




0 场景描述
有一张入库成本表,一个商品每次入库就会产生一条数据,里面包含商品id,入库时间,以及入库采购的成本.但由于某些某些原因,导致表中某些数据的成本是有丢失的.现在的逻辑是,当成本丢失时,有两种取成本的方式,现在需要把两种成本都取出来,最后取2次成本的平均值作为本次入库的成本。取数逻辑如下:
1.取同一个商品最近一次入库的有效成本(即存在成本时就为有效成本,无效成本为null)
2.取同一个商品紧接着一次入库的有效成本
3 上述中结果依然有无效值时,记为0
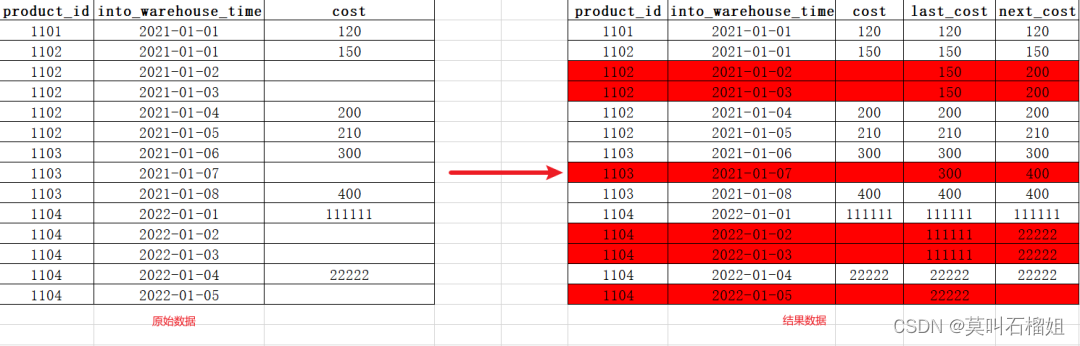
1 数据准备
Hive开发环境
create table cost as (
select stack(
14,
'1101', '2021-01-01' , 120 ,
'1102', '2021-01-01' , 150 ,
'1102', '2021-01-02' , null ,
'1102', '2021-01-03' , null ,
'1102', '2021-01-04' , 200 ,
'1102', '2021-01-05' , 210 ,
'1103', '2021-01-06' , 300 ,
'1103', '2021-01-07' , null ,
'1103', '2021-01-08' , 400 ,
'1104', '2022-01-01' , 111111 ,
'1104', '2022-01-02' , null ,
'1104', '2022-01-03' , null ,
'1104', '2022-01-04' , 22222 ,
'1104', '2022-01-05' , null
) as (product_id,into_warehouse_time,cost)
);2 数据分析
方法1:断点分组思想【通用解法】
难点:如何存在多个NULL值时能正确取到最近上一次有效值,和最近的下一次的有效值。
如果为null的能和最近一次上一个有效的数据分到一个组里,或和最近一次有效的下一条数据分到一个组里,问题就好解决了。那么怎么分组呢?我们采用断点分组的思想来解决
核心逻辑如下:
--将NULL值最近上一个分到一个组里
sum(if(cost is null,0,1)) over(partition by product_id order by into_warehouse_time) as grp_flg1
--将NULL值最近下一个分到一个组里
sum(if(cost is null,0,1)) over(partition by product_id order by into_warehouse_time desc) as grp_flg2
上述逻辑可以进一步优化,我们观察到数据的特征,由于存在NULL值,表示稀疏的,可以利于count(字段) 忽略NULL值得特性,利用count()函数的分析函数来显示条数的变化来达到同样的结果,具体优化SQL如下:
count(cost) over (partition by product_id order by into_warehouse_time) as grp_flg1
count(cost) over (partition by product_id order by into_warehouse_time desc) as grp_flg2最终完整的SQL如下:
select product_id
, into_warehouse_time
, coalesce(cost, (last_cost + next_cost) / 2,0) cost
from (select product_id
, into_warehouse_time
, cost
, COALESCE(max(cost) over (partition by product_id,grp_flg1), 0) as last_cost
, COALESCE(max(cost) over (partition by product_id,grp_flg2 ), 0) as next_cost
from (SELECT product_id
, into_warehouse_time
, cost
, count(cost) over (partition by product_id order by into_warehouse_time) as grp_flg1
, count(cost) over (partition by product_id order by into_warehouse_time desc) as grp_flg2
from cost
) t
) t
order by product_id,into_warehouse_time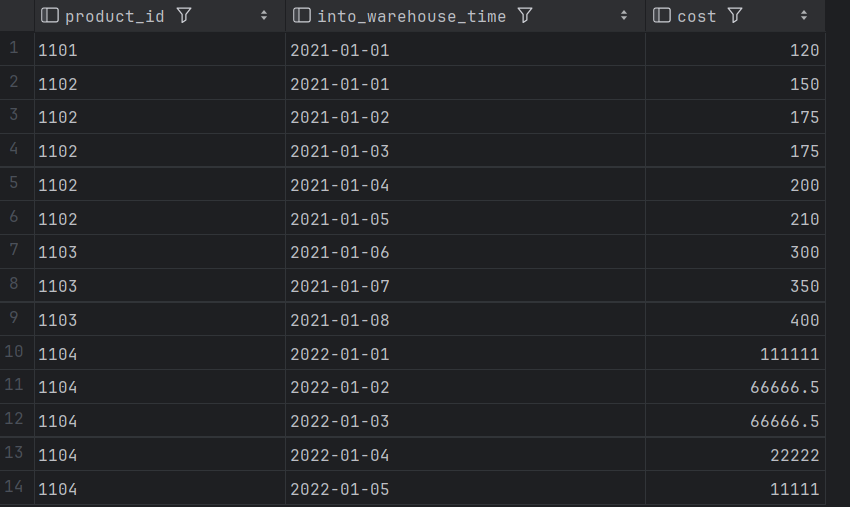
方法2:优雅解法 | last_value分析函数忽略NULL值特性实现
利用last_value(a,true) over(order by b)求解,如果该函数第二个参数为true,则按照order by指定的顺序获取距离当前行最近且值不为NULL的一行对应字段值,oracle数据库则使用last_value(a ignore nulls) over(order by b) 语法,另外oracle数据库lag函数的分析函数,也可以忽略null值,实际上对该问题lag函数更为精确,而对于Hive数据库中则lag()函数的分析函数没有忽略NULL值这一特性,只能使用last_value分析函数。
具体求解SQL如下:
select product_id
, into_warehouse_time
, coalesce(cost, (NVL(last_cost, 0) + NVL(next_cost, 0)) / 2, 0) as cost
from (select cost.*
, last_value(cost, true) over (partition by product_id order by into_warehouse_time) last_cost
, last_value(cost, true) over (partition by product_id order by into_warehouse_time desc) next_cost
from cost) t
order by product_id, into_warehouse_time;3 小结
本文分析了一种商品入库采购成本数据缺失用有效值填充的问题,该问题在数据清洗中比较常见,文章中给出了两种解题思路,一种利用断点分组的思路,一种利用last_value()忽略NULL值的思路,第二种方法较为优雅。
原文链接:Sql进阶技巧:如何分析商品入库采购成本数据缺失问题?| 近距离有效的数据缺失值填充问题
本篇文章收录于CSDN 莫叫石榴姐 数字化建设通关指南 中,也欢迎大家去我的公众号“会飞的一十六”进行交流

最后修改时间:2024-08-24 14:40:04
文章转载自江月明,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
