




etcd作为k8s的核心,有着举足轻重的地位。但它又作为管理组件,相比业务组件,它通常会被部署在性能比较差的虚拟机+hdd上,(性能好的机器优先给业务使用),这也导致相关性能问题的产生。
etcd虽然资源占用少,存储最多2g,但对于存储io与网络有着很高的要求。将从三个方面来分析其原因:
etcd选举与心跳
etcd写请求处理流程
etcd读请求处理流程
01
etcd选举与心跳
etcd 共有三种角色:
Follower、Candidate、Leader
只有Leader与Follower可受理读写请求。角色之间状态转换如下:
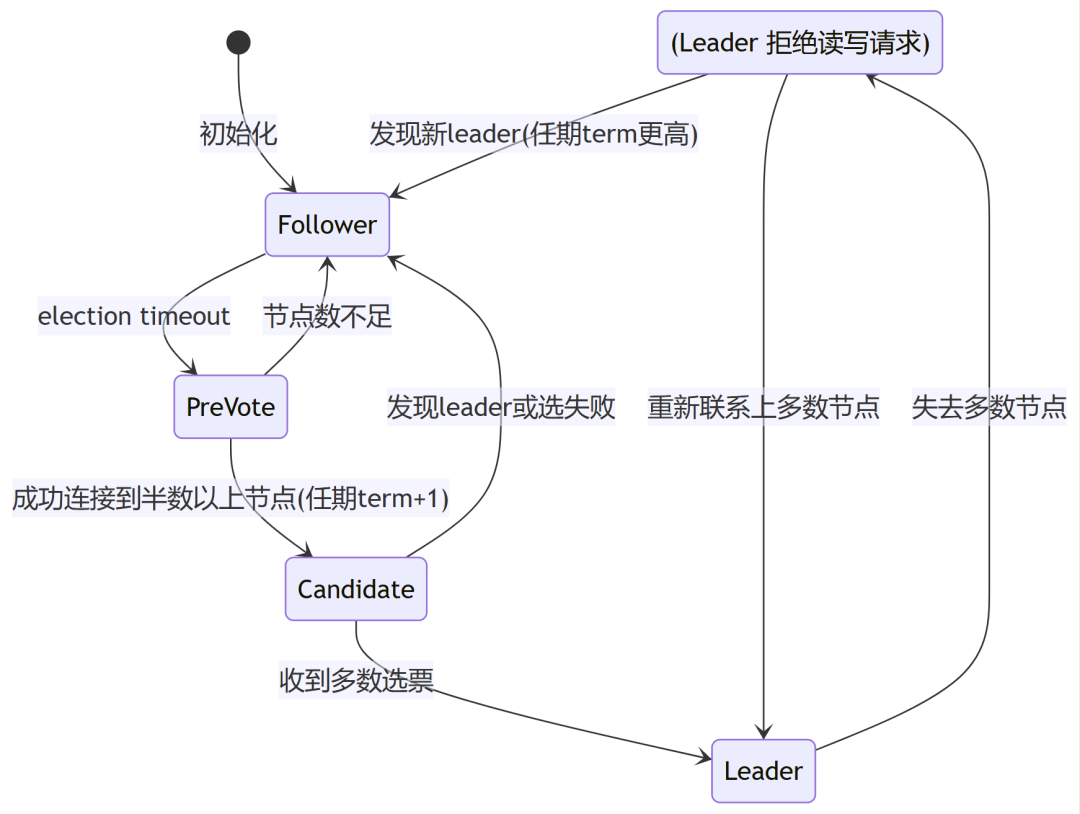
etcd默认选举超时(election timeout)为1s,很敏感,同时,为了减小网络抖动导致心跳失败,所以要求心跳间隔小于 (election timeout)/5,保证一次超时中能发5次心跳。而默认心跳间隔为100ms,可发10次。
而一次选举,会触发中间状态preVote与选举状态candidate,这个状态是无法提供服务的,客户端会在选举结束后,收到Leader changed的应答,业务是有感知的。
etcd的读写流程是比较复杂的,为了保证数据的全局一致性。而为了提高性能,etcd节点之间的数据会聚合发送,而消息处理是FIFO算法。所以,单个的消息处理也会导致整体的性能,尤其是当中如果出现磁盘读写慢时。
etcd三个角色分别对应三个消息处理函数:
stepLeader、stepCandidate、stepFollower
这些消息全部都是异步处理。
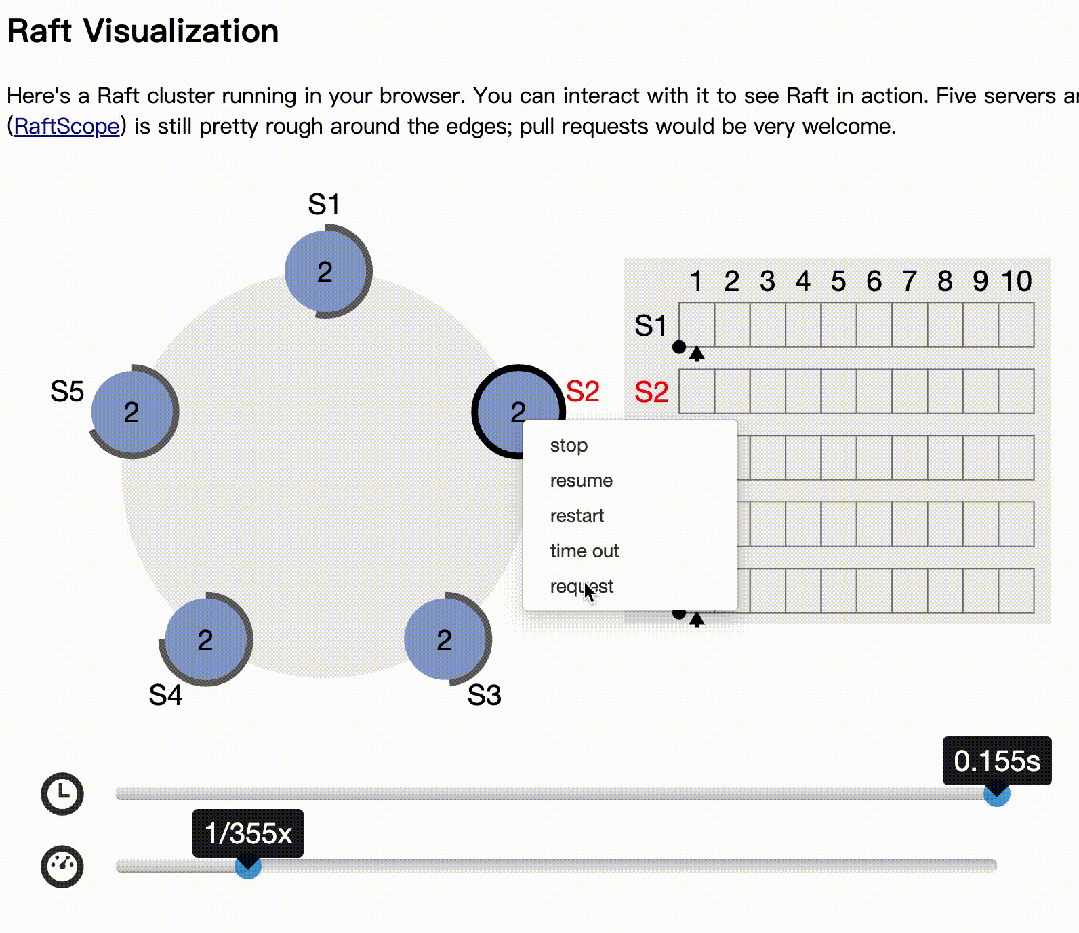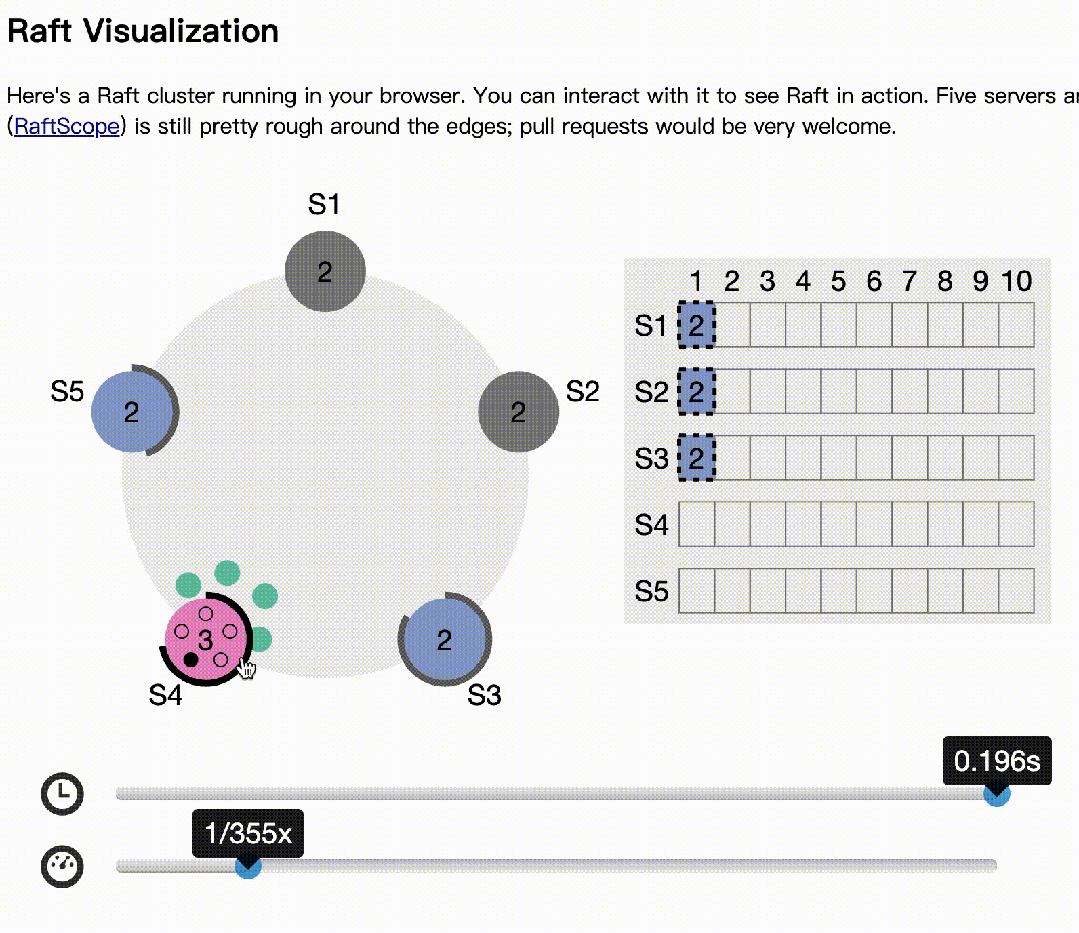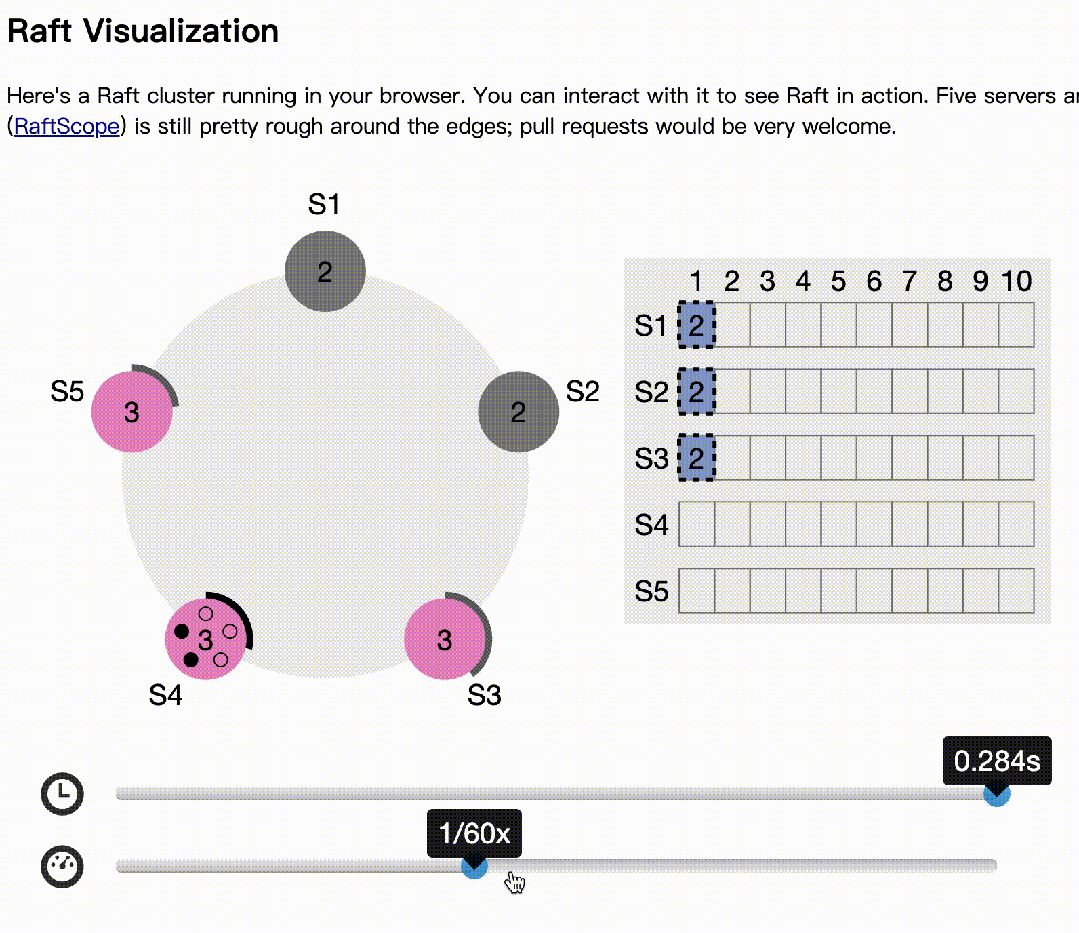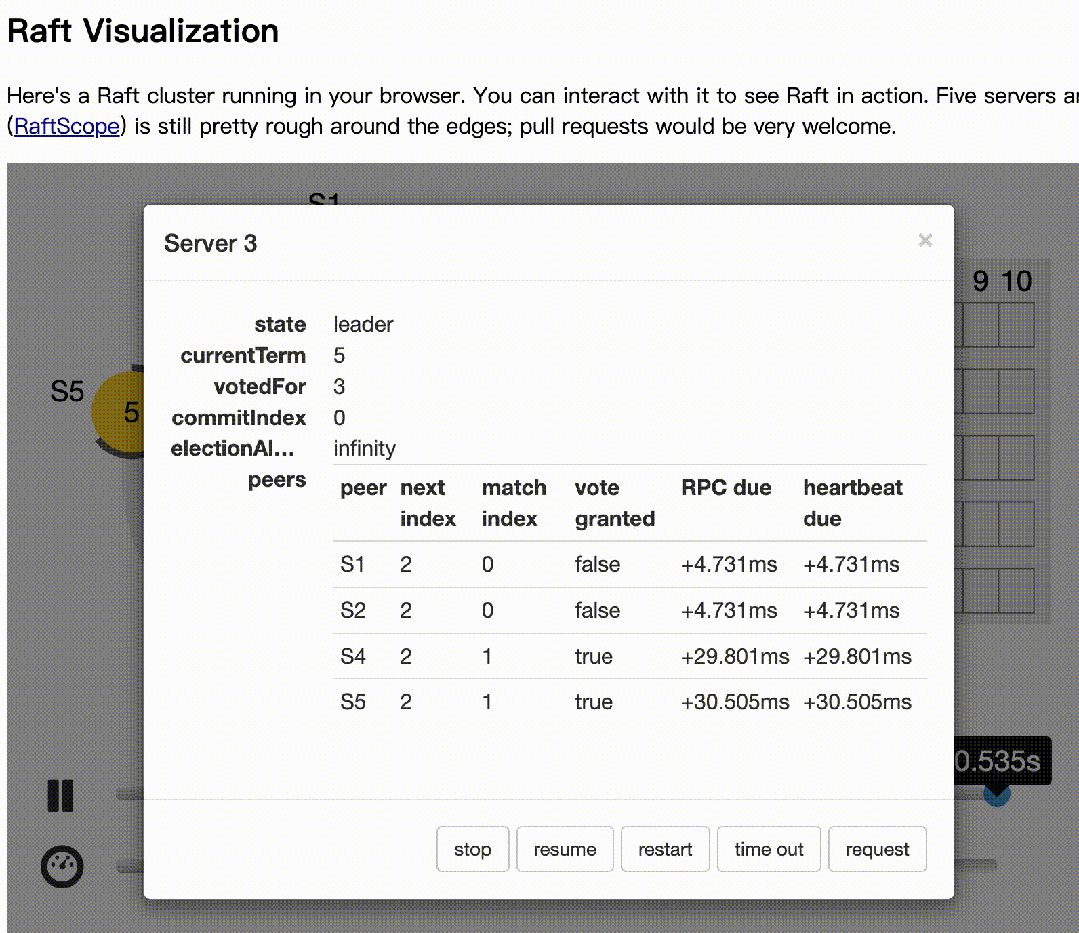
下面基于raft官网(https://raft.github.io/)的动画模拟了多节点同时选举的情况:
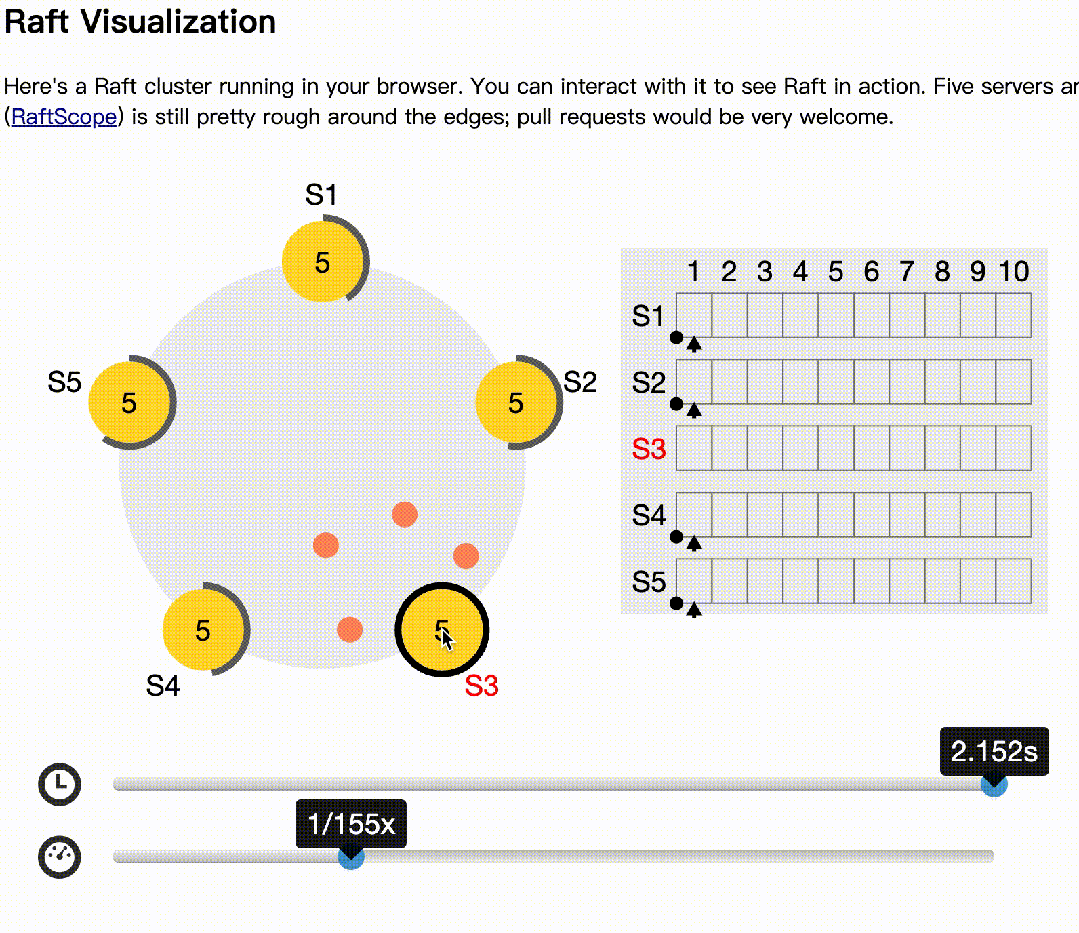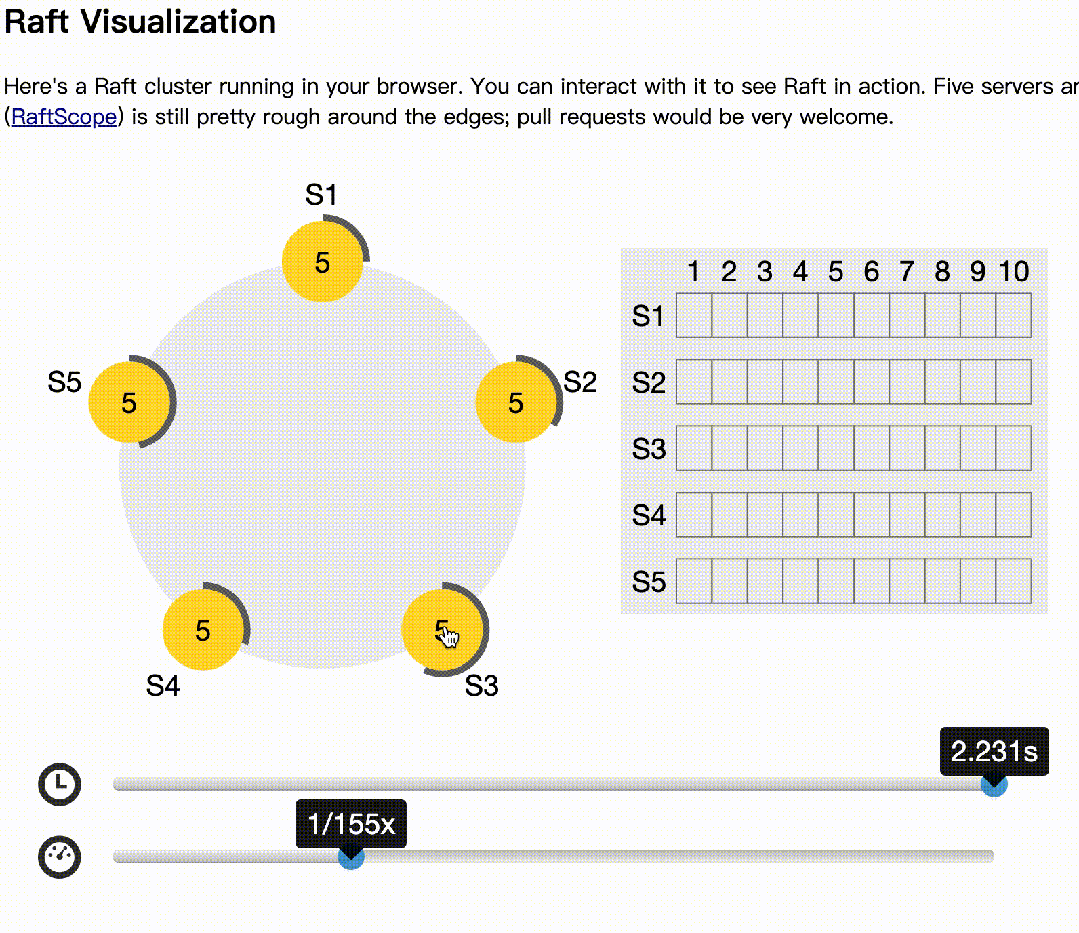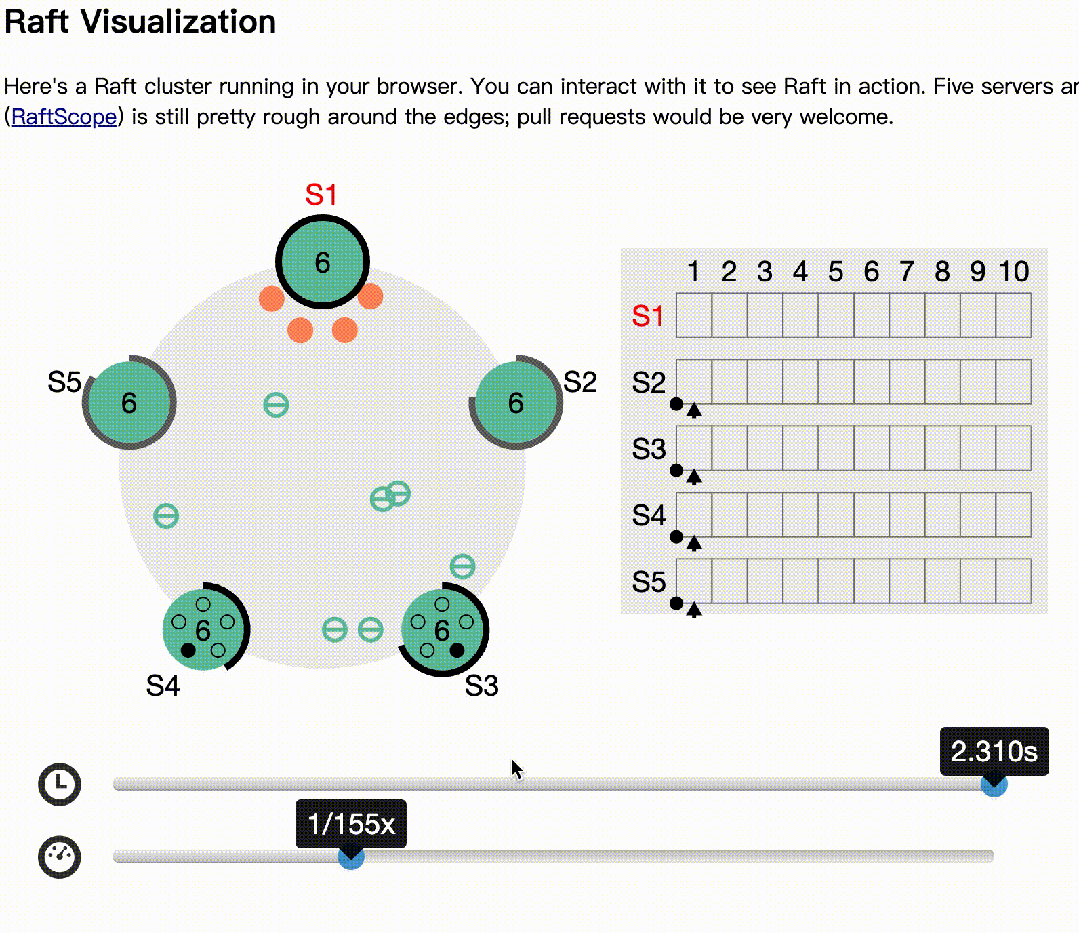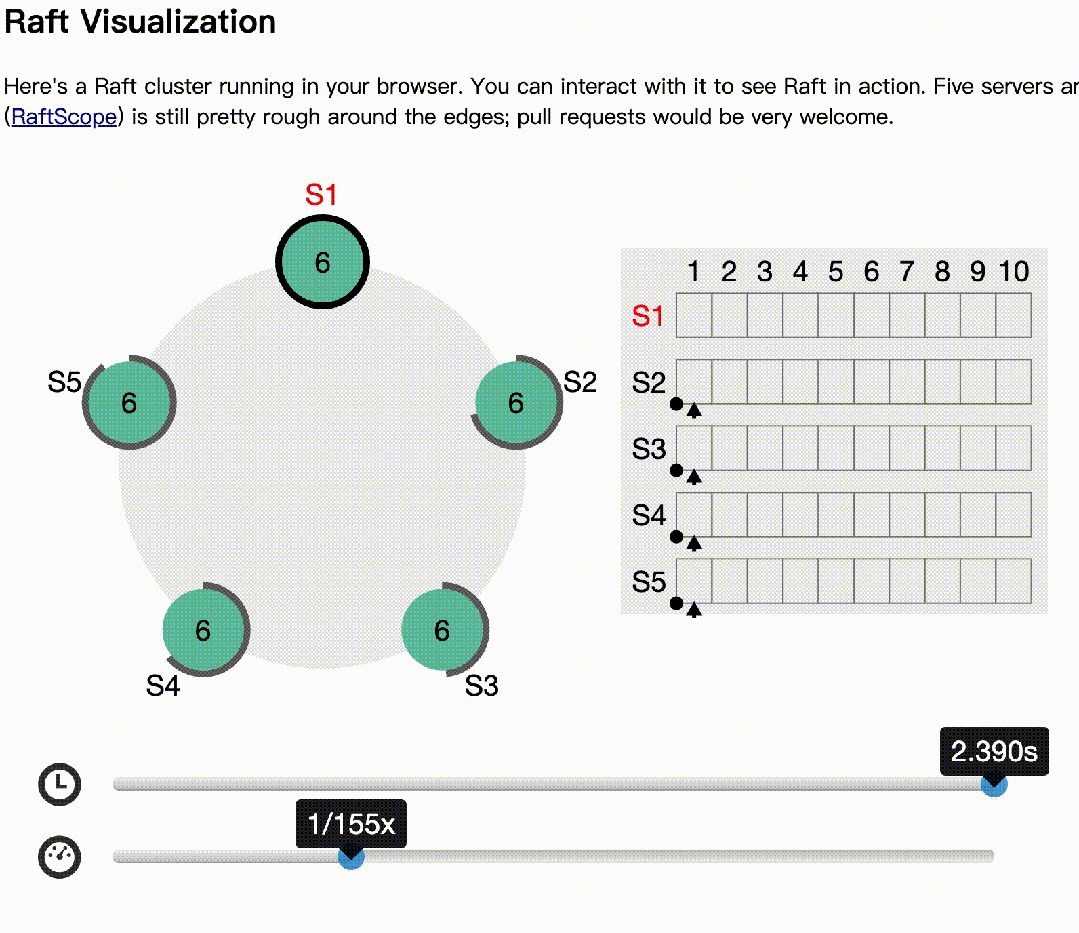
下面模拟主记录日志,多数节点收到后,异常的情况:
s2作为主,写日志后,1,3收到,4,5异常
s2,s1异常,但s4先发起选举
s3拒绝s4的选举,因为日志多。同样,s5发起也会拒绝
s3成为下一个主
当少数节点时,会被丢弃⬇️⬇️⬇️
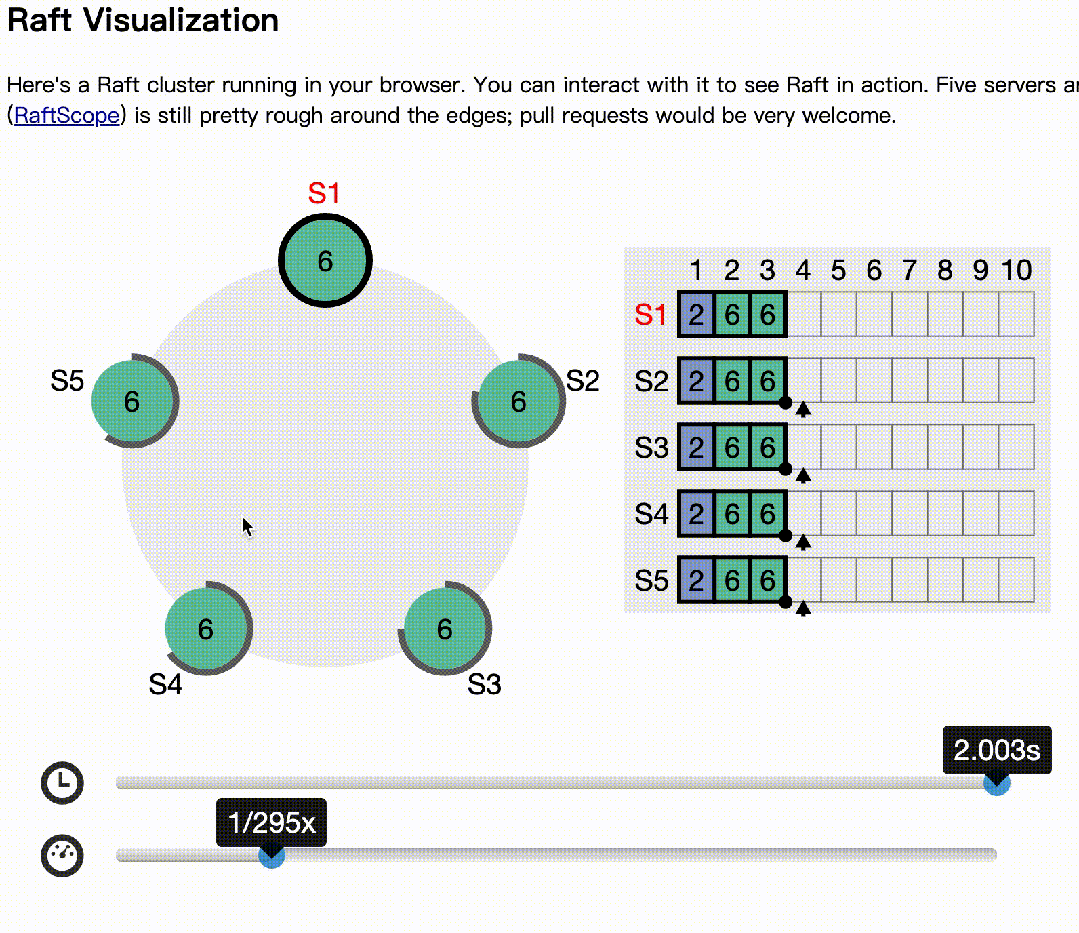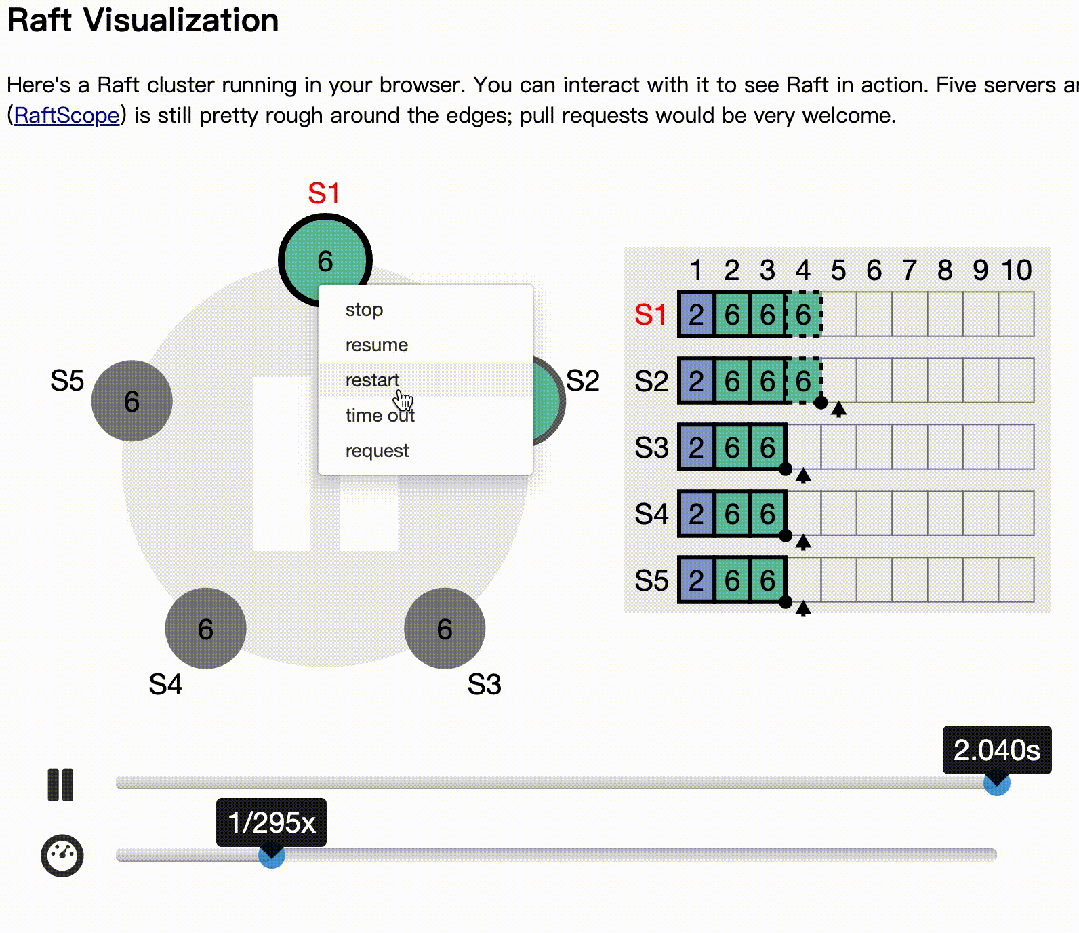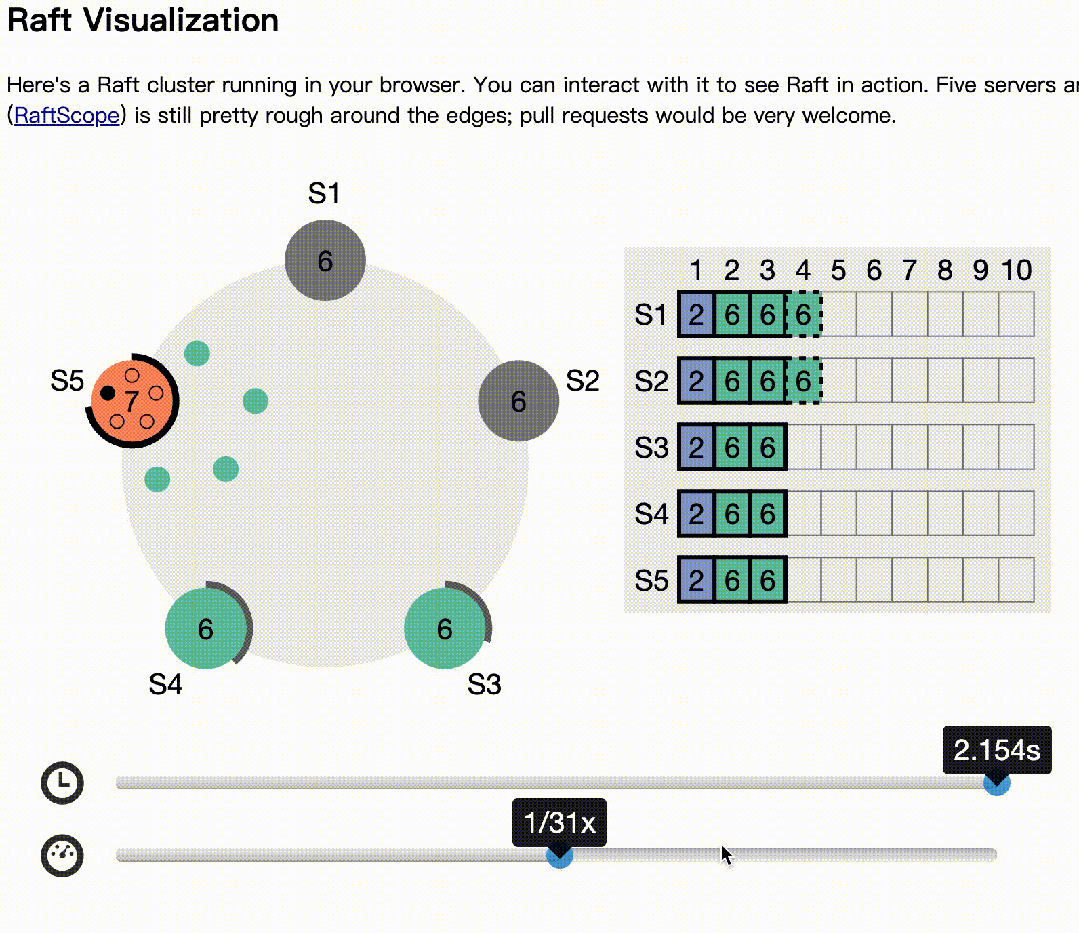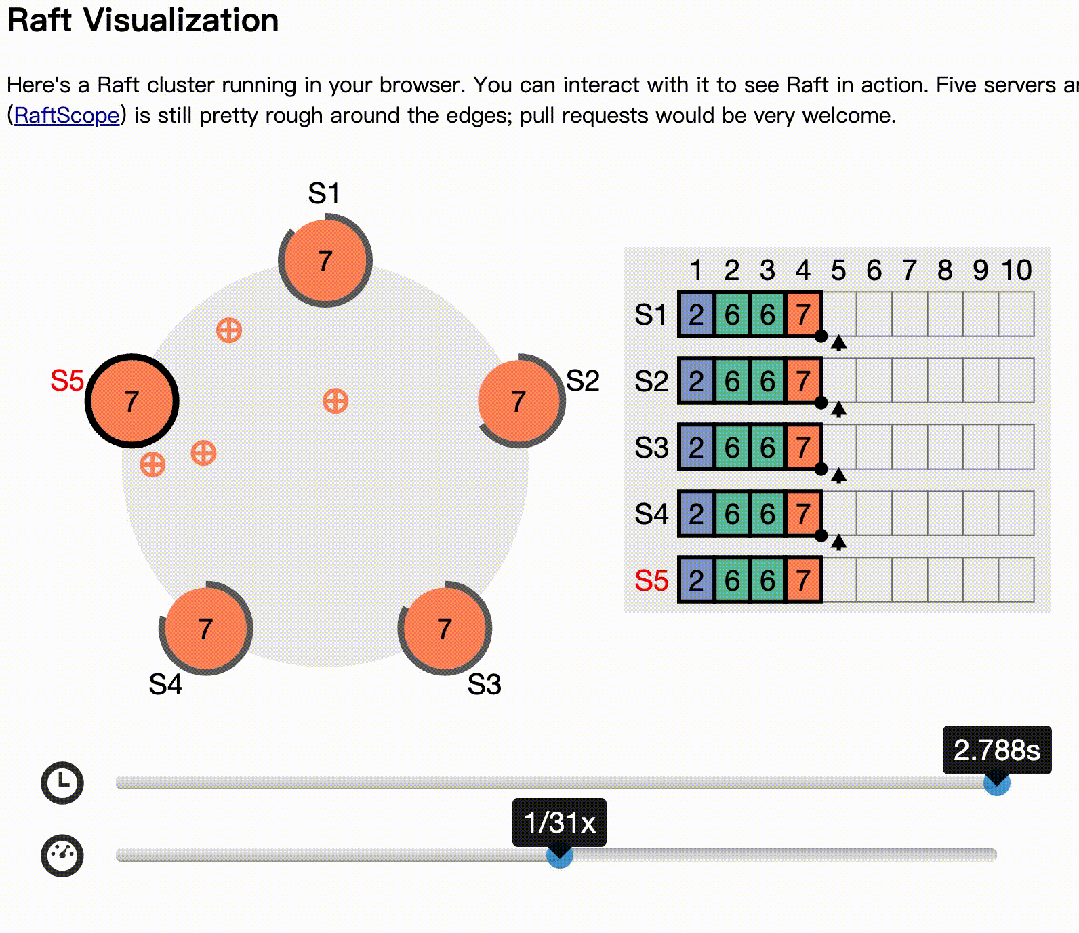
02
etcd写入流程
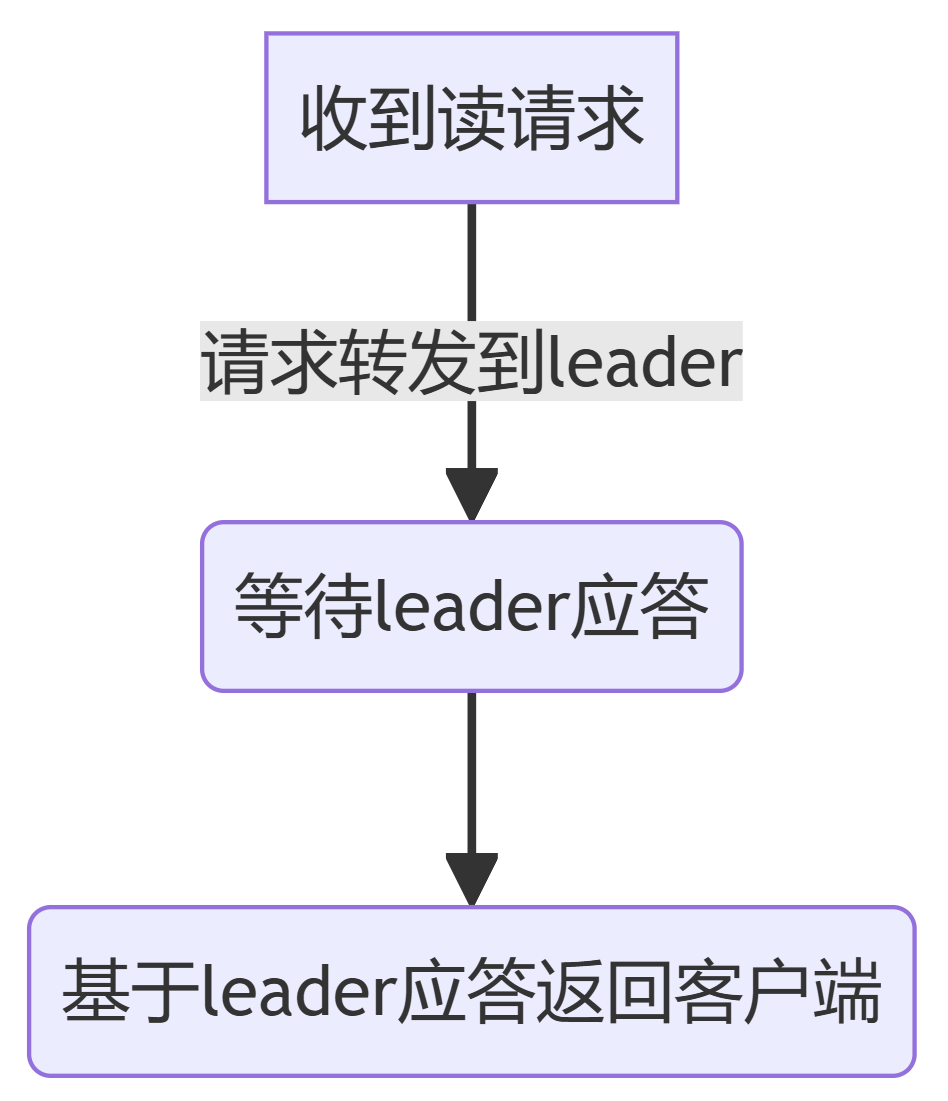
只有leader可以写。Follower收到写请求时,会转发到leader,再将返回返回客户端。
Leader写请求处理流程⬇️⬇️⬇️
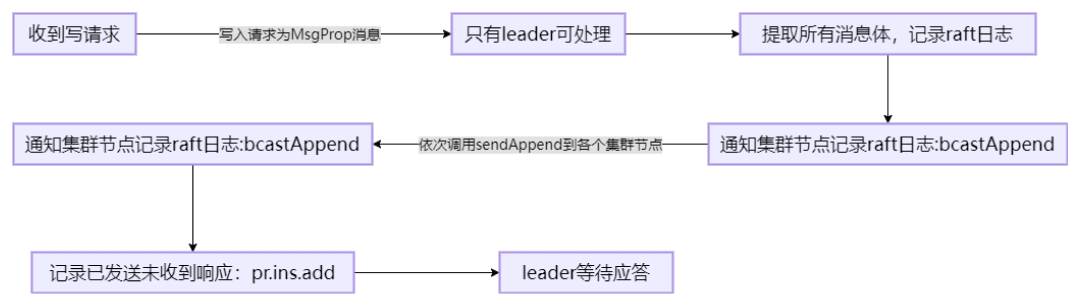
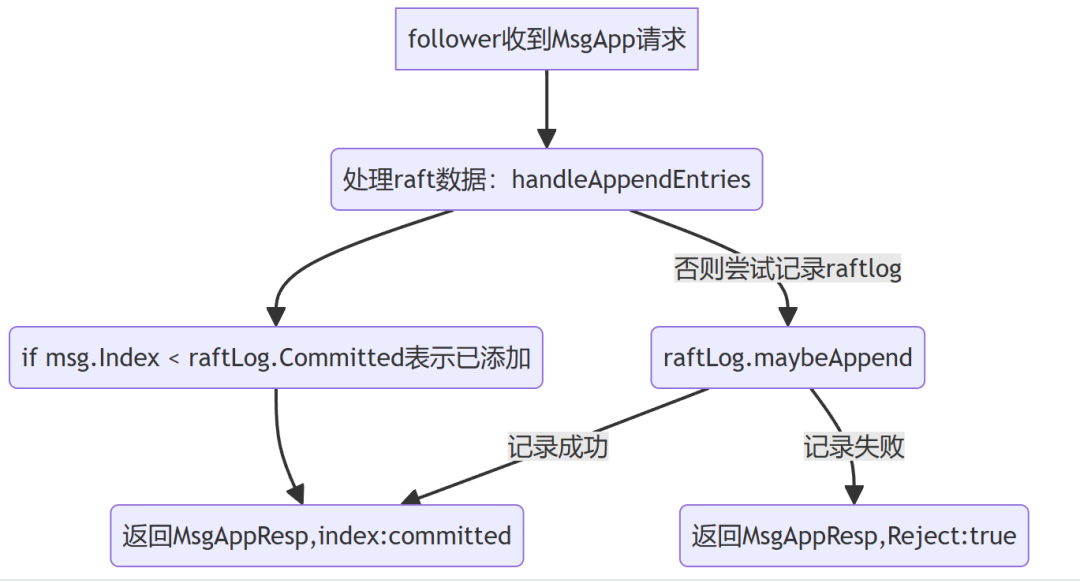
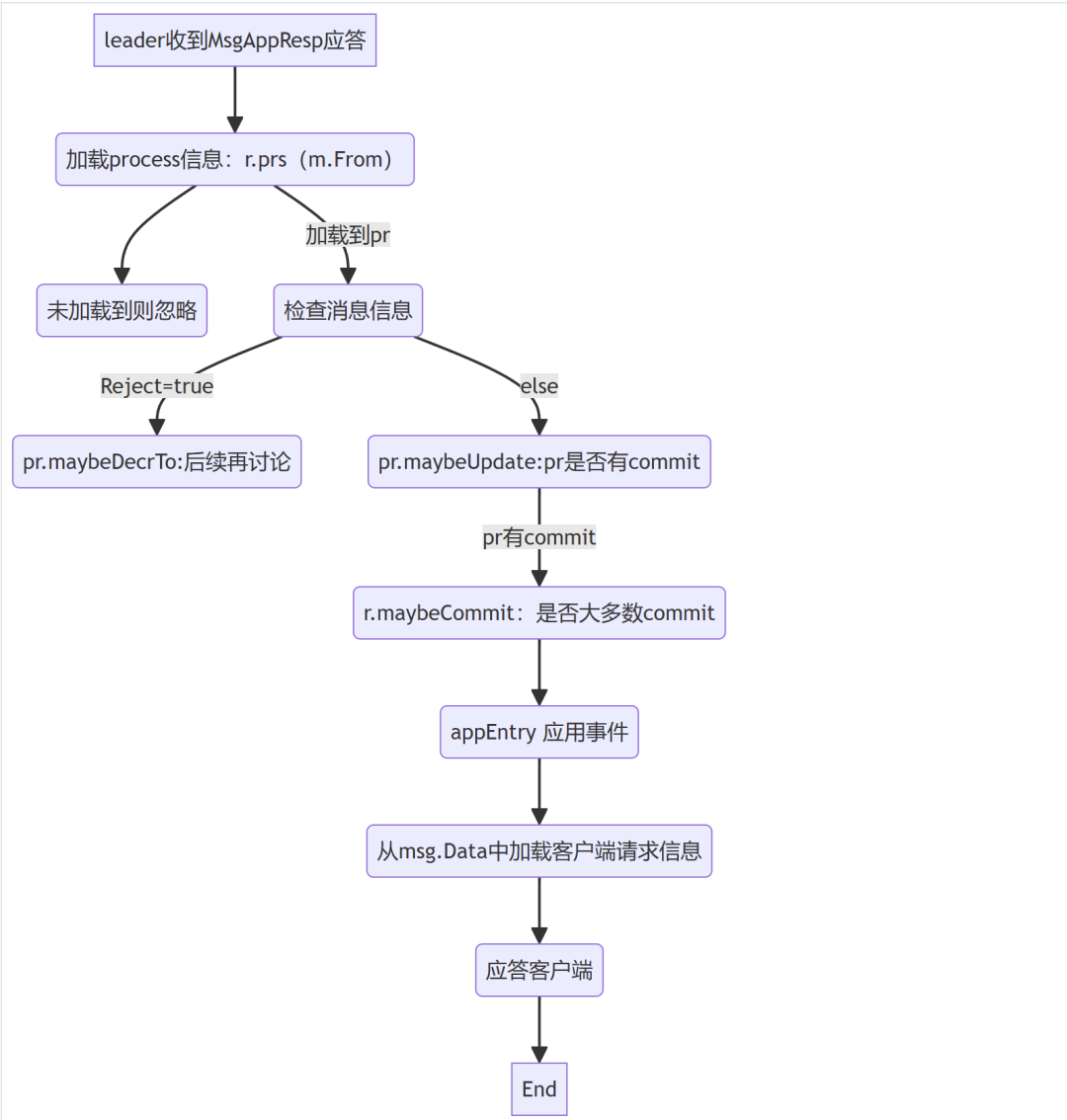
写数据时序图⬇️⬇️⬇️
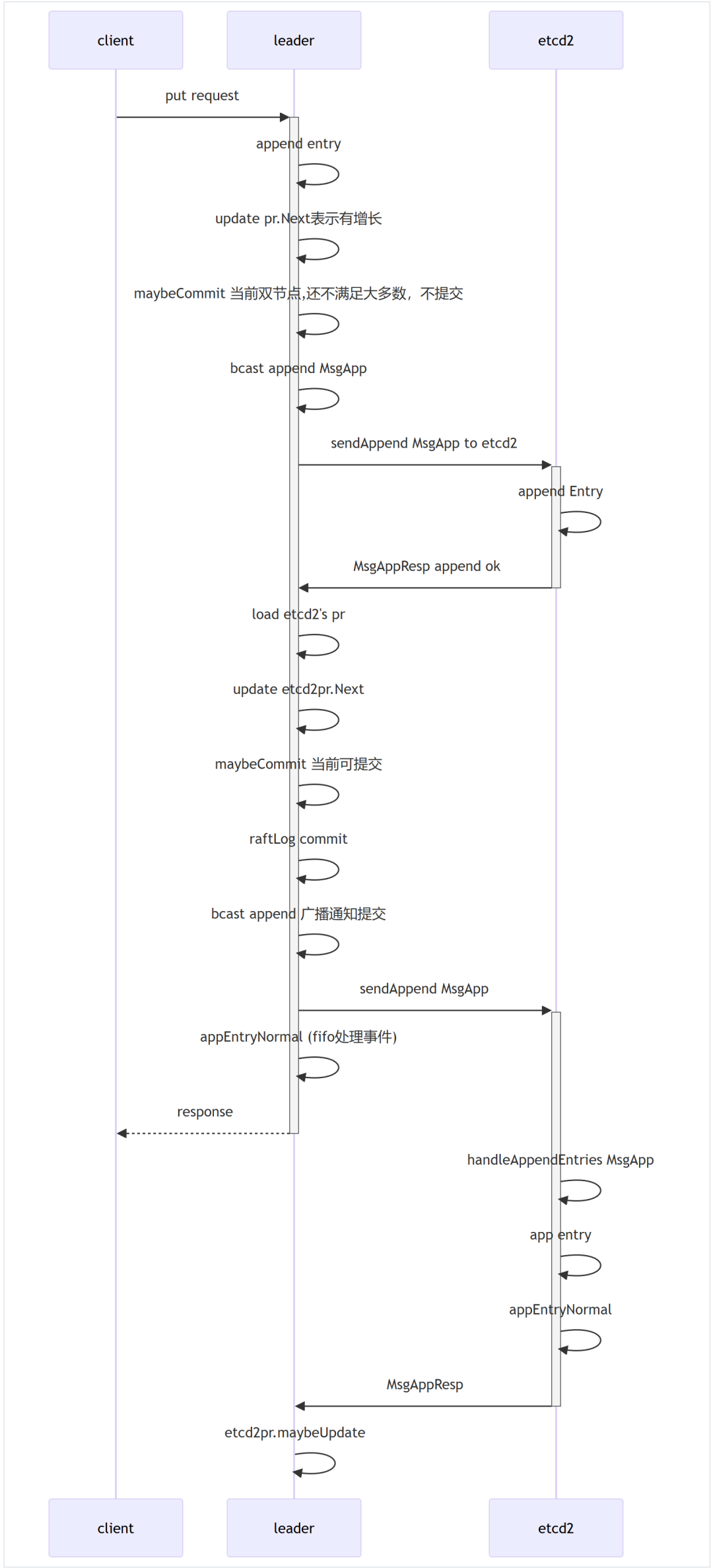
一些注意点⬇️⬇️⬇️
写数据必需保证多数节点接收后,才会提交。而选举时要求多数节点存在时,才可选举,这就保证了参于选举的节点 与 接收数据的节点 一定存在交集。
样例中,取的是双节点,而三节点类似,唯一的区别在于:
当主节点触发写事件W1,etcd2反馈后主节点提交
下一个写事件W2,etcd2未响应,etcd3在未响应W1之前,不会响应W2(会拒绝)
当etcd3拒绝时,主节点会将上一个事件W1重发给etcd3(这里有一点特殊情况,当etcd3继续拒绝时,主节点会继续前移,当主节点前移无事件时,会发送全量快照给etcd3)
所以当etcd中某节点下线时间过长,加入集群时,为了补齐数据,会加重集群的网络压力与主节点压力。
03
etcd读取流程
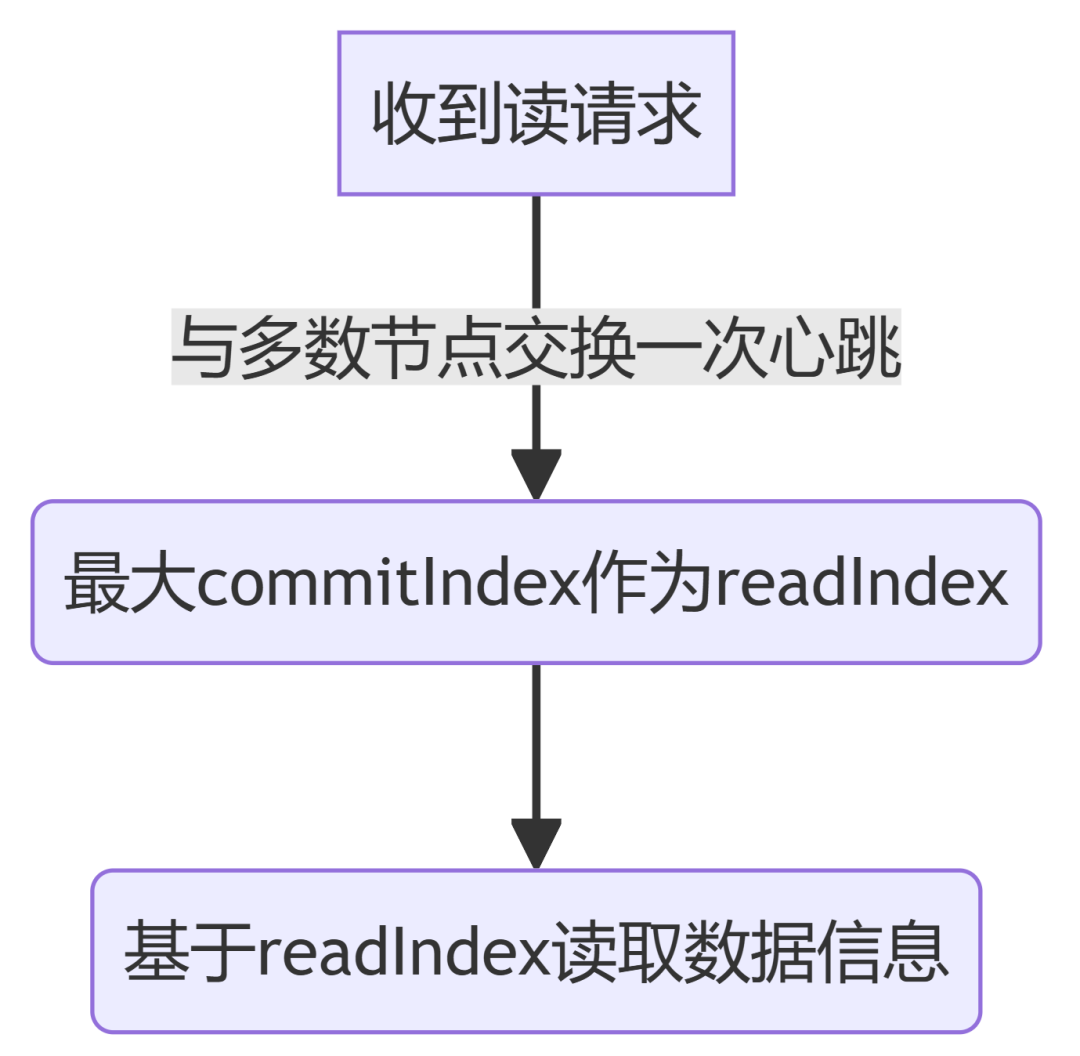
为保证全局一致性读,所有读请求都会转发到主节点中。
Leader读请求处理流程⬇️⬇️⬇️
Follower读请求处理流程⬇️⬇️⬇️
老版本etcd还有ReadOnlySafe、ReadOnlyLeaseBased选项,新版本已经不开放参数了,默认为ReadOnlySafe。两个的区别就在于ReadOnlySafe要求读之前强制交换一次心跳,并且明确收到心跳应答才响应读请求。
正是因为etcd为了保证数据库的全局一致性读写,加重了对基础资源的依赖。
04
总结
针对etcd的特性,可做如下优化:
针对环境情况可适当提高election timeout。
当然也会导致主节点真的异常时选举时间变长。
为etcd准备单独高性能盘,因为空间本身不需要太大。
一块盘可分多个目录,分别给多个etcd集群使用,比如将k8s event数据单独存储,apiserver本身也支持数据拆分。
当异常节点恢复之前,可对主节点进行一次compaction,快速通过快照恢复
可考虑引入etcd proxy,因为正常运行时,follower也是充当了proxy功能
本期作者丨沃趣科技产品研发部
版权作品,未经许可禁止转载
往期作品快速浏览:




