今天为大家分享一篇VLDB 2025年的向量检索论文:
-Hardness: A Query Hardness Measure for Graph-Based ANN Indexes 论文地址: https://arxiv.org/pdf/2408.13899
代码地址: https://github.com/CaucherWang/Steiner-hardness
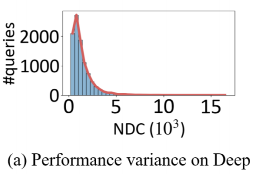
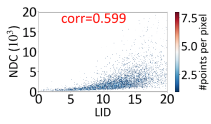
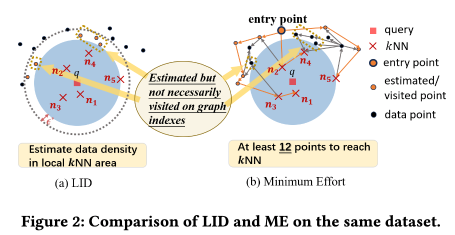
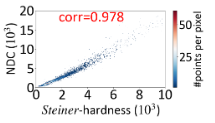
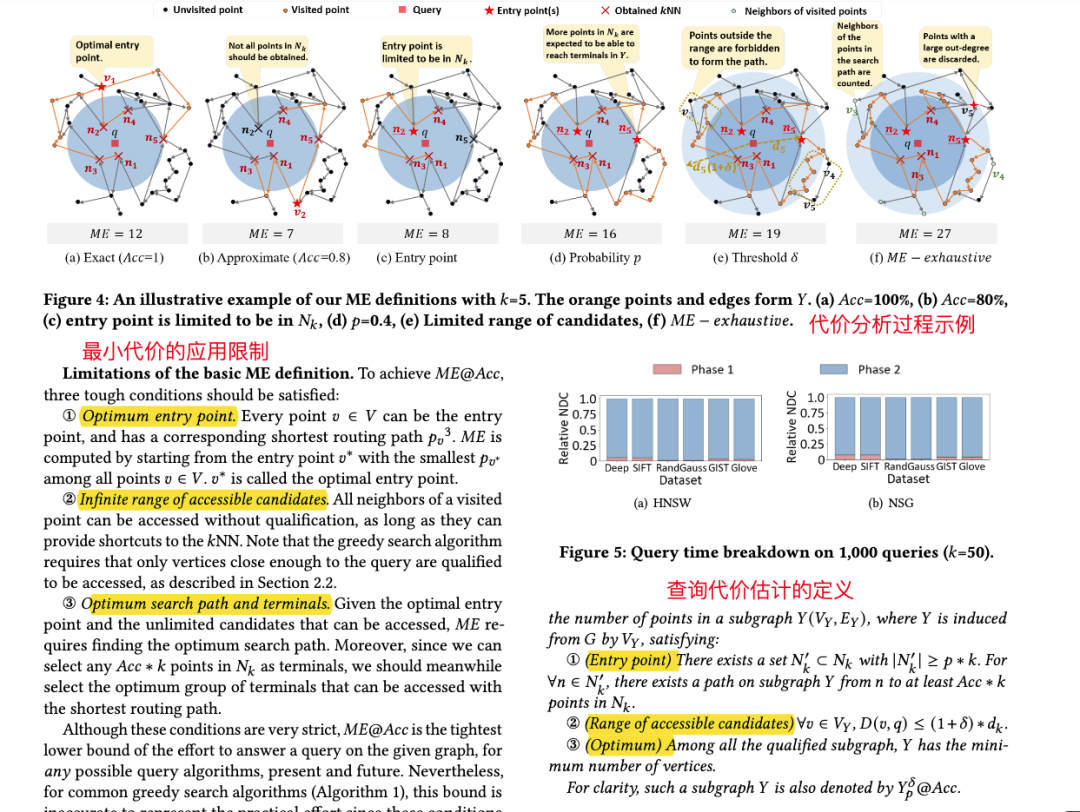
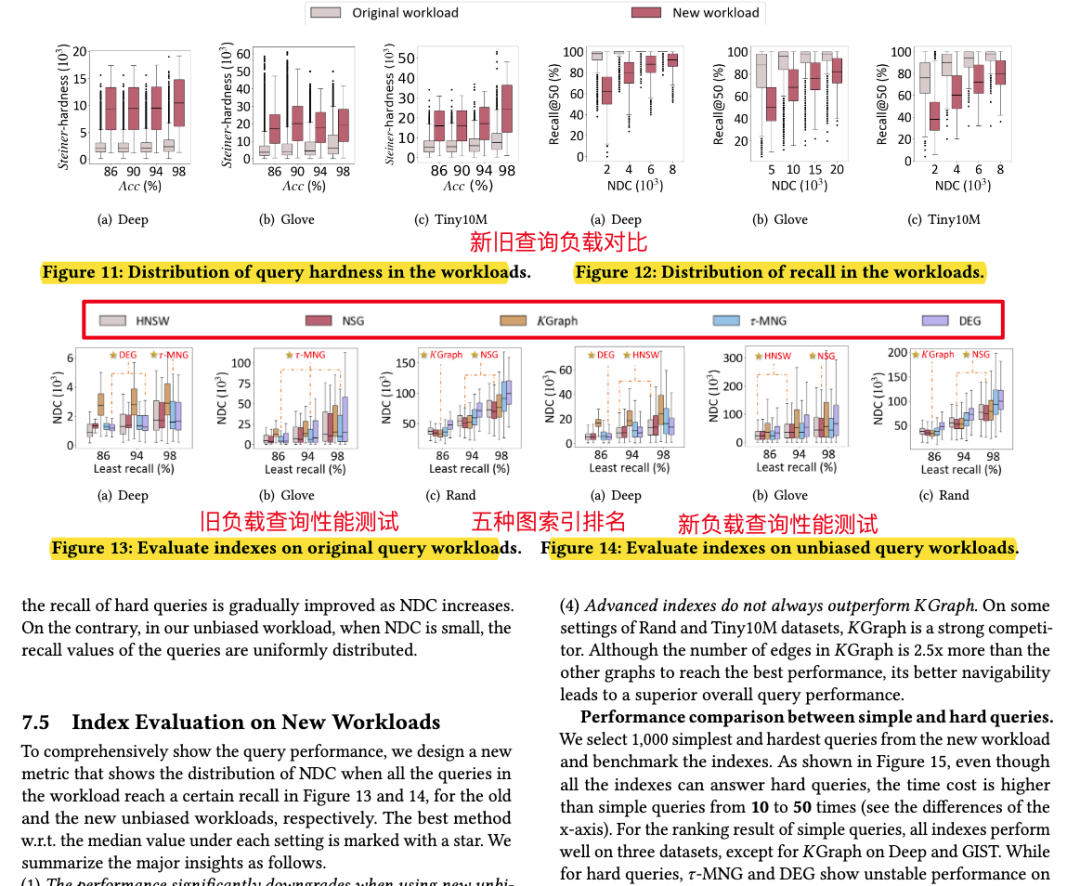
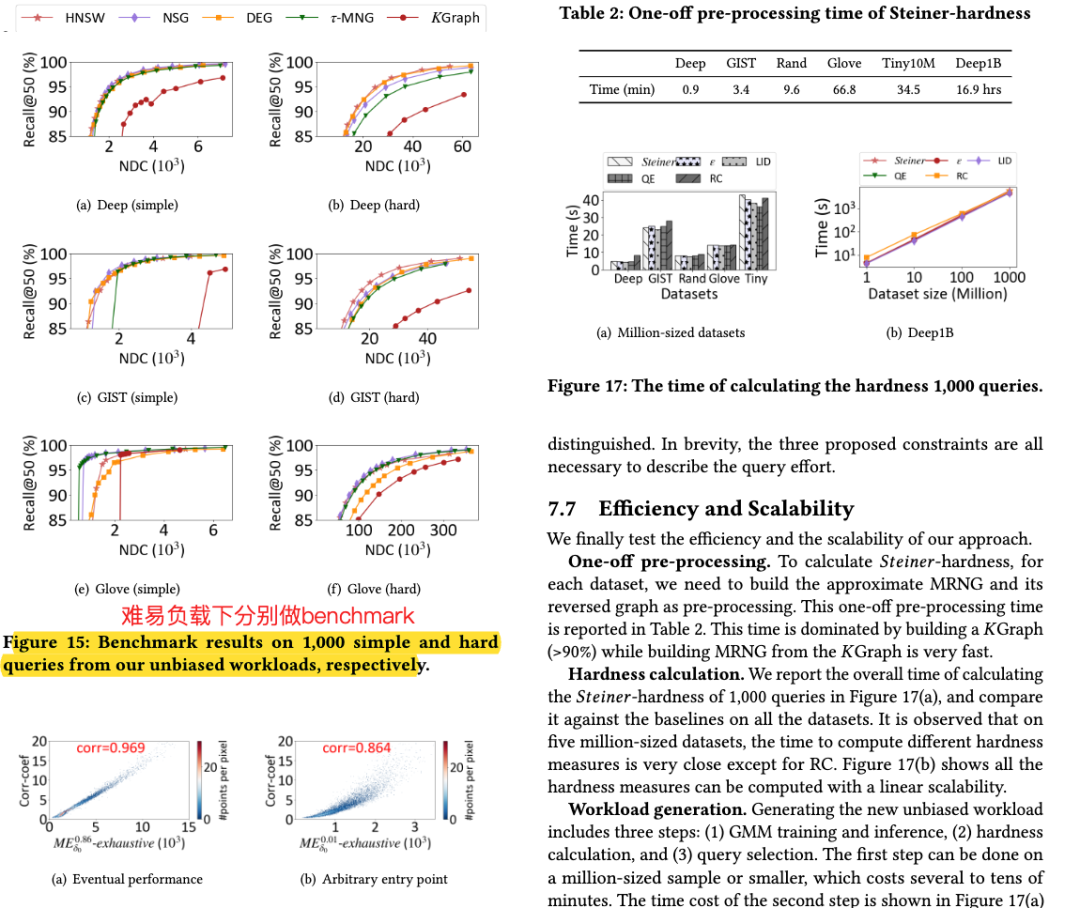
论文概述 图索引是当前向量数据库中普遍认为查询性能最好的索引算法之一。然而最近部分研究发现,图索引的性能在不同查询上并不稳定,即在某些“简单”查询上召回高,查询快;但在“较难”查询上召回不达标,查询速度也更慢。 如下图,在Deep1M数据集上,要想让所有查询达到90%@50召回,大部分简单查询只需要访问不到1000条向量,而少部分难查询需要访问10000向量以上。这样的性能差距会导致在实际使用时,尽管设置了同样的搜索参数,仍然会有一部分查询精度低、速度慢。 这就引出了一个问题,如何在图索引上分辨出简单和困难查询?此前常用的方法是使用局部本征维数LID,然而论文实验证实,LID与实际查询难度相关系数并不高(见下图)。 其原因在于LID是基于kNN区域距离分布的,但是图索引中存在长边,距离近的点可以不访问(见下图褐色矩形中的点)。因此,论文基于图索引的结构特性,探讨了基于图论查询的代价分析方法、并以此设计了查询难度的定义方法,即斯坦纳难度。 从图1中可以看出,目前公开数据集上的大部分查询都是简单查询,使用这种查询负载,难查询的性能很难被观察到,给索引的上线使用带来了隐患。因此,论文设计了均匀包含各种查询难度的向量索引压测负载,并对近年来的最新图索引重新做了评测。 论文结果显示,斯坦纳难度与实际查询代价的相关系数平均在0.8以上,远高于LID。在压测负载上的benchmark结果显示,HNSW,NSG至今仍然是在大部分场景下性能最好的索引结构。 关键算法 最小查询代价分析 论文首先分析了在给定一个图索引的情况下,返回一个满足召回精度条件的查询结果所需的最小代价 是多少。这里的最小意味着不限制查询算法、不限制返回哪些最近邻结果。这一最小代价是图索引查询性能的上确界。 论文随后证明,当召回为1时,这一最小代价实际上等价于在图上以任意点为起点,以knn为终点的最小斯坦纳树问题(无权图)。当召回小于1时,则斯坦纳树的终点有多种组合可能,最小代价则是这些组合中代价最小的一个。 实际查询代价估计 尽管最小代价有着良好的界限性质,但现在使用的贪婪查询算法(有时也称为集束搜索beam search),距离最优查询算法还有不小的距离。要想估计贪婪算法的查询代价,需要在最小代价的分析中加入一些限制。具体包括: 入口点:全局最优的入口点很难找到,但最近邻之一有很多快捷的方法可以得到。因此首个限制要求入口点仅能在knn中选择一个。 搜索范围:贪婪搜索会放弃在搜索过程中距离查询较远的点,尽管这些点有可能通往一条到达最近邻的捷径。因此,第二个限制要求拒绝斯坦纳树算法访问距离查询过远的邻居。 决策代价:对于贪婪搜索算法,查询中的每一步都需要访问上一步的所有邻居,论文将其称之为决策代价。第三个限制要求将斯坦纳树路径上所有点的邻居也纳入代价中。 在这三条限制下,原有的最小斯坦树问题被转换成了一个斯坦纳树问题的变体,而该估计代价和实际查询代价有着很强的相关性,相关系数高达0.98。 查询难度定义 查询难度的定义需要与具体索引技术无关,论文作者选择使用理论图MRNG作为图索引的一个代表图,而查询难度则定义在MRNG上的估计代价。选择MRNG有以下原因: MRNG采用的RNG裁边规则被证实是现有图索引的关键技术; 无偏压测负载构建 压测负载构建是要让难易查询在负载中均匀分布。由于实际场景中可能没有查询集,或者查询集太小,论文用GMM模型学习了向量数据分布,对原始数据集扩增了数据作为查询集,从中选取难度均衡的点构建压测负载。 精彩段落 <<< 左右滑动见更多 >>>
总结 论文在图索引上分析了查询的最小代价,设计了实际查询代价的估计算法,将代价分析问题与经典的斯坦纳树问题联系了起来,并进一步定义了图索引上的查询难度,构造了无偏的压测负载。压测负载上的性能测试显示图索引中HNSW,NSG仍然是最好的索引结构。 代价估计是数据库查询优化中必须的一环,然而在向量数据库中尚无对应算法,其中一个核心难点是同时考虑精度和速度对代价的影响。本文首次在这一问题上做出探索,然而对向量查询优化器的系统研究仍然在起步阶段。 延伸阅读 [1] IS'21:LID作为查询难度的测试 The role of local dimensionality measures in benchmarking nearest neighbor search
(https://pure.itu.dk/ws/files/86422343/1.pdf) [2] IEEE Data Engineering Bulletin'23: ANN-benchmark团队对于近似查询度量合理性的思考 Recent Approaches and Trends in Approximate Nearest Neighbor Search, with Remarks on Benchmarking
(https://sites.computer.org/debull/A23sept/p89.pdf) [3] KDD'15: 时序索引的查询代价分析 Query Workloads for Data Series Indexes
(https://disi.unitn.it/~zoumpatianos/edq/paper/workloads-kdd2015.pdf) 编者简介
王泽宇
复旦大学与巴黎西岱大学联合培养博士生,研究领域为高维数据(向量、序列等)管理和分析。以第一作者在SIGMOD,VLDB,VLDBJ,TKDE等数据库领域会议/期刊发表多篇论文,并担任审稿人。 个人主页:https://zeyuwang.top/
谷歌学术:https://scholar.google.com.hk/citations?hl=zh-CN&user=XXGhABIAAAAJ
技术博客:https://www.jianshu.com/u/d015902c6d09