




在 7 月 26 日的 TDengine 用户大会上,涛思数据(TDengine)首席架构师肖波进行了题为《TDengine 助力新型电力系统高质量发展》的主题演讲。他不仅分享了 TDengine 在新型电力系统中的应用案例,还深入探讨了如何利用 TDengine 的高性能数据处理能力,推动电力行业的数字化转型与智能化升级。本文根据演讲内容整理而成。

什么是新型电力系统?
在这一政策的要求下,大规模可再生能源的介入成为了重要的背景。以数据为依据,2017 年我国的电力装机容量大约为 17.7 亿千瓦,而到 2023 年这一数字已增至 29.2 亿千瓦,预计到 2060 年实现碳中和时,装机容量可能达到 71 亿千瓦。这一增长速度是显著的。具体来看,2017 年火电占比为 62%,而到 2023 年已降至 38%。根据预测,2030 年碳达峰时,火电占比将降至 30%。与此同时,风电和光伏的比例从六年前的 16% 增长至去年的 36%。
在这样的发展趋势下,我们来探讨下新型电力系统的特点。首先,高比例的可再生能源介入是其重要特征。截至去年,风电和光伏的装机容量已达到 10.5 亿千瓦,加上水电,整体可再生能源的比例已超过 15 亿千瓦。未来,这一绝对数量和相对比例都将快速攀升,导致可再生能源在电力结构中的比重加大。
我们看到,风电、光伏与储能的集成已成为趋势,针对大规模的风电和光伏项目,其测点数量也显著增加。例如,一个核电岛通常有约 20 万个测点,而集中式风电和光伏项目的测量点可能从数百万到数千万,这对生产安全和运营管理提出了更高的要求。
其次,智能电网的建设也在加速推进。微电网、虚拟电厂和电力市场机制的引入,进一步提高了对电网的要求。例如,20 年前我国的电网尚未实现分布式光伏接入,而如今,分布式光伏已在全国范围内接入了数百万户,带来了新的监测、预警和控制挑战。过去,电力调度不需要关注这些问题,但现在情况已大为不同。
此外,电力市场机制的引入也是新型电力系统的重要组成部分。目前,以国家电网为例,其营销任务中仅承担 20%,剩余 80% 则依靠其他市场经营主体的竞争。此外,充电桩的建设、新能源的使用以及负荷侧管理和需求响应等概念,都是近十年才逐渐形成的,构成了新型电力系统的独特特点。
在这样的一个发展趋势下,TDengine 在全球的用户数量也在急剧增长。截至目前,TDengine 在全球已运行超过 57 万个实例,每天新增 500 多个实例。如下图所示,尽管我们在台湾省和欧洲等地尚未设立办事处,但依然有大量用户在使用我们的产品。
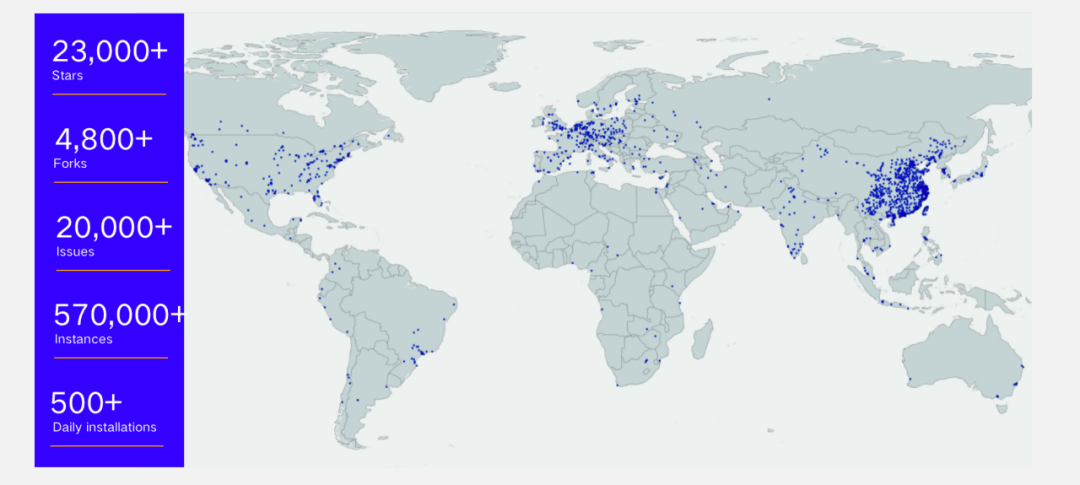
通过以上分析,可以看出新型电力系统在面对可再生能源快速增长的同时,也带来了许多新的挑战和机遇。我们需要不断适应这种变化,以推动电力行业的可持续发展。
新型电力系统的时序场景
回顾过去,在电网调度和电厂运行中,实时感知力的重要性愈发凸显。以十年前的一个实例为例,我的一位同事在京能的火电厂工作,当时新能源的接入给他们带来了巨大的挑战。为了应对变化,他们每天需要至少调节机组负荷两次,这在十年前是不可想象的。以大亚湾核电站为例,其机组出力非常稳定,几乎没有波动。然而,一旦进入新能源领域,出力的波动性显著增加,例如光伏发电的波动会直接影响火电的出力,带来了诸多挑战。因此,实时感知力的提升显得尤为关键,调度人员必须及时了解机组的运行风险以及外部电源的变化情况,以确保安全生产和经济运行。
在这里,我们需要思考如何提升感知力,实现精益化和智能化。信息电力系统的数据特征主要包括显著的结构化特征和日益增加的采集频度。某五大六小发电集团的新能源集控,需要接入全国数百个新能源场站,测点规模突破亿级,需要对这些海量遥测遥信测点进行实时处理。以南方电网为例,广东省的电表数量已达 5100 万,每个表计测量的物理量超过 10 个,导致测点总量达到亿级。这些测点的数据处理和响应要求我们具备强大的即时感知能力。
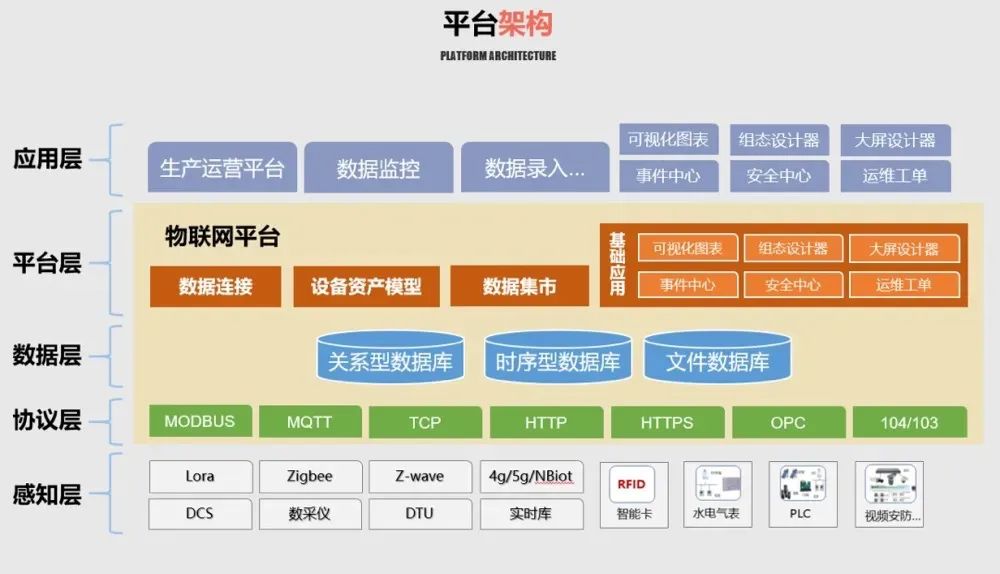
然而,当前时序数据处理面临诸多挑战。下图是大部分企业采用的数据架构图,数据从采集后进入 Kafka,通过流批处理后存储到实时数据库、历史数据库和数据仓库中。这样的架构中,数据存储的参考点往往不止一个,数据可能被存储在多个地方,有一些数据流的 Pipeline 级数多达四五级。这种多层次的数据流架构导致了许多问题,例如写入性能不足、实时告警的复杂性、实时分析的延迟和数据分发的资源浪费等。
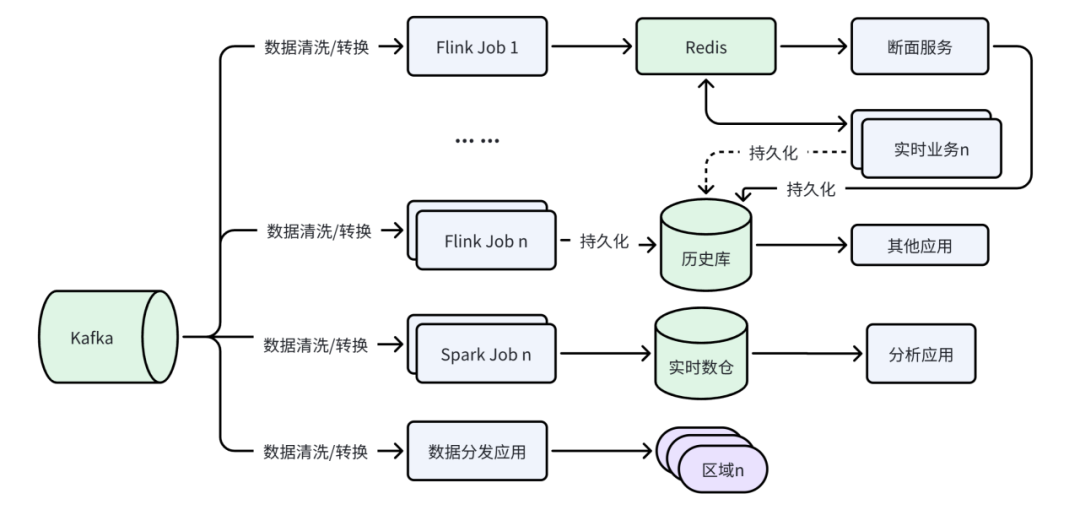
在实时告警方面,实现通常依赖 Kafka、Flink、Spark 和 Redis 的结合,然而,这种架构的复杂性导致数据重复处理,消耗大量资源。实时分析方面,有些企业选择直接在 Flink 中处理数据,还有一些通过搭建数仓的方式,但写入性能的不足使得全量数据难以入库。面对高基数问题,一些人会选择搭建多个实时数仓,这又导致融合变得很难,大大降低数据的关联性和分析的灵活度。此外,数据分发环节也需要从 Kafka 再次消费数据,造成资源浪费和数据一致性维护的高成本。
此前,针对数据治理并没有一个很好的技术方案,很多企业就选择重复消费 Kafka,在很多电网公司省一级公司的营销侧,为满足巨量的消费能力,他们的 Kafka 集群是巨大的,能达到十多个甚至数十个节点,以满足多路应用重复消费数据的需求。大家可以想象,这是一个多么臃肿的架构,但当时确实没有更好的方案,也因此带来了很多难以解决的问题。
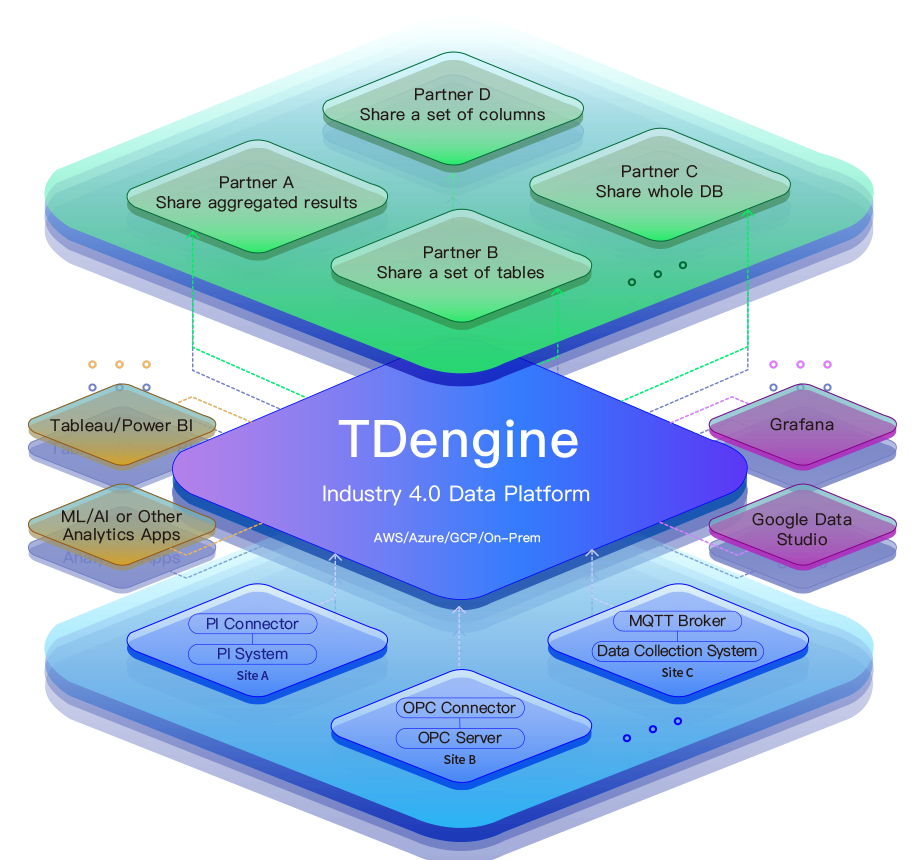
基于 TDengine,我们提出了一种简化的数据处理方案。通过对数据进行一次持久化和清洗,确保在数据进入前就完成治理,避免后续的重复处理。下图中绿色的这几条线代表结构化数据在进行消费,你可以从 TDengine 的实时和历史数据库中用 Flink 对它进行订阅消费,可以把它推送到任何数据源目的地。你的实时应用也可以利用 TDengine 内嵌的消息订阅接口来进行数据订阅,数据可以消费出去,也可以处理后再回写回来。除此之外,应用还可以通过 TDengine 的实时查询方法获取最新数据,驱动相关业务。

以河北电力为例,我们成功实现了全省分布式光伏的接入。他们的省级调度中心和营销中心的数据接入量极大,将近 3000 万表计,达到每 15 分钟 7 亿到 8 亿条报文。借助 TDengine 的结构化实时入库、数据分发,能够高效支持实时业务场景,性能优于传统的 Kafka +ETL 架构。
总结而言,TDengine 作为新型电力系统的时序大数据基座,不仅能够独立运作,也能够与现有的时序数据生态良好结合,替代 Kafka 等传统架构。如果企业已经在现有架构上进行了投资,TDengine 同样能够与之融合,提供更高效的解决方案。这样,我们就能够在新型电力系统的建设中,更加灵活地应对未来的挑战。
新型电力系统 5 类场景分析与挑战

电网调度的现状与挑战
OT 域场景:实时数据库与历史数据库分离,系统的高可用性较为脆弱。
稳态 SCADA 与 WAMS 实时采集:主要依靠这些系统支撑调度业务。
数据存储:目前历史数据主要存储在关系数据库中,仅保留 SCADA 的分钟级数据。
基于上述现状,电网调度面临三大挑战:
新能源发电数据接入难:分布式光伏和配变的接入困难。
回溯与问题分析难:在需要回溯问题时,往往缺乏秒级或毫秒级的断面数据。
数据实时分发难:在某些情况下,数据分发必须通过重复消费 Kafka 进行处理。
针对这些挑战,TDengine 提供了有效的解决方案。
实时与历史库的合一:在 TDengine 中,实时数据与历史数据并无区分,数据写入后即可进行实时订阅,同时成为历史数据的一部分。
全量 SCADA 稳态遥测与遥信实时写入:以前较为困难的任务,如秒级数据的实时写入,现在已经能得到很好的解决。
全面接入与监控:包括 PMU/WAMS、故障录波等中高频数据的实时写入,以及分布式光伏和配变的接入。
实时计算与数据分发:TDengine 支持功率、发电量等多维度的实时聚合计算,并能按需实时分发结构化数据。数据分析师可以通过窗口和流计算的结合,利用 TDengine 的 SQL 和相关函数,无需编写代码即可实现创新查询。
电网营销的现状与挑战
巨量测点数:用户电能表与分布式光伏接入的测点数达到亿级至十亿级,且多数基于 Hadoop 或 GP 方案,这些方案的缺点是要么资源消耗高,要么存在高基数问题。
采集频率提升:频率从 15 分钟逐渐缩短到 1 分钟,数据量持续增长。
业务需求规划难:即席分析功能的满足率低。
由此,电网营销面临的挑战包括:
实时性需求难以满足:数据链路长、批处理延时长。
业务创新受限:即席查询受到限制,数据一致性难以保证。
需求开发周期长:技术栈复杂,数据链路复杂。
功率预测效果不理想。
在电网营销中,TDengine 能够实现亿级测点的实时写入,确保数据的新鲜度和低延时。数据快速接入后,便可进行实时计算,支持负荷评估与综合能源管理。同时,TDengine 还能够满足突发性计算的需求,助力业务创新。
新能源大基地的创新集控
电力湖仓一体的时序数据解决方案
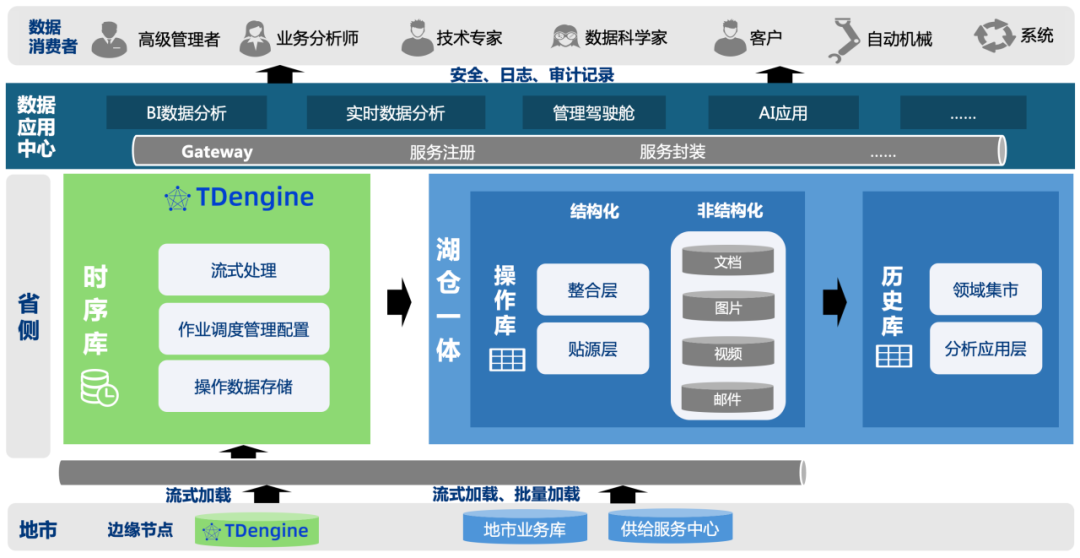
电力时序预测
进入 https://www.taosdata.com/tdgpt 查看 TDgpt 更详细信息
结语

·END·



👇 点击阅读原文,立即体验 TDgpt !
