




flink job overview
Checkpoint的知识讲解
backpressure的知识讲解
实际案例介绍分析
I. Job Overview

 Job-1
Job-1
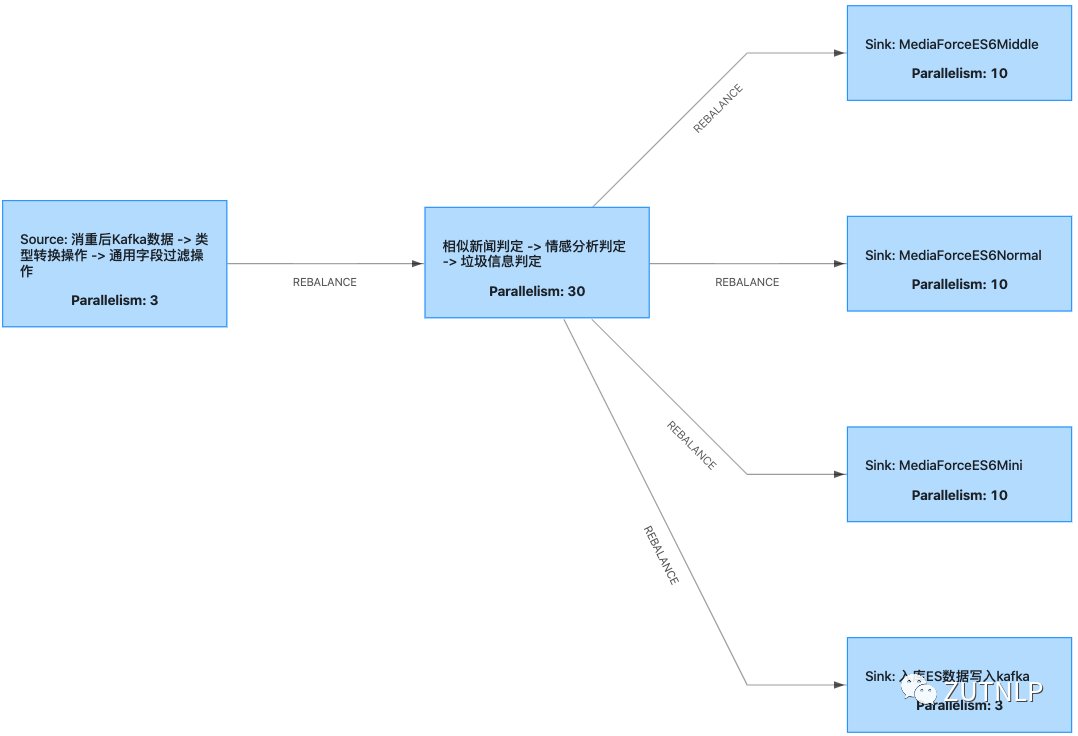
Job-2
II. Checkpoint的知识讲解
barrier是什么
barrier 从 Source Task 处生成,一直流到 Sink Task,期间所有的 Task 只要碰到 barrier,就会触发自身进行快照。如图所示,Checkpoint barrier n-1 处做的快照就是指 Job 从开始处理到 barrier n-1 所有的状态数据,barrier n 处做的快照就是指从 Job 开始到处理到 barrier n 所有的状态数据。 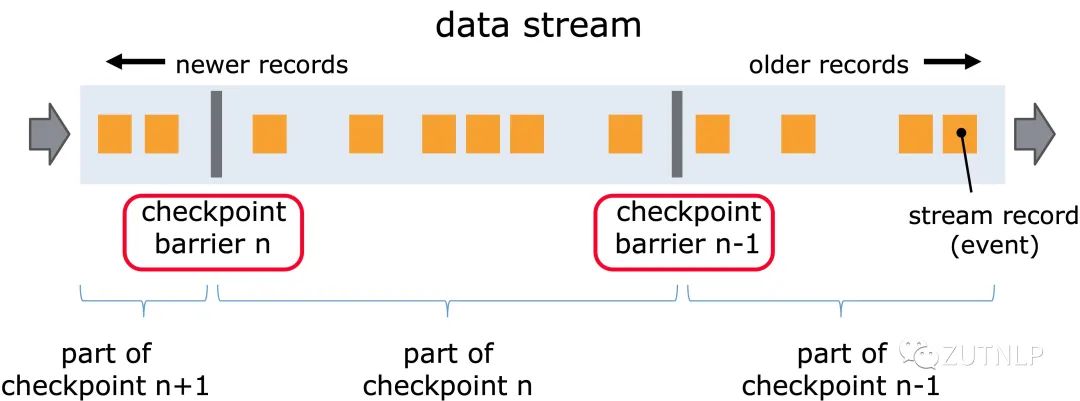
可以看到位于barrier之前的数据在本次Checkpoint之前都需要处理完,而处于barrier之后的数据在本次Checkpoint之前是不能处理的。当然这属于barrier对齐模型,比较严格,会影响数据处理速率。 barrier对齐与非对齐
我们知道Flink支持两种语义:Exactly Once 和 At Least Once。分别对应着barrier对齐和非对齐。我们来理解下barrier对齐的概念。 单流的barrier
如果 Operator 实例只有一个输入流,就根本不存在 barrier 对齐,自己跟自己默认永远都是对齐的,所以当我们的应用程序从 Source 到 Sink 所有算子的并行度都是 1 的话,就算设置的 At Least Once,无形中也实现了 barrier 对齐,此时 Checkpoint 设置成 Exactly Once 和 At Least Once 一点区别都没有,都可以保证 Exactly Once。
并行barrier
如下图所示,该Operator具有两个输入流。当JobManager下发Checkpoint时,由于该算子的上游输入流执行速率并非一致,barrier并非能同时到达,那么问题来了,该Operator何时才可以进行Checkpoint?

首先考虑barrier aligning(对齐)的情况(上图由左至右依次查看),上游的数字流我们称之为数据流和字母流:
begin aligning
数字流的barrier优先达到,字母流barrier未到达。数字流暂停处理,其实是放置于Input buffer中。字母流正常处理。
aligning
该Operator获取到字母流的barrier,开始准备Checkpoint
checkpoint
监测该Operator上游输入流的barrier都到达,触发Checkpoint
continue
该Operator正常处理数据,并发送barrier给下游输出流。
Checkpoint Monitor
这里主要介绍几组有意义的监测指标。
History Tab
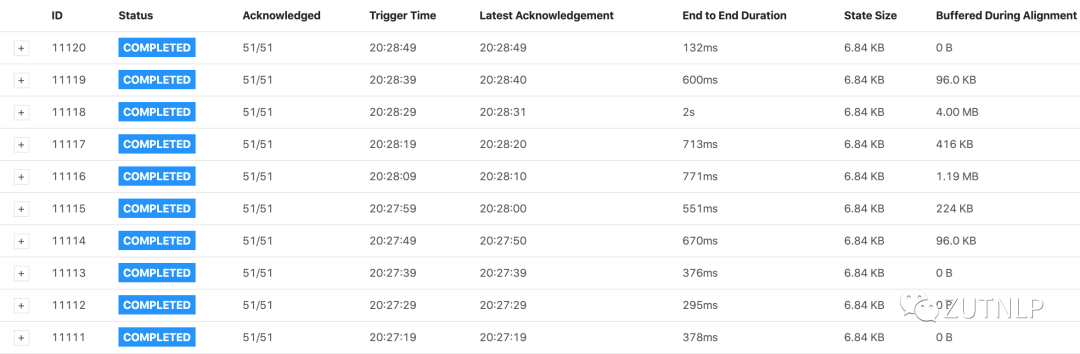
Trigger Time:在JobManager上触发检查点的时间。
Latest Acknowledgement: JobManager收到对任何子任务的最新确认的时间(如果尚未收到确认,则为n/a)
Buffered During Alignment: 在所有已确认的子任务aligning期间缓冲的字节数。如果在Checkpoint期间发生aligning,则该值大于零0。如果检查点模式为AT_LEAST_ONCE,则它将始终为零,因为AT_LEAST_ONCE模式下不需要流对齐。
State Size: 所有已确认子任务的状态大小
Configuration Tab
Checkpointing Mode: Alignment(Exactly Once) 或者 Not-Alignment(At least Once)。
Interval: Checkpointing 时间周期。
Timeout: JobManager等待Checkpointing的响应时长,超时后,会触发一轮新的Checkpointing。
Minimum Pause Between Checkpoints: 两次Checkpoint之间的最小时间间隔。
Maximum Concurrent Checkpoints: 当前时刻,Checkpoint的最大处理量。
Persist Checkpoints Externally: Enabled or Disabled. 如果设置为为enabled,还需要指明清除策略在程序被cancel后。具体见参数介绍。
Params Setting
上述便是一个Operator Checkpoint的过程。当然里面的流程有优化的环境。比如:该Operator可以不用等Checkpoint执行完毕,可优先发送barrier给到下游,来尽快完成整体Checkpoint流程。相信介绍完barrier aligning,也就能理解barrier not-aligning。
如下述所示计算流图(barrier not-aligning),红色代表barrier标识。
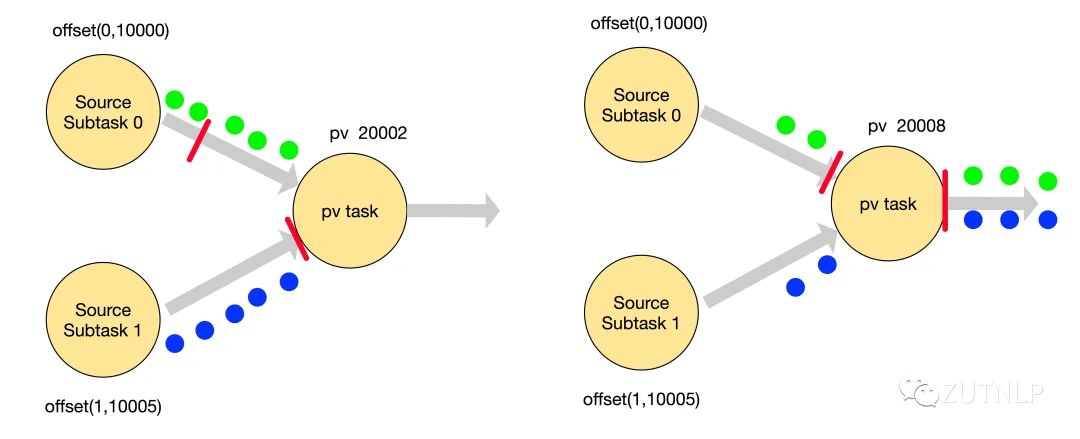
可以看到,Source-Subtask-1 的barrier优先到达pv-task,但是并没有把数据放到input buffer中,而是直接进行处理;等到Source-Subtask-0的barrier到达后,才触发Checkpoint。可以看到pv从20002变为20008。这就是barrier not-aligning。

StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();// 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】env.enableCheckpointing(1000);// 高级选项:// 设置模式为exactly-once (这是默认值)env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】env.getCheckpointConfig().setCheckpointTimeout(60000);// 同一时间只允许进行一个检查点env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);cancel处理选项:(1)ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint(2)ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
III. Backpressure的知识详解
网络传输组件介绍
可以知道如果上下游相关的operator如果在一个TaskManager中,即在一个JVM中,不涉及网络传输。接下来主要介绍跨多个TaskManager的网络传输流程。
| 术语/概念 | 解释 |
| ResultPartition | 生产者生产的数据首先写入到 ResultPartition 中,一个 Operator 实例对应一个ResultPartition |
| ResultSubpartition | 一个 ResultPartition 是由多个 ResultSubpartition 组成。当 Producer Operator 实例生产的数据要发送给下游 Consumer Operator n 个实例时,那么该 Producer Operator 实例对应的 ResultPartition 中就包含 n 个 ResultSubpartition |
| InputGate | 消费者消费的数据来自于 InputGate 中,一个 Operator 实例对应一个InputGate。网络中传输的数据会写入到 Task 的 InputGate。 |
| InputChannel | 一个 InputGate 是由多个 InputChannel 组成。当 Consumer Operator 实例读取的数据来自于上游 Producer Operator n 个实例时,那么该 Consumer Operator 实例对应的 InputGate 中就包含 n 个 InputChannel。 |
| RecordReader | 用于将记录从Buffer中读出 |
| RecordWriter | 用于将记录写入Buffer |
| LocalBufferPool | 为 ResultPartition 或 InputGate 分配内存,每一个 ResultPartition 或 InputGate分别对应一个 LocalBufferPool。 |
| NetworkBufferPool | 为 LocalBufferPool 分配内存,NetworkBufferPool 是 Task 之间共享的,每个 TaskManager 只会实例化一个。 |
基于上述概念知识,我们解释下下述数据传输流程:
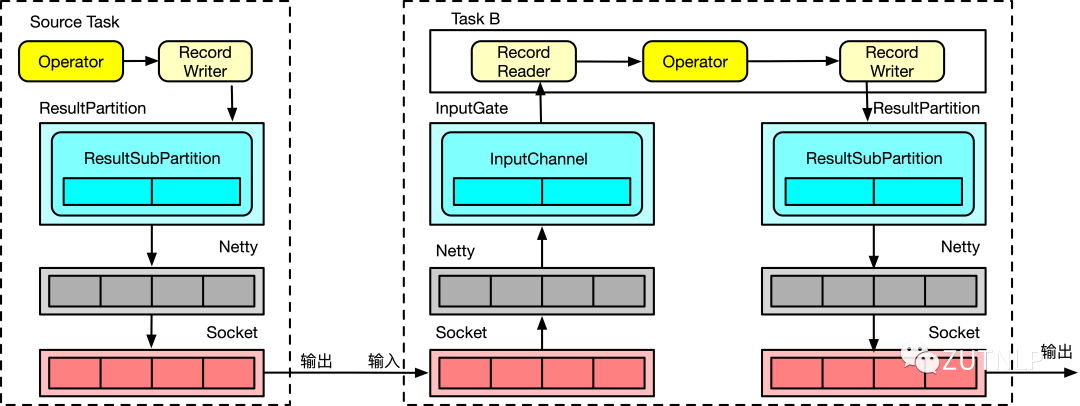
Source Task 给 Task B 发送数据,Source Task 做为 Producer,Task B 做为 Consumer,Producer 端产生的数据最后通过网络发送给 Consumer 端。
Producer 端 Operator 实例对一条条的数据进行处理,处理完的数据首先缓存到 ResultPartition 内的 ResultSubPartition 中。
ResultSubPartition 中一个 Buffer 写满或者超时后,就会触发将 ResultSubPartition 中的数据拷贝到 Producer 端 Netty 的 Buffer 中,之后又把数据拷贝到 Socket 的 Send Buffer 中,这里有一个从用户态拷贝到内核态的过程,最后通过 Socket 发送网络请求,把 Send Buffer 中的数据发送到 Consumer 端的 Receive Buffer。
数据到达 Consumer 端后,再依次从 Socket 的 Receive Buffer 拷贝到 Netty 的 Buffer,再拷贝到 Consumer Operator InputGate 内的 InputChannel 中,最后 Consumer Operator 就可以读到数据进行处理了。
InputGate 和 ResultPartition 的内存是如何申请的呢?如下图所示,了解一下 Flink 网络传输相关的内存管理。
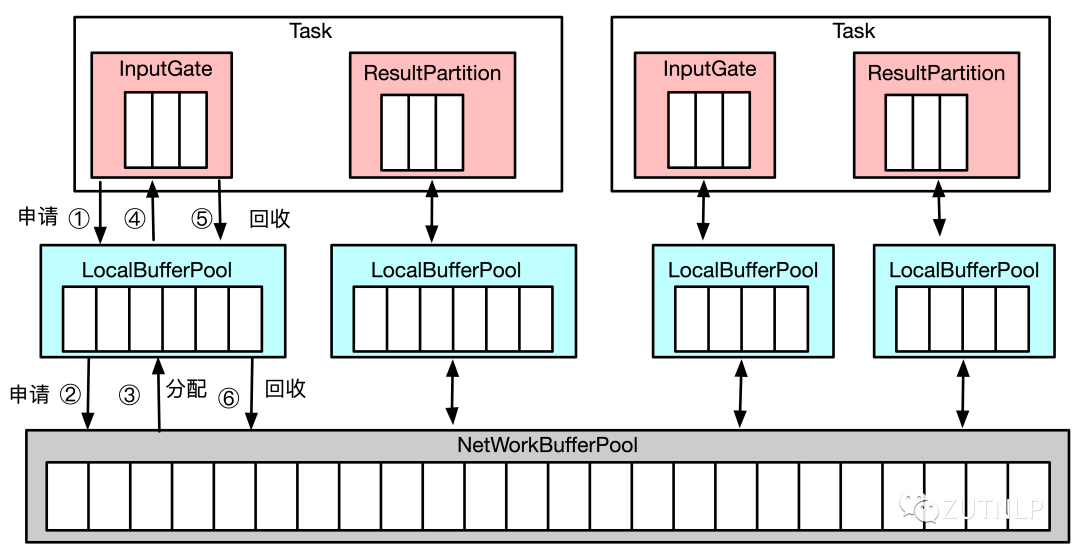
在 TaskManager 初始化时,Flink 会在 NetworkBufferPool 中生成一定数量的内存块 MemorySegment,内存块的总数量就代表了网络传输中所有可用的内存。
NetworkBufferPool 是 Task 之间共享的,每个 TaskManager 只会实例化一个。
Task 线程启动时,会为 Task 的 InputChannel 和 ResultSubPartition 分别创建一个 LocalBufferPool。InputGate 或 ResultPartition 需要写入数据时,会向相对应的 LocalBufferPool 申请内存(图中①),当 LocalBufferPool 没有足够的内存且还没到达 LocalBufferPool 设置的上限时,就会向 NetworkBufferPool 申请内存(图中②),并将内存分配给相应的 InputChannel 或 ResultSubPartition(图③④)。
虽然可以申请,但是必须明白内存申请肯定是有限制的,不可能无限制的申请,我们在启动任务时可以指定该任务最多可能申请多大的内存空间用于 NetworkBufferPool。
当 InputChannel 的内存块被 Operator 读取消费掉或 ResultSubPartition 的内存块已经被写入到了 Netty 中,那么 InputChannel 和 ResultSubPartition 中的内存块就可以还给 LocalBufferPool 了(图中⑤),如果 LocalBufferPool 中有较多空闲的内存块,就会还给 NetworkBufferPool (图中⑥)。
b. 基于Credit的反压机制
Flink 1.5 之前一个 Operator 实例对应一个InputGate,每个 InputGate 的多个 InputChannel 共用一个 LocalBufferPool。Flink 1.5 之后每个 Operator 实例的每个远程输入通道(Remote InputChannel)现在都有自己的一组独占缓冲区(Exclusive Buffer),而不是只有一个共享的 LocalBufferPool。与之前不同,LocalBufferPool 的缓冲区称为流动缓冲区(Floating buffers),每个 Operator 对应一个 Floating buffers,Floating buffers 内的 buffer 会在 InputChannel 间流动并且可用于每个 InputChannel。
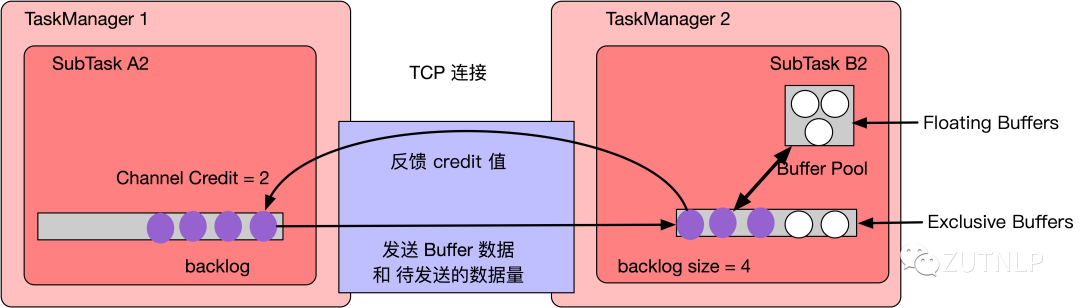
如上图所示,上游 SubTask A2 发送完数据后,还有 4 个 Buffer 被积压,会把要发送的 Buffer 数据和 Backlog size = 4 一块发送给下游 SubTask B2,下游接受到数据后,知道上游积压了 4 个Buffer 的数据,于是向 Buffer Pool 申请 Buffer,申请完成后由于容量有限,下游 InputChannel 目前仅有 2 个 Buffer 空间,所以,SubTask B2 会向上游 SubTask A2 反馈 Channel Credit = 2,上游就知道了下游目前最多只能承载 2 个 Buffer 的数据。所以下一次上游给下游发送数据时,最多只给下游发送 2 个 Buffer 的数据。当下游 SubTask 反压比较严重时,可能就会向上游反馈 Channel Credit = 0,此时上游就知道下游目前对应的 InputChannel 没有可用空间了,所以就不向下游发送数据了。
此时,上游还会定期向下游发送探测信号,检测下游返回的 Credit 是否大于 0,当下游返回的 Credit 大于 0 表示下游有可用的Buffer空间,上游就可以开始向下游发送数据了。
通过这种基于 Credit 的反馈策略,就可以保证每次上游发送的数据都是下游 InputChannel 可以承受的数据量,所以在公用的 TCP这一层就不会产生数据堆积而影响其他SubTask 通信。基于Credit的反压机制还带来了一个优势:由于我们在发送方和接收方之间缓存较少的数据,可能会更早地将反压反馈给上游,缓冲更多数据只是把数据缓冲在内存中,并没有提高处理性能。
c. BackPressure Monitor
java.lang.Object.wait(Native Method)o.a.f.[...].LocalBufferPool.requestBuffer(LocalBufferPool.java:163)o.a.f.[...].LocalBufferPool.requestBufferBlocking(LocalBufferPool.java:133) <--- BLOCKING request
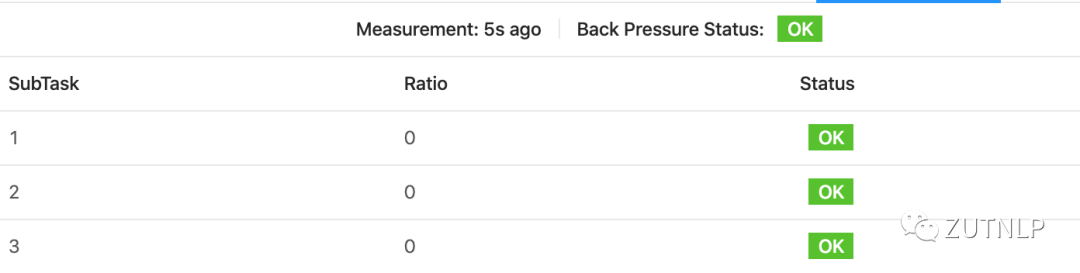
OK:0 <= 比例 <= 0.10
LOW:0.10 < 比例 <= 0.5
HIGH:0.5 < 比例 <= 1
当然你也可以使用Rest API来获取某个Operator的反压情况。
Format:/jobs/:jobid/vertices/:vertexid(Task-Id)/backpressureEg: http://bfd-wfj-67p121:8088/proxy/application_1582644888198_0190/jobs/a24f0c4879fc6ecb2efdae868f721d98/vertices/cbc357ccb763df2852fee8c4fc7d55f2/backpressureResponse如下:{"status": "ok","backpressure-level": "ok","end-timestamp": 1586617775024,"subtasks": [{"subtask": 0,"backpressure-level": "ok","ratio": 0.0},{"subtask": 1,"backpressure-level": "ok","ratio": 0.0},{"subtask": 2,"backpressure-level": "ok","ratio": 0.0}]}
下面我们借助mertics来进一步监控反压。下面是是一个有持续反压的Flink Job。
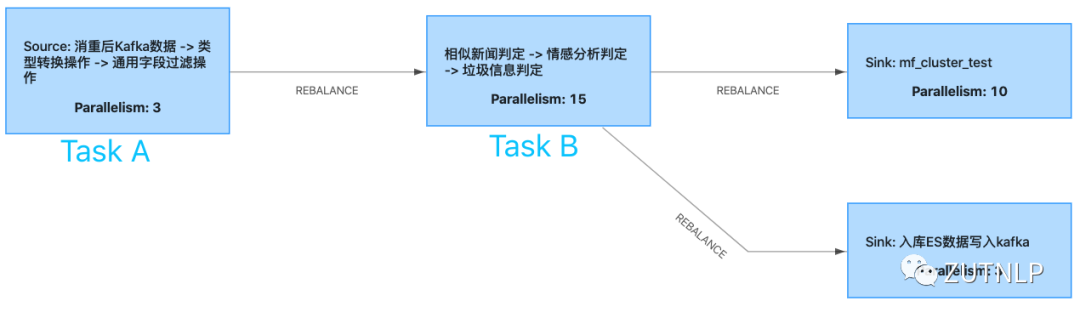
Job-BackPressured
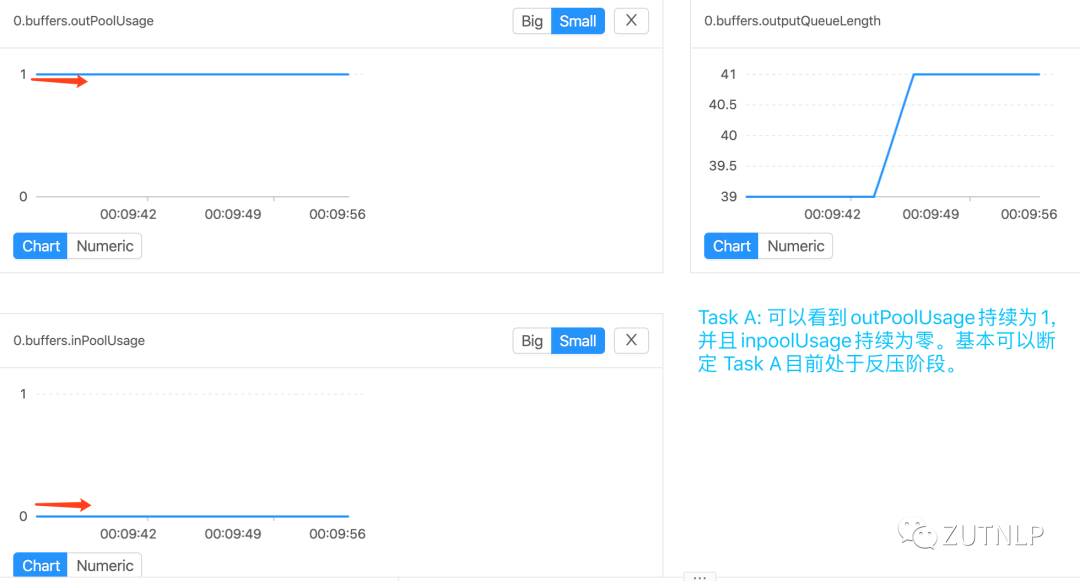
TaskA-Metrics
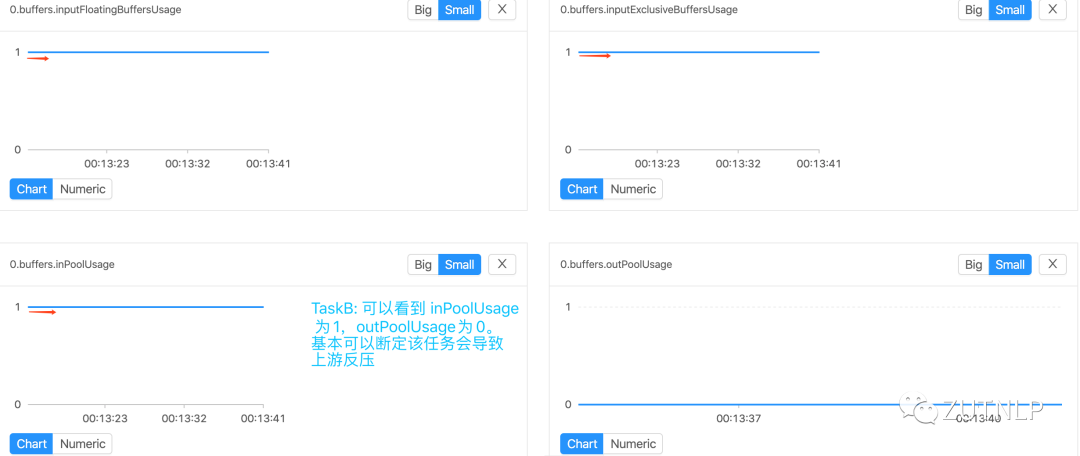
TaskB-Metrics
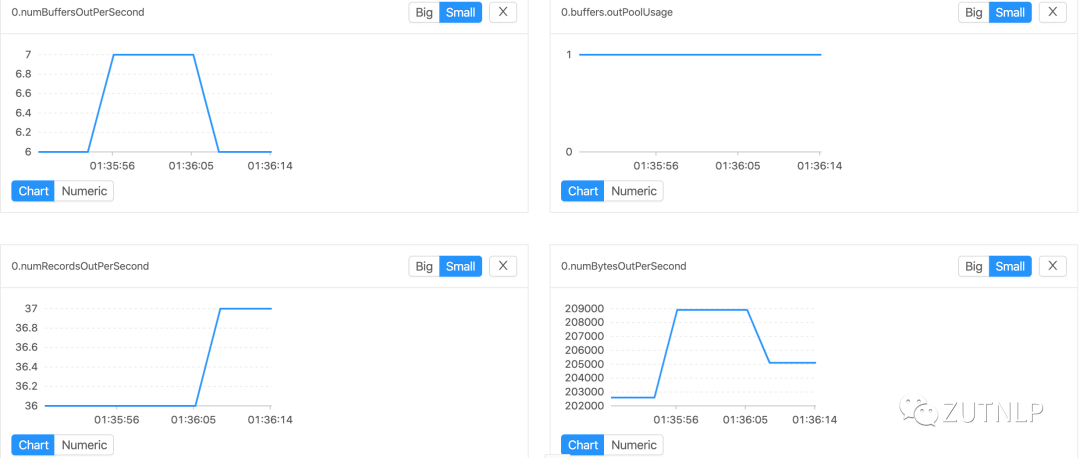
由上图Metrics分析可得出,由于TaskB处理性能受限导致TaskA反压。我们查看BackPressure UI:
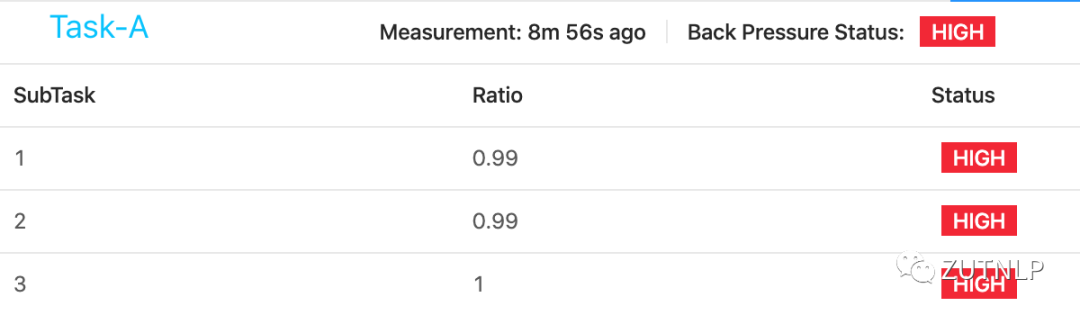
TaskA-BackPressured
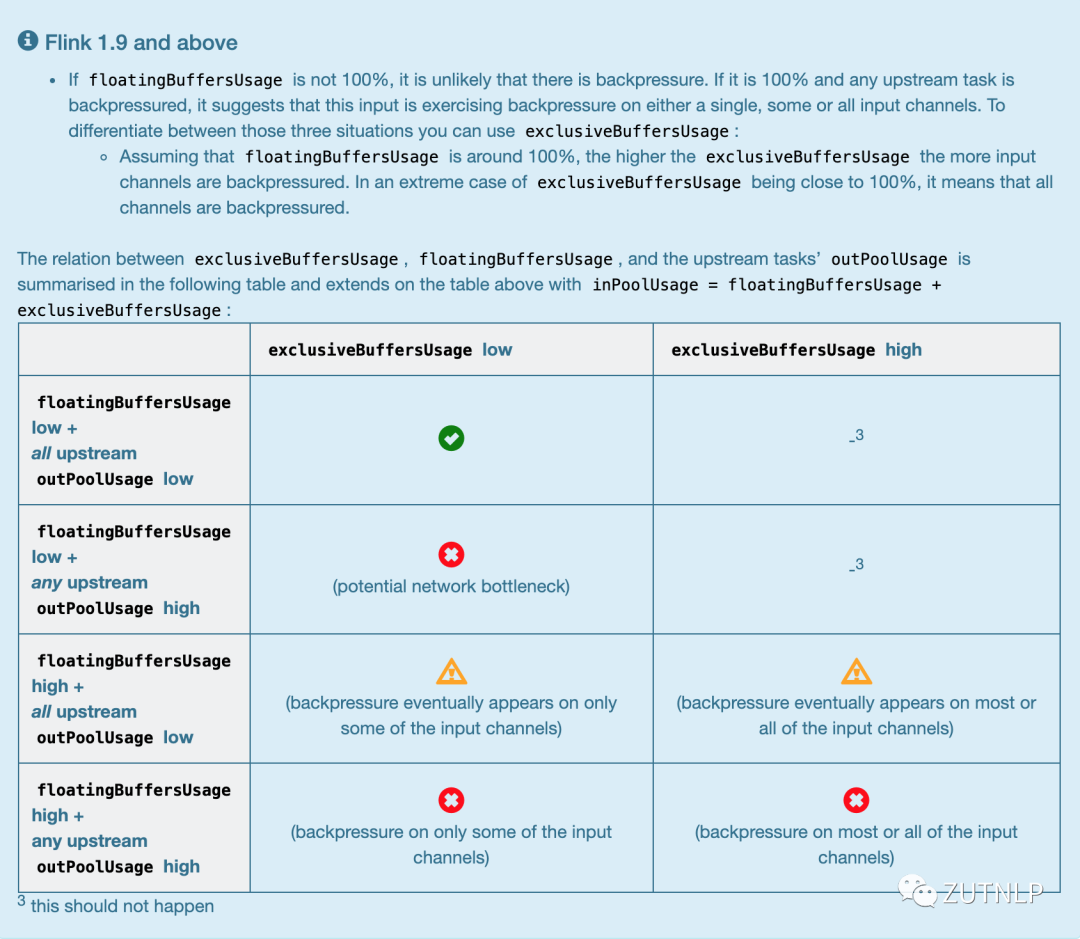
Flink 1.9 and above
相关参数解释如下:
| 参数 | 解释 |
| inputFloatingBuffersUsage | 每个 Operator 实例对应一个 FloatingBuffers,inputFloatingBuffersUsage 表示 Operator 对应的 FloatingBuffers 使用率 |
| inputExclusiveBuffersUsage | 每个 Operator 实例的每个远程输入通道(Remote InputChannel)都有自己的一组独占缓冲区(ExclusiveBuffer),inputExclusiveBuffersUsage 表示 ExclusiveBuffer 的使用 |
| inPoolUsage | Flink 1.5 - 1.8 中的 inPoolUsage 表示 inputFloatingBuffersUsage。Flink 1.9 及以上版本 inPoolUsage 表示 inputFloatingBuffersUsage 和 inputExclusiveBuffersUsage 的总和 |
由于Metrics只有 5 minutes时效性,一般都会将Metrics单独存储。主流的做法是 prometheus+grafana。这里我推荐下使用 InfluxDB + Chronograf进行信息收集和展示。
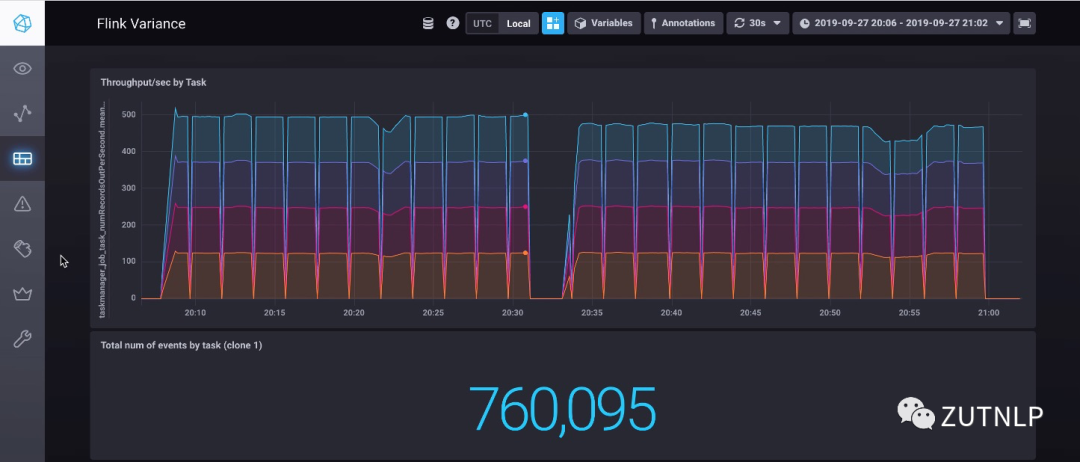
Chronograf示例
关于反压的知识就先介绍到这里,想了解更多,可以看下文末的引用部分。
IV. 实际案例讲解分析
 ,重点监控程序要着重对待。这是这件事故的一个大致背景,具体分析如下:
,重点监控程序要着重对待。这是这件事故的一个大致背景,具体分析如下:异常观测
反压监测
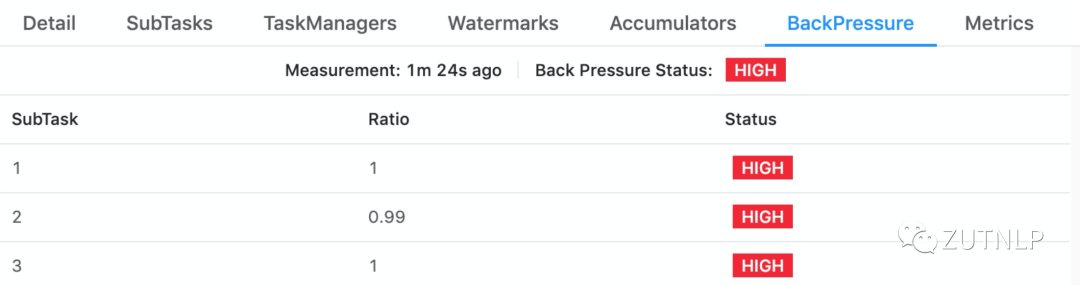
High BackPressure
说明该算子下游处理较慢,经过业务确认,下游算子的确属于耗时操作。
流量统计
经过流量统计,上游流量异常增大,并及时控制了流量输入。
checkpoint日志统计
这里截取部分checkpoint日志如下:
2020-04-09 08:11:59,813 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 48534 from task 9aa70b63cbeb6dd9e2f3559002e6706d of job 268d3f36d279f081fac6a21a98a6f94f at container_e06_1582644888198_0182_01_000003 @ bfd-wfj-67p121 (dataPort=13077).2020-04-09 08:12:01,259 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 48534 from task 18d35e92a4124e88231720160dc2c52f of job 268d3f36d279f081fac6a21a98a6f94f at container_e06_1582644888198_0182_01_000003 @ bfd-wfj-67p121 (dataPort=13077).2020-04-09 08:12:01,285 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 48534 from task 7e0971a4c056df8899d1ad5b1e428075 of job 268d3f36d279f081fac6a21a98a6f94f at container_e06_1582644888198_0182_01_000002 @ bfd-wfj-67p123 (dataPort=6277).2020-04-09 08:12:03,351 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 48534 from task c3802c332e99230a020c7ea9ce57ed6e of job 268d3f36d279f081fac6a21a98a6f94f at container_e06_1582644888198_0182_01_000003 @ bfd-wfj-67p121 (dataPort=13077).2020-04-09 08:12:04,383 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 48534 from task 831c8afaafa4b1c96e03ba1bd5ff8b36 of job 268d3f36d279f081fac6a21a98a6f94f at container_e06_1582644888198_0182_01_000002 @ bfd-wfj-67p123 (dataPort=6277).2020-04-09 08:12:05,089 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 48534 from task 7cc2c8f6250237bc8a5bc483df753f7b of job 268d3f36d279f081fac6a21a98a6f94f at container_e06_1582644888198_0182_01_000004 @ bfd-wfj-67p123 (dataPort=28322).2020-04-09 08:12:05,436 WARN org.apache.flink.runtime.checkpoint.CheckpointCoordinator - Received late message for now expired checkpoint attempt 48534 from task ca819f60686b7787b73ac5ed82bc775c of job 268d3f36d279f081fac6a21a98a6f94f at container_e06_1582644888198_0182_01_000002 @ bfd-wfj-67p123 (dataPort=6277).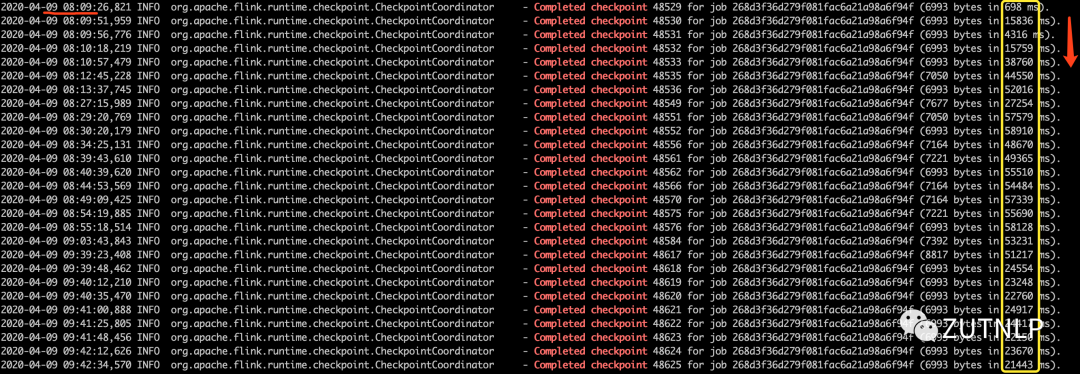
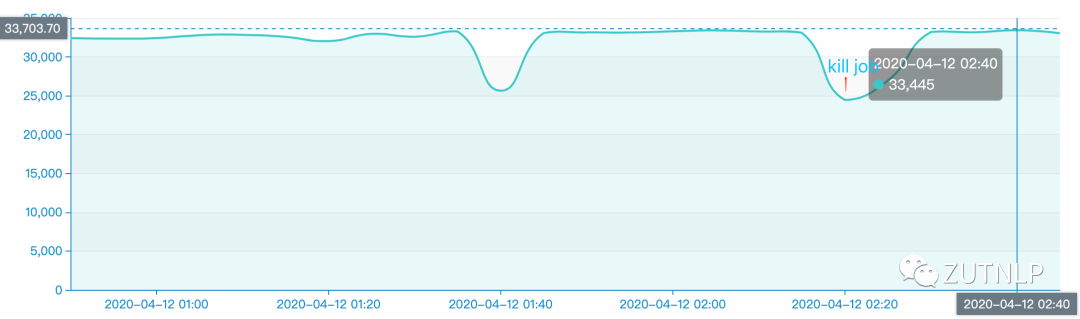
上述日志说明 checkpoint超时。注意开始时刻 08:11:59,checkpoint的时长是一直在几十秒,甚至接近1minutes。并且这种情况一直持续下去,直到我们Kill Job。随后紧急增加复杂算子的并行度,却依旧观察到如下图所示:

checkpoint超时
Kafka-Consumer日志
同时过滤日志发现如下:
2020-04-09 08:14:03,831 INFO org.apache.kafka.clients.FetchSessionHandler - [Consumer clientId=consumer-4, groupId=mf.streaming.nlp.v1] Error sending fetch request (sessionId=2051621507, epoch=2721109) to node 2: org.apache.kafka.common.errors.DisconnectException.2020-04-09 08:14:05,243 INFO org.apache.kafka.clients.FetchSessionHandler - [Consumer clientId=consumer-3, groupId=mf.streaming.nlp.v1] Error sending fetch request (sessionId=897133184, epoch=2698016) to node 1: org.apache.kafka.common.errors.DisconnectException.2020-04-09 08:16:03,413 INFO org.apache.kafka.clients.FetchSessionHandler - [Consumer clientId=consumer-4, groupId=mf.streaming.nlp.v1] Error sending fetch request (sessionId=706279173, epoch=4) to node 2: org.apache.kafka.common.errors.DisconnectException.2020-04-09 08:16:21,487 INFO org.apache.kafka.clients.FetchSessionHandler - [Consumer clientId=consumer-3, groupId=mf.streaming.nlp.v1] Error sending fetch request (sessionId=306063984, epoch=5) to node 1: org.apache.kafka.common.errors.DisconnectException.2020-04-09 08:17:04,623 INFO org.apache.kafka.clients.FetchSessionHandler - [Consumer clientId=consumer-4, groupId=mf.streaming.nlp.v1] Error sending fetch request (sessionId=1493541258, epoch=1) to node 2: org.apache.kafka.common.errors.DisconnectException.DisconnectException一般表现在Client和Server端未及时通信导致。可以看到发生时刻从08:14:03开始,持续到Job Killed。
Flink 监控
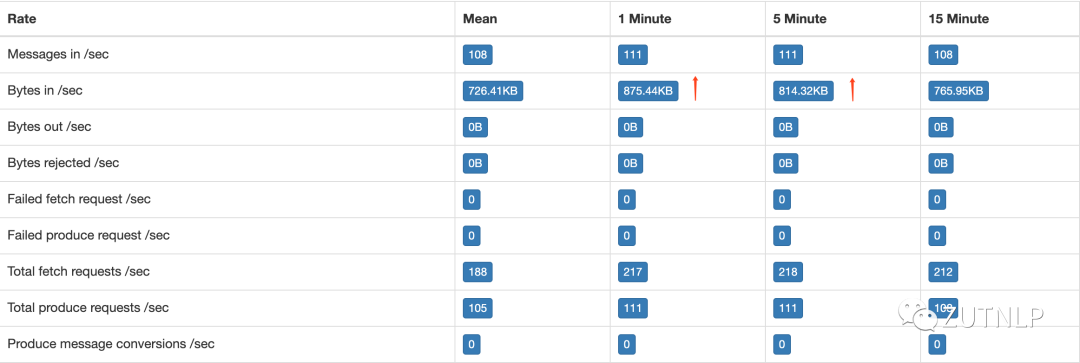
从下图可以看出,在08:00后,各个指标变化比较迅速。
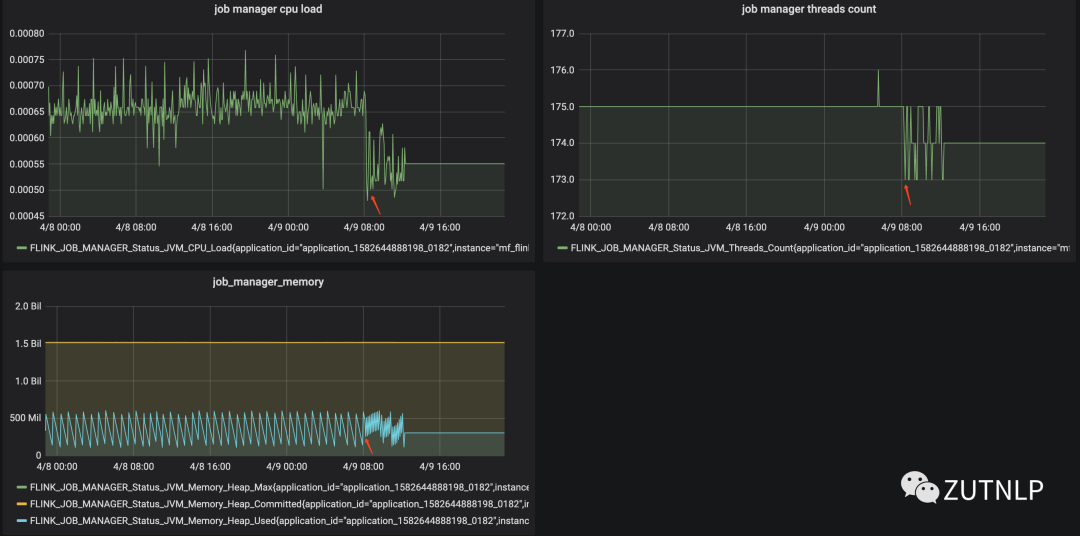
Flink Monitor
消费延迟时刻分析
分析和总结
从上述监控和日志信息来看,Job整体表现较为平稳。我们重点解释下如下现象:
barrier对齐-EXACTLY_ONCE
barrier不对齐-AT_LEAST_ONCE
 Checkpoint Config
Checkpoint Config Checkpoint Summary
Checkpoint Summary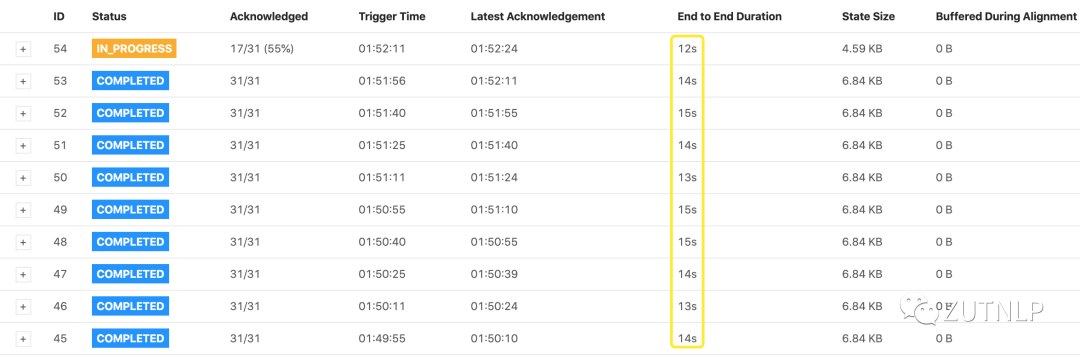 Checkpoint History
Checkpoint History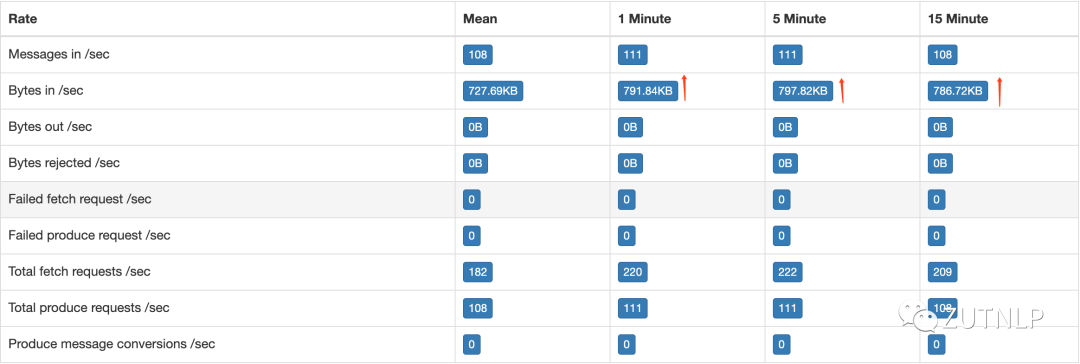
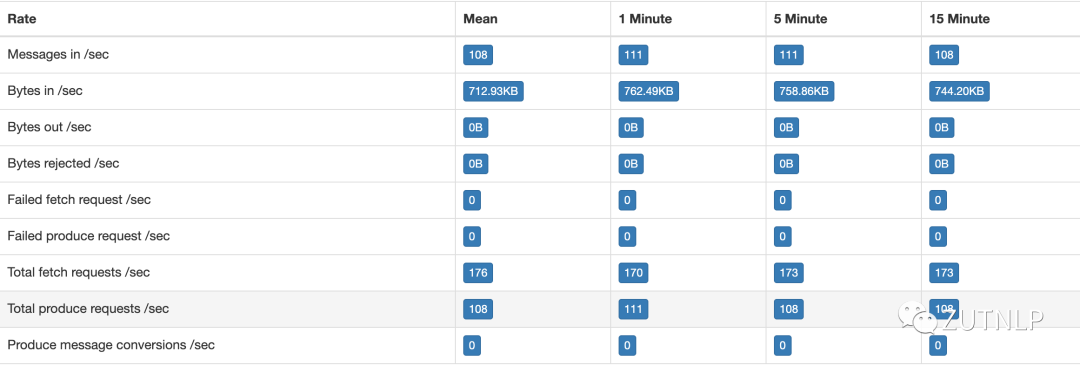
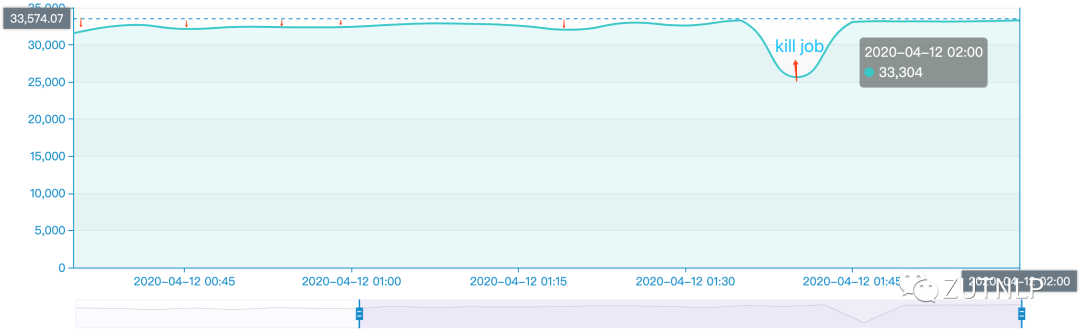 Kafka Sink 吞吐量
Kafka Sink 吞吐量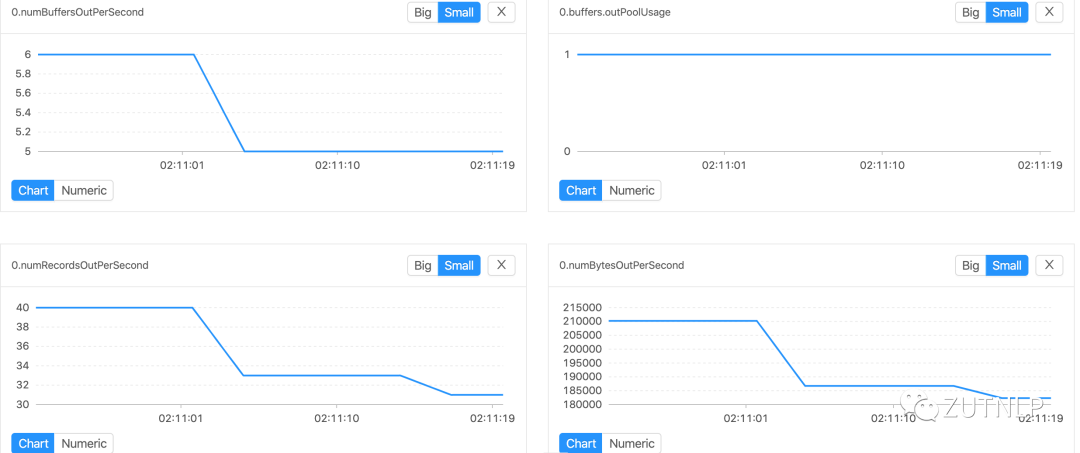 BackPressure Operator Metric
BackPressure Operator Metric取消Checkpoint

Checkpoint Config
 Kafka Sink 吞吐量
Kafka Sink 吞吐量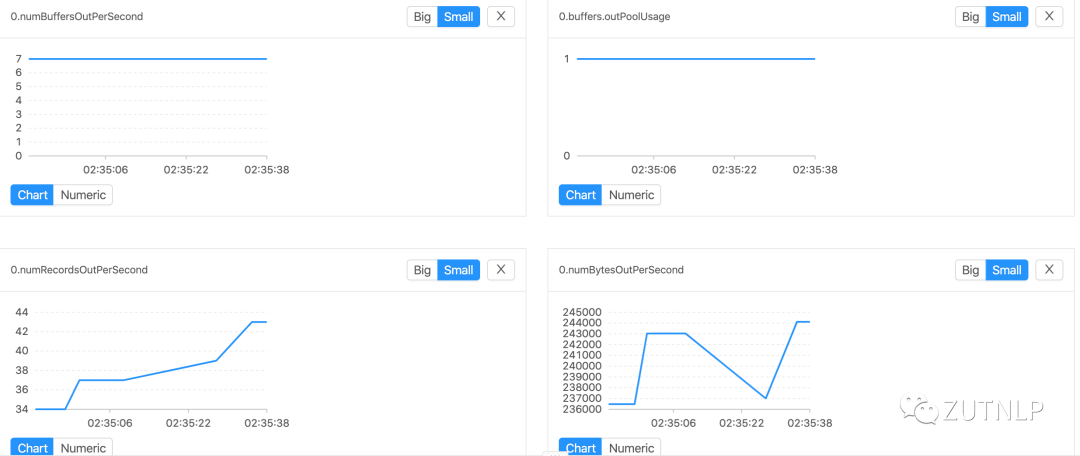 BackPressure Operator Metric
BackPressure Operator Metric在上述A、B、C实验中基本可以得出,Flink Job的吞吐量是递增的,但增幅并不大。从barrier对齐角度来看,在AT-LEAST-ONCE语义下,Checkpoint的时长会更加久些。但是在A\B组实验中都没有出现checkpoint超时的现象。需要增加在流量异常激增情况下的一组实验,来判定是否可以模拟当时的现象。那么我们先从源码角度看下,是如何判定超时以及超时后的处理:
boolean wasPendingCheckpoint;if (this.recentPendingCheckpoints.contains(checkpointId)) {wasPendingCheckpoint = true;LOG.warn("Received late message for now expired checkpoint attempt {} from task {} of job {} at {}.",new Object[]{checkpointId, message.getTaskExecutionId(), message.getJob(), taskManagerLocationInfo});} else {LOG.debug("Received message for an unknown checkpoint {} from task {} of job {} at {}.", newObject[]{checkpointId, message.getTaskExecutionId(), message.getJob(), taskManagerLocationInfo});wasPendingCheckpoint = false;}this.discardSubtaskState(message.getJob(), message.getTaskExecutionId(), message.getCheckpointId(),message.getSubtaskState());return wasPendingCheckpoint;可以看到这是receiveAcknowledgeMessage函数中处理超时checkpoint的code。首先判定是属于PendingCheckpoint队列,随后就执行discard-丢弃本次任务状态操作。
由于目前还没有一个完善的Topic offset和Consumer offset的一个实时对比图,所以无法确定消费延迟是在某时刻进行发生的。但是通过checkpoint和kafka消费信息日志显示,似乎都指向08:10这一时刻。我们借助数据的采集时间和入库时间进行对比分析发现:08:00时刻(08:00~09:00区间段)就已经出现消费延迟。
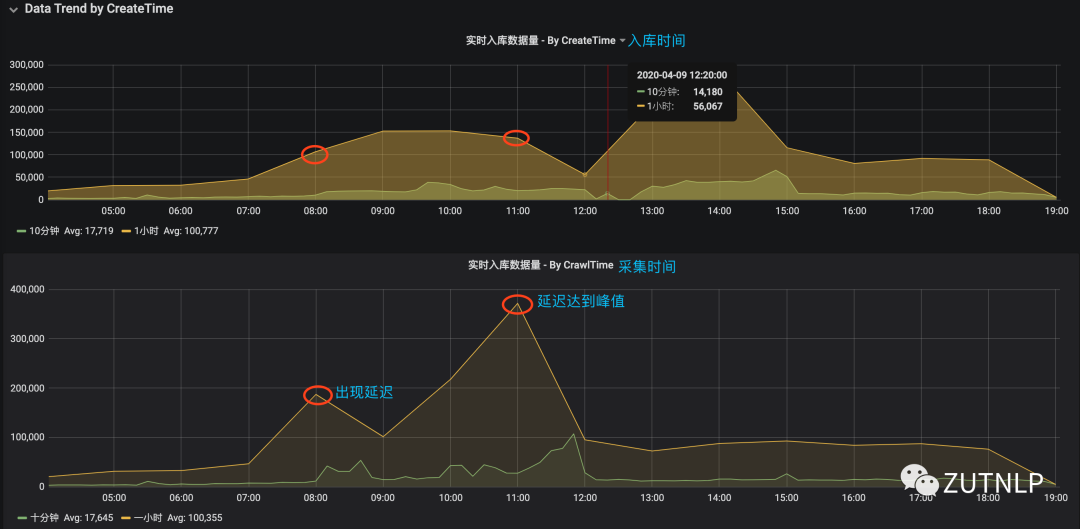
小时聚合
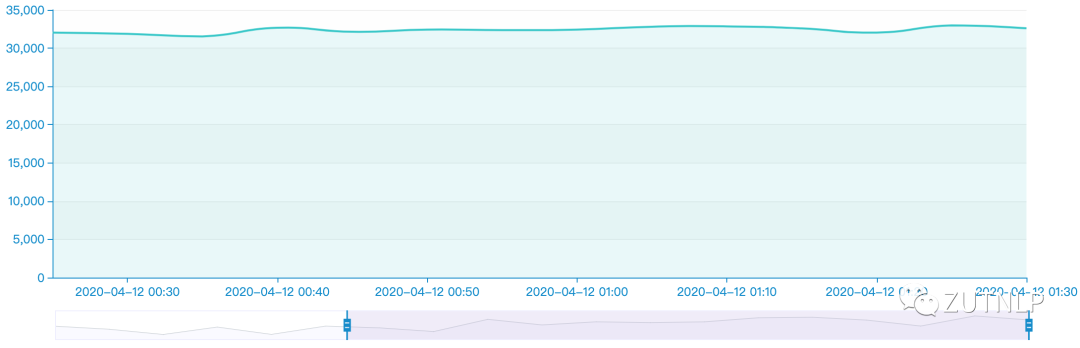
离线统计 07:00 ~ 12:20时间区间,总数据量差额约:34W。这与在Kafka Manager 中查看到的延迟基本吻合。该时间区间内上游推送数据量达95W,消费60W。
下图看下10分钟聚合的效果图:
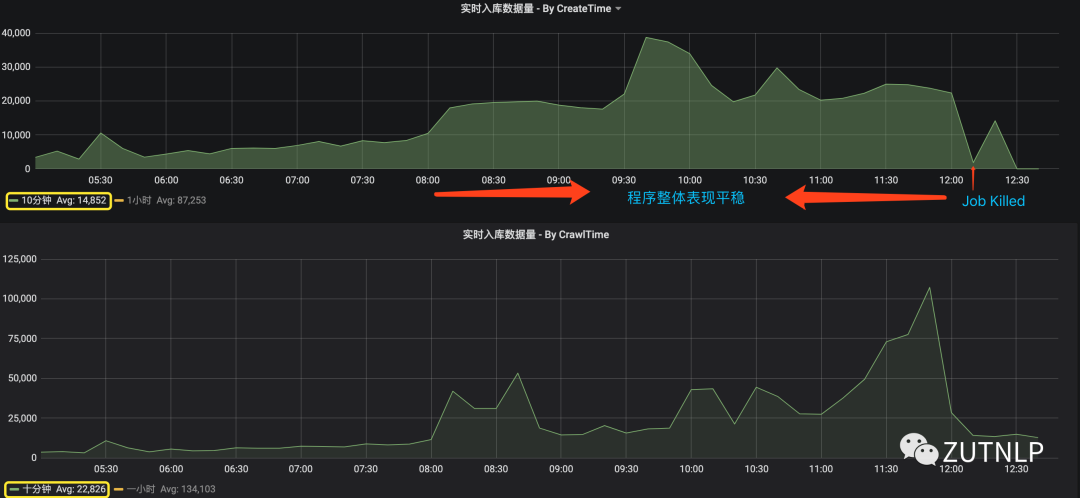
10min聚合
从上图还可得到信息:Flink Job的消费能力先增大,再趋于平稳,应该是反压机制起到作用。
I.Expired Checkpoint

Checkpoint Config

Checkpoint Summary
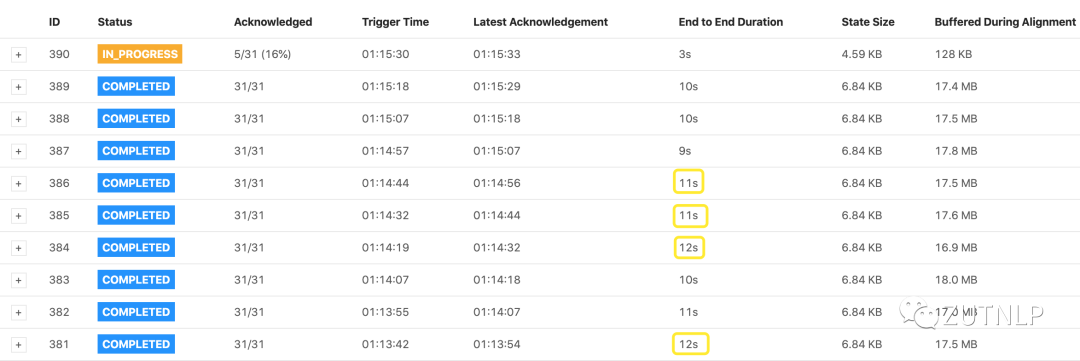
Checkpoint History
Kafka Sink 吞吐量
BackPressure Operator Metric
II. Kafka DisconnectException
这种现象应该属于Consumer 拉取消息失败报错,引起的原因可能有:
网络问题
拉取消息超时
代码如下:更侧重于网络问题引起的。
/*** Handle an error sending the prepared request.** When a network error occurs, we close any existing fetch session on our next request,* and try to create a new session.** @param t The exception.*/public void handleError(Throwable t) {log.info("Error sending fetch request {} to node {}: {}.", nextMetadata, node, t.toString());nextMetadata = nextMetadata.nextCloseExisting();}
在08:00~12:00的4个小时内,总共出现224条日志信息。在上述压测过程中也未发生该现象。
Refer:
https://juejin.im/post/5bf93517f265da611510760d#heading-19
https://flink.apache.org/2019/07/23/flink-network-stack-2.html
https://mp.weixin.qq.com/s/ywpmYUCJRPimkwiWQbL-1w
https://owenrh.me.uk/blog/2019/10/03/
https://www.influxdata.com
