




今天分享的文章:
Interleaving Retrieval with Chain-of-Thought Reasoning for Knowledge-Intensive Multi-Step Questions
用于COT多步骤推理问题的交叉检索方法

摘要
方法
检索器组件:能够根据查询从语料库中返回一定数量的段落。 LLM组件:具备零样本或少样本的“思维链”(CoT)生成能力。 标注数据集:包含少量带注释的问题,其中有解释如何以自然语言(思路链)得出答案的推理步骤,以及一组来自语料库的段落,共同支持推理链和答案。
初始检索:首先,通过将问题 (Q) 作为查询,使用基础检索器从知识源中检索出 (K) 个初始段落。 交替进行推理和检索: 推理步骤(Reason):在这个步骤中,模型利用当前问题、已检索到的段落以及之前生成的思维链(CoT)句子,生成下一个 CoT 句子。 检索步骤(Retrieve):根据新生成的 CoT 句子更新检索过程,以获取更多相关段落。 这一过程持续交替进行,直到满足终止条件。
Wikipedia Title: <Page Title>
<Paragraph Text>
...
Wikipedia Title: <Page Title>
<Paragraph Text>
Q: <Question>
A: <CoT-Sent-1> ... <CoT-Sent-n>
结合下面这个例子来理解一下IRCoT的工作流程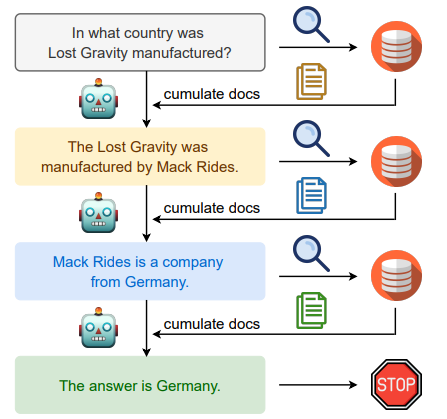
首先将该问题检索得到关于Lost Gravity的一些信息。
LLM能够从该信息中抓取到Lost Gravity的制作公司为 Mack Rides。
接着搜索 “The Lost Gradvity was manufactured by Mack Rides”, 我们会得到一些关于 Mack Rides 的信息。
基于该信息我们能够得到 (通过 LLM 抓取) “Mack Rides” 是一家德国公司的信息。
最终我们能够得到答案为: Germany。
总结
优点
提升多步推理能力:通过利用CoT提示技术,IRCoT显著提升了大语言模型在多步推理任务上的表现。
改善检索与问答性能:在四个数据集上,IRCoT相较于一次性的检索方法,在检索和问答性能方面都有显著提升,适用于大规模和相对较小规模的语言模型。
减少事实错误:由IRCoT生成的CoT含有较少的事实错误。
局限性
依赖基础模型的CoT生成能力:IRCoT要求基础语言模型具备零样本或少量样本的CoT生成能力,这对于超过100亿参数的大模型较为常见,但对于小于20亿参数的小模型则不那么普遍。
长输入支持:IRCoT需要基础模型能够处理长输入,因为多次检索的段落需要一起作为输入。目前使用的模型如code-davinci-002(GPT3)和Flan-T5系列能够支持这一需求。
未来工作
优化输入长度:未来的研究可以探索重新排序和选择检索段落的方法,而不是将所有段落都传递给语言模型,从而减轻模型处理长输入的需求。
降低计算成本:IRCoT的性能提升伴随着额外的计算成本,因为每生成一个CoT句子都需要单独调用一次语言模型。未来可以研究动态决定何时检索更多信息以及何时使用现有信息进行额外推理的策略。
