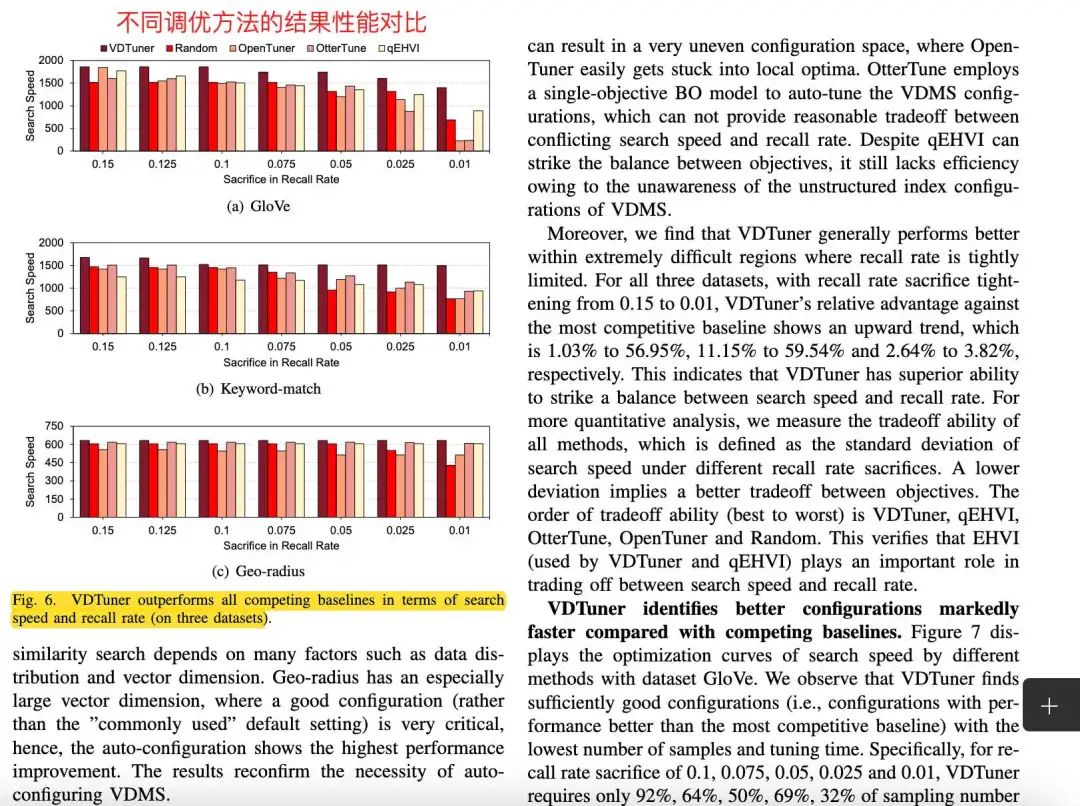
今天为大家分享一篇ICDE 2024年的向量检索论文:VDTuner: Automated Performance Tuning for Vector Data Management Systems论文概述
同关系型数据库一样,向量数据库中也存在着不少的配置参数,如何设定这些参数对数据库的性能和结果的精确性有不小的影响。这些参数既包括系统配置方面的参数,比如数据库分段的大小,内存垃圾回收的频率;也有和向量索引相关的参数,如HNSW中的efCons,M等。这些参数之间存在着耦合关联,给调优带来了很大的困难。本文提出了一个自动化调优的方法VDTuner,基于贝叶斯优化的方法,以查询精度和性能为目标,针对用户数据集训练黑盒模型,推理出最优的参数配置,解决参数调优的难题。论文在Milvus数据库上,针对在三个十万到百万级别数据集上测试了VDTuner的调参效果,结果显示,VDTuner可以在搜索速度和精度上相比于均有提升。论文地址:https://arxiv.org/pdf/2404.10413代码地址:https://github.com/tiannuo-yang/VDTuner关键算法
基本框架
贝叶斯优化是对黑盒模型进行超参优化的一个经典方法。论文把向量数据库当做一个黑盒模型,模型输入为向量数据库的参数,输出为查询时间和结果精度。即黑盒模型建模的函数是“参数-性能曲线”。论文使用高斯过程作为模型的先验分布。训练这个模型就需要不同参数下的性能测试的数据。这意味着产生每条训练数据都需要重新构建索引、性能测试,数据采样的效率很低。此时如何能够以最有效的方式确定采样哪些参数可以对黑盒的性能进行更好地建模,成为了一个核心挑战。论文采用了下述的两种策略提高采样效率。双目标优化的获取函数
在贝叶斯优化算法中,获取函数负责确定采样哪些参数以测试模型性能,一个更优质的获取函数可以用更少的采样训练出更精准的代理函数以模拟黑盒模型。在向量数据库的场景中,论文认为需要对查询精度和查询实验做双目标的。多目标的贝叶斯优化在过往已有研究。其核心思想是对于已探索过的参数区域构建帕累托曲线(Pareto Curve),换句话说,抛弃那些在各个维度上都不如其它参数的性能的参数。然后获取函数在探索区域内按照参数出现的概率分布采样,选取能使得帕累托曲线增长最多的参数。这一方法被称为EHVI(Expected Hyper-Volumn Improvement)。不同索引类型的选择
相比于关系型数据库,向量数据库一个特殊的参数是索引类型。索引相关的参数只和特定的索引类型相关。因此存在两种调优策略,一种是各类索引分开调优,另一种是把索引类型也作为参数之一统一调优。论文认为不同的索引由于性能不同,使用同样的代价去调优性能更差的索引是算力的浪费,因此选择了后一种方案。在这种方案下,各索引类型采取了轮询的策略分别调优,但是采取了淘汰机制。如果在一定的参数采样窗口内,基于EHVI的思想,淘汰对整个向量数据库性能贡献最小的索引。此外,由于索引参数对索引性能的影响较大,所以为了保证每一种索引能够充分调优,论文采用了相对性能来训练每一种索引。精彩段落
<<< 左右滑动见更多 >>>
总结与思考
论文基于贝叶斯优化的方法设计了一个向量数据库的自动化调优方法,用双目标、索引类型轮询等方法将向量数据库的场景嵌入到贝叶斯优化的框架下,并得到了较好的收敛性,比通用的索引调优框架效果更好。向量数据库的调优仍然是一个前沿领域,许多问题仍待考虑。比如采样效率仍然很低,模型容易过拟合,如何提高采样效率?再比如模型采用双目标还是单目标,能获得更好的收敛性?构建参数和查询参数是否应该分开调优,分别控制索引整体性能(帕累托曲线),与实际使用时的点性能(固定精度)?延伸阅读
[1] SIGMOD'17:Ottertune参数调优框架 Automatic Database Management System Tuning Through Large-scale Machine Learning
(https://15799.courses.cs.cmu.edu/spring2022/papers/06-knobs1/p1009-van-aken.pdf)[2] IS'23:基于元学习的向量索引调优方法 A meta-learning configuration framework for graph-based similarity search indexes
(https://www.sciencedirect.com/science/article/pii/S0306437922001016)编者简介

复旦大学与巴黎西岱大学联合培养博士生,研究领域为高维数据(向量、序列等)管理和分析。以第一作者在SIGMOD,VLDB,VLDBJ,TKDE等数据库领域会议/期刊发表多篇论文,并担任审稿人。个人主页:https://zeyuwang.top/ 谷歌学术:https://scholar.google.com.hk/citations?hl=zh-CN&user=XXGhABIAAAAJ技术博客:https://www.jianshu.com/u/d015902c6d09👆 关注 AI 搜索引擎,获取更多专业技术分享 ~