






阿里云瑶池旗下的云原生数据库PolarDB分布式版(PolarDB for Xscale,简称PolarDB-X),采用集中式和分布式一体化的架构,为了能够灵活应对混合负载业务,作为数据存储的 Data Node 节点采用了多种数据结构,其中使用行存的结构来提供在线事务处理能力,作为 100% 兼容 MySQL 生态的数据库,DN 在 InnoDB 的存储结构基础上,进行了深度优化,大幅提高了数据访问的效率。
B+tree结构
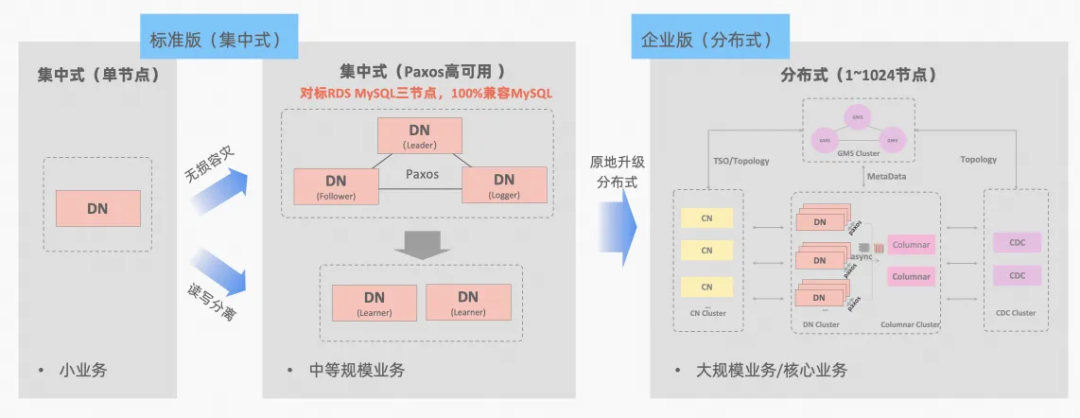
真实世界中的应用负载是多种多样的,不同的数据系统会采用适用于其存储和检索特点的数据组织方式,常见的有 B-tree、LSM-tree、Hash Map、Heap Table、R-tree 等。其中,B-tree 及其变种在关系型事务系统要求的高效检索、磁盘 IO 优化、范围查询支持、并发控制、事务安全性等方面表现均衡,可谓「六边形战士」,因此被主流 OLTP 数据库所采用。MySQL InnoDB 使用 B+tree 作为索引组织结构。
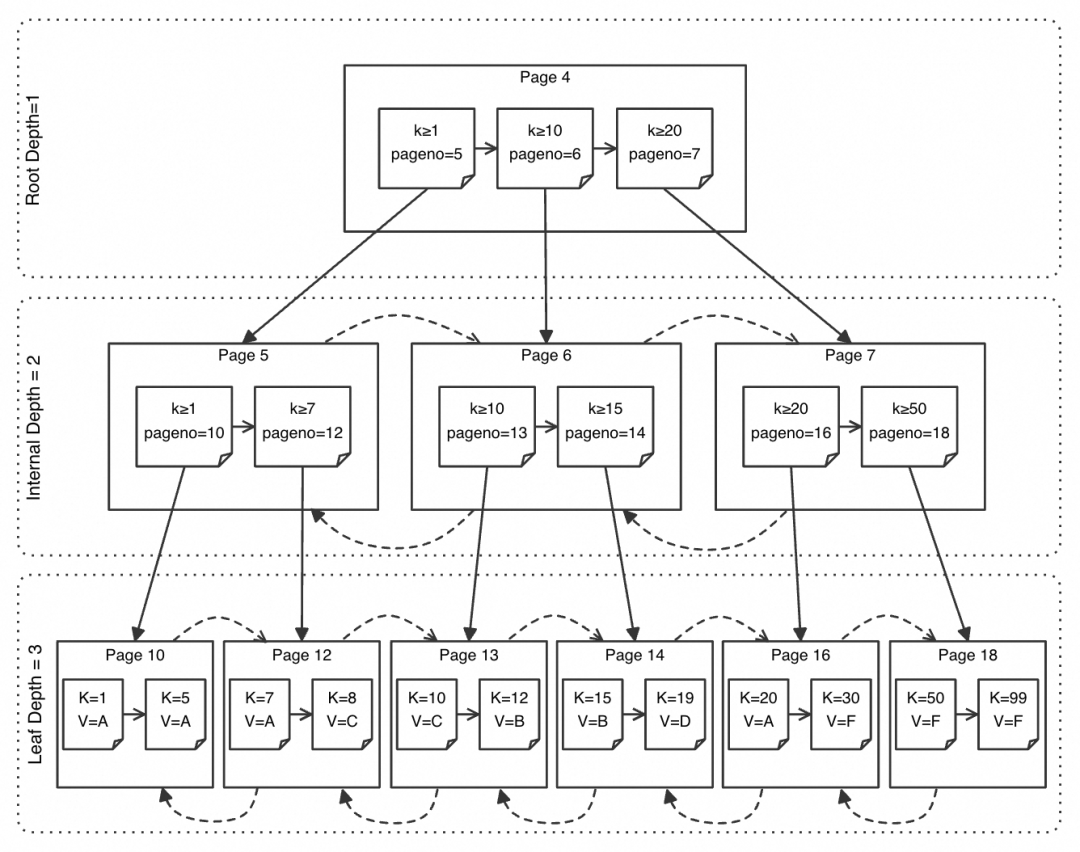
数据表结构
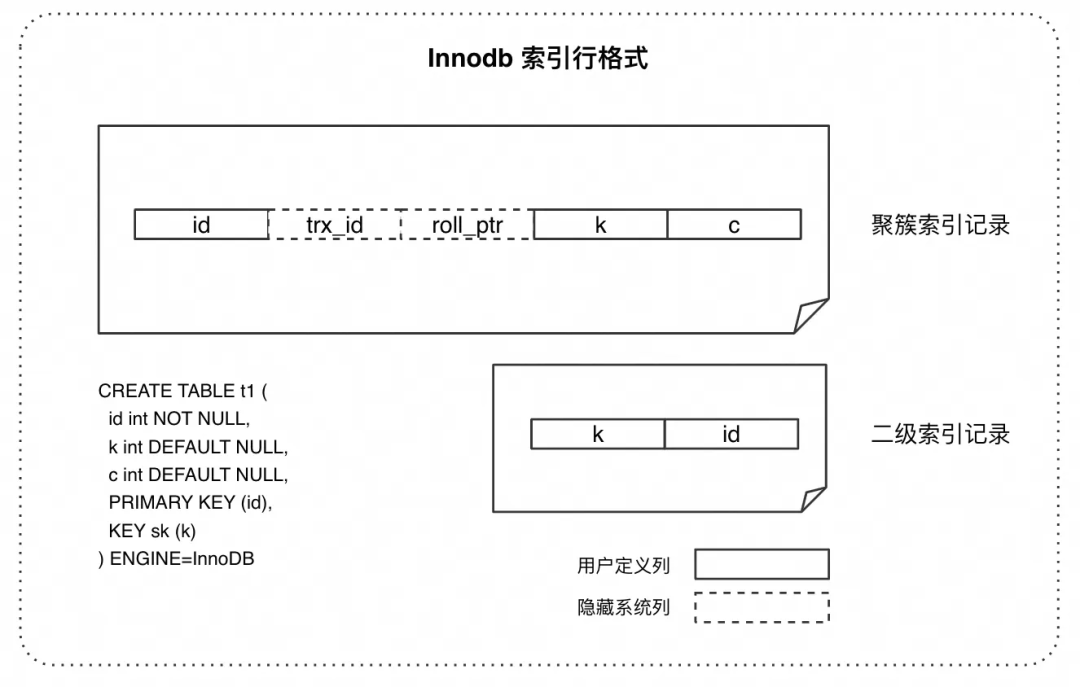
对 InnoDB 数据的访问可以分为两个步骤, B+tree 索引上的数据定位,以及数据可见性的判断和构建。
数据定位
树形查找:B+tree 是一种自平衡的多叉树,查找过程由根节点开始,沿着树结构自上而下进行页面跳转。树形查找的次数与树的高度相等,每层访问一个页面。
页内查找:B+树的每个页面存储多个键值对。在叶子节点,记录对应实际的行数据;而在非叶子节点,键(Key)与叶子节点一致,值(Value)指向下一层级的页面。在非叶子节点中,通过二分查找目标键,决定跳转到下一层的具体页面;达到叶子节点后,再进行一次二分查找,便可准确找到所需的数据。
▶︎ 聚簇索引定位
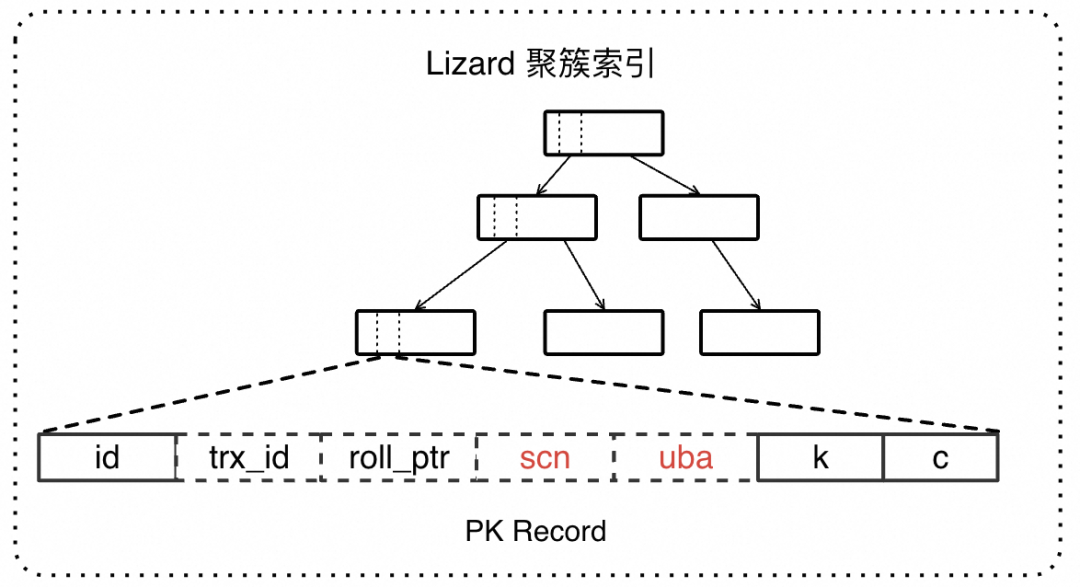
聚簇索引是InnoDB默认的主键索引,由于聚簇索引的叶子节点直接存储了完整的数据行,因此一旦找到叶子节点,查找过程就完成了。
▶︎ 二级索引回表定位
由于二级索引不包含完整的数据行,因此在使用二级索引查找时,可能需要进行回表操作。考虑上图中的表结构,对于查询语句 select * from t1 where k > 1,选择二级索引可以避免全表扫描,但二级索引记录中并没有 c 字段的值,因此扫描到符合 k>1 的二级索引记录后,还需要根据记录上的 pk 值,「返回」聚簇索引上扫描得到完整的行记录。
上述场景就是回表查询的典型例子。所谓「二级索引回表查询」,就是由于二级索引存储信息的不充分,需要先扫描二级索引 B+tree,再扫描聚簇索引 B+tree 的查询过程。
数据可见性
在InnoDB存储引擎中,数据定位只是数据访问的第一步。在某些场景下,出于多版本并发控制(MVCC)的需要,还需要进行数据可见性判断,以确保返回的数据符合事务隔离级别的要求。InnoDB 的 MVCC 实现主要依赖行记录上的隐藏系统列 trx_id/roll_ptr,可见性视图 Read View 和 Undo log。
每个数据行都有两个隐藏的列,用于记录事务信息:
roll_ptr:指向 undo log 的指针,用于存储该行的旧版本。
InnoDB MVCC 主要体现在两个方面:
活跃事务判断。Read View 是事务为了实现一致性读记录的当前活跃事务的快照,创建时拷贝了全局活跃事务数组。当事务定位到某条记录,会根据记录上的 trx_id 与事务的视图 Read View 进行比较来判断当前记录是否活跃。 历史版本构建。Undo log 中记录着记录的历史版本数据,若记录当前版本不可见,则可以通过行上的 roll_ptr 指向事务对应的 undo log,构建出记录的前版本,实现快照读机制。
数据访问成本分析
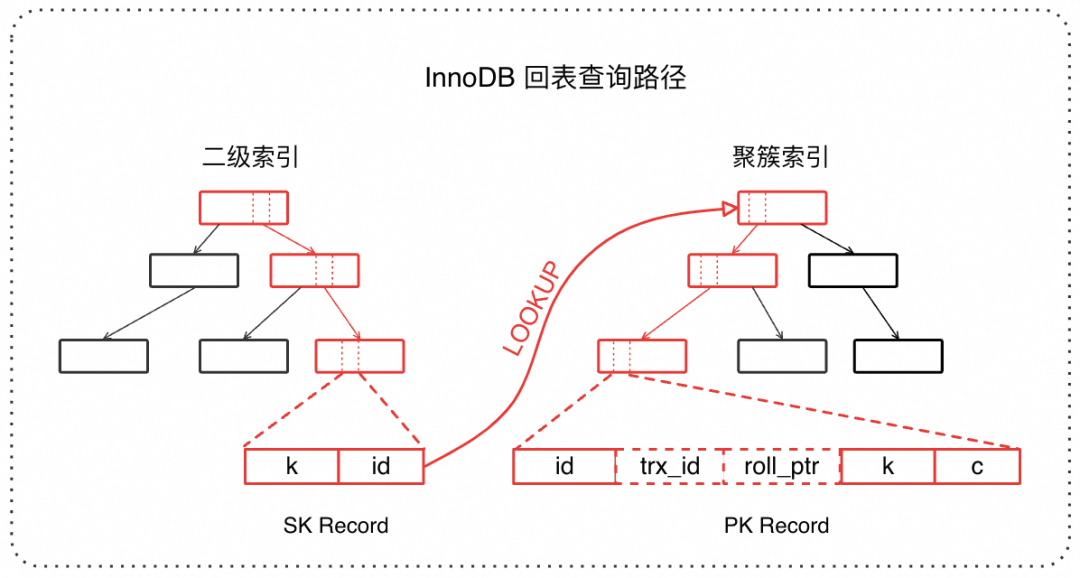
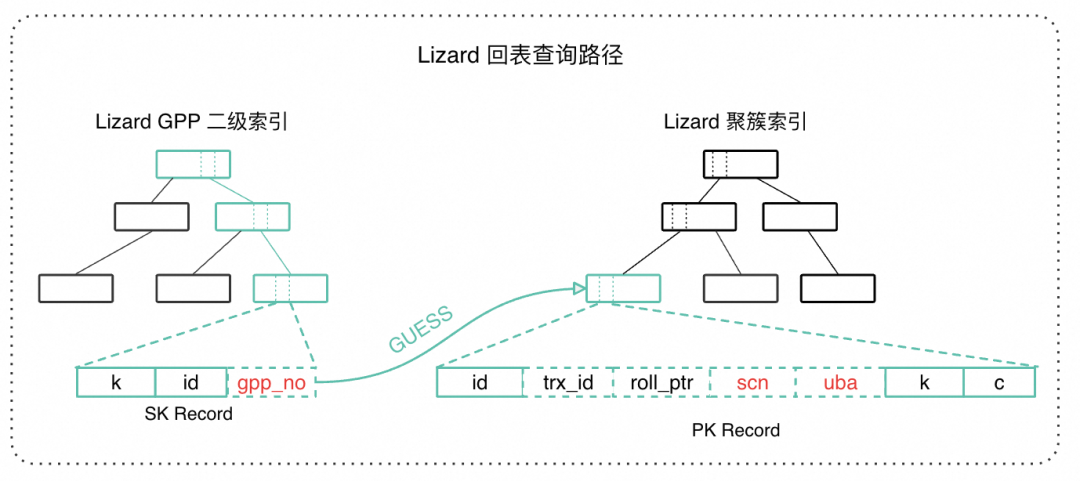
由于二级索引上不包含全量用户信息和可见性判断需要的系统列,二级索引的回表查询占据了数据定位的很大部分。如下图红色路径所示,回表查询相对于聚簇索引查询和不回表的二级索引查询,多了一次聚簇索引 B+tree 的完整扫描。多出来的这条 PK LOOKUP 路径会对磁盘 IO、BufferPool 空闲页、B+tree 并发控制等模块带来额外的压力。特别是在大 range 查询中,如果每条记录都要回表,那么回表代价将成为主要开销,对查询的 RT 和整体吞吐都会带来巨大影响。
InnoDB 可见性判断需要访问全局结构(全局活跃事务数组),这个过程需要在一个事务大锁的保护下完成,并且 MVCC 的视图 Read View 是一个数组,无法固定大小和高效传播。随着 CPU 多核能力的大幅加强,目前的设计越来越成为制约 InnoDB 事务性能的瓶颈。以 PolarDB-X DN 节点在公有云上目前售卖的最大规格(polarx.st.12xlarge.25, 90C, 720G, 最大并发连接数2W)为例,压测 Sysbench read_write 场景,CPU 有接近 17% 的时间耗在无用的等待上。
针对 InnoDB 的以上问题,Lizard 事务系统设计了特有的索引结构,显著降低了数据访问成本,提升了系统整体性能。
聚簇索引结构
针对可见性判断代价的优化,Lizard 事务系统在聚簇索引上引入 scn/uba 系统列,表达事务的提交顺序,解绑对全局结构的访问依赖,将 Read View 数组升级为只有一个 SCN 数字的 Vision,易于传播。
🔗 https://zhuanlan.zhihu.com/p/654126910
GPP二级索引结构
PolarDB-X Lizard 事务引擎通过实现 Guess Primarykey Pageno (GPP) 方案,大大减少二级索引回表代价。其索引行格式如下图所示。
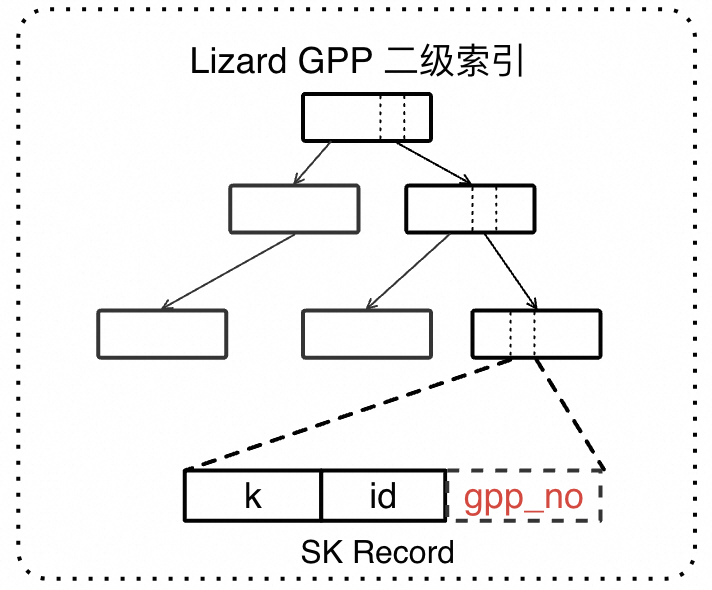
针对回表查询路径的优化,在二级索引上,Lizard 新引入 gpp_no 系统列,表示对应的聚簇索引记录所处 page 的 "guess" pageno。所谓 "guess",意指 gpp_no 是对主键位置的一种猜测,不保证一定正确。下面通过 insert 流程来解释 gpp_no 是如何生成和记录的。
InnoDB 的插入流程遵循先插聚簇索引,后插二级索引的顺序。在主键插入成功之时,我们可以获知主键记录在当下的准确位置(pageno),后续插入二级索引时,我们将上一步获知的 pageno 作为 gpp_no 填入二级索引记录,以供之后的回表查询使用。
▶︎ 回表查询
借助 gpp_no, GPP 二级索引显著缩短了回表查询路径。如下图绿色路径所示,在二级索引 B+tree 上定位到记录后,我们首先取得 gpp_no 对应的页,对其二分查找尝试获取对应的主键记录,如果获取成功,那么就免去了一次聚簇索引上的完整 B+tree 扫描。GPP 是对回表查询的一种短路方法,直观地降低了回表查询的 RT,同时也降低了回表查询对系统整体的 Buffer Pool/IO 等资源的压力,可以显著提高系统整体吞吐量。
▶︎ GPP 代价
空间代价
Lizard 在二级索引上扩充了 gpp_no 隐藏系统列,会让二级索引单条记录增加 4B。以 Sysbench 测试的典型表结构为例,GPP 的引入使整张表的存储空间上涨 4.6%,相对于性能的显著提升,「以空间换时间」的策略在二级索引回表查询场景下特别合适。
命中率代价
既为 "guess",那么自然会有 gpp_no ≠ 实际 pk pageno 导致无法命中的情况出现,这发生在 B+tree 树形结构变化后。当聚簇索引 B+tree 进行数据更新时,若数据的变动仅限于叶子页面内部,由于我们记录的 gpp 额外信息不包含记录的 offset,所以原记录在页内的地址变化不会造成 GPP MISS。
而当聚簇索引 B+tree 的数据更新引发叶子节点分裂时,原 page 中的一半数据会被移动至新的 page,那么这部分 pk 记录对应的二级索引 gpp_no 就会变为不准确的值;同理,叶子节点发生合并时,也会有 pk 记录的搬迁,造成命中率下降的问题。
虽然会有无法命中的概率出现,但在随机插入数据,命中率约 50% 的测试场景中,GPP 二级索引回表仍然表现出显著的性能提升,说明命中后短路操作的收益远大于未命中造成的额外代价。另外,对于表结构为隐藏主键,或是以主键顺序导入数据的场景,可以触发 InnoDB B+tree 插入点分裂优化,不搬迁原叶子节点中的数据,保证 GPP 命中率维持高位。
▶︎ Cleanout
一条 pk 记录由于 B+tree 的分裂/合并而被搬迁到其他数据页后,其二级索引 gpp_no 将一直保持无法命中的状态。GPP 实现了回表查询的 Cleanout 方案,对命中率进行“事后补救”。回表查询过程中,如果当前记录的 gpp_no 为错误值,那么会记录重走聚簇索引扫描后准确的 page_no,将 gpp_no 回填为正确值,以便下次回表查询可以命中。
虽然 Cleanout 带来了部分代价,但可以为后续的查询奠定命中率基础,尤其在读多写少,B+tree 结构比较稳定的场景下,Cleanout 机制可以为系统整体吞吐带来提升。
▶︎ 业界对比
Oracle Heap-Organized Table
row_id 直接对应到堆表数据页中的记录,省去了 GPP 最后仍需页内二分查找的代价。
B-tree 上记录的 row_id 一定能准确找到数据,没有 GPP 命中率问题。
劣势在于:
没有聚簇索引的概念,所有的索引扫描完毕后都需要访问堆表页(覆盖索引除外),而 InnoDB 聚簇索引扫描到叶子节点可以获得全部数据。
堆表有行迁移问题,row_id 的查找可能不止一跳。
PostgreSQL
与 Oracle 类似,PostgreSQL 同样采用数据存储在 Heap 上的策略,所有的索引都是二级索引,数据的访问需要经历 B-tree 和 Heap 两个结构。其与 Lizard GPP 的对比和 Oracle 相似。
Oracle Index-Origanized Table
Oracle IOT row_id 直接查找到记录,无需页内二分查找。
Oracle IOT 没有 cleanout 机制,row_id 失效没有补救手段。
性能表现
我们在Intel 8269CY 104C 物理机上,部署polardbx-engine[2]。测试数据为 Sysbench 16 张 1 千万行数据的表。分别对聚簇索引 SCN 事务系统和 GPP 二级索引进行测试。
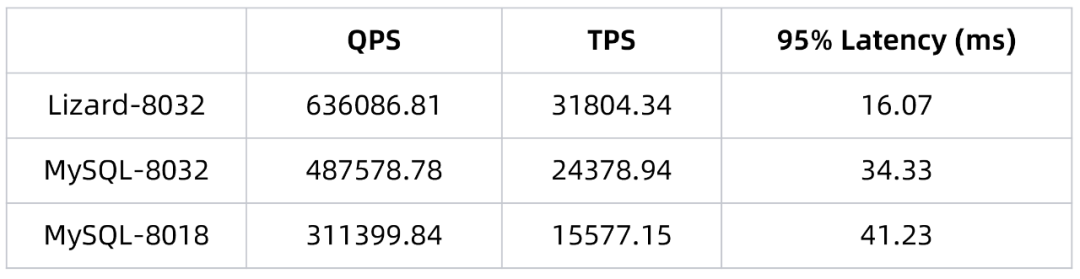
▶︎ GPP 二级索引
我们仿照 Sysbench oltp_read_only/oltp_point_select 构造了回表查询的只读场景。
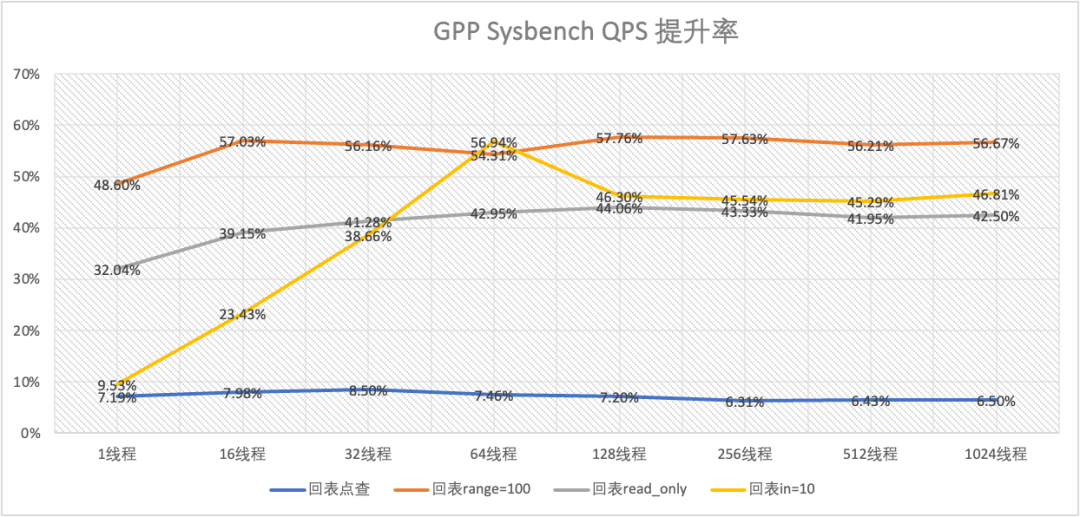
上图是 GPP 二级索引相对于未开启 GPP 的 polardbx-engine 在 qps 上的提升率。可以看到 GPP 在回表查询场景中全面领先,特别是在 range=100 的大 range 场景,查询性能提升可达 50%以上。
相关链接
[1] https://blog.jcole.us/2013/01/10/btree-index-structures-in-innodb/
[2] https://github.com/polardb/polardbx-engine




 点击了解 PolarDB分布式版
点击了解 PolarDB分布式版
