




SELECT ...FROM ...PIVOT(pivot_agg_clause #定义进行聚集的列pivot_for_clause #定义需要分组和转置的列pivot_in_clause #定义限定结果集的值的范围)WHERE ...
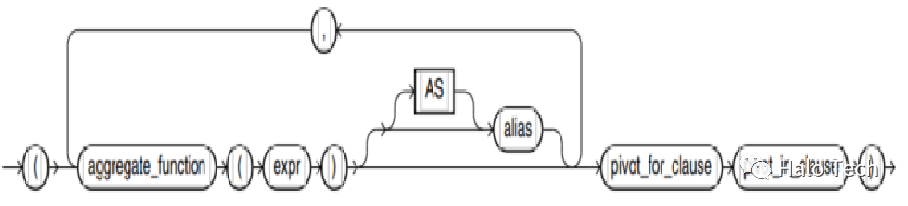
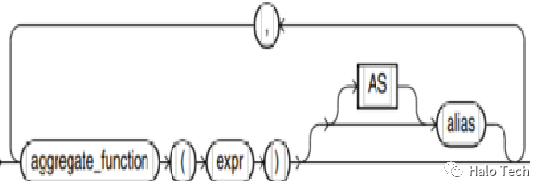
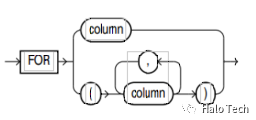
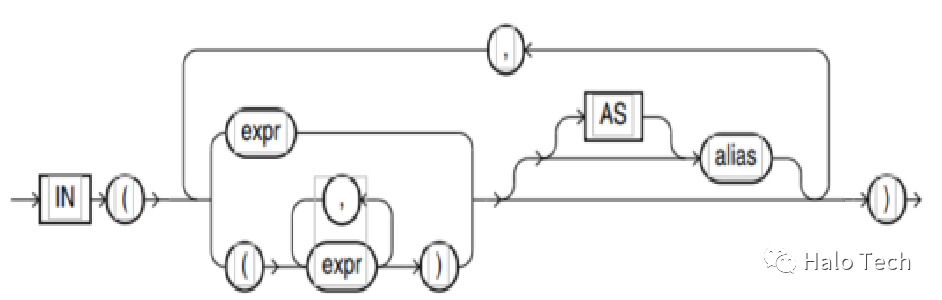
pivot_in_clause语法图如下
PIVOT 示例
CREATE TABLE part (partname varchar2(32),manufacturer varchar2(32),quality int,price decimal(12, 2));INSERT INTO part VALUES ('prop', 'local parts co', 2, 10.00);INSERT INTO part VALUES ('prop', 'big parts co', NULL, 9.00);INSERT INTO part VALUES ('prop', 'small parts co', 1, 12.00);INSERT INTO part VALUES ('rudder', 'local parts co', 1, 2.50);INSERT INTO part VALUES ('rudder', 'big parts co', 2, 3.75);INSERT INTO part VALUES ('rudder', 'small parts co', NULL, 1.90);INSERT INTO part VALUES ('wing', 'local parts co', NULL, 7.50);INSERT INTO part VALUES ('wing', 'big parts co', 1, 15.20);INSERT INTO part VALUES ('wing', 'small parts co', NULL, 11.80);
halo0root=# SELECT * FROM(SELECT partname, price FROM part)PIVOT (AVG(price) FOR partname IN ('prop' AS prop, 'rudder' AS rudder, 'wing' AS wing));+---------------------+--------------------+------+| prop | rudder | wing |+---------------------+--------------------+------+| 10.3333333333333333 | 2.7166666666666667 | 11.5 |+---------------------+--------------------+------+(1 row)
halo0root=# SELECT *FROM (SELECT quality, manufacturer FROM part) PIVOT (count(*) FOR quality IN (1, 2));+----------------+---+---+| manufacturer | 1 | 2 |+----------------+---+---+| local parts co | 1 | 1 || big parts co | 1 | 1 || small parts co | 1 | 0 |+----------------+---+---+(3 rows)
halo0root=# SELECT *FROM (SELECT quality, manufacturer FROM part)PIVOT ( count(*) AS count FOR quality IN (1, 2 AS low));+----------------+---------+-----------+| manufacturer | 1_count | low_count |+----------------+---------+-----------+| local parts co | 1 | 1 || big parts co | 1 | 1 || small parts co | 1 | 0 |+----------------+---------+-----------+(3 rows)
halo数据库PIVOT 的使用说明:
PIVOT 可以应用于表、子查询和公用表表达式(CTE)。PIVOT 不可应用于任何 JOIN 表达式、递归 CTE、PIVOT 或 UNPIVOT 表达式。
PIVOT 支持 COUNT、SUM、MIN、MAX 和 AVG 等聚合函数。
PIVOT IN 列表值不得为列引用或子查询。每个值必须与 FOR 列引用类型兼容。
如果 IN 列表值没有别名,PIVOT 会生成默认的列名。对于常量 IN 值(例如“abc”或 5),默认列名是常量本身。对于任何复杂表达式,列名都是表达式本身。
pivot aggregate_function可以带别名也可以不带别名。
pivot _for_clause 单属性列与多属性列对应 pivot_in_clause 每个参数可以有单个或者对各对应值的功能。
pivot_in_clause 每个参数可以对应设置一个别名,如果没有设置别名,截取值表达式作为作为别名,如果一个参数有(多个值表达式),则表达式1_表达式2_...格式合并作为别名;如果常量字符串没有别名,例如‘prop'没有别名,则’prop‘作为别名,单引号不会去除。如果是数值表达式,是+-是表示正负符号的,正数’+‘默认去除,负数要默认要带括号,例如+3别名为3,-3别名为(-3),所以建议表达式最好带别名,不然可能因为列名书写错误导致取不到结果。
pivot_in_clause每个参数的别名与pivot aggregate_function 别名组合格式为 参数别名_函数别名,如果pivot aggregate_function没有别名,则直接取pivot_in_clause参数的别名。
pivot _for_clause 列可以引用cte自定义列别名进行操作。
如果pivot对CTE表操作,pivot aggregate_function用到的列名,pivot_in_clause用到的列名必须要在CTE表中存在,否则会报错。
在pivot aggregate_function用到的列,pivot_in_clause用到的列,不在结果中显示。
在table表或者CTE表中没有被pivot aggregate_function和pivot_in_clause引用的列隐式作为group by的参数,并且在结果中显示。
UNPIVOT
UNPIVOT则比一系列复杂的 LATERAL 语句中所指定的语法更简单和更具可读性。
halo数据库UNPIVOT 语法如下:
SELECT ...FROM ...UNPIVOT(unpivot_val_clause #定义反转置值的列名unpivot_for_clause #定义反转置所得到列的列名称unpivot_in_clause #定义进行反转置已转置列的列表)WHERE ...

unpivot_val_clause语法图显示如下:
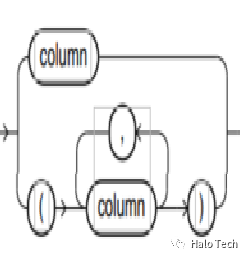
unpivot_for_clause语法图显示如下:
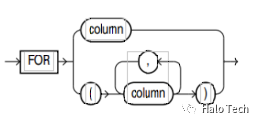
unpivot_in_clause语法图显示如下:
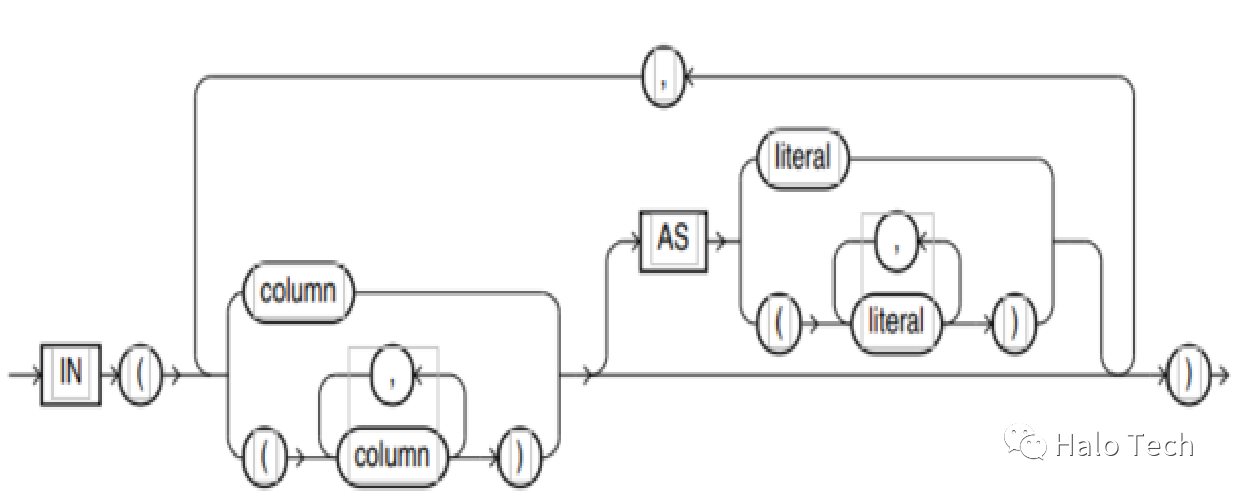
UNPIVOT 示例
CREATE TABLE count_by_color (quality varchar, red int, green int, blue int);INSERT INTO count_by_color VALUES ('high', 15, 20, 7);INSERT INTO count_by_color VALUES ('normal', 35, NULL, 40);INSERT INTO count_by_color VALUES ('low', 10, 23, NULL);
halo0root=# SELECT *halo0root-# FROM (SELECT red, green, blue FROM count_by_color)halo0root-# UNPIVOT ( cnt FOR color IN (red, green, blue));+-------+-----+| color | cnt |+-------+-----+| red | 15 || green | 20 || blue | 7 || red | 35 || blue | 40 || red | 10 || green | 23 || red | 50 |+-------+-----+(8 rows)
halo0root=# SELECT *halo0root-# FROM (halo0root(# SELECT red, green, bluehalo0root(# FROM count_by_colorhalo0root(# ) UNPIVOT INCLUDE NULLS (cnt FOR color IN (red, green, blue));+-------+-----+| color | cnt |+-------+-----+| red | 15 || green | 20 || blue | 7 || red | 35 || green | || blue | 40 || red | 10 || green | 23 || blue | || red | 50 || green | || blue | |+-------+-----+(12 rows)
halo0root=# SELECT *halo0root-# FROM count_by_color UNPIVOT (halo0root(# cnt FOR color IN (red, green, blue)halo0root(# );+---------+-------+-----+| quality | color | cnt |+---------+-------+-----+| high | red | 15 || high | green | 20 || high | blue | 7 || normal | red | 35 || normal | blue | 40 || low | red | 10 || low | green | 23 || low | red | 50 |+---------+-------+-----+(8 rows)
halo0root=# SELECT * FROM count_by_colorUNPIVOT (cnt FOR color IN (red AS 'r', green AS 'g', blue AS 'b'));+---------+-------+-----+| quality | color | cnt |+---------+-------+-----+| high | r | 15 || high | g | 20 || high | b | 7 || normal | r | 35 || normal | b | 40 || low | r | 10 || low | g | 23 || low | r | 50 |+---------+-------+-----+(8 rows)
将表中多个列缩减为一个聚合列,例: 值聚合名 FOR 聚合列名 IN (表列名1 AS 常量别名1, 表列名2 AS 常量别名2...)。 将表中多个列集合缩减为一个聚合列,例:(值聚合名1,值聚合名2) FOR 聚合列名 IN ((表列名1, 表列名2)AS (常量别名1), (表列名3,表列名4)...)。
将表中多个列缩减为多个聚合列,例:值聚合名 FOR (聚合列名1,聚合列名2) IN (表列名1 AS (常量别名1,常量别名2), 表列名2 ...)。
将表中多个列集合缩减为多个聚合列相对应,例:(值聚合名1,值聚合名2) FOR (聚合列名1, 聚合列名2) IN ((表列名1, 表列名2) AS (常量别名1,常量别名2), (表列名3,表列名4)...)。
UNPIVOT 可以应用于表、子查询和公用表表达式(CTE)。UNPIVOT 不可应用于任何 JOIN 表达式、递归 CTE、PIVOT 或 UNPIVOT 表达式。
UNPIVOT IN 列表必须仅包含输入表列引用。IN 列表列必须具有它们都与之兼容的常见类型。UNPIVOT 值列具有这一常见类型。UNPIVOT 名称列属于类型 VARCHAR2。
如果 IN 列表值没有别名,UNPIVOT 则使用列名作为默认值。
unpivot 可以跟EXCLUDE NULLS 或者INCLUDE NULLS 关键字,EXCLUDE NULLS表示结果排除转换后的数值列全为NULL的一行。unpivot不跟关键字默认是EXCLUDE NULLS的操作。
unpivot_value_clause的单列与多列要跟unpivot_in_clause的对应单个参数的单个或者多个取值列,所以两者的个数要保持一致。
unpivot_for_cluase的单列与多列要跟unpivot_in_clause的对应单个参数的单个或者多个常量别名值,所以两者的个数要保持一致。
unpivot_in_clause如果没设置常量别名,默认单个参数中各列名的组合,例如:unpivot_in_clause其中有一个参数包含red,green两列,那么别名常量默认组合为’red_green‘。
unpivot_in_clause可以引用cte自定义列别名进行操作,也可以引用表内列名。
如果unpivot对CTE表操作,pivot_in_clause用到的列名必须要在CTE表中存在,否则会报错。
unpivot_in_clause用到的列,不在结果中存在,它替换为unpivot_for_cluase列和unpivot_value_clause列显示。
unpivot_value_clause,unpivot_for_cluase,pivot_in_clause的都必须是列名,不支持表达式。pivot_in_clause列别名必须是常量字符串,支持Q转义。
