




导读
作者:七良 云器科技联合创始人&CPO
Kaggle是一个数据建模和数据分析竞赛平台。企业和研究者可在其上发布数据,统计学者和数据挖掘专家可在其上进行竞赛以产生最好的模型。这一众包模式依赖于这一事实,即有众多策略可以用于解决几乎所有预测建模的问题,而研究者不可能在一开始就了解什么方法对于特定问题是最为有效的。Kaggle的目标则是试图通过众包的形式来解决这一难题,进而使数据科学成为一场运动。
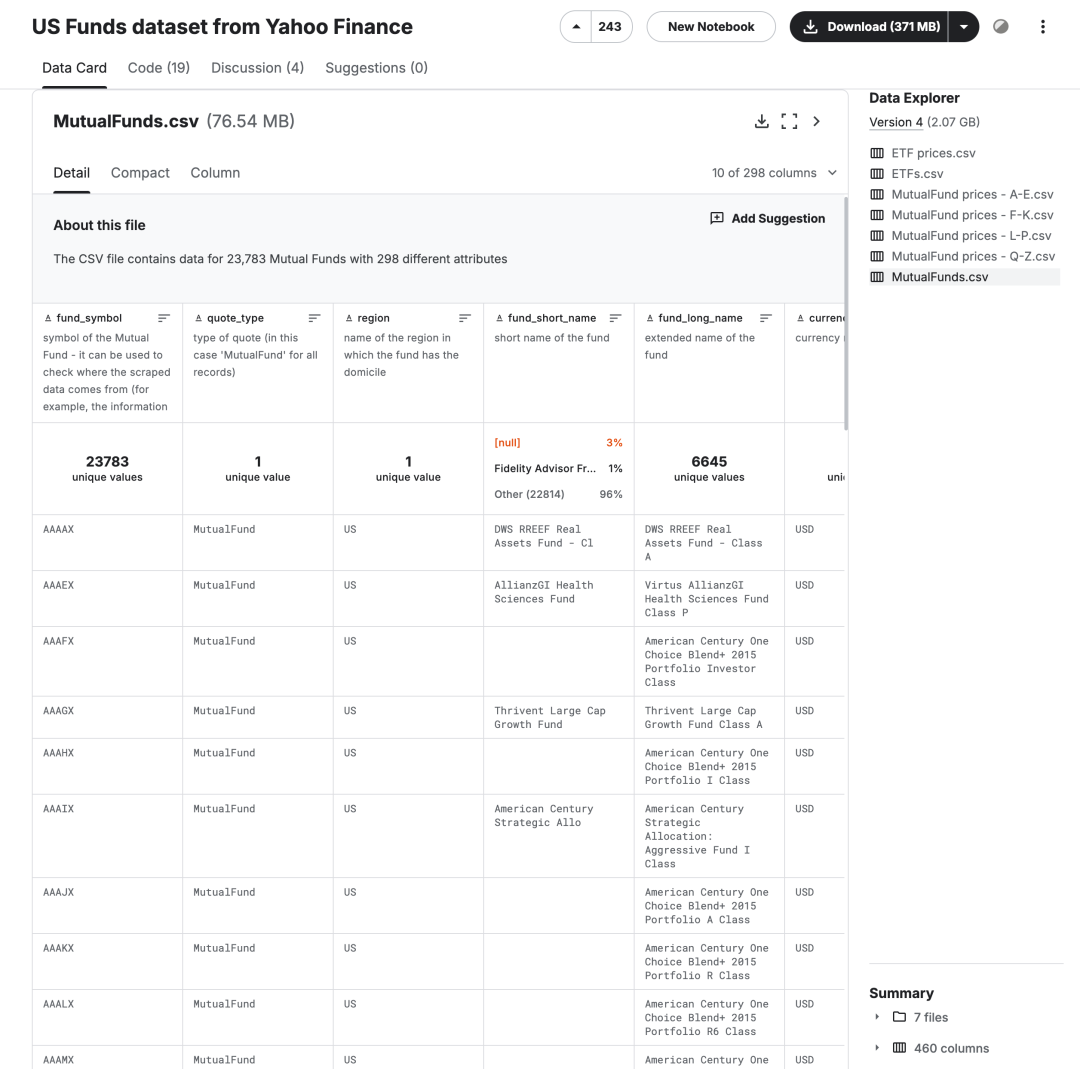
US Funds dataset from Yahoo Finance是Kaggle上的一个数据集,该数据集包括从 Yahoo Finance 收集的财务信息,包括所有美国共同基金、ETF及其历史价格。更新版本涉及 2021 年 11 月的数据。该数据集包含 23,783 只共同基金和 2,310 只 ETF,其中包括:
一般基金方面(例如总净资产、基金家族、成立日期等) 投资组合指标(如现金、股票、债券、行业等) 历史年度和季度回报(例如年初至今、1 年、3 年等) 财务比率(市盈率、特雷诺比率和夏普比率、阿尔法比率和贝塔比率) ESG 分数
任务一:如何快速生成这些文件对应的表结构需要的DDL语句-LLM or 手写 or Python?
不同于玩玩具的玩数据,只是一个简单的表,10来个字段,手写一把,问问大模型,都可以很快的生成需要的DDL语句。话说有460个字段,近亿行数据,手写是不行的。试试Kimi吧,看看Kimi能不能帮上这个忙。
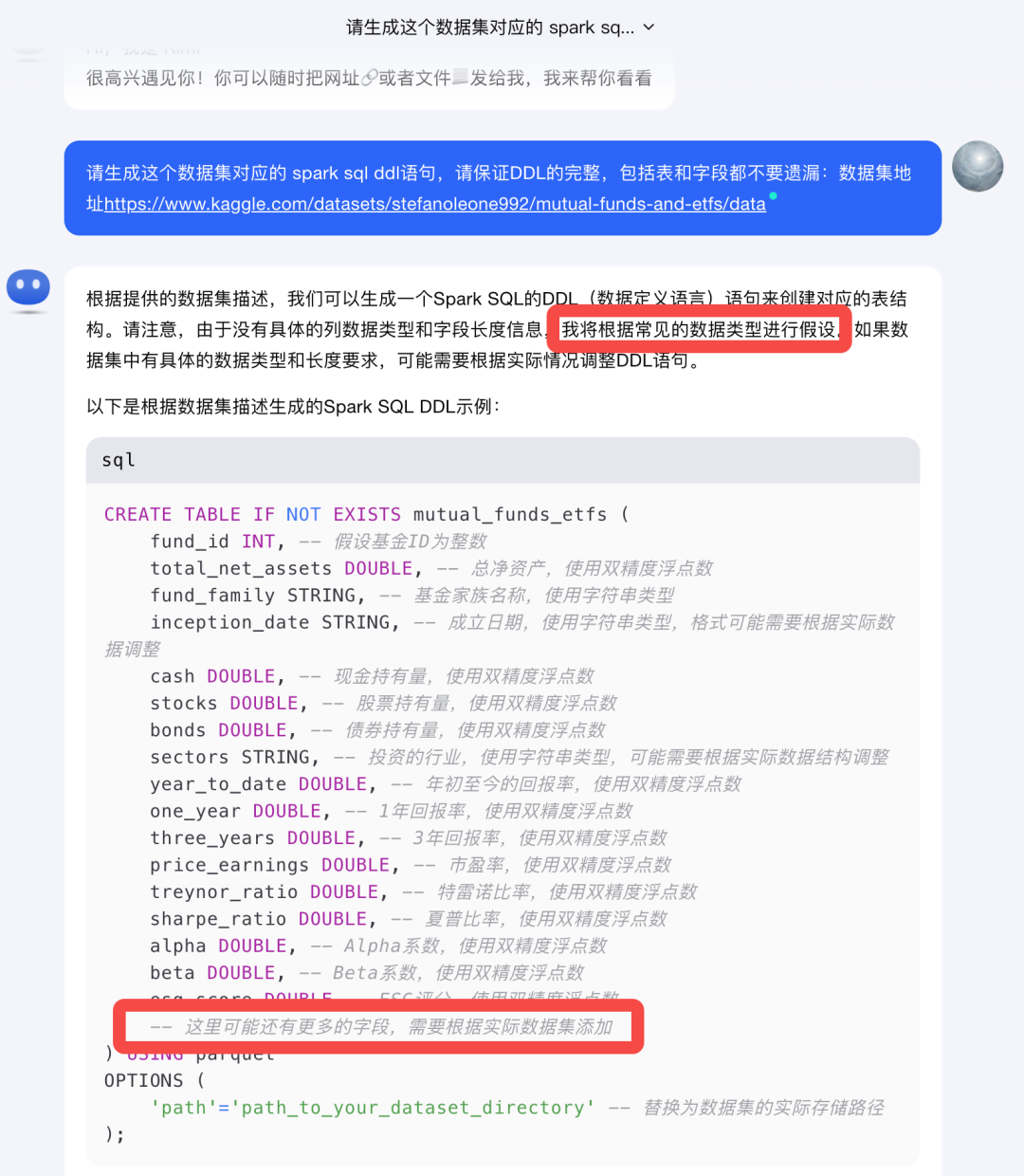
Kimi给的这个首先是假设,都没有去访问网页内容,Kimi也是变懒了。大模型不像刚出来那样爱干活了,这完全没法用啊!再试试Azure Copilot、智谱CodeGeeX,都是这样,对于这种依赖外部信息、几百个字段的表都没法生成需要的SQL DDL语句。
✅换个思路:从Kaggle下载文件放在当前目录的data/USFundsdatasetfromYahooFinance下。让Azure Copilot写个Python程序,生成CSV文件对应的SQL DDL。
import osimport pandas as pdfor dirname, _, filenames in os.walk('./data/USFundsdatasetfromYahooFinance'):for filename in filenames:if filename.startswith('.'):continue # 跳过隐藏文件if filename.endswith('.csv'): # 只处理CSV文件file_path = os.path.join(dirname, filename)df = pd.read_csv(file_path) # 加载CSV文件内容schema = df.dtypes.to_dict() # 获取数据类型table_name = os.path.splitext(filename)[0]# 去掉空格并将空格后的第一个字符变成大写table_name = ''.join(word.capitalize() for word in table_name.split())ddl = f"CREATE TABLE {table_name} (\n"for column, dtype in schema.items():if 'int' in str(dtype):ddl += f" {column} BIGINT,\n"elif 'float' in str(dtype):ddl += f" {column} DOUBLE,\n"elif 'date' in str(dtype):ddl += f" {column} DATE,\n"else:ddl += f" {column} STRING,\n"ddl = ddl.rstrip(',\n') + "\n);" # 去掉最后一个逗号并添加括号print(f'CSV文件路径: {file_path}')print(f'SQL DDL语句:\n{ddl}')print('---')
看下结果
(因篇幅原因省略部分,可通过https://www.yunqi.tech/resource/blogs/technical-lakehouse-kaggle-data查看完整代码)
CSV文件路径: ./data/USFundsdatasetfromYahooFinance/ETF prices.csvSQL DDL语句:CREATE TABLE EtfPrices (fund_symbol STRING,price_date STRING,open DOUBLE,high DOUBLE,low DOUBLE,close DOUBLE,adj_close DOUBLE,volume BIGINT………CSV文件路径: ./data/USFundsdatasetfromYahooFinance/.ipynb_checkpoints/ETF prices-checkpoint.csvSQL DDL语句:CREATE TABLE EtfPrices-checkpoint (fund_symbol STRING,price_date STRING,open DOUBLE,high DOUBLE,low DOUBLE,close DOUBLE,adj_close DOUBLE,volume BIGINT);---
相比手写,一个是快速,一个是准确。基本的用来建表的DDL语句这就有了。
检查一下,把几个日期字段的数据类型改为Date,把表的名字规范一下,就形成了云器Lakehouse兼容的建表DDL语句了。
任务二:在云器Lakehouse里建模,存放数据
在数据处理过程中,我们首先对 ETFs、ETFPrices、MutualFunds 和 MutualFundPrices 这四张表的列进行了重命名和添加注释的操作,以便更好地理解和管理数据。
对于 ETFs 表,我们涵盖了基金代码、报价类型、地区、基金简称、基金全称、货币、基金类别、基金家族、交易所代码、交易所名称、交易所时区、平均成交量、总净资产等众多关键信息。
对于 ETFPrices 表,主要记录了基金代码、价格日期、开盘价、最高价、最低价、收盘价、调整后收盘价和成交量等价格相关数据。
对于 MutualFunds 表,包含了基金代码、报价类型、地区、基金简称、基金全称、货币、初始投资、后续投资、基金类别、基金家族、交易所代码、交易所名称、交易所时区、管理人姓名等详细信息。
对于 MutualFundPrices 表,重点记录了基金代码、价格日期和每股净值。
云器Lakehouse内置了SQL IDE开发界面,将Python生成的SQL DDL语句COPY进IDE执行即可,在执行之前,先创建一个schema,并且指定使用该schema:
CREATE SCHEMA IF not exists usfundsdatasetfromyahoofinance;USE SCHEMA usfundsdatasetfromyahoofinance;
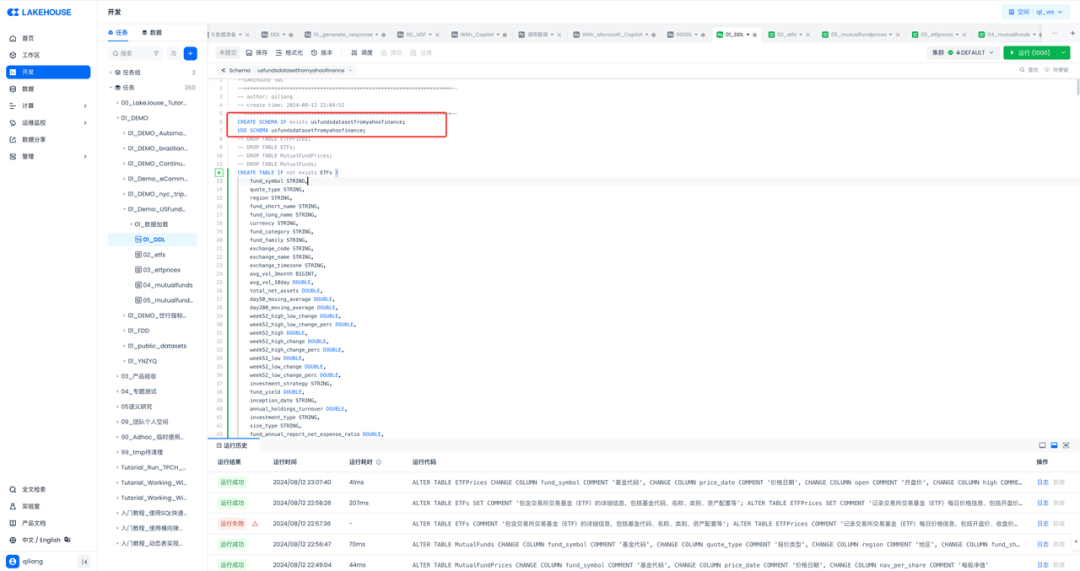
完整的DDL可通过云器官网查看。
(通过https://www.yunqi.tech/resource/blogs/technical-lakehouse-kaggle-data查看完整代码)
任务三:给表和字段加上中文注释,方便中文口径的对齐
由于每个表的字段很多,4张表有460个字段,根据经验这样的活还是交给Azure Copilot比较靠谱。也是经过分段处理,Azure Copilot最终还是帮忙生成了字段和表的注释语句。
(因篇幅原因省略部分,可通过https://www.yunqi.tech/resource/blogs/technical-lakehouse-kaggle-data查看完整代码)
ALTER TABLE ETFsCHANGE COLUMN fund_symbol COMMENT '基金代码',CHANGE COLUMN quote_type COMMENT '报价类型',CHANGE COLUMN region COMMENT '地区',CHANGE COLUMN fund_short_name COMMENT '基金简称',CHANGE COLUMN fund_long_name COMMENT '基金全称',CHANGE COLUMN currency COMMENT '货币',CHANGE COLUMN fund_category COMMENT '基金类别',CHANGE COLUMN fund_family COMMENT '基金家族',CHANGE COLUMN exchange_code COMMENT '交易所代码',CHANGE COLUMN exchange_name COMMENT '交易所名称',CHANGE COLUMN exchange_timezone COMMENT '交易所时区',CHANGE COLUMN avg_vol_3month COMMENT '三个月平均成交量',CHANGE COLUMN avg_vol_10day COMMENT '十天平均成交量',CHANGE COLUMN total_net_assets COMMENT '总净资产',……
任务四:将CSV文件里的数据加载到云器Lakehouse的表中
人总是喜欢简单的,加载数据这个活,试试云器Lakehouse内置的数据上传功能,期望点几下鼠标就能完成:
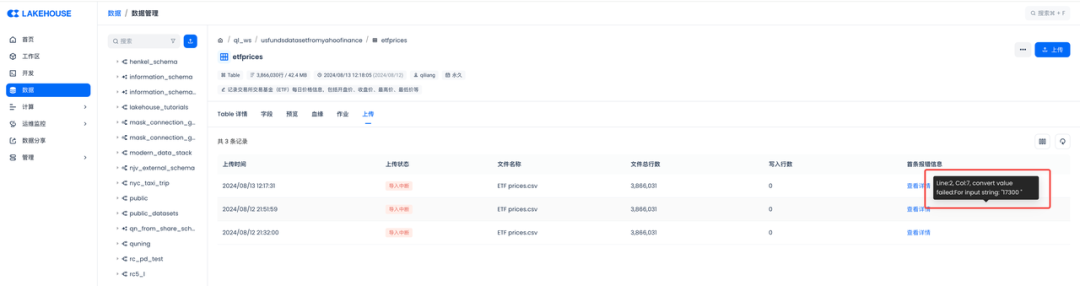
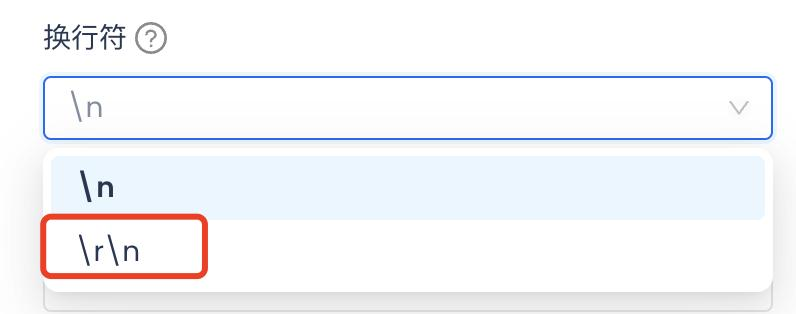
读取csv文件,最后一列多读了个空格还是什么特殊字符,导致string类型转整型失败了。小遇挫折。(补充一下:后来有同学反馈发现是换行符需要设置为\r\n,而不是缺省的\n,就可以了,如下:)
想想,云器Lakehouse内置的数据加载功能,还有离线同步这种方式。但是不支持从本地文件同步,那就把数据放在阿里云的对象存储,从对象存储OSS加载到云器Lakehouse的表中。
将本地文件上传到阿里云OSS,推荐使用OSS浏览器,一款笔者用了10年的老工具:
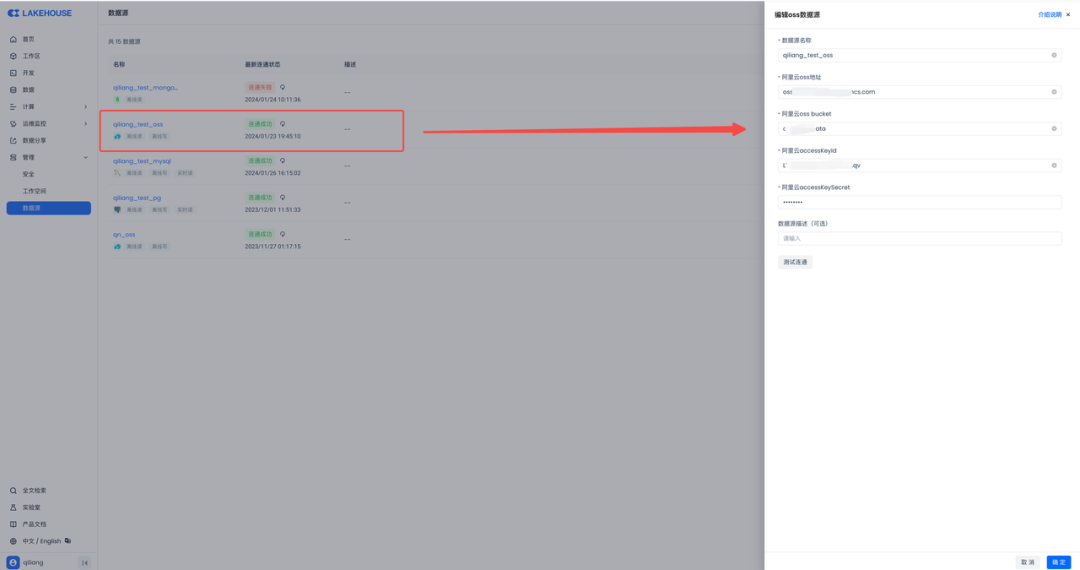
然后在云器Lakehouse里新建一个数据源,连上阿里云OSS:
新建几个离线同步任务:
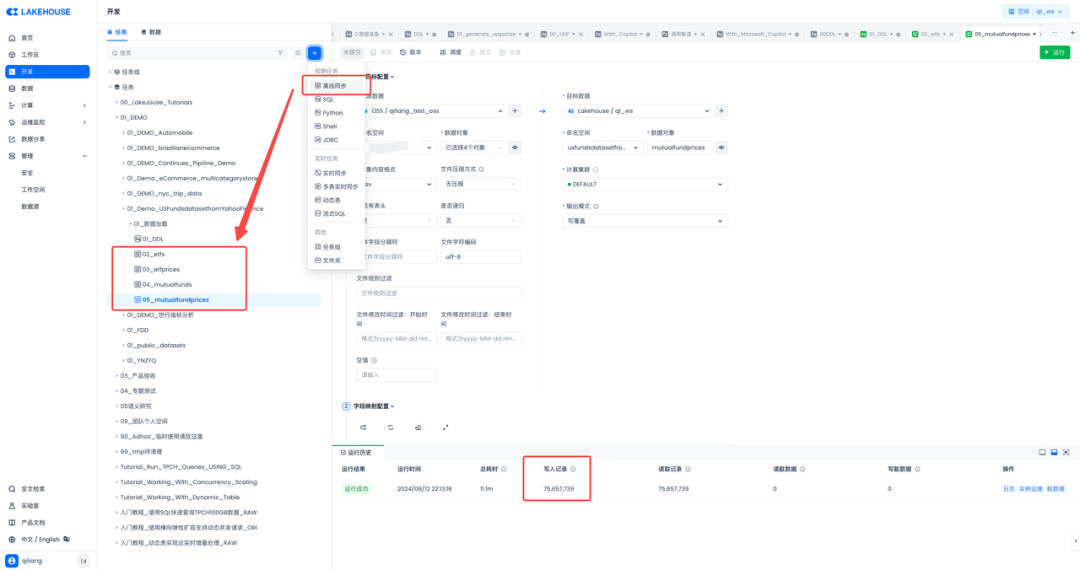
很顺利,一次成功。最大的表有7千多万条记录,不少呢!
任务五:检查导入到云器Lakehouse的数据
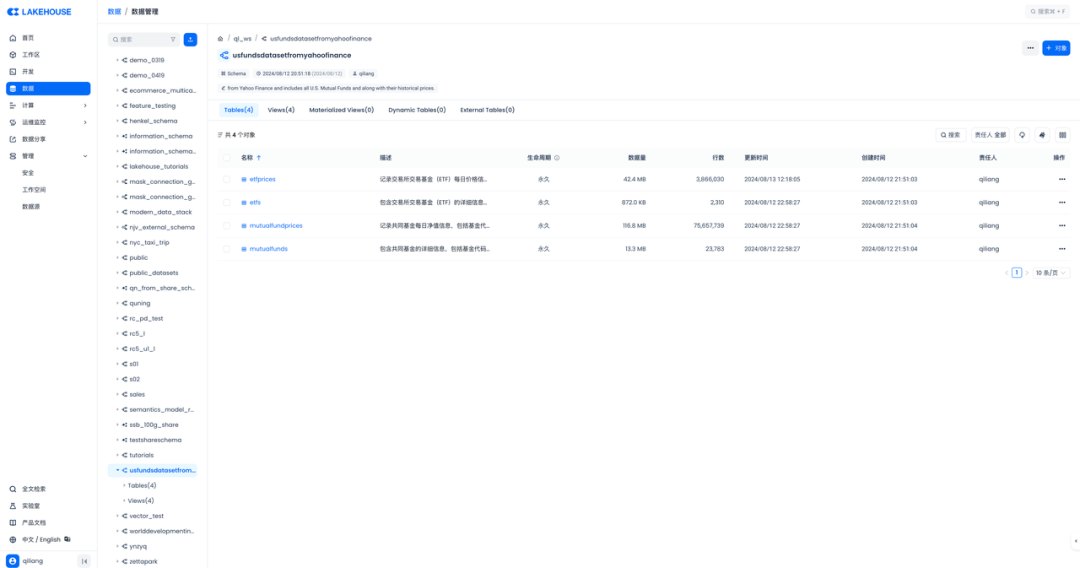
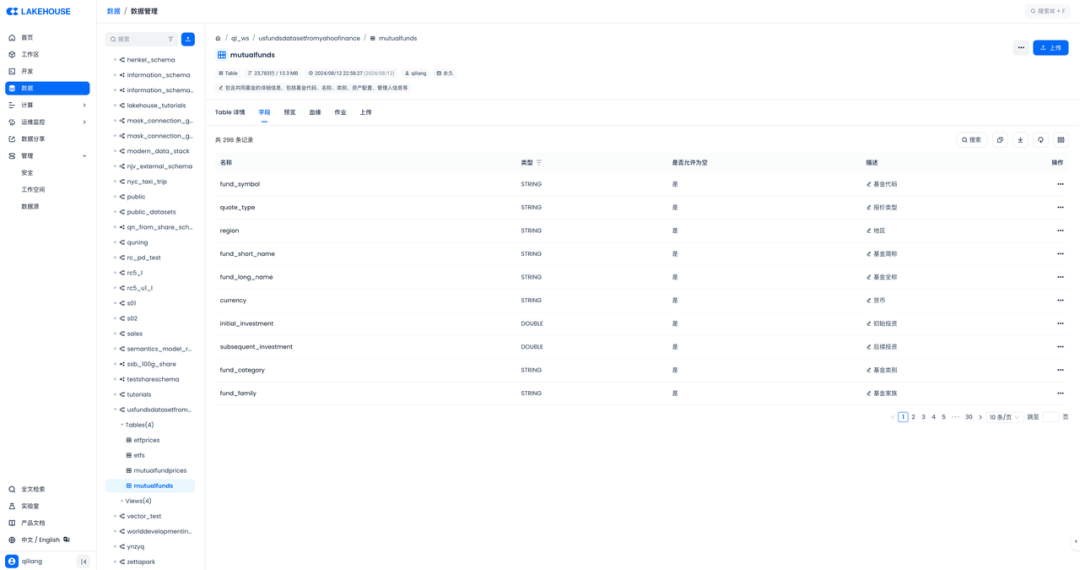
检查表结构、表注释、字段注释都有的。
✅话说为什么一定要给表、字段加上注释呢?因为后面会用到大模型分析数据,所以从数据工程师的工作开始,就是把数据处理的要对大模型友好啦!好的AI来自好的数据么!
任务六:用云器DataGPT对数据进行探索
说到数据分析,笔者也有一个用了10几年的老工具,就是Tableau。不过这次笔者不打算用Tableau了,也不打算用SQL来分析数据了。云器Lakehouse内置了对话式分析工具DataGPT,AI加持的工具,体验一下看看如何呢。
内置就是好,刚才在Lakehouse里建好的表,导进来的数据,那是拿来就用,省了数据同步,减少了数据不一致。
只要将Lakehouse的表添加进DataGPT的数据集,DataGPT就会自动为表的数据创建数据档案,对每个字段的数据分布进行统计分析,方便快速了解数据。
任务七:在DataGPT创建指标
明确的指标定义可以避免产生歧义。虽然可以让大模型发挥进行语义理解和匹配,但是会带来很大的不确定性,为了提高问题理解到精准性,通过指标名称可以做到精准匹配。指标定义内容是通过SQL来表达从而来提升生成SQL的准确性。
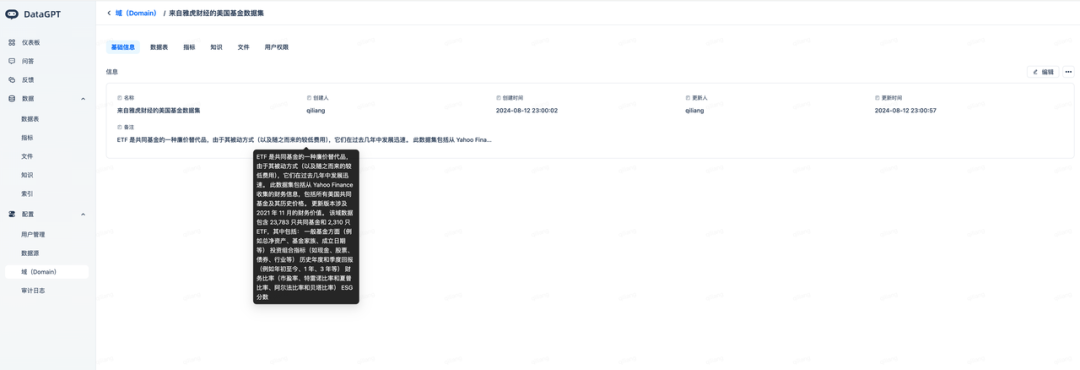
任务八:创建单独的域
域(Domain)划分:将数据集表、指标、文件等对象,按照不同业务域进行隔离,避免产生歧义;如:销售业绩在财务域与销售域的指标定义。本实验中为US Funds dataset from Yahoo Finance数据集及相关指标创建了如下单数的域(Domain):
任务九:在DataGPT进行数据分析
💡每年的CP?CP是啥?
CP不是Cose Play,而是收盘价的黑话:
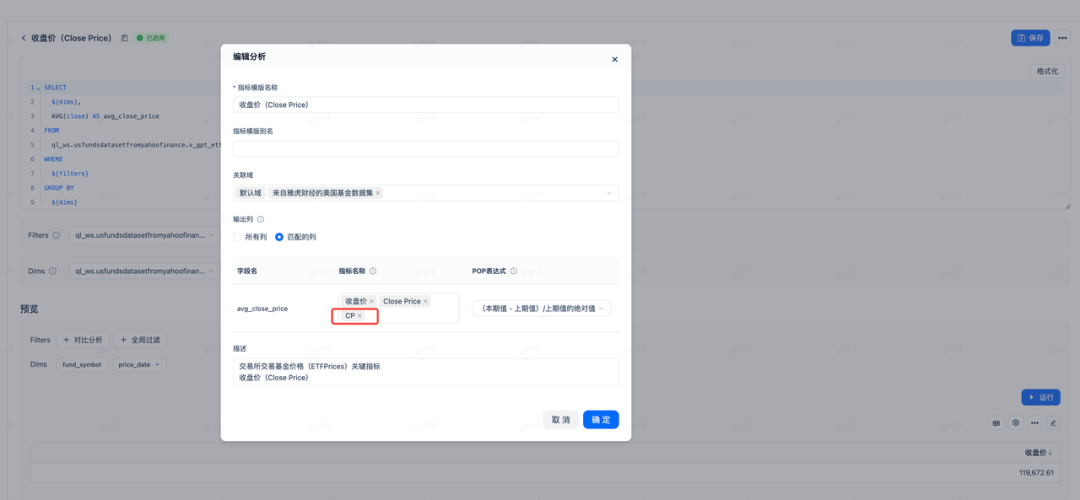
通过精细且准确的指标定义,我们成功地大幅提升了大模型在将文本语义转换为 SQL 语句时的准确性。这种指标定义不仅涵盖了语义理解的深度和广度,还包括了对语法结构和逻辑关系的精确把握。它为大模型提供了明确的方向和标准,使其能够更加准确地捕捉文本中的关键信息,并将其转化为准确无误的 SQL 翻译。
总结
本文讨论了在云器 Lakehouse 上处理 Kaggle 数据集中的 US Funds dataset from Yahoo Finance 的过程,包括生成表结构的 DDL 语句、建模存放数据、添加中文注释、加载数据、检查数据以及使用 DataGPT 进行探索分析等任务。
关键要点包括:
生成 DDL 语句:使用 Python 程序根据 CSV 文件生成建表的 DDL 语句,并对日期字段数据类型和表名进行规范。 建模存放数据:对表的列进行重命名和添加注释,在云器 Lakehouse 中创建 schema 并执行 DDL 语句创建表。 添加中文注释:借助 Azure Copilot 为表和字段生成中文注释。 加载数据:尝试内置数据上传功能,因格式问题失败后采用离线同步方式,从阿里云 OSS 加载数据。 检查数据:检查表结构、表注释和字段注释。 数据探索分析:使用云器 Lakehouse 内置的 DataGPT 进行数据探索、创建指标和业务域,并进行数据分析。
END
▼点击关注云器科技公众号,优先试用云器Lakehouse!
关于云器
往期推荐
