




这是性能调优三部分系列的第一篇文档,包含以下文章:
第 1 部分:如何阅读 Vertica 的执行计划
第 2 部分:使用系统表排除 Vertica 查询性能故障
第 3 部分:重新设计查询优化投影
1. 执行计划
查询计划是 Vertica 查询优化器选择在 Vertica 数据库中执行语句的一系列步骤式路径。Vertica 可以以多种不同的方式执行查询以实现相同的结果。
查询优化器会创建一个以最低执行成本(COST)执行查询的计划。您可以使用 EXPLAIN 来获取执行计划,分析数据库如何处理查询,并可通过可视化工具来查看 Vertica 的查询执行路径。
2. EXPLAIN 语句
EXPLAIN 语句返回优化器针对指定语句的执行计划的格式化描述。您可以使用此信息来分析和调查查询。
默认情况下,EXPLAIN 输出将查询计划表示为层次结构。每个级别代表优化器定义的用于执行查询的单个数据库操作。
EXPLAIN 输出还将 .DOT 语言附加到源文件,使您能够以图形方式显示此输出。
EXPLAIN
SELECT DISTINCT s.product_key, p.product_description
FROM store.store_sales_fact s, public.product_dimension p
WHERE s.product_key = p.product_key
AND s.product_version = p.product_version
AND s.store_key IN
(
SELECT store_key
FROM store.store_dimension
WHERE store_state = 'MA'
)
ORDER BY s.product_key;
-- 或者
EXPLAIN LOCAL VERBOSE
SELECT DISTINCT s.product_key, p.product_description
FROM store.store_sales_fact s, public.product_dimension p
WHERE s.product_key = p.product_key
AND s.product_version = p.product_version
AND s.store_key IN
(
SELECT store_key
FROM store.store_dimension
WHERE store_state = 'MA'
)
ORDER BY s.product_key;
下一节提供有关 EXPLAIN 语句和输出选项的详细信息。
2.1 EXPLAIN 选项
EXPLAIN 语句具有以下类型的输出:
- EXPLAIN :EXPLAIN 选项返回有关查询执行计划的详细信息,而无需执行查询。您可以将输出视为文本输出或图形输出。
- EXPLAIN LOCAL VERBOSE :EXPLAIN LOCAL VERBOSE 选项返回可用于分析复杂查询的详细信息。详细信息包括每个资源的成本和内存使用情况。您可以将输出视为文本输出或图形输出。
3. EXPLAIN 的输出结果
EXPLAIN 选项返回有关查询执行计划的详细信息,而无需执行查询。查询优化器会考虑不同的查询重写、投影组合和 JOIN 顺序,从而产生不同的执行计划。
然后,为了选择最佳查询计划,优化器会执行统计分析。它为每个运算符分配一个成本,并选择成本最低的计划作为执行计划。Vertica 以两种不同的格式返回带有 EXPLAIN 选项的选定查询计划:
- 文本输出:查询计划的纯文本表示。查询计划详细列出了步骤,Vertica 以自下而上的方式执行查询计划。
- 图形输出:查询计划采用 .DOT 语言。
- 您可以使用管理控制台查看树路径。
- 您可以使用 Graphviz 等 Web 可视化工具查看图形表示。
此表示比纯文本计划提供更多详细信息,并为复杂查询提供更好的可读性和演示。
3.1 EXPLAIN 的文本输出
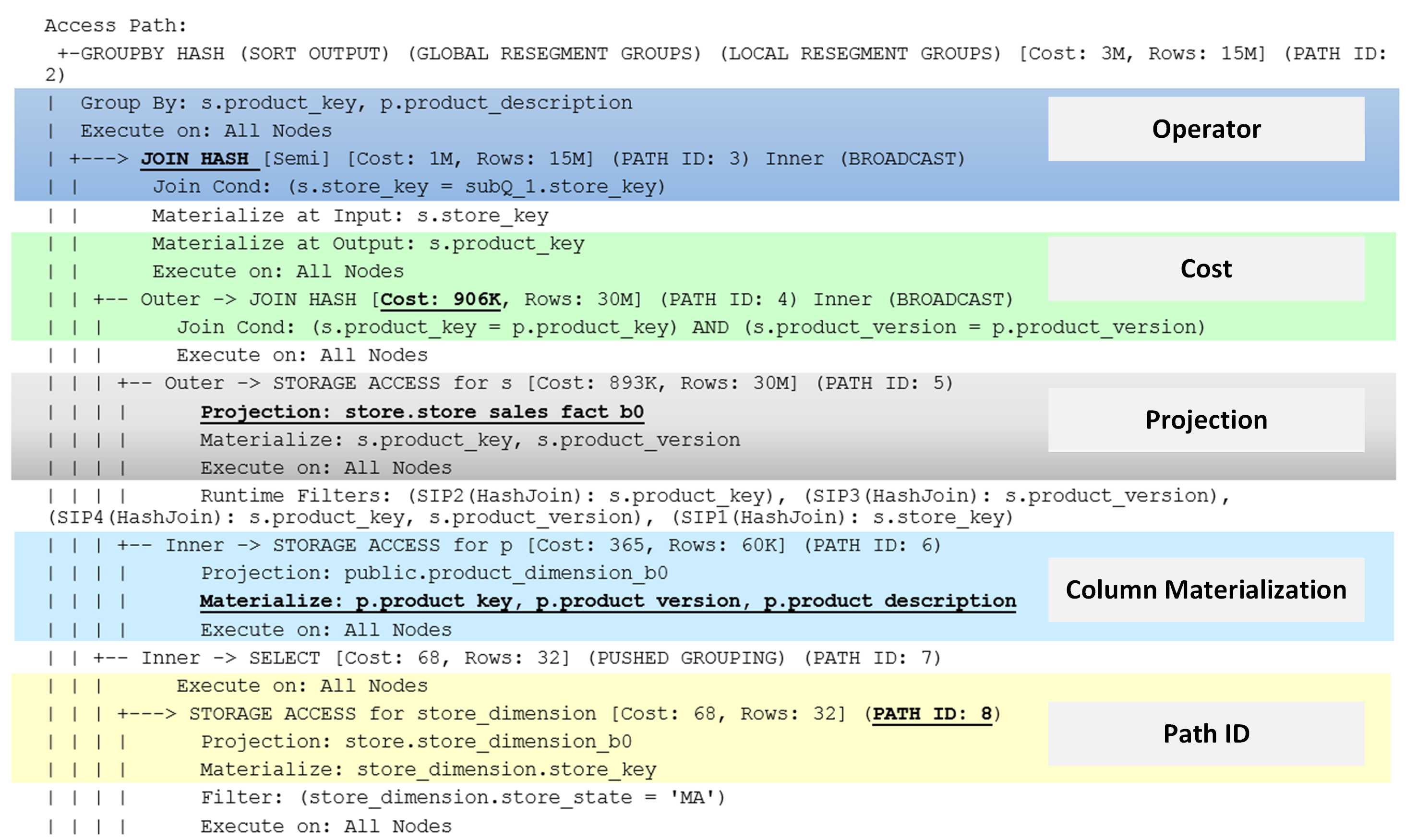
本文档前面显示的示例查询的访问路径信息描述了查询的运算符、成本、投影、列实现和路径 ID。
-
Operators(运算符):Vertica 使用自下而上的方法执行查询计划中指定的运算符,例如 JOIN、SORT、FILTER、LIMIT。这些运算符可以:
- 单线程或多线程
- 将数据传输到下一个运算符
例如,某些运算符需要先完成计算,然后才能转到下一个操作,例如 SORT 或 GROUPBYHASH。其他运算符可以在完成计算之前传输数据,例如 JOIN。
-
Cost(成本):优化器使用估算 CPU、内存和网络资源的算法来计算每个运算符的成本。资源使用情况的估计基于统计信息数据。统计数据的一些示例如下:
- 表中的行数。
- 每列的不同值的数量。
- 每列的最小值或最大值。
- 每列中值分布的直方图。
- 每列的磁盘空间。
及时更新统计数据。如果没有准确的统计数据,优化器可能会选择影响查询性能的次优计划。
通过运行以下任一命令来更新统计信息:
=> SELECT ANALYZE_STATISTICS
=> SELECT ANALYZE_HISTOGRAM
有关更多信息,请参阅 Vertica 文档中的获取统计信息和直方图。
- Projection(投影):优化器会分析满足查询要求的可能投影组合,以确定哪个投影的计算成本最低。当优化器计划查询时,它会为每个表选择一个投影。但是,如果某个节点发生故障,优化器可能会为同一张表选择两个投影。
- Column Materialization(列数据物化):列数据物化提供对列的访问以执行运算符。访问是指根据投影列定义打开列文件、进行编码和解压缩。
- Path ID(路径 ID):路径 ID 是优化器为特定事务分配给每个查询操作的整数值。当查询计划包含多个运算符时,分析路径 ID 的配置文件信息有助于优化器在每个实例中识别运算符。
3.2 EXPLAIN 的图形输出
使用管理控制台查看查询计划的图形表示。管理控制台随 Vertica 一起提供。有关如何使用管理控制台查看查询计划的更多信息,请参阅 Vertica 文档。
如果您无法访问管理控制台,则可以使用开源 Web 可视化工具查看图形。图形输出提供有关查询计划的详细信息,以便更好地理解查询计划。
下图显示了图形可视化工具 Graphviz 如何显示本文档前面的示例查询的图形。下图是完整图形的片段。
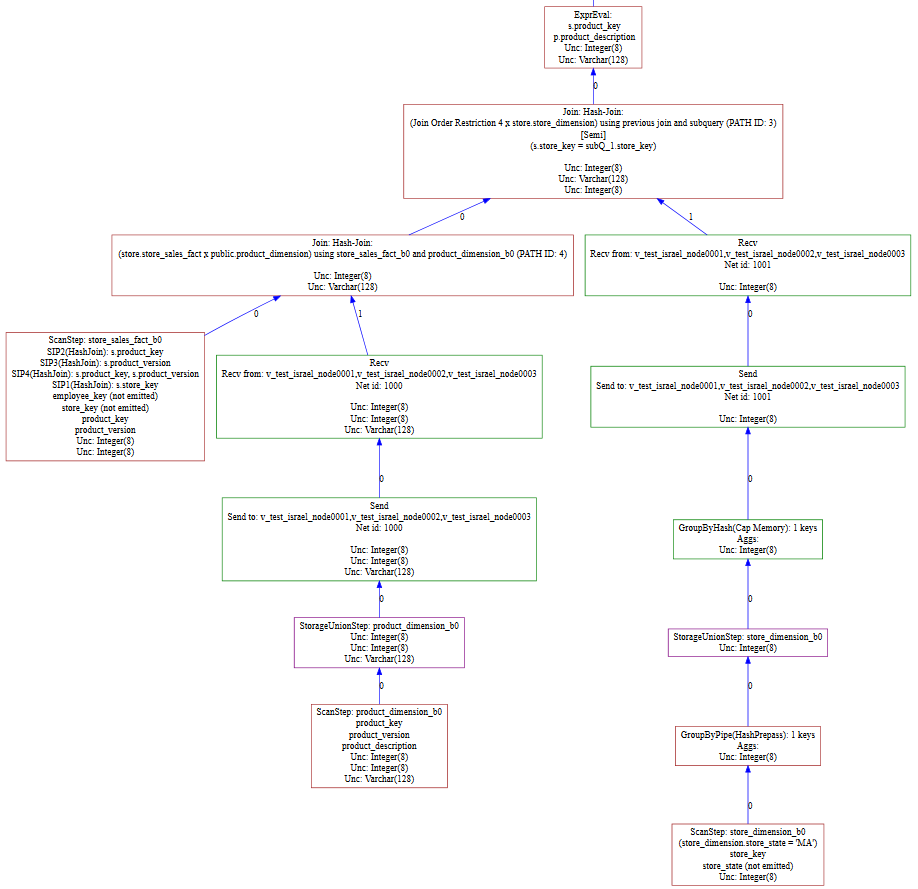
图中的每个对象都对应一个运算符,方框提供了有关该运算符的详细信息。方框的不同形状和颜色可帮助您直观地了解数据流。
| Color | Description |
|---|---|
| Green 绿色 |
Single-threaded operation that passes data from its own operator to another. 将数据从其自己的运算符传递到另一个运算符的单线程操作。 |
| Brown 棕色 |
Multi-threaded operators. The number of threads that can be managed on the settings the resource pool in which the query is executed. 多线程运算符。 可以在执行查询的资源池的设置上管理的线程数。 |
| Purple 紫色 |
Combined stream of data or storage. 组合数据流或存储。 |
| Blue 蓝色 |
Data target that is written to the disk. 写入磁盘的数据目标。 |
| Shape | Description |
| Oval or Circle 椭圆形或圆形 |
Push model. The operator sends the information to the next operator above it. 推送模型。操作员将信息发送给其上方的下一个操作员。 |
| Rectangle 长方形 |
Pull model. The next operator looks for information from the operator data buffers. 拉动模型. 下一个操作符从操作符数据缓冲区查找信息。 |
| House | Root object where the query starts. |
下表列出了前述图形计划中最重要的操作符。
| Operators | Description | Usage Considerations |
|---|---|---|
| Copy | Makes a copy of the data for the buddy projections during load. 在加载过程中为伙伴投影制作数据副本。 |
|
| DataTarget | Writes the data from WOS to ROS during load. 在加载期间将数据从 WOS 写入 ROS。 |
|
| ExprEval | Evaluates expressions such as C1+C2. 计算诸如 C1+C2 的表达式。 |
Select only the required columns. 仅选择所需的列。 |
| Filter | Filters Vertica tuples to the next operator. 将 Vertica 元组过滤到下一个运算符。 |
|
| GroupByHash | Aggregates tuples in hash in memory before streaming data to the next operator. 在将数据流传输到下一个运算符之前,先在内存中的哈希中聚合元组。 |
GroupByHash uses all possible memory. If the data exceeds available memory, disk spillover results. The operator must complete all the operations before passing the data to the next operator. GroupByHash 会使用所有可能的内存,如果数据超出可用内存,则会导致磁盘溢出,操作符必须完成所有操作后才能将数据传递给下一个操作符。 |
| GroupByPipe | Aggregates sorted tuples before streaming data to the next operator. 在将数据流传输到下一个运算符之前,聚合已排序的元组。 |
GroupByPipe has fewer memory requirements than GroupbyHash and streams data to the next operator. GroupByPipe 比 GroupbyHash 需要的内存更少,并且会将数据传输到下一个运算符。 |
| Join Merge-Join | Joins pre-sorted tuples. 数据预先排序 |
Uses less memory. 使用更少的内存。 |
| Join Hash-Join | Joins unsorted tuples by loading the inner side of the join operator in memory. 通过将join运算符的inner加载到内存后与未排序的数据进行关联。 |
If the inner side is large, and the data does not fit in memory, the query fails. If the inner side is small, the operation is faster than merge-join. 如果inner表很大,并且数据无法装入内存,则查询失败。 如果inner表较小,则操作比merge-join更快。 |
| Load | Loads data from disk and parses the input. 从磁盘加载数据并解析输入。 |
|
| Merge | Merges multiple data streams into one sorted stream. 将多个数据流合并为一个已排序的流。 |
|
| NetworkRec NetworkSend |
Information about the data sent to another node or the data received from another node. 发送到另一个节点的数据或从另一个节点接收的数据相关信息。 |
The query requires more memory for each pair of network operators (send and receive). |
| ParallelMerge | Combines sorted data stream. 合并已排序的数据流。 |
|
| ParallelUnion | Combines not sorted data stream. 合并未排序的数据流。 |
|
| Root | The first operator. 第一个步骤。 |
|
| Scan | Reads data from the disk for applying filters. 从磁盘读取数据以应用过滤器。 |
|
| Sort | Sorts data stream. 对数据流进行排序。 |
|
| StorageMerge | Combines data storage while maintaining the sort order. 合并数据存储并保持排序顺序。 |
|
| StorageUnion | Combines data storage without maintaining the sort order. 合并数据存储但不保持排序顺序。 |
|
| Top-K | Analytic function that returns the Top-K tuples. 返回Top-K的分析函数。 |
|
| ValExpr | Evaluates join expressions. 评估连接表达式。 |
接下来,让我们详细检查示例查询的三个运算符。
-
Send or Recv(发送或接收):平面图中间的发送和接收的绿色部分表示网络操作,例如广播或分段,这可能表示投影设计不正确。

在图中,如颜色所示,数据通过网络单线程移动。在计划的中间,这种单线程会减慢查询速度,因为此操作上方的运算符在第一个 Send 操作完成之前无法完成执行。此外,此网络操作需要更多内存,因为每个 Send/Recv 组合都需要一个网络缓冲区来保存元组。集群的节点越多,所需的缓冲区就越多。避免使用 Send/Recv 运算符。为此,请重新设计您的投影,以便在执行连接或分组时节点中可以使用数据。
-
GROUPBYHASH:GROUPBYHASH 是单线程操作,而不是数据流操作。Vertica 必须完成整个 GROUPBY 计算才能将信息发送给 GROUPBYHASH 运算符上方的运算符。在图形计划中,您可以看到以下序列:
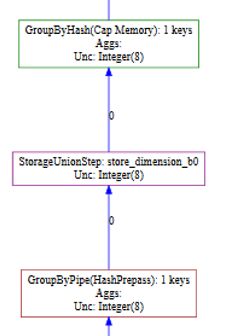
在这种情况下,当 Vertica 在同一路径中执行 GROUPBYHASH 操作时,它还会执行 GROUPBYPIPE 以从存储容器开始聚合。STORAGEUNIONSTEP(紫色框)将这些运算符的结果组合起来,将数据发送到 GROUPBYHASH,以完成此路径中语句的聚合。这些详细信息仅在图形计划中可用,不会出现在文本查询计划中。 -
SIP:图形计划还提供了有关横向信息传递 (SIP) 的信息。在图形计划中,SIP 显示了 Vertica 可用于减少元组导数的过滤器。减少通过 JOIN 运算符传递的元组数量可以降低资源消耗,从而提高查询性能。

4. EXPLAIN LOCAL VERBOSE 输出结果
EXPLAIN LOCAL VERBOSE 是查看有关执行查询的优化器建议的详细信息的另一种方法。EXPLAIN LOCAL VERBOSE 选项添加了更多可用于查看复杂查询的信息。EXPLAIN LOCAL VERBOSE 输出提供了有关以下内容的详细信息:
- Textual output(文本输出):查询计划的纯文本表示。查询计划列出了步骤详细信息,Vertica 采用自下而上的方法执行查询计划。该计划具有与 EXPLAIN 输出中相同的运算符和路径。但是,它还包含更多详细信息,例如每个运算符的成本、内存和网络信息。
- Graphical output(图形输出):查询计划采用 .DOT 语言。
- 您可以使用管理控制台查看树路径。
- 您可以使用 Web 可视化工具(如 Graphviz)查看图形表示。
图形表示比纯文本计划提供更多详细信息,并为复杂查询提供更好的可读性和演示。EXPLAIN LOCAL VERBOSE 选项生成多个图形计划。以下每个都是单独的图形计划。
- Simplified join order(简化的连接顺序):简化计划仅包含理解查询所需的最少连接信息。查看此计划对于理解复杂语句很有用。下一节包含简化连接顺序的示例。
- JOIN graph(连接图):该计划由查询计划中的连接描述组成。
- Plan for each node(每个节点的计划):
- 初始化节点
- 执行节点。如果您有多个节点,您将有多个计划 — 每个节点一个。
- Resource information for each node(每个节点的资源信息):有关在每个节点上执行计划的资源的详细信息。优化器计算资源,执行引擎分配资源。下一节包含一个显示给定节点的资源信息的示例。
考虑以下带有 EXPLAIN 语句的查询。
EXPLAIN LOCAL VERBOSE
SELECT DISTINCT s.product_key, p.product_description
FROM store.store_sales_fact s, public.product_dimension p
WHERE s.product_key = p.product_key
AND s.product_version = p.product_version
AND s.store_key IN
(
SELECT store_key
FROM store.store_dimension
WHERE store_state = 'MA'
)
ORDER BY s.product_key;
4.1 EXPLAIN LOCAL VERBOSE 的文本输出
EXPLAIN LOCAL VERBOSE 返回的查询计划与 EXPLAIN 的查询计划具有相同的信息,但包含其他详细信息,例如成本和不同资源的权重。在下面的示例中,粗体文本标识了每个资源的额外成本、网络和内存使用情况。
Access Path:
Sort Key: (store_sales_fact.product_key, product_dimension.product_description)
LDISTRIB_UNSEGMENTED
+-GROUPBY HASH (SORT OUTPUT) (GLOBAL RESEGMENT GROUPS) (LOCAL RESEGMENT GROUPS) [Cost: 2662115.000000,
Rows: 15000000.000000 Disk(B): 2400000000.000000 CPU(B): 2280000000.000000 Memory(B): 4560000000.000000 Netwrk(B):
4440000000.000000 Parallelism: 3.000000] [OutRowSz (B): 144] (PATH ID: 2)
| Group By: s.product_key, p.product_description
| Execute on: All Nodes
| Sort Key: (store_sales_fact.product_key, product_dimension.product_description)
| LDISTRIB_SEGMENTED
| +---> JOIN HASH [Semi] [Cost: 1387361.000000, Rows: 15000000.000000 Disk(B): 5436997632.000000 CPU(B): 4800001024.000000
Memory(B): 2304.000000 Netwrk(B): 768.000000 Parallelism: 3.000000] [OutRowSz (B): 152] (PATH ID: 3) Inner (BROADCAST)
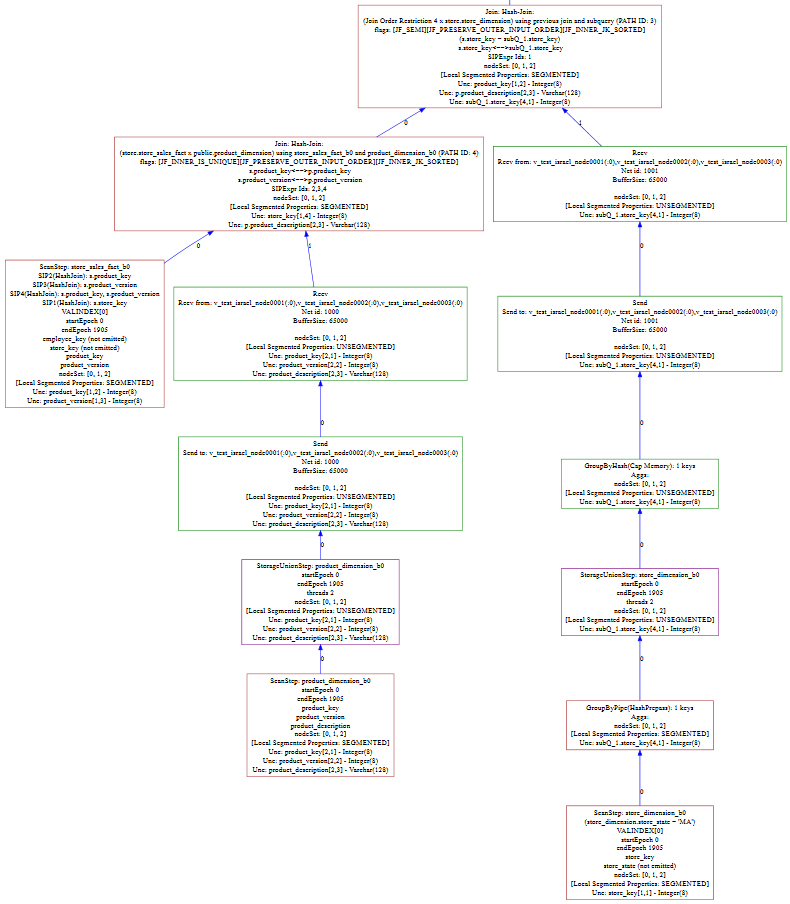
4.2 EXPLAIN LOCAL VERBOSE 的图形输出
下图显示了图形可视化工具 Graphviz 如何显示本文档前面的示例查询的图形。每个框都提供了比 EXPLAIN 语句的图形输出更详细的信息。下图是完整图形的片段。
4.3 EXPLAIN LOCAL VERBOSE 的简化连接顺序
简化连接顺序框以易于阅读的格式提供有关运算符(SORT、JOIN、MERGE 和 GROUPBY)的信息。在具有多个连接的复杂查询中,此计划可以帮助您了解查询执行情况。
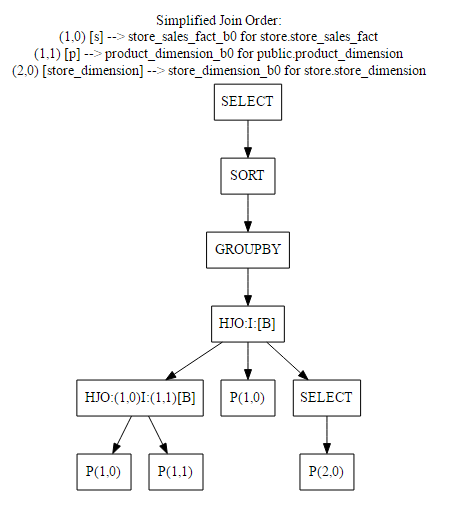
4.4 EXPLAIN LOCAL VERBOSE 的资源信息
EXPLAIN LOCAL VERBOSE 选项返回有关每个节点的资源信息。查询计划生成估计的资源。
以下示例显示了启动器节点执行查询所需的估计资源。
Estimated resources for plan:
-----------------------------
Scratch Memory MB: 1474
File Handles: 64
Worker Threads: 38
Blocking Threads: 22
Externalizing Ops: 4
Unbounded Mem Ops: 2
Max Threads: 2

