




量化大语言模型对提示词中的结构敏感性(我是如何开始学习担心提示词格式的)

文章链接:https://arxiv.org/pdf/2310.11324
摘要
量化敏感度
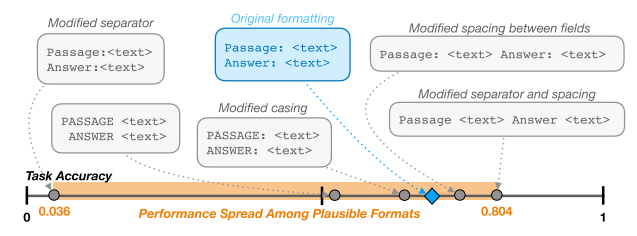
上图显示了在使用LLaMA-2-7B模型进行1-shot学习时,不同提示词格式对模型在具体任务上的表现差异。具体来说,图中各个“
1. 定义语法的基本组成部分
基本字段(Basic Fields):每个提示词格式由一个或多个基本字段组成。一个基本字段通常包括: 描述符(Descriptor):用于描述数据的短语或词语,如“Passage”或“Answer”。 分隔符(Separator):描述符和数据之间的符号,如“: ”。 占位符(Placeholder):用来替换实际数据的占位符,通常表示为 <text>
。基本字段的形式化定义:使用巴科斯-诺尔范式(Backus-Naur Form, BNF)来定义基本字段。比如,基本字段可以被定义为: B1(d, s, f) := f(d)s<text>其中, d
是描述符字符串,s
是分隔符,f
是改变描述符形式的函数(如大小写转换),<text>
是数据的占位符。
2. 组合字段
多字段组合(Field Composition):多个基本字段可以组合成完整的提示词格式。组合时,可以使用连接符来分隔各个字段,如空格或其他符号。
例如,两个基本字段
a1
和a2
可以组合成一个格式:B(2)2(a1, a2, ' || ')这表示两个字段
a1
和a2
通过" || "
连接起来,形成完整的提示词格式,如"Passage: <text> || Answer: <text>"
。
3. 支持枚举(Enumeration Support)
枚举列表项:语法支持定义列表项的格式,比如选项
(A)
,(B)
,(C)
等。每个列表项也可以通过基本字段来表示。枚举的示例:
Option (A): <text>, Option (B): <text>, Option (C): <text>该格式可以表示为: B(3)2(a1, a2, a3, ' || ')其中,
a1
,a2
,a3
分别代表“Option (A)”、“Option (B)”、“Option (C)”的基本字段。
4. 语法规则的总结
最终的语法定义通过一系列组合规则来确定提示词格式的合法性。这些规则包括了各种字段的定义、字段之间的连接方式、以及支持的各种格式变体。
所有字段的组合必须符合语法定义,才能生成被认为是“有效”的提示词格式。
5. 语法验证
验证生成能力:研究人员通过验证语法是否能生成特定任务的提示词格式来测试其有效性。例如,验证语法是否能生成Super-NaturalInstructions任务中使用的100多种提示词格式。
确保语义等价性:通过控制描述符的形式(如只改变大小写)来保证生成的不同格式之间的语义等价性。
实验
实验方法如下:
数据选择:从Super-NaturalInstructions中选取了53个任务,包括19个多选任务和34个分类任务。为了构建最终的提示词模板,将每个任务的指令与多个格式化的few-shot示例通过 \n\n
间隔连接。为了消除示例选择和顺序对模型输出的影响,固定了每个任务的few-shot示例的选择和顺序,这些示例在任务中随机选择,但不会用于评估。每个数据集的大小假设为1,000,以确保任务之间的评估公平性。模型:实验评估了几种自回归语言模型,包括LLaMA-2-{7B, 13B, 70B}、Falcon-7B、Falcon-7B-Instruct,以及GPT-3.5-Turbo。 任务评估指标:采用了两种常见的准确率计算方法: 精确前缀匹配:检查模型输出的前缀是否与期望答案匹配,经过标准化处理后进行比较。 概率排序准确率:计算模型输出分布中,期望答案是否为排名最高的有效选项(适用于多选和分类任务)。结果主要通过概率排序准确率进行报告。
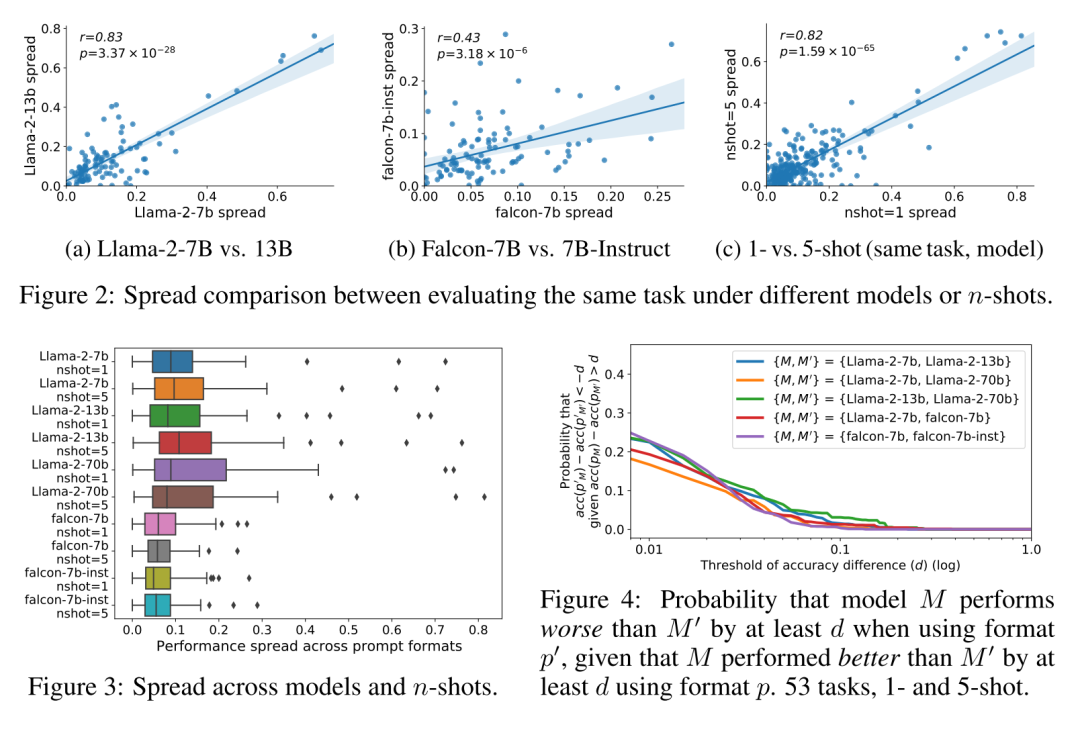
图2: 图3: 这里展示了在不同模型和few-shot设置下提示词格式选择导致的性能扩展范围。图中的每个条形图表示不同模型和few-shot设置下的性能扩展情况,可以看出即使是在相同模型和不同few-shot设置下,性能扩展也可能显著。
图4: 该图描述了一个模型相对于另一个模型在使用不同格式时,性能差异超过某一阈值的概率。该图进一步表明,提示词格式的选择对模型性能的影响是非线性的且难以预测的,提示在模型比较中需要考虑格式的多样性。
总结
这篇文章主要探讨了提示词格式对大型语言模型性能的显著影响。作者提出了一种名为FORMATSPREAD的算法,用于估计不同提示词格式选择对模型性能的扩展(spread)。实验表明,即使在增加模型规模、增加few-shot示例数量或使用指令微调的情况下,提示词格式的选择仍会导致模型性能的显著差异。
