控制台使用构建分布式追踪系统,核心步骤:数据采集,数据存储,
查询展示;
持久化:
数据存储:MySQL、Elasticsearch、Cassandra;
持久化后需使用 Zipkin Dependencies 才能进行依赖关系的查看;
(完)
识别二维码,关注我,不定时更