




在流式数据处理中,Kafka是一个经常被使用的消息队列。本文主要介绍在Flink流式处理场景下,使用Kafka需要注意的问题。
动态扩充 Topic Partition,可以被下游任务发现和消费吗?
答案是可以的。默认情况下,分区发现是禁用的。要启用它,请在提供的属性配置中为flink.partition-discovery.interval-millis设置一个非负值,表示发现间隔(以毫秒为单位)。
在执行正则表达式消费Topic Group时,动态扩充Topic,可以被识别吗?
答案是可以的。默认情况下,主题发现是禁用的。要允许Counsumer 在作业开始运行后发现动态创建的主题,请为flink.partition-discovery.interval-millis设置一个非负值。这使Consumer可以发现名称也与指定模式匹配的新主题的分区。下面是一个主题发现的正则表达:
FlinkKafkaConsumer011<String> myConsumer = new FlinkKafkaConsumer011<>(java.util.regex.Pattern.compile("test-topic-[0-9]"),new SimpleStringSchema(),properties);Consumer Offset是如何被管理的?
Flink Kafka Consumer可以配置如何将偏移量提交回Kafka Brokers(或0.8中的Zookeeper)的行为。请注意,Flink Kafka Consumer不依赖提交的偏移量来提供容错保证。提交的偏移量仅是出于对消费进度的一种监控目的。配置偏移提交行为的方式有所不同,具体取决于是否为作业启用了Checkpoint。
Checkpointing disabled: 如果禁用检查点,则Flink Kafka Consumer依赖于内部使用的Kafka客户端的自动定期偏移量提交功能。因此,要禁用或启用偏移提交,只需在提供的“属性”配置中将enable.auto.commit(或对于Kafka 0.8为auto.commit.enable)/ auto.commit.interval.ms键设置为适当的值。
Checkpointing enabled: 如果启用检查点,则Flink Kafka Consumer将在检查点完成后提交存储在检查点状态中的偏移量。这样可以确保Kafka broker中已提交偏移量与检查点状态中的偏移量一致。用户可以通过在使用者上调用setCommitOffsetsOnCheckpoints(boolean)方法来选择禁用或启用偏移提交(默认情况下为true)。请注意,在这种情况下,“属性”中的自动定期偏移提交设置将被完全忽略。
往下游Kafka Topic写数据时,可以实现 EXACTLY_ONCE 的语义吗?如何实现呐?
在Checkpointing enabled模式下,比如在High BackPressure模式下,会导致checkpoint超时或者失败,那么此时来观测Kafka Offset是不是变的,但是数据却是已经处理的,只是未来的及同步信息。如下图所示:
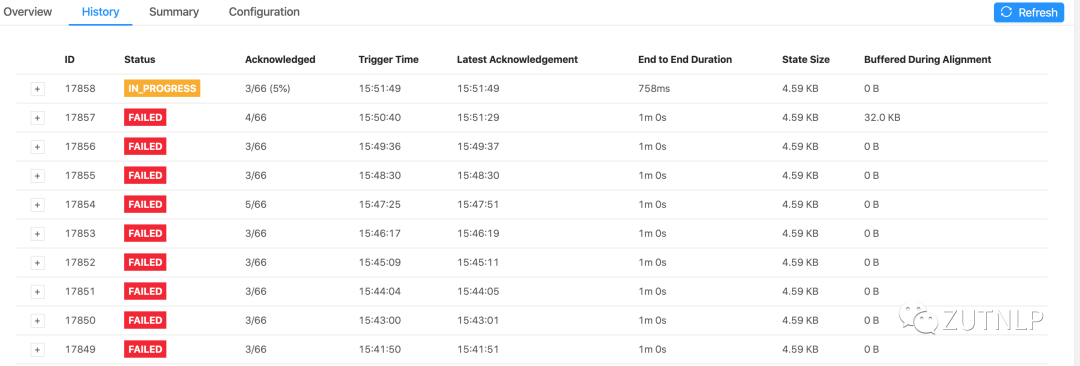
Checkpoint-Failed
Kafka Offset Monitor
checkpoint失败时,可以看到监测到的consumer offset一直在累加。当checkpoint成功时,便瞬间回落,解除告警信息。
这在最早的Kafka版本中是不支持。这里其实是利用到了Flink两阶段提交的模式,那么下游Sink要支持事物才可以。这里讨论的Kafka 版本大于等于0.11。启用Flink的检查点后,FlinkKafkaProducer011(适用于Kafka> = 1.0.0版本的FlinkKafkaProducer)可以保证精准一次性写入。
除了启用Flink的检查点之外,还可以通过将适当的语义参数传递给FlinkKafkaProducer011(适用于Kafka> = 1.0.0版本的FlinkKafkaProducer)来选择三种不同的操作模式:
Semantic.NONE:Flink将不做任何保证。产生的记录可能会丢失或可以重复。
Semantic.AT_LEAST_ONCE(默认设置):与FlinkKafkaProducer010中的setFlushOnCheckpoint(true)相似。这样可以保证不会丢失任何记录(尽管可以重复记录)。
Semantic.EXACTLY_ONCE:使用Kafka事务提供一次精确的语义。每当使用事务写入Kafka时,请不要忘记为所有使用Kafka记录的应用程序设置所需的isolation.level(read_committed或read_uncommitted-后者为默认值)。
Refer:https://ci.apache.org/projects/flink/flink-docs-stable/dev/connectors/kafka.html
