





本文字数:5255;估计阅读时间:14 分钟

本文由 Azur Games 首席解决方案架构师 Vladimir Rudev 撰写。
去年,我们发现现有的技术方案已经无法满足公司日益增长的需求。显而易见,我们需要对基础设施进行大规模的重构,因为技术债务已经不堪重负。
我们多年来一直在使用 ClickHouse,因此在 AWS 上尝试 ClickHouse Cloud 自然成为了我们的选择。
最大的挑战是如何在不影响分析系统运行的情况下,无缝迁移 120 TB 的数据库。为此,我们选择了“全量复制”、验证和原子切换的策略来实现目标。你可能会好奇这些数据的来源。作为全球下载量排名第一的移动游戏发行商,我们已推出 150 多个项目,总下载量超过 80 亿次。这产生了海量的遥测数据。
超休闲游戏是一类简单、易上手且门槛低的移动游戏。由于游戏节奏快、玩法简单,用户互动会产生大量遥测数据,这对了解玩家行为、优化变现策略、进行实验以及提升整体游戏体验至关重要。同样,这对 Azur Games 开发的休闲和中度游戏也适用。不同类型的游戏都离不开数据分析。
在这篇文章中,我将详细介绍我们的迁移过程、遇到的挑战以及获得的优势。
剧透一下:我们不仅成功完成了迁移,还取得了诸多积极成果。迁移到云端后的服务成本与之前基本持平。此外,我们节省了两名工程师一半的工作时间,减轻了大量压力,使我们能够将精力从日常维护转向更具创造性和挑战性的任务。

现在,让我们逐步回顾整个迁移过程。
我们希望实现的主要目标:
提升存储可靠性。
改善运行稳定性,减少故障次数。
简化维护工作。
确保系统的可扩展性和灵活性。
在预算范围内优化成本。
我们当前的基础设施:
资源配置:
20 台高性能数据库服务器 + 3 台低功耗的 ZooKeeper 服务器。
11 台 Airflow 服务器(200+ vCPUs)。
6 台 MinIO 服务器(S3 模拟器,用于 Airflow 缓存)。
4 台 MySQL 数据库服务器。
4 台用于 BI 和支持服务的服务器。
2 名 Airflow 工程师。
1 名 DevOps 工程师。
总计:45 台服务器,3 名技术人员。
除此之外,还有许多托管的组件,最重要的包括:ClickHouse、ZooKeeper、MySQL、MinIO、Airflow(调度器和工作节点)以及 BI 服务。
工具使用情况:
使用 Ansible 来管理所有服务器。
Airflow 2.2.3 版本,已有两年历史。
MinIO 版本同样已有两年历史。
ClickHouse 21.3 版本,使用时间超过两年。

总结:单个磁盘故障导致整个分片崩溃的风险是我们面临的主要问题。这会导致某些项目的数据长期不可用。我们最担心的是磁盘的级联故障。
在长期运行且磁盘负载高的项目中,这种问题并不罕见。服务器中的磁盘通常来自同一批次,因此它们常常在类似的时间出现故障。由于它们的使用时间相同,故障概率也相近。当一块磁盘故障时,相邻的磁盘负载增加。在我们的 RAID 10 服务器中,磁盘成对工作,这意味着一块磁盘的故障会提高其副本磁盘故障的可能性。如果同一组中的两块磁盘同时故障,整个服务器将会宕机。
如果一个副本宕机 3-6 小时,我们不会太担心。然而,如果一块 15 TB 的磁盘故障,同步可能需要长达一周。如果在此期间另一块副本磁盘也故障,整个服务器就会宕机,重新同步副本可能需要三天到一周的时间。在此期间,剩余的副本将因 ETL 过程和同步任务而严重超载。因此,建议每个分片至少有三个副本,并且每个副本的负载不超过 60%,尽管这会显著增加成本。
第二个主要问题是 MinIO。实时更新 MinIO 对我们来说风险较高。随着数据量的增加,服务故障变得更加频繁,添加资源也未能显著改善性能。我们要么存在操作失误,要么遭遇了 MinIO 特定版本的 bug,虽然我们尚未确定问题的根源。随着时间的推移,故障越来越频繁,导致 ETL 任务失败,Airflow 工程师不得不耗费大量时间来排查并恢复失败的任务。
总结来说,我们主要面临两个痛点:
当软件出现崩溃且无法通过简单修复(不涉及更新)解决时,管理员会遇到困难。
ETL 任务失败时,Airflow 工程师会受到持续的干扰,影响数据的及时性和新功能的开发。
尽管我们尽可能自动化这些流程以减少问题的发生,ETL 支持依然占用了大量时间,影响了团队的士气。
找到合适的解决方案耗费了不少时间。以下是我们需要解决的关键任务:
提升存储可靠性
提高运行可靠性
简化维护工作
确保系统的扩展性
符合预算的成本优化
我们评估的选项包括:
1. 继续使用裸机,但更换供应商——其他保持不变
这可以解决扩展性问题,但无法在保持成本不变的同时实现目标。
2. 迁移到 AWS/Google/Azure
如果配置得当,这个选项可以解决存储可靠性、操作稳定性以及成本灵活性问题。凭借我们对 Kubernetes 的技术能力,还可以在一定程度上简化维护工作。
然而,成本问题依然是一个难题。详细解释如下:迁移到 AWS 而不使用 ClickHouse Cloud 虽然能提供更强大的硬件支持,但由于数据量巨大,价格会显著提升。AWS 允许我们使用更大的单体服务器,这能够减少配置的复杂性。我们可以使用一个大分片来取代多个小分片,并配置大量存储设备,但仍然需要至少两个副本。这样一来,我们需要管理 240 TB 的数据,光存储费用就增加了数千美元,还不包括其他费用。因此,成本问题依然突出。
我们也考虑过将数据分为冷热存储,这可能会将成本减半。但这需要经验丰富的工程师进行详细规划和测试,并且要找到合适的配置,确保不会影响未来的服务质量和速度。
3. 保持现有供应商,但在其框架内升级
这可以让我们升级到最新的软件版本,解决部分技术债务问题。但在其他目标上,这种方法只能提供有限的改善。
ClickHouse Cloud 通过将数据存储在 S3 上而非磁盘中,并利用 Zero Copy Replication (ZCR) 技术,大大降低了成本。ZCR 在这里尤为关键,因为它允许我们在一个分片中拥有两个副本,而无需存储两份数据。这样,存储的数据量就等于数据的实际大小。
此外,S3 提供 99.999999% 的数据持久性,且成本远低于传统磁盘存储。
硬件方面:
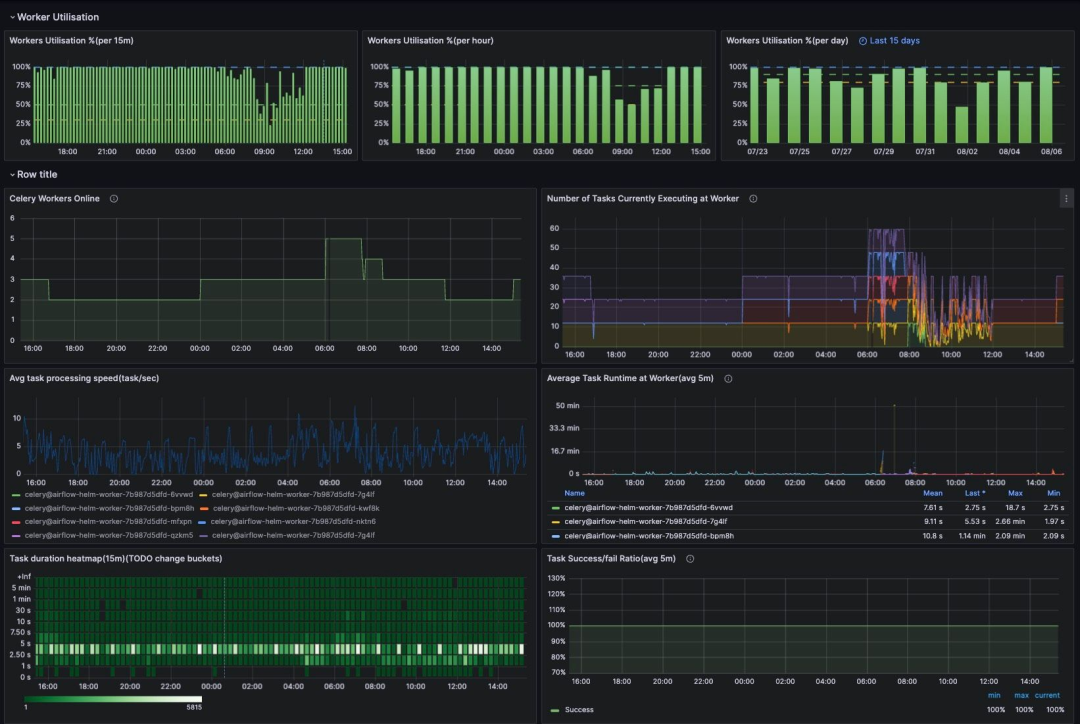
Airflow 现在运行在 24 到 40 个 vCPUs 上,并且支持自动扩展。
ClickHouse 现有三个副本,所有数据都存储在 S3 上。我们对所有请求进行了实际数据量测试,性能均未比旧的 ClickHouse 配置差(这一点非常关键,我们反复验证过)。
大部分请求的处理速度有所提升,其他请求的性能与之前持平。
其余数据库现已迁移到 RDS 中。
管理员和 ETL 工程师的工作负担大幅减轻。
尽管 ClickHouse 数据库和 ETL 基础设施的总成本略有上升,但总体仍在可控范围内。
那么,我们的目标是否实现了呢?
存储可靠性:所有关键组件(如数据库和 S3)均纳入到提供可靠性保障的服务中。我们将许多复杂任务交由 SaaS 解决方案处理,这大幅降低了成本。
操作可靠性、增长灵活性和成本优化:100% 达成。
维护简便性:已解决 80-85%。尽管问题并未完全消除,但已大幅减少。考虑到我们投入的资源,这是一个很好的结果,足以弥补轻微的成本增加,并节省了大量工程师的时间。
扩展性:100% 达成。
我们投入了两名工程师三个月的全职工作时间,外加我一个月的时间来完成迁移。服务成本不仅仍保持在可接受范围内,而且迁移带来的收益早已远超成本。
减少的复杂性:
我们已用 Amazon S3 取代了 MinIO。
之前的三个不同版本的 Airflow 现已统一为最新版本,并在优质硬件上稳定运行,完美处理所有负载。
大量用于旧服务器配置和维护的冗余配置和脚本已被淘汰。
获得的优势:
系统整体变得更简洁、更快、更可靠。
开发人员与最终结果之间的管理流程变得更简化。我们的团队现在可以在不依赖管理员的情况下掌控系统,执行操作。团队可以自主为 Python 添加所需的软件,进行扩容或缩容,从而减少日常操作中的中间环节。
我们从 Amazon 获得了极其优质的硬件,特别是在新的 Airflow 上。
快速的 S3 存储、超高速的网络和磁盘极大地加速了我们的 ETL 流程。
我们能够在几分钟内将系统扩展 2 倍、5 倍甚至 10 倍。例如,当数据提供商端出现暂时性中断时,我们可以快速处理比平时更多的数据。
我们使用了最新版本的 ClickHouse,且在 ClickHouse 团队的管理下持续进行滚动升级。这些升级包含了我们急需的一些新功能和优化:
便捷的新计算函数;
提升查询速度的优化;
与数据存储相关的新特性,既能节省存储空间(进而降低成本),还能加快查询速度;
加速 ETL 进程的新功能,使其更加高效、稳定和简便。
需要实验的任务现在能够更快完成。如今,当我们调整服务器参数时,配置应用的速度快得让我甚至来不及泡一杯茶。能够快速看到结果始终令人欣慰,不必在等待时切换到其他任务。
实验变得更加可控。我脑海中一直有一份“可以优化的事项”清单,大多与数据相关。过去,任何需要大规模调整数据存储和处理方式的实验都会对磁盘造成极大压力,但现在这一问题已经解决。在旧的 ClickHouse 环境中,这个过程让人望而却步,但现在我们可以无忧地进行任何负载测试,而不必担心系统崩溃。
最大的好处在于员工节省了大量时间,现在可以专注于更具趣味性和战略性的任务。我们的一位管理员大约有 60% 的时间被释放出来,而我们的 ETL 工程师现在节省了 40% 的工作时间。
同时,这也大大减轻了精神压力,尽管这方面的具体衡量较为复杂。我们现在能够专注于创新,而不是耗费精力去维护复杂的基础设施。公司总是有很多有趣的项目在等待推进,例如我们终于能够开始实验 DBT(Data Build Tool),这一工具目前广泛应用于数据分析,且非常适合我们的需求。
此外,许多业务任务的交付速度大幅提升。在很多情况下,所需的时间缩短了一半甚至更多。
例如,当我们需要为整个历史周期重新计算数据聚合时,过去我们必须计算集群中的可用资源,估算处理速度,乘以计算量,并在一切顺利的情况下确定最终完成时间。
现在,我们可以即时扩展 ETL 和数据库的计算能力,这意味着任务完成速度可以直接根据资源投入量进行调整,大大加快了任务进度。
通过在相同资源成本下加快完成进度,企业自然从中受益。
并没有新的问题出现,而是面对新的现实。云计算的运作方式不同,云端成本往往很严苛。你需要为每个传输的字节和每个处理器周期付费,即使没有完全利用资源,它仍会产生成本。因此,我们必须优化算法和架构以最大化效率。
不过,这也带来了积极的效果。结合快速扩展能力和强大的硬件,我们可以在较小的努力下显著提升系统性能。
新的集群架构与我们之前的架构有很大不同。过去有效的方案在新集群中不再适用,但新的解决方案也随之而来。在迁移过程中,我们逐步适应了这种新的环境。
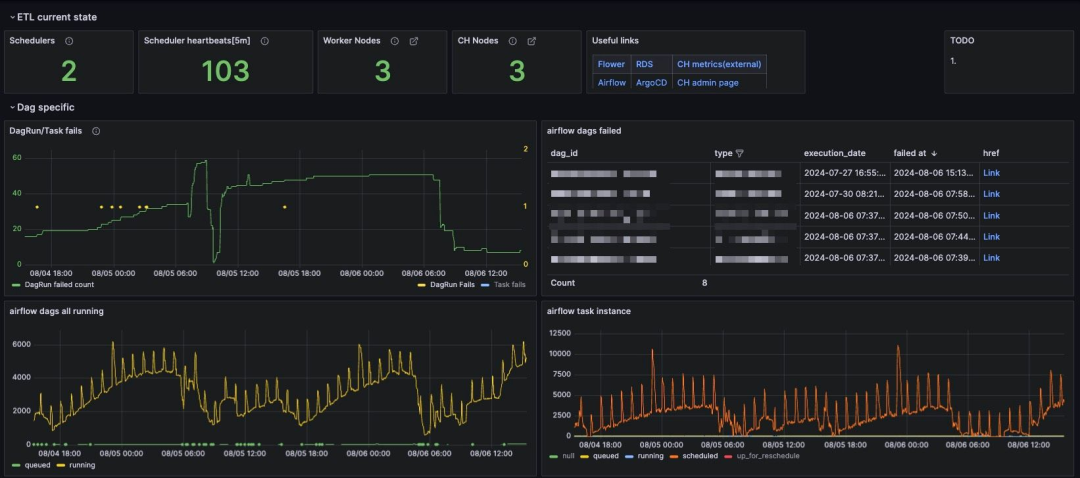
7月。我们正式开始了迁移工作。花了一个月时间与 ClickHouse 团队紧密合作,熟悉产品并进行小规模的实验。
8月。我们意识到需要全面的测试,于是开始迁移数据。我们原计划一个月内完成迁移,最多六周,同时进行必要的代码重构。然而,由于两位工程师经常被业务任务打断,迁移进度有所延迟,许多任务未能按期完成。
9月。我们继续将数据迁移并做出必要调整。
10月。原本规划为备用的时间用于完成剩余的任务并进行全面测试。到了9月底,我们发现了一些数据合并问题,10月初我们继续迁移数据,后半月专注于确保数据准确传输。尽管付出了努力,工作依然未能按计划在10月底完成。
11月。还剩一个月,我们能够更加专注于数据传输和验证,确保准确性。团队表现非常出色。到11月中旬,我们几乎准备好将分析系统切换到新系统。
11月21日,我们切换了系统,但遇到了两个问题。某些 ClickHouse 查询的行为与预期不符。我们报告了这些问题,ClickHouse 团队迅速提供了临时解决方案,并修复了另一个问题。
11月23日,BI 操作正式切换至新的 ClickHouse 系统。
11月27日,我们签署了合同并关闭了旧服务器。
总计:3个月的密集工作。
ClickHouse Cloud 的架构与传统的本地部署大不相同,这让我们在测试阶段遇到了一些挑战。ClickHouse 团队非常支持我们,不仅帮助我们找到替代方案,还根据我们的需求快速进行了代码修改。
在短短三个月内,我们部署了一个更先进的技术解决方案。这几乎为我们提供了 100% 的存储和服务可靠性,为未来扩展提供了空间,并为工程师节省了大量时间。尽管维护成本略有增加,但带来的收益远远超过了这一成本。
阿里云 ClickHouse企业版 服务试用
轻松节省30%云资源成本?阿里云数据库ClickHouse架构全新升级,推出和原厂独家合作的ClickHouse企业版,在存储和计算成本上带来双重优势,现诚邀您参与100元指定规格测一个月的活动,了解详情:https://t.aliyun.com/Kz5Z0q9G


征稿启示
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出&图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com


