




1. 使用 COPY 语句批量加载
COPY 语句是将大量数据(一个或多个文件)加载到 Vertica 数据库的最有效方法。对于批量加载,最有用的 COPY 命令是:
- **COPY LOCAL:**将数据文件从本地客户端系统加载到服务器处理文件的 Vertica 主机。
- **在 Vertica 集群中复制源数据:**将数据文件或来自不同源(例如 JSON 和 CSV)的所有指定文件加载到 Vertica 集群中的 Vertica 内部格式。
- **使用具有自定义源、过滤器或解析器的用户定义加载 (UDL) 函数进行复制:**通过控制数据加载设置,从自定义用户定义源、解析器和过滤器加载数据文件或指定文件。
所有类型的 COPY 语句都共享相同的方法和过程,但它们都有不同的限制。无论有何差异,COPY 语句始终有两个阶段:
- 第一阶段(初始化节点)加载并解析文件并将文件分发到其他节点。
- 第二阶段(执行节点)处理所有节点上的数据。
使用 COPY语句可以使用许多执行引擎运算符进行批量加载。用于加载一个或多个文件的执行引擎运算符包括 Load、Parse、Load Union、Segment、Sort/Merge 和 DataTarget。
如果目标表已分段,则 COPY 语句会为每个投影创建分段。分段定义了数据如何在集群节点之间分布,以实现查询性能和快速数据清除。
2. COPY语句如何加载数据
加载一个或多个文件的 COPY 语句工作流分为两个阶段:
阶段 I
- Load 运算符将包含数据的源文件加载到数据库中。Parse 运算符解析并加载数据到数据库。
- Load Union 运算符在对数据进行分段之前将解析的数据合并到一个容器中。加载多个文件时,该运算符处于活动状态,加载一个文件时,该运算符处于非活动状态。
- Segment 运算符根据数据的大小将解析的数据分段为一个或多个投影。此外,表分区将每个节点上的数据分开,以将数据均匀分布在多个数据库节点上。这样做可确保所有节点都参与执行查询。
阶段 II
- Sort 运算符对分段数据和投影进行排序。Merge 运算符适当地合并排序后的数据。Sort 和 Merge 运算符处理聚合数据。
- DataTarget 运算符复制磁盘上的数据。
下图显示了分两个阶段加载一个或多个文件的工作负载。浅蓝色和深蓝色框代表执行引擎操作符。
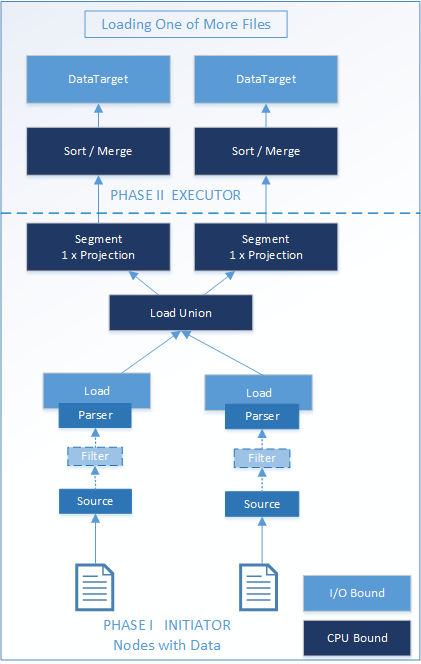
在具有分摊负载(Apportioned Load)的 Vertica 8.0 中,如果所有节点都可以访问源数据,则阶段 I 会在多个节点上发生。
分摊负载是可分割负载,因此您可以在多个节点上加载单个数据文件。
如果源在多个节点上可用并且可以分割,则内置分隔解析器可以自动分摊负载。
如果分摊负载不可用,则阶段 I 只会在读取文件的节点上发生。
阶段 II 使用带有pre-join projections和live aggregate projections的附加执行引擎运算符。
下图“pre-join projections”显示了维度表的附加执行引擎运算符 JOIN 和 SCAN。
下图“live aggregate projections”显示了附加的 GROUP BY/Top-K 执行引擎运算符。
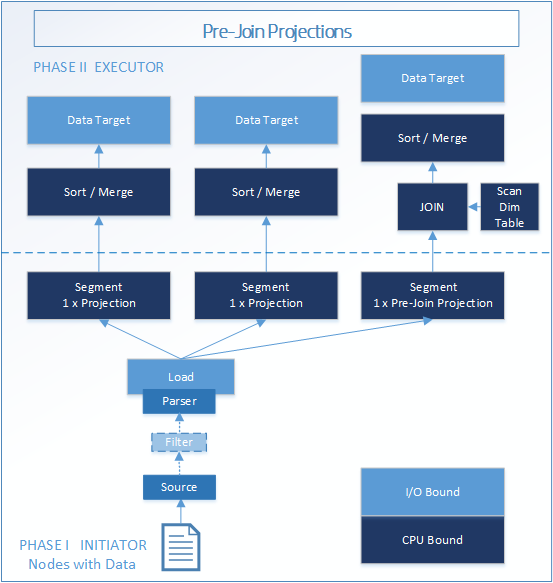
Pre-join projections为维度表添加了额外的执行引擎操作符 JOIN 和 SCAN。
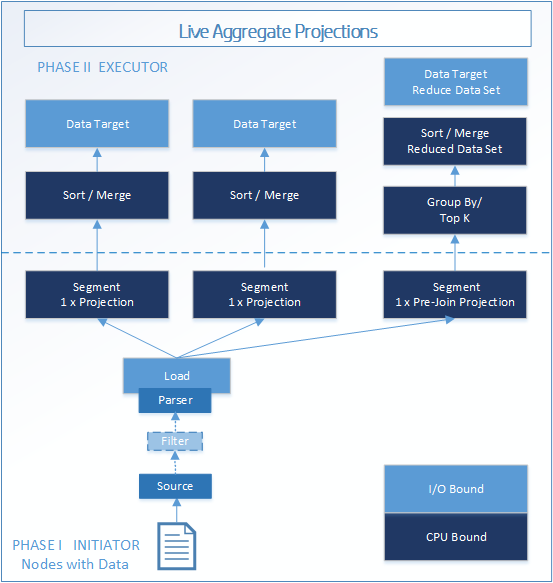
Live aggregate projections添加了 GROUP BY/Top-K 执行引擎运算符。
3. 加载方式
根据您加载的数据,COPY 语句有几种加载方法。您可以从三种加载方法中选择:
- COPY AUTO
- COPY DIRECT
- COPY TRICKLE
3.1 何时使用 COPY AUTO
COPY 使用 AUTO 方法将数据加载到 WOS 中。
对于较小的批量加载,请使用此默认 AUTO 加载方法。当您无法确定文件大小时,AUTO 选项最有用。一旦 WOS 已满,COPY 将继续直接加载到磁盘上的 ROS 容器中。ROS 数据经过排序和编码。
注:从10版本开始,wos资源池被弃用,数据加载不再通过WOS资源池。
3.2 何时使用 COPY DIRECT
COPY 使用 DIRECT 方法将数据直接加载到 ROS 容器中。
对于大批量加载(100 MB 或更大),请使用 DIRECT 加载方法。
DIRECT 方法通过避免 WOS 并将数据加载到 ROS 容器中来提高大文件的性能。使用 DIRECT 加载许多较小的数据集会产生许多 ROS 容器,这些容器必须在以后进行合并。
3.3 何时使用 COPY TRICKLE
COPY 使用 TRICKLE 方法将数据直接加载到 WOS 中。
完成初始批量加载后,使用 TRICKLE 加载方法以增量方式加载数据。
如果 WOS 已满,则会发生错误,并且整个数据加载将回滚。
仅当您的站点具有精细调整的加载和移出过程,并且您确信 WOS 可以保存您正在加载的数据时,才使用此方法。
将数据加载到分区表中时,此选项比 AUTO 更有效。
注:一般涉及消费Kafka数据的场景会用到这种加载方式。
4. 监控数据负载的 Vertica 系统表
Vertica 提供系统表,允许您监控数据库负载:
**LOAD_STREAMS:**监控每个节点上负载流的活动和历史负载指标,并提供有关已加载和拒绝记录的统计信息。
**DC_LOAD_EVENTS:**存储有关负载解析期间重要系统事件的信息。
- Batchbegin
- Sourcebegin
- Parsebegin
- Parsedone
- Sourcedone
- Batchdone
5. 数据加载优化
资源池参数和配置参数影响数据加载的性能。
5.1 资源池参数
以下参数指定资源池的特征,帮助数据库管理员管理用于加载数据的资源。
| Parameter | Description |
|---|---|
| PLANNEDCONCURRENCY | 定义每个 COPY 命令分配的内存量。表示资源池中并发执行查询的首选数量。 |
| MAXCONCURRENCY | 限制并发COPY作业的数量,并表示资源池可用的最大并发执行槽数。 |
| EXECUTIONPARALLELISM | 限制用于处理此资源池中发出并分配给负载的任何单个查询的线程数。 Vertica 根据系统中的核心数、可用内存和数据量设置此值。 除非内存有限,或者数据量非常小,否则 Vertica 会将此值设置为节点上的核心数。 |
5.1.1 Query Budget
RESOURCE_POOL_STATUS 系统表中的 query_budget_kb 列显示在关联池上执行的查询的目标内存。
要检查查询 budget_kb,请使用以下命令:
=> SELECT pool_name, query_budget_kb FROM resource_pool_status;
在修改 query_budget_kb 之前,请注意以下内存注意事项:
- 如果 MEMORYSIZE > 0 且 MAXMEMORYSIZE 为空或等于 MEMORYSIZE,则 query_budget = MEMORYSIZE / PLANNEDCONCURRENCY
- 如果 MEMORYSIZE = 0 且 MAXMEMORYSIZE > 0,则 query_budget = (MAXMEMORYSIZE * 0.95) / PLANNEDCONCURRENCY
- 如果 MEMORYSIZE = 0 且 MAXMEMORYSIZE 为空,则 query_budget = [(General Pool * 0.95) – (sum(其他池的 MEMORYSIZE) ] / PLANNEDCONCURRENCY
5.1.2 如何修改资源池参数
使用如下命令修改资源池参数:
=> ALTER RESOURCE POOL <pool_name> <parameter> <new_value>;
5.2 数据加载配置参数
以下配置参数可以帮助您提高数据加载的性能。
| Parameter | Description |
|---|---|
| EnableCooperativeParse | 在节点上实现多线程协作解析功能。 您可以将此参数用于分隔和固定宽度加载。协作解析并行化是源数据节点的本地操作。 |
| SortWorkerThreads | 控制排序工作线程的数量。 设置为 0 时,将禁用后台线程。当瓶颈位于加载的解析/排序阶段时,可提高加载性能。 |
| ReuseDataConnections | 尝试在查询执行之间重用 TCP 连接。 |
| DataBufferDepth | 控制为数据连接分配的缓冲区。 |
| CompressNetworkData | 压缩数据流量以减少数据带宽。 |
| EnableApportionLoad | 定义数据加载的可分配源/解析器,并将数据拆分成适当的部分。 在 Vertica 8.0 中,apportioned load与“FilePortionSource”源函数一起使用。 |
| MultiLevelNetworkRoutingFactor | 定义大型集群的网络路由并调整计数减少因子。 |
5.3 数据源优化
Vertica对ORC、PARQUET格式文件解析的时候,不支持Apportioned load和Cooperative parse。
- Apportioned load(分配负载)
在分配负载中,Vertica 将单个大文件或其他单个源划分为多个段(部分),并将其分配给多个节点以并行加载。分配负载在规划时根据每个节点上的可用节点和核心划分负载。
要使用分配负载,您必须确保所有参与数据库节点都可以访问源。您通常在分布式文件系统中使用分配负载。
对于支持分配负载的解析器,默认情况下会启用分配负载。要禁用它,请将 EnableApportionLoad 配置参数设置为 0。
- Cooperative parse(协作解析)
默认情况下,Vertica 在一个数据库节点上的单个线程中解析数据源。如果解析器支持协作解析,则节点将使用多个线程来并行化解析。协作解析根据线程的调度方式在执行时划分负载。
对于支持协作解析的解析器,默认情况下会启用协作解析。要禁用它,请将 EnableCooperativeParse 配置参数设置为 0。
所以在加载ORC、PARQUET格式文件的时候,尽量避免使用单个大文件,而是需要多个文件,使得尽可能多的节点能够参与加载和解析。
不同Parser对Apportioned load和Cooperative parse的支持情况:
| Parser | Apportioned load | Cooperative parse | Note |
|---|---|---|---|
| DELIMITED | T | T | |
| FAVROPARSER | F | F | |
| FCEFPARSER | 文档未明确说明是否支持。 | ||
| FCSVPARSER | 文档未明确说明是否支持。 | ||
| FDELIMITEDPAIRPARSER | 文档未明确说明是否支持。 | ||
| FDELIMITEDPARSER | 文档未明确说明是否支持。 | ||
| FJSONPARSER | F | T (only if record_terminator is specified) |
|
| FREGEXPARSER | 文档未明确说明是否支持。 | ||
| ORC | F | F | 从24.4版本可通过将加载划分为单独的源(例如行组或条带)来实现并行加载。 这些源使用多线程在多个 Vertica 节点上并发处理。 线程数根据资源池中的可用内存自动确定。 |
| PARQUET | F | F | 从24.4版本可通过将加载划分为单独的源(例如行组或条带)来实现并行加载。 这些源使用多线程在多个 Vertica 节点上并发处理。 线程数根据资源池中的可用内存自动确定。 |
6. 案例介绍
如果您在将数据加载到数据库时无法解决问题,请联系 Vertica 支持。
6.1 加载大批量文件
案例: 数据量太大,加载需要很长时间。
建议:通过以下两种方式之一使每个节点上的负载并行:
- 使用
EnableApportionLoad参数使工作负载在集群中的不同节点之间并行。对于分摊负载,在加载文件的节点之间共享文件,并使用以下语句安装FilePortionSource Source UDx参数:
=> COPY copy_test.store_sales_fact with source FilePortionSource(file='/data/test_copy/source_data5/
Store_Sales_Fact.tbl',nodes='v_vdb_node0001,v_vdb_node0002,v_vdb_node0003')direct;
- 拆分并暂存 NFS 挂载点中的文件,以便所有节点都可以访问任意节点上的文件。
两种选项的加载性能相似。但是,第二种选项需要您手动分割文件。
6.2 加载多个小文件到同一目标表
案例:使用 COPY DIRECT 加载多个小文件会降低性能。带有小文件的多个语句会生成多个 ROS 容器。大量 ROS 容器会影响 Vertica 的性能,并且在加载完成后需要 Tuple Mover 进行额外的工作。
建议:考虑使用 COPY 语句加载多个小文件的以下选项:
- 控制 COPY 语句的数量以合并加载文件。较少的 COPY 语句可减少事务数量并在一次事务中加载更多数据。
- 使用 Linux 管道合并加载文件。
- 在同一个 COPY 语句中合并文件可提高性能。
6.3 加载宽表
**案例:**具有large VARCHAR 列的宽表是 COPY 命令第二阶段工作流的瓶颈。
**建议:**考虑以下加载宽表的选项:
- 针对特定加载场景修改
LoadMergeChunkSizeK参数。 - 对宽表和多个小表使用弹性表。将宽表加载到弹性表中需要加载一个字段而不是多个字段。因此,它减少了目录的大小并提高了整体数据库性能。初始加载非常快,用户可以快速获得数据。但是,与列式存储相比,查询性能较低。
- 使用 GROUPED 相关列加载宽表。GROUPED 子句将两个或多个列分组为一个磁盘文件。如果一列的值与另一列的值相关,则两列是相关的。
您无法通过添加更多资源、拆分文件或在节点之间并行化工作来解决此问题。联系Vertica支持并在他们的指导下调整配置参数。

