




关注我们

从0构建一个数据集成系统
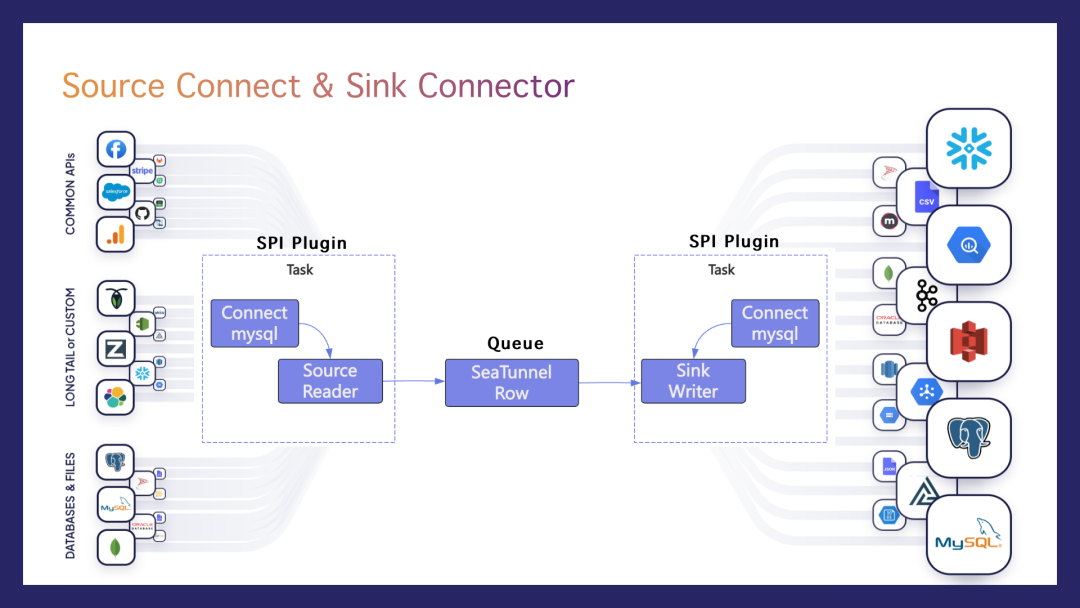
构建数据集成系统的初衷,是因为我们面临着多种数据源到目标数据库的同步问题,如MySQL到MySQL、PostgreSQL到Oracle等。由于数据源众多,促使我们设计了灵活的源连接器和目标连接器。
Source连接器&Sink连接器
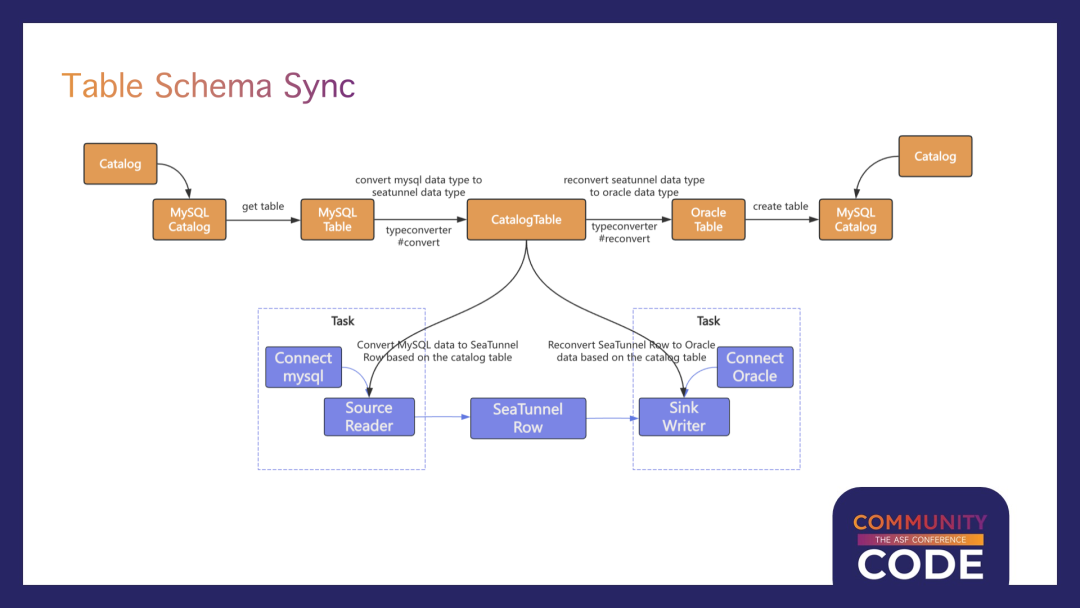
表结构同步
并行化挑战
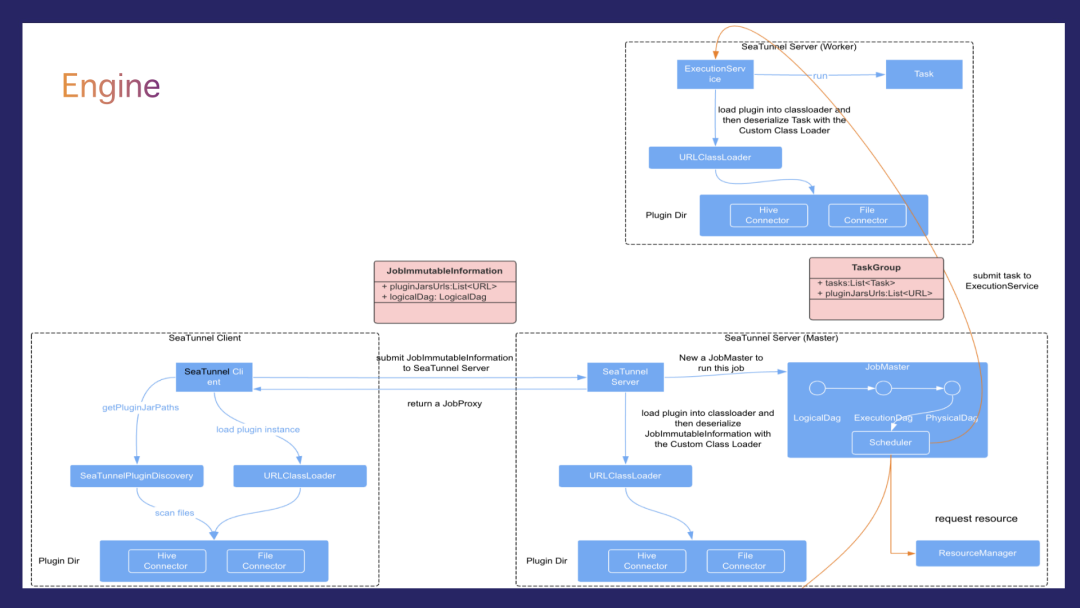
SeaTunnel引擎
Apache SeaTunnel
可以看到,之所以出现越来越多的复杂的数据集成引擎,是出于各种需求而不断演进。在这样的背景下,Apache SeaTunnel应运而生。
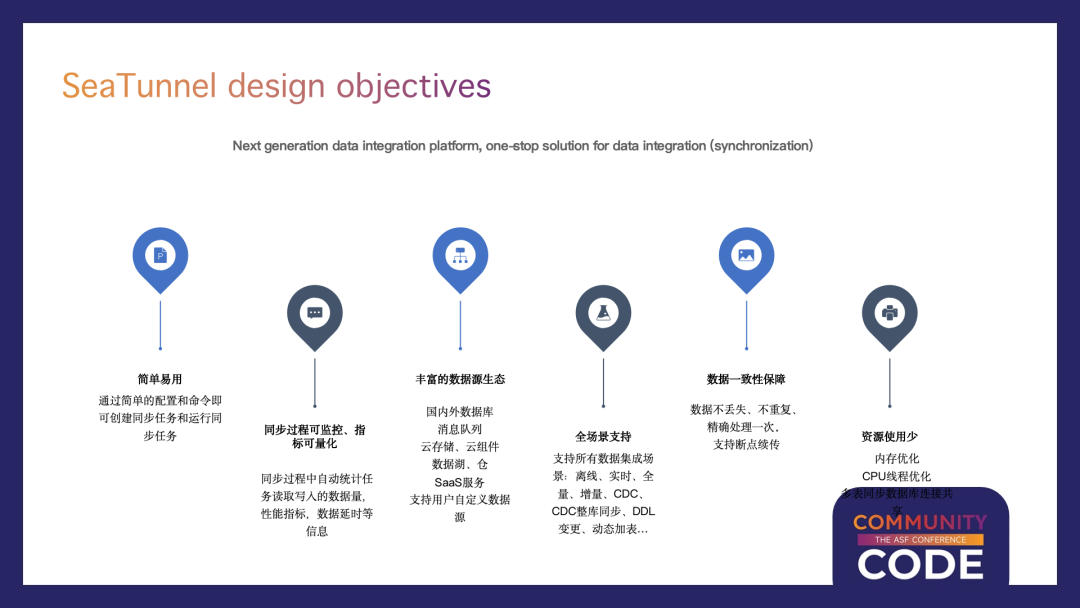
设计目标
简单易用:通过简单的配置和命令即可创建同步任务和运行同步任务; 同步过程可监控、指标可量化:同步过程中自动统计任务读取写入的数据量,性能指标,数据延时等信息 丰富的数据源生态:支持国内外数据库、消息队列、云存储、云组件、数据湖、仓、SaaS服务、支持用户自定义数据源 全场景支持:支持所有数据集成场景,包括离线、实时、全量、增量、CDC、CDC整库同步、DDL变更、动态加表 数据一致性保障:数据不丢失、不重复、精确处理一次、支持断点续传 资源使用少:包括内存优化、CPU线程优化、多表同步数据库连接共享
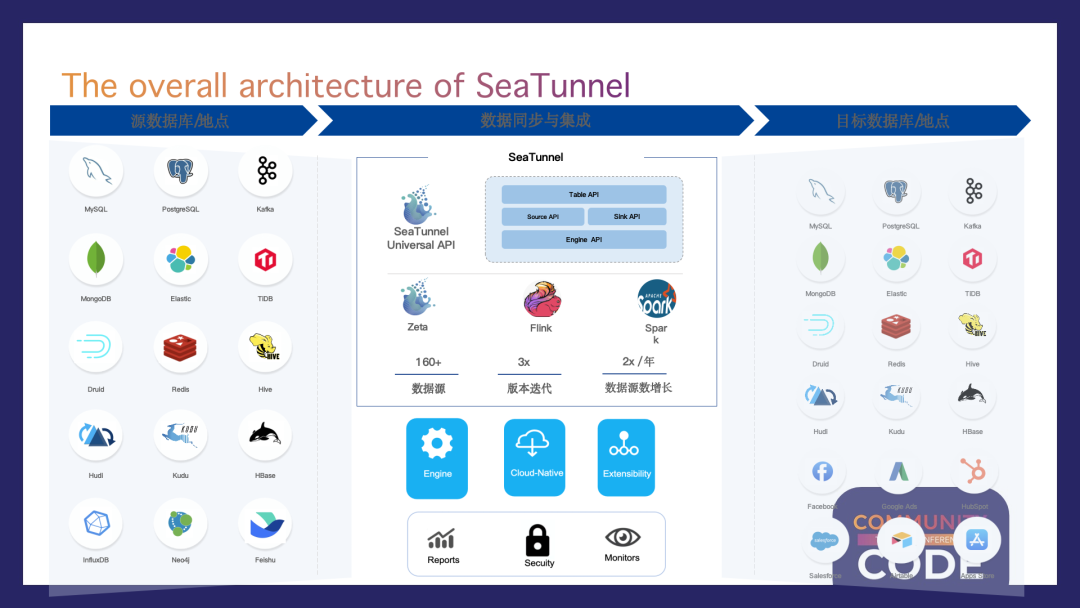
架构概览
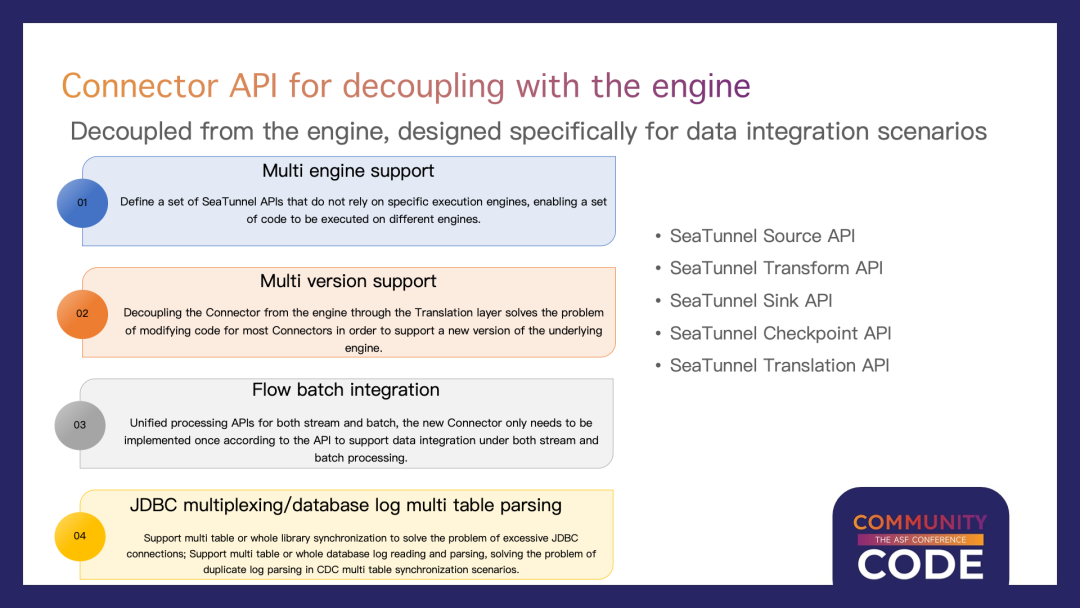
连接器API与引擎解耦
Source连接器
Sink连接器
job.mode指定为 BATCH 或 DataMING,SeaTunnel的同一Sink连接器可以轻松地在离线和实时同步模式之间切换。
支持SaveMode,灵活选择目标性能和数据处理方式 自动创建表,支持模板修改表创建,在多表同步场景下解放双手 精确一次语义支持,数据不会丢失或复制,Checkpoint机制适配 Zeta、Spark、Flink引擎 CDC支持,支持处理数据库日志事件
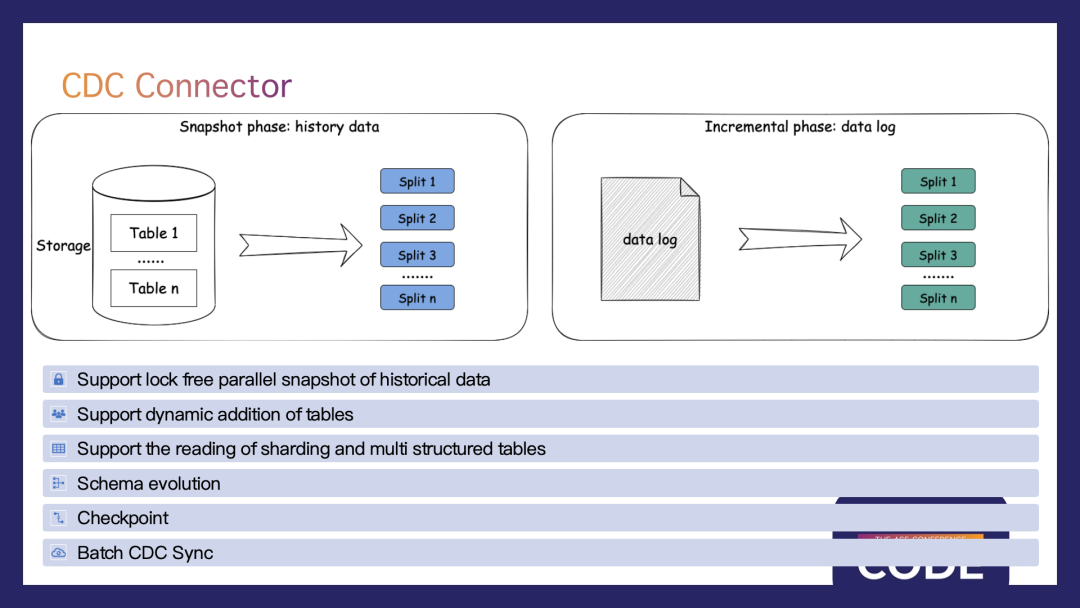
CDC连接器
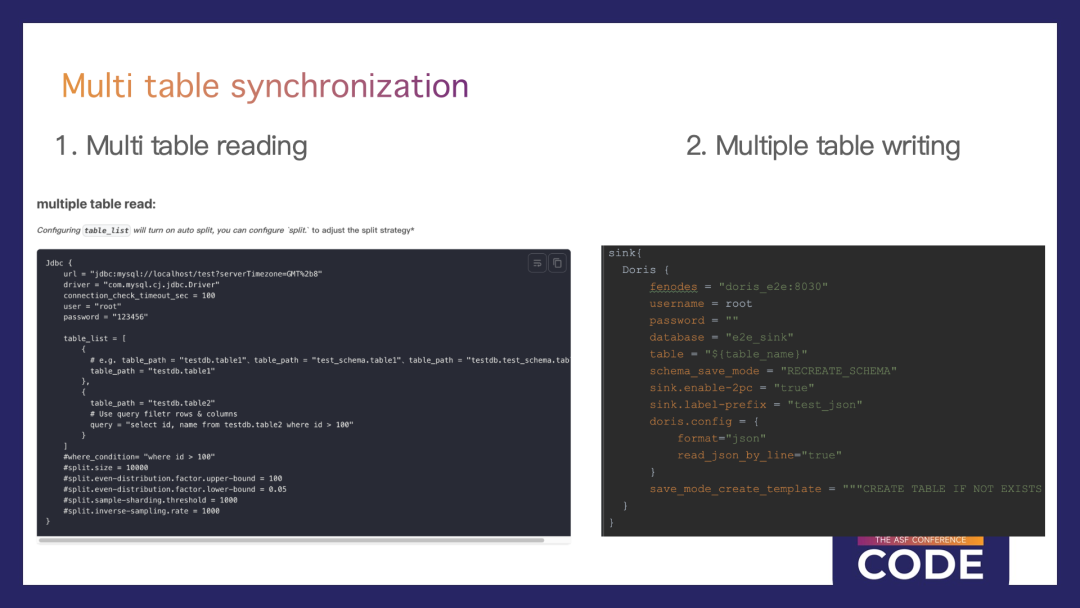
多表同步
新一代数据同步引擎-SeaTunnel Zeta
SeaTunnel Zeta作为新一代的数据同步引擎,具有其他计算引擎所不具备的一些特性:
不依赖第三方组件和大数据平台; 无主,内置分布式网格可持久化存储内存; 支持WAL,即使整个集群重启也能恢复之前的作业; 支持分布式快照算法,保障数据一致性; 支持更细粒度的数据同步监控指标; 支持事件通知机制; 类加载器隔离和缓存,提高了系统的稳定性和性能。
SeaTunnel在AI领域的应用
社区近期在AI领域应用方面进行了一些工作,除了常规数据类型之外,还添加了对多种向量数据类型的支持,比如BINARY_VECTOR、FLOAT_VECTOR、FLOAT16_VECTOR、BFLOAT16_VECTOR、SPARSE_FLOAT_VECTOR等,为AI领域的数据处理提供了强大支持。
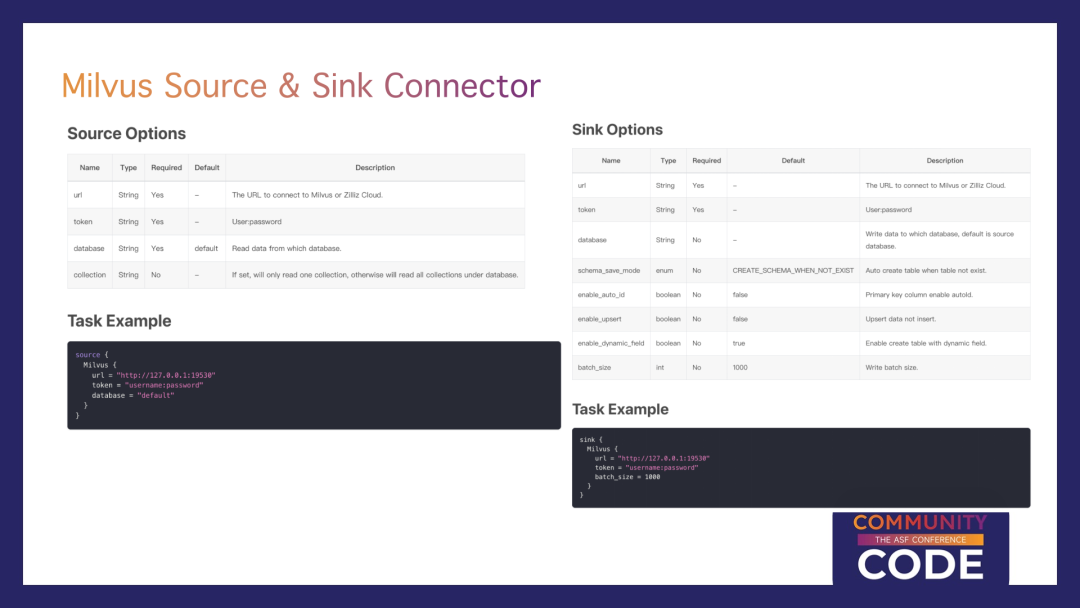
最新规划
为了使SeaTunnel能够满足更多用户需求,社区近期也在计划一些新功能的添加和优化工作。
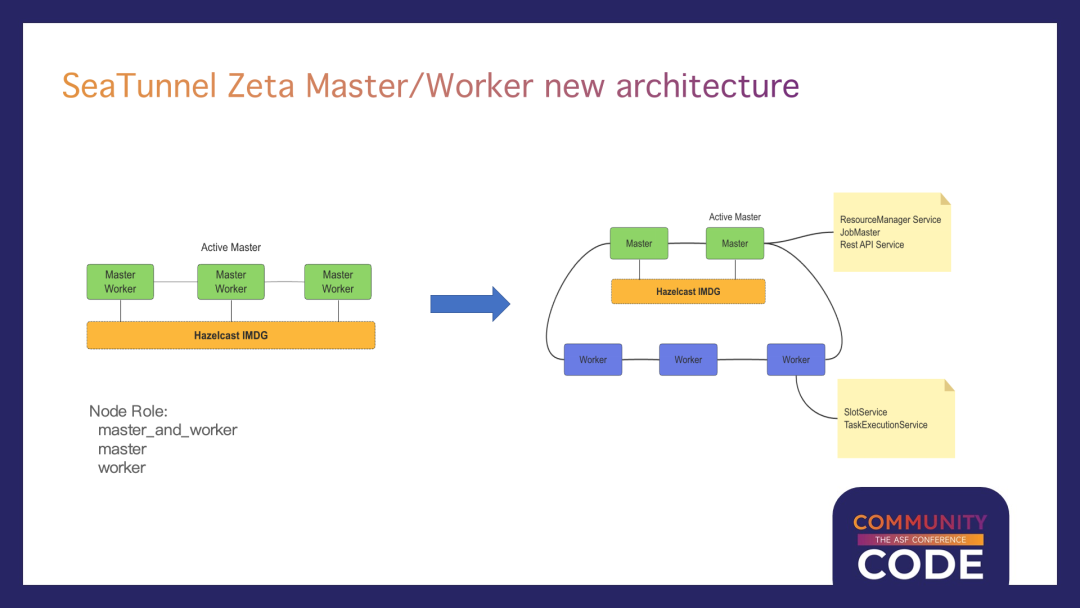
引入SeaTunnel Zeta Master/Worker新架构
使用SQL创建SeaTunnel作业

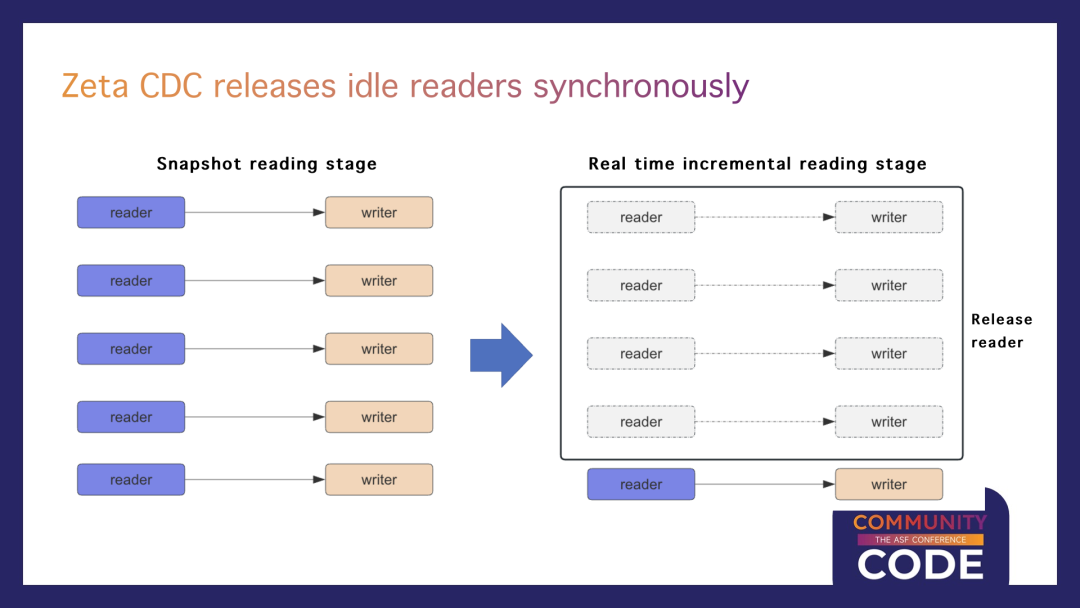
Zeta CDC的改进
ClassLoader隔离改进
CDC同步监控优化
支持事件通知机制
结语

Apache SeaTunnel
精彩推荐
点击阅读原文了解更多⭐️!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
