




2024 年 8 月 22 日-24 日,由 IT168 联合旗下 ITPUB、ChinaUnix 两大技术社区主办的第 15 届中国数据库技术大会(DTCC 2024)在北京朗丽兹西山花园酒店隆重召开。大会以“自研创新 数智未来”为主题,邀请超百位行业专家,共同探讨新时代下数据库的技术动态和应用实践,为广大数据领域从业者带来一场年度交流盛宴。OceanBase 首席科学家阳振坤受邀出席并发表了《云数据库的发展趋势》的主题演讲。以下为演讲实录:

各位朋友大家好,非常高兴有机会和大家分享我的一些想法。大家都知道,最近这些年国内的数据库产业得到了很好的发展,这里有一些自然的因素——如国内信息化及互联网的发展,也有其他一些短期的因素。但归根到底,数据库其实跟语言、文化、地域是弱相关的,中国数据库的发展一定会融入到全世界潮流里去,因为数据库本身就是在全世界范围内竞争的产品,一个数据库很难只用于某个国家或某个地方。
对于我们来讲,长时间内中国的数据库还是不是一直繁荣?今天现场这么多用户用的数据库是不是符合发展潮流?并且不会落伍和淘汰?数据库偏离了主流、落伍了,就不得不换掉,这对于使用者、用户是不是很大的负担?我想这些事情比我讲 OceanBase 的产品更重要,所以借这个机会把一些观点拿出来,未必是正确的,但想和大家一起探讨。
一、云数据库已经成为主流
说到数据库,数据库是一个产品,是一个服务,是给用户用的。我们先看一看用户的需求,结合福布斯技术委员会列出了 15 个数据库不可或缺的需求。

第一,对数据库最重要的是扩展性(伸缩能力)。今天的数据量和并发量变得更大、用户变得更多。第二,应用敏捷,数据库本身既要有交易处理能力,又要有分析处理能力,还要有多模的能力。第三个就是老生常谈的成本。
我们看一下数据库的现状。我相信所有人都知道,今天的云数据库已经成了全世界的主流,下面我列举几个 Gartner 的公开数据。
全球范围内云上数据库已经超过了 60%,如果对市场每年增量的贡献来看,云上数据库已经超过了 90%,可能有人问为什么云下数据库还有 9%,这里的 9% 指的是增量里面的 9%,如果说全球的数据库每年的增速是 10%以上,那么云下数据库是 10%里面的 9%,是一个很小的比例。
从数据库厂商占比来看,也能看到这个趋势。我列出来了市场份额大于 5%的所有数据库厂商,一共 4 家,这里面有 3 家是纯粹的云,即从云计算发展的 Google 和 AWS,还有一个是 Microsoft,这些年微软数据库的发展很大程度上得益于云本身及云数据库的发展。而真正传统的数据库并且还以线下为主的只有 Oracle 一家,除此外,剩下其他云厂商在今天的市场份额都已经低于 5%。
云计算领域里面的领头羊 AWS,从 2013 年到 2023 年的 10 年时间,AWS 云收入涨了 30 倍,从 31 亿涨到 900 亿,所以大家可以看到云这些年的发展非常迅速。还有一个更值得关注的数据是运营利润,对这个词不太熟悉的话可以当成净利润来看,去年和前年净利润是 27%和 29%,为什么说非常值得关注呢?因为云上主要卖的东西是虚拟机,仅卖虚拟机能赚这么多钱。
有人想说也卖数据库,那么是不是这些钱都是数据库赚的?肯定不是。因为整个数据库占收入总额不到 30%,或者说差不多 30%,不可能数据库都是净利润。很多人知道,个人电脑毛利只有十几个点,云能做出 20%-30%的净利润,是什么原因呢?
二、云带来了什么?
我们可以一起看一看云,云给大家带来了什么?带来了易用性,带来了按需使用、按需付费,带来了企业效率的提升。
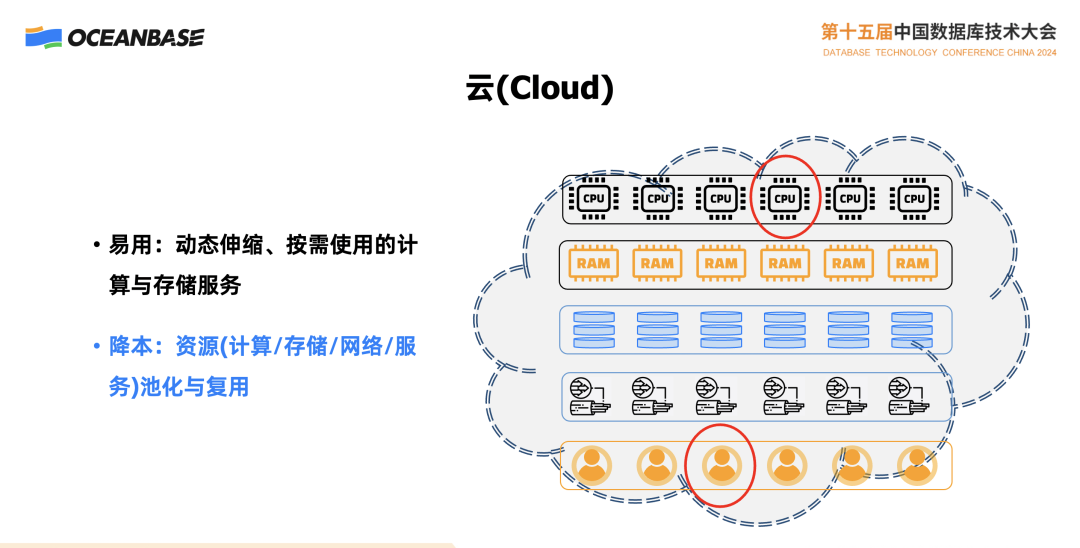
一方面是降本。很多人可能会说,我觉得云上卖的虚拟机没有便宜多少,有时候看到成本只看到了机器的购买成本,但其实今天一台服务器的购买成本是低于运营成本的,这台机器所占机架、所用电费和维修,这些加起来高于它的购买成本。这个降本带来的好处,一方面让用户成本得到了降低,但你的成本还远高于线下的话,依旧没有人来用。
另一方面是让厂商得以盈利,究竟什么原因能够让这里有这么大的降本幅度呢?是资源的共享和复用。你有一个足够大的资源池,我们来举个例子,比如说 CPU,很多人知道企业里面的计算机系统的 CPU 平均利用率很少到 10%,绝大多数低于 10%,如果云厂商把这个事情,通过复用做到了 20%,大家可以想一想意味着什么呢?意味着用一份硬件投资,包括运营投资就产生了两份硬件。这怎么能够不赚钱呢,所以资源的复用对于云来讲至关重要,我们用通俗的话说,这就是"超卖"。复用这件事情在日常生活中处处存在,我们的电信系统和网络宽带都是很多人复用的,这些东西不可能说是一个人独享,今天很多家庭的带宽,网络是几百兆、千兆,一个大城市就有几百万用户,不可能每个人带宽都是线性累加,而是大家共享。
云上还有一个优势是人力资源服务在很大程度上也能够共享。我们以数据库行业为例,如果是线下部署,用户遇到了一些疑难问题,我们厂商要去解决,就算是同城,这个人也要跑过去,路上时间可能用小时来计,到了用户还有各种安全登记,进去之后绝大多数情况是数据库的服务支持人员不能碰用户的键盘,否则厂商的服务支持人员去删了库,厂商不跳楼用户就得跳楼了(开个玩笑🫢)。
当一个系统发现问题的时候,你只能告诉用户的操作人员说“我怀疑是这样,你可能是执行了什么操作,我们看看是什么情况”。这就好像说一个中医给一个病人看病,你不能给他号脉,你让别人号脉,然后你告诉他怎么样号脉让他自己操作,但其实这样解决事情的效率是很低的,这就导致一天能把一个用户问题解决就不错了。但在云上完全是另外一回事,因为用户使用云的前提是需要跟厂商之间建立信任,前提是得到用户授权,厂商人员才能访问云上系统,得到授权后我们的技术人员可以很快在系统里面直接操作、来定位发现问题,这样一个人可能一天支持五个、八个、十个用户,就变得是一件容易的事情,不只是设备得到复用,人力资源成本也得到很大程度的复用。
三、回归云数据库的本质
云数据库本质上还是一个数据库,但在云环境下的数据库应该要借鉴或参考云的一些特性,云非常重要的是易用性、资源动态的伸缩、按需使用和按需付费、通过资源池化和复用,使成本得到很大程度降低。
数据库本身的一些需求包括伸缩能力、应用敏捷性还有成本,组合起来我们需要云上数据库也一定要是易用的,虽然做不到像手机一样大家拿起来就能用的程度,但是起码要在原来的环境下,保证更加易用、效率更高,以此更进一步降低成本。
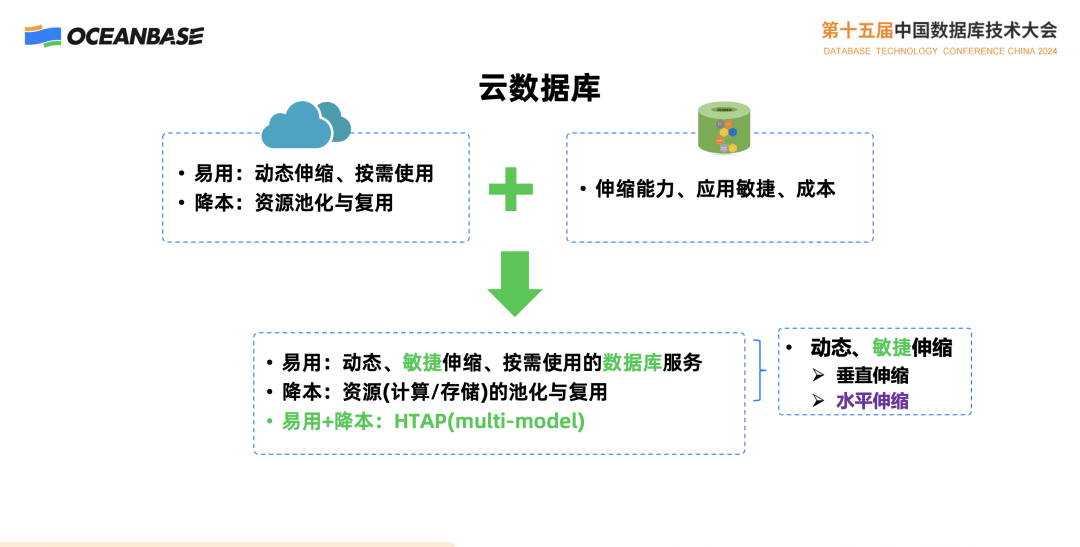
另外一方面从刚才的定义来看,云数据库至少是多模的,这对数据库提出的挑战就是动态和敏捷的伸缩,否则这个资源的复用就成了空谈,没有充分利用时还占着,意味着这个资源没有办法复用,所以对数据库来说,伸缩能力至关重要。
(一)Zero ETL 是否成立?
垂直伸缩指的是现在很多系统一定程度上都能够做得比较好,在单机上容量可以扩展,CPU 处理能力也可以增加或减少,还有一个是水平的伸缩。很多人会对这件事情有疑惑,今天一台普通 CPU 机架服务器,内存可以到十几个 T,几十个 T,硬盘容量可以到几百个 T,对于绝大多数处理能力来说足够了,那么我还用得着要水平伸缩吗?要分布式吗?分布式数据库比单机数据库要复杂得多,这个等一下我们看一个具体例子。
今天云上数据库最主要的是这种方式,一个交易数据库在处理业务,通过 ETL 把交易产生的数据同步到分析系统里面去,然后分析系统来进行分析,这样的系统能不能工作呢?能!今天主流的系统,绝大多数都是这样的,但是这样的系统其实有不够完善的一面。
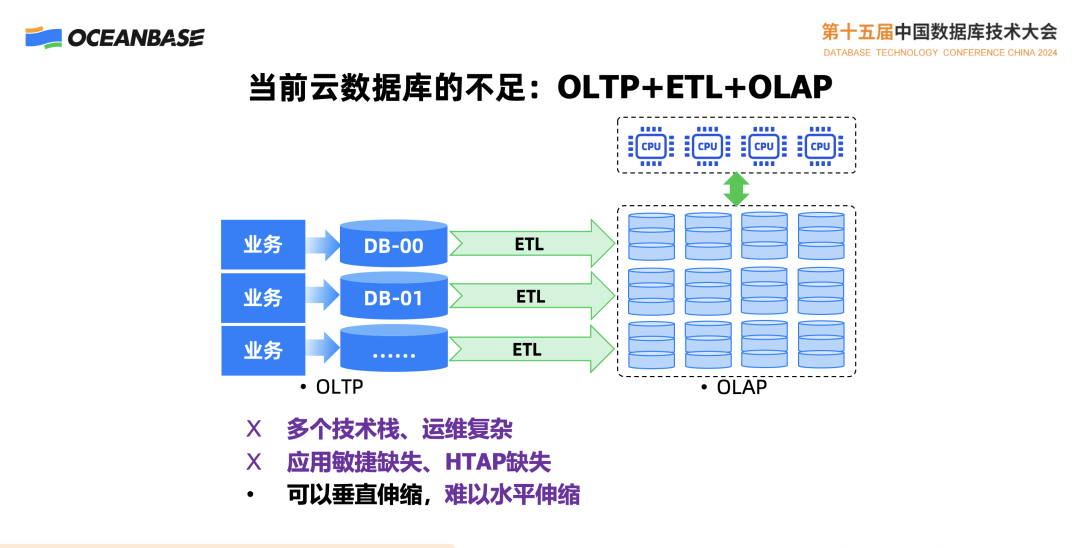
首先是多个技术并存,需要有一个交易数据库,有一个分析数据库,还要有一个 ETL。Zero ETL 概念本质上这还是 ETL,只不过把某些细节隐藏到背后去了,所有运维过这一套的系统人员,都知道它是一个复杂的事情,一旦你的业务系统或表结构有变化,意味着 ETL 系统要做调整。一直以来,这个问题本身就存在,而不是因为有了 Zero ETL,这个问题就消失了。一个系统同时支持交易和分析的能力依然缺失,更不用说具备多模能力了。
(二)为什么必须水平伸缩?
与此同时,这个系统的水平伸缩能力也是缺失的。那么,为什么水平伸缩能力如此重要呢?我们来看一个例子。众所周知,云计算最重要的优势之一在于资源的复用,这也是降低成本的关键。如果资源不能得到有效复用,系统的效率会受到影响,成本也会大幅上升。这里展示的是一个企业的业务图,大家可以看到图中有两个业务高峰。
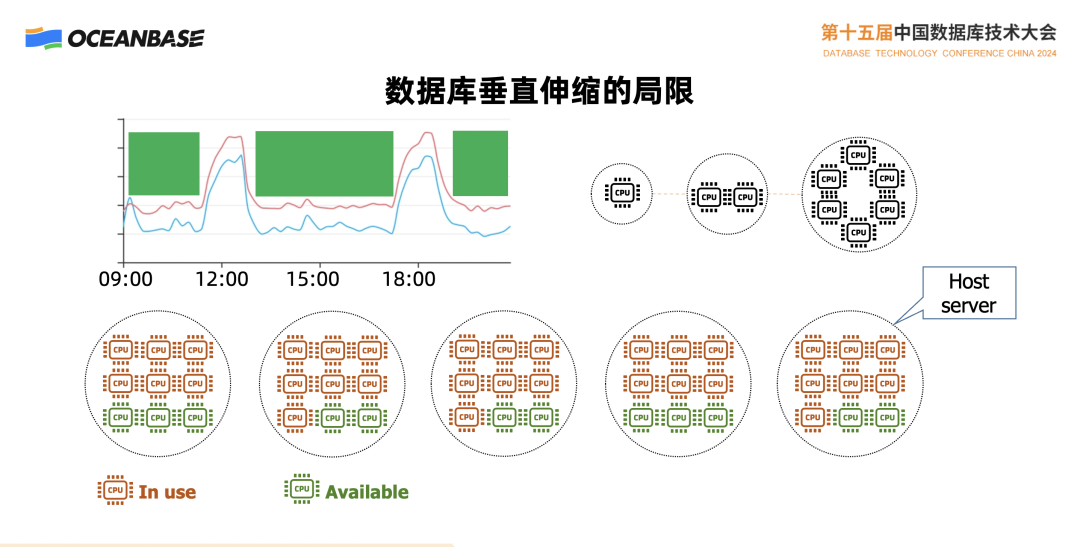
中午 12 点和下午 18 点是业务的高峰,白天其他时间业务流量较小,晚上可能就更小了,大家可以想象这是一个便利店,平时也有点业务,中午和晚上来吃饭的人多,但这些人不一定都来吃饭,可能是中午吃饭的时候买点东西。晚上的时候业务量比较小,1个 CPU 可能就够了;白天的时候业务量稍微多一点,可能要2个 CPU;到了中午高峰和晚上高峰的时候,要6个 CPU 才能够处理过来。
假设下面是我们的云数据库,一台物理机但有很多机器 CPU 要用上,也还有不少空闲 CPU,当我们找不到一台机器能够有6个 CPU 核时要扩容,此时垂直扩容是无法操作的,但如果系统数据库能够支持水平扩容,就可以找2台有3个 CPU,或者找3台有2个 CPU 的机器来解决这个问题。
如果只用垂直扩容,即使数据量不是特别大、处理能力也不是要求特别高的时候,垂直扩容的能力也会不够,因为即使在小用户情况下,也会面临着资源不能够充分复用和利用的问题,提高了整个云平台的成本。
HTAP 系统在理想情况下,我们希望在一个数据库甚至一个事务中,既能执行交易型的 SQL 语句,又能执行分析型的 SQL 语句。这样的业务场景今天依旧存在,比如说典型的财务系统,以及很多公司有专门的风控系统,对于大企业来说,没有必要在事务处理里引入这样一套与风控有关的东西。对于中小企业来说,单独架设一套风控系统,成本是很高的,最好的方式是在一个系统里面做一些在线的实时风险判断。比如,当进行一笔付款时,系统需要具备一定的分析能力来支持风险评估。
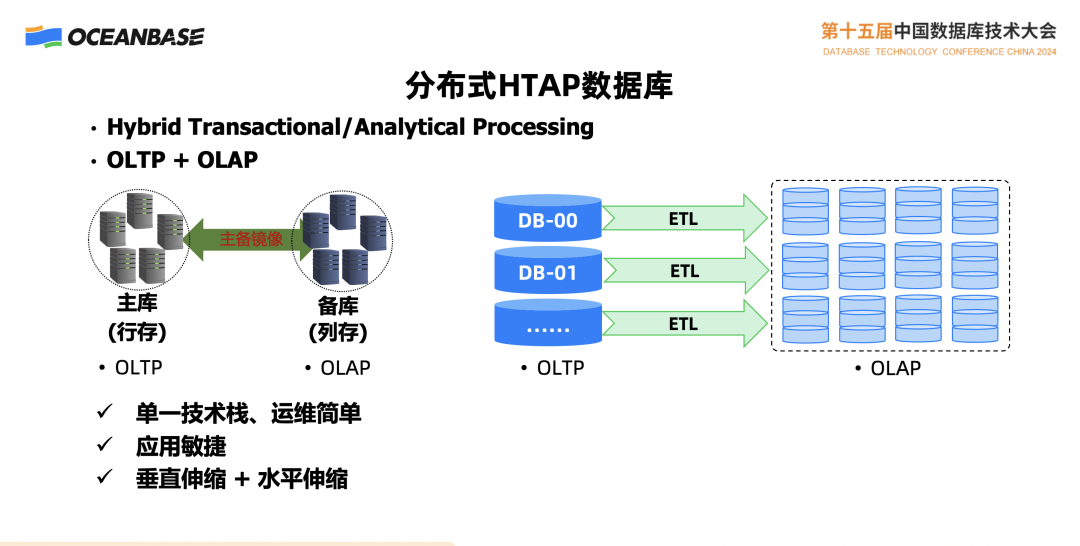
以一个简单的场景为例,很多时候大家会担心,当 TP 和 AP 不隔离时,系统的交易性能会收到影响。我们来看一个隔离的场景:主库负责交易,配备一个列存的备库,二者做成同步,形成主备镜像,所有分析操作可以在列存备库上来做,有人会问,这种场景跟刚才在 ETL 中的做法很相似,其实上有很大的差别,这样的系统是单一的技术架构,本质是通过一个数据库实现 TP 和 AP 负载,即使一个是行存,一个列存,依然属于同一个数据库的范畴。
四、云数据库的未来挑战
未来随着技术的发展,数据可能既不是单纯的行存,又不是单纯的列存,而是行列混合。比如通过统计发现,某数据列的访问频率较高,这些列会以列存的方式存在,并被经常用来做一些分析。还有一些数据列更多地用于交易处理,它可能是以行存的方式存在。
因为它能够既支持交易又支持分析,所以应用的敏捷性没有问题。在需要时,这样的系统可以利用资源进行垂直伸缩,如果垂直伸缩的资源不够,还可以做水平伸缩,这样保证整个系统的资源能够更好地利用起来。
世界上没有免费的午餐,HTAP 系统不是说有就有的,它面临一个很大的挑战——行存和列存。交易处理几乎依赖于行存,因为列存的修改效率非常低,当涉及到 100 个列甚至 1000 个列进行实时原地更新时,几乎是不可能完成的任务。目前为止我们已知比较可行的方案——就是 LSM-tree,把整个数据分成基线数据和增量数据,并在系统相对空闲的时候把增量数据合并到基线数据。
使用 LSM-tree 作为数据库的存储子系统会带来一些挑战,这跟传统数据库的定长块原地更新相比,差异很大,或者说完全是两类不同的东西。对于传统的数据库,它的块是定长块,哪怕你修改了数据但脏页还没有刷到硬盘,它也是定长块;对于 SQL 优化器而言,它只需要处理定长块这一个模型。如果采用 LSM-tree,内存里插入或删除了大量的数据,但基线数据并没有真正修改,这对 SQL 优化器的代价模型有比较大的影响。
当今的主流分布式数据库,在敏捷性上也面临着挑战。得益于集中式共享存储,传统数据库的伸缩不需要复制数据。但今天我们没有一个可用的分布式共享存储,这导致几乎所有的分布式数据库几乎都是 Shared Nothing 架构,数据在每个节点上,无论是云盘还是本地盘。这样无论是扩容还是缩容,都需要进行数据复制,无论是时间、IO 带宽,还是网络带宽的消耗都非常大,伸缩的敏捷性就无法保证。
很多用户也会遇到这样的问题,虽然在夜间业务量较小,但由于数据量庞大,做一次缩容可能需要花几个小时,而在业务高峰来之前做一次扩容又需要几个小时,这样一来,几乎一个晚上的时间都被耗尽了。所以,尽管今天大部分的分布式数据库系统都具备垂直伸缩、水平伸缩和动态伸缩的能力,但是敏捷性仍然不足,这仍是行业内还是需要继续探索和改进的方向。
最后,我对今天的分享做一个简单的小结:
云数据库成为主流:云技术得到了快速发展,对于所有企业来说,云数据库已逐渐成为主流选择。 易用&降本:提升效率、降低成本、云的易用性、动态的伸缩、按需使用、按需付费,都在很大程度上提高了企业的效率。此外,资源的池化和复用,通过规模效应即复用能够大幅度降低成本。 云数据库:云数据库的三大重要特征是良好的伸缩能力(易用性)、应用的敏捷性和成本。除此之外,还需要具备 HTAP 能力。要实现这些目标,尤其是在数据库的敏捷伸缩能力方面,依然面临很大的挑战。
我今天的分享就到这里,谢谢大家。
