




简介
NebulaGraph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载包含数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
图数据库在许多业务场景中扮演着重要角色,得益于其独特的数据模型和高效的查询性能。以下是一些常见的图数据库业务应用场景:
知识图谱:企业和组织需要从各种数据孤岛中构建领域知识图谱,支持智能问答和语义搜索。 社交网络分析:社交网络平台需要分析用户之间的关系、兴趣、互动等信息,以提供个性化推荐、广告定向投放。 金融风控:金融机构需要监测异常交易活动、识别潜在的欺诈行为、评估信用风险。 推荐系统:电子商务、媒体平台需要根据用户的浏览历史、购买记录等信息,提供个性化的商品或内容推荐。
NebulaGraph Cloud 是为 NebulaGraph 设计的全托管云服务,本文将结合亚马逊云科技的产品,详细介绍如何实现降本增效。

平台架构和组件
平台架构
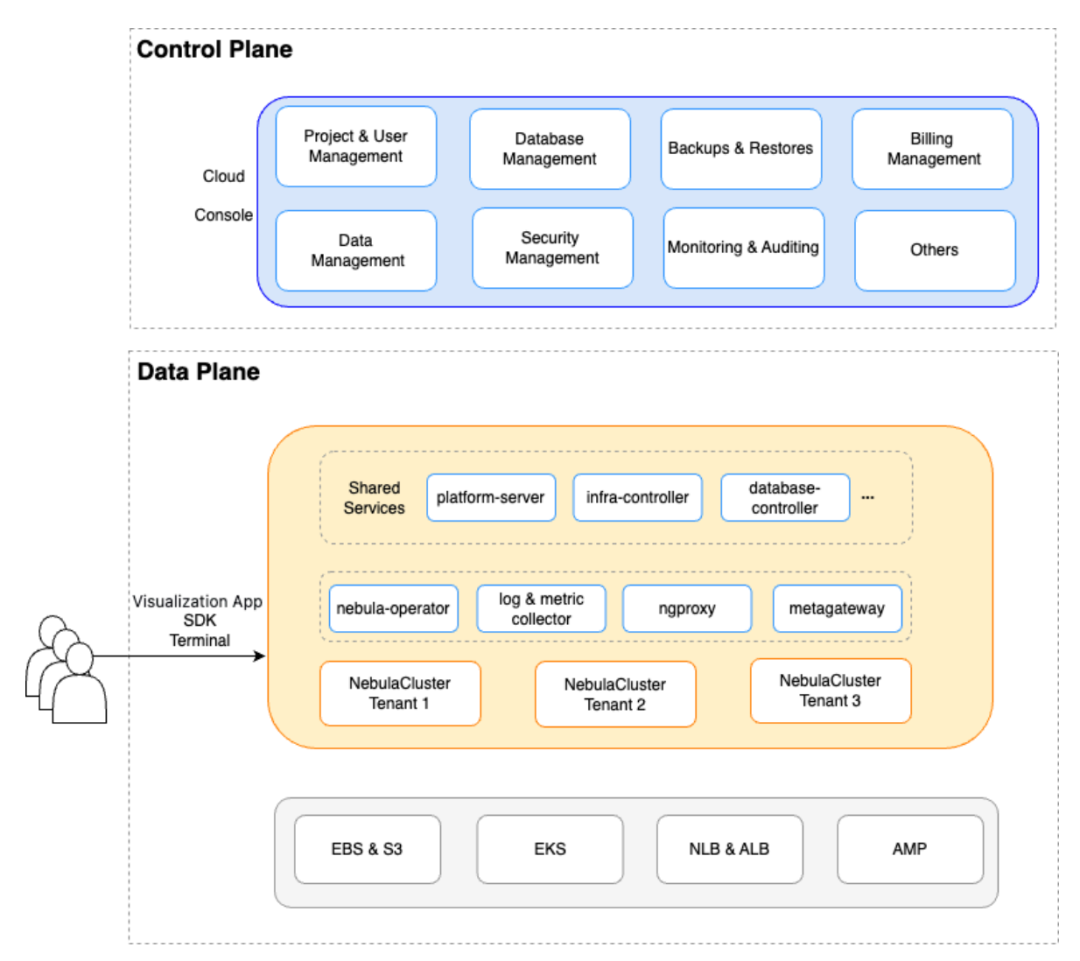
NebulaGraph Cloud 基于 K8S 设计和构建 ,背后有以下因素:
K8S 的 Opertor 模式使得集群内部发生的一切可以被自动化,降低开发成本。 K8S 提供了一系列抽象能力,用于简化计算、存储和网络资源的管理,可以帮助用户避险厂商锁定,做到 100% Cloud agnostic。 K8S 内置的扩缩容、调度框架、资源监控、服务发现等能力,可以将各种管理操作变的更容易。
服务组件
NebulaGraph Cloud 由两部分构成:
提供用户控制台访问,包括组织管理、用户权限控制、数据库管理、网络安全设置、监控、告警等功能,帮助用户管理他们的 NebulaGraph 集群。
接收控制平面下发的指令,包括资源调度、配置、版本更新、水平扩缩容、规格调整、备份和恢复、可观测性、计量等功能。
成本优化设计
以数据库的配置示例来说明:
apiVersion: apps.nebula-cloud.io/v1alpha1kind: Databasemetadata:name: db123456namespace: db123456spec:provider: awsregion: "us-east-2"k8sRef:name: "k8s-ml65nmjg"namespace: "k8s-ml65nmjg"tier: standardgraphInstanceType: NG.C4.M32.D0graphNodes: 1StorageInstanceType: NG.C4.M32.D50StorageNodes: 1version: v3.8.2c
左右滑动查看完整示意
数据库实例使用 CRD Database 定义,它在数据平面的管理操作由控制器 database-controller 负责。
对于依赖的计算资源通过 CRD NodePool 定义,NodePool 是对各个云厂商计算资源的抽象,在 Amazon EKS 中用于管理 NodeGroup。
前文提到 NebulaGraph 是计算-存储分离的架构,所以一个数据库实例会对应两个 NodePool 对象。
# Graph 资源池apiVersion: apps.nebula-cloud.io/v1alpha1kind: NodePoolmetadata:name: gnp-7d0b156enamespace: db123456spec:databaseRef:name: db123456namespace: db123456instanceCount: 1instanceType: xk8sRef:name: k8s-ml65nmjgnamespace: k8s-ml65nmjglabels:platform.nebula-cloud.io/database-name: db123456platform.nebula-cloud.io/graph-pool: db123456-f24aprovider: awsregion: us-east-2zoneIndex: 0# Storage 资源池apiVersion: apps.nebula-cloud.io/v1alpha1kind: NodePoolmetadata:name: snp-59e9cc63namespace: db123456spec:databaseRef:name: db123456namespace: db123456instanceCount: 1instanceType: xk8sRef:name: k8s-ml65nmjgnamespace: k8s-ml65nmjglabels:platform.nebula-cloud.io/database-name: db123456platform.nebula-cloud.io/Storage-pool: db123456-un6gprovider: awsregion: us-east-2zoneIndex: 0
左右滑动查看完整示意
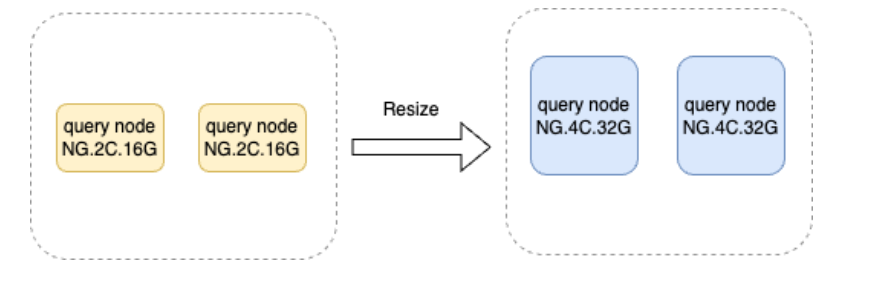
规格调整
选择合适的实例规格对用户和服务商都是一个比预期更具挑战性的任务。用户通常不清楚他们需要多大的实例,例如,当用户的数据从100 GB 逐渐增长到 1 TB 时,他们可能不清楚这些数据在每个阶段需要多少 CPU 核心或多大内存。这就需要用户和 SA 共同努力来找出答案。
在使用全托管云服务时,我们提供实例规格调整功能,支持对 Query 节点或者 Storage 节点单独调整,以满足用户在成本控制和性能达标方面的需求。用户可以根据监控面板的历史曲线判断是否达到单节点处理瓶颈,同时云平台也会发出站内告警。
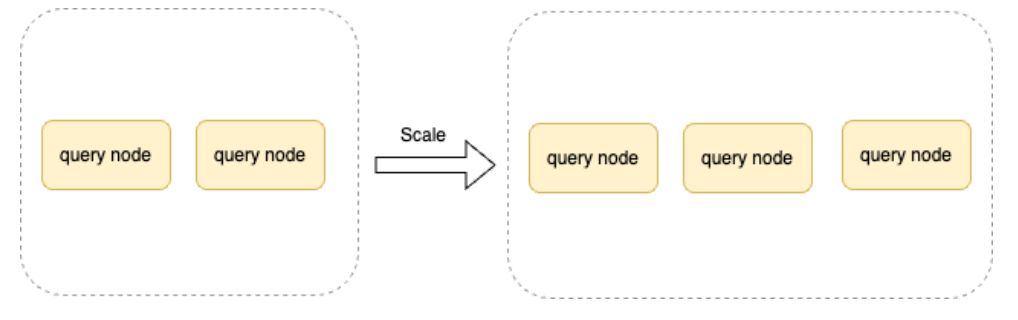
水平扩缩容
水平扩缩容支持对 Query 节点或者 Storage 节点单独调整。Query 节点可视为无状态服务,在处理查询流量波动时可通过扩缩容来解决。
Storage 节点负责存储图数据并提供读写能力,每个 Storage 节点上都分布一定数量的数据分片。每次进行扩缩容都会涉及数据迁移及数据分片再均衡,因此需要谨慎操作。
节点扩容前需要准备相应的计算资源,控制器 database-controller 会将当前期望的节点数下发给 infra-controller 触发 Amazon EKS 的 NodeGroup 扩容,这里我们没有启用 CA 或者 Karpenter 有以下原因:
扩缩容决策依赖于特定的集群条件和资源请求,如果这些条件没有得到满足,它可能不会执行预期的扩缩容操作。 跨可用区场景下无法保证指定区域的扩缩容。 基于 Pending Pod 的模式跟我们的业务系统无法紧密集成。
自动弹性伸缩
通过自动扩容/缩容支持不同的工作负载是我们的一个重要目标。由于计算和存储是分离的,我们可以根据每个服务节点的利用率来增加或减少 CPU 和内存资源。
弹性伸缩服务架构如下:
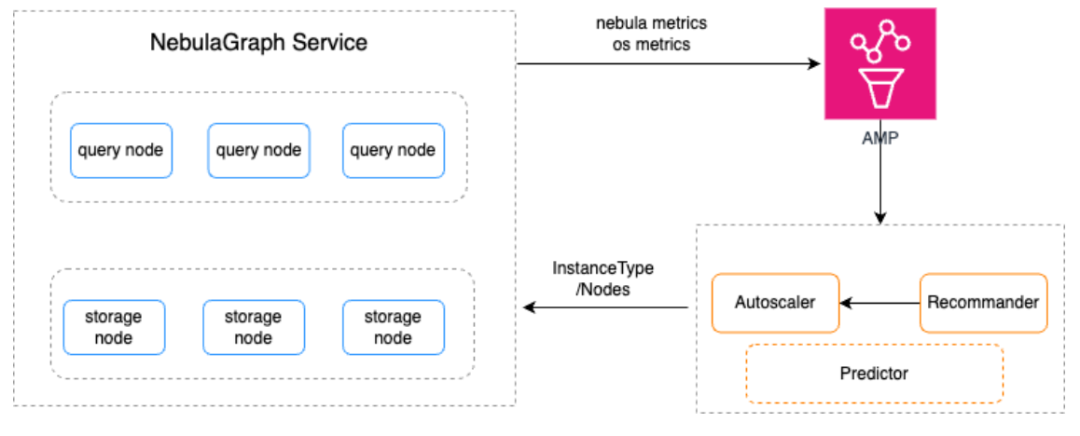
每隔 10 分钟,弹性伸缩服务就会根据监控数据的历史和当前值计算数据库实例应分配的资源量,最终确定是否应增加或缩减计算资源。
它可以驱动水平扩缩容和垂直扩缩容(调整实例规格),确保业务高峰时能提前弹出来。我们在此基础上将继续不断改进,通过纳入更多指标和主动预测策略来缩短扩缩容的时间。
效率提升设计
网络安全访问
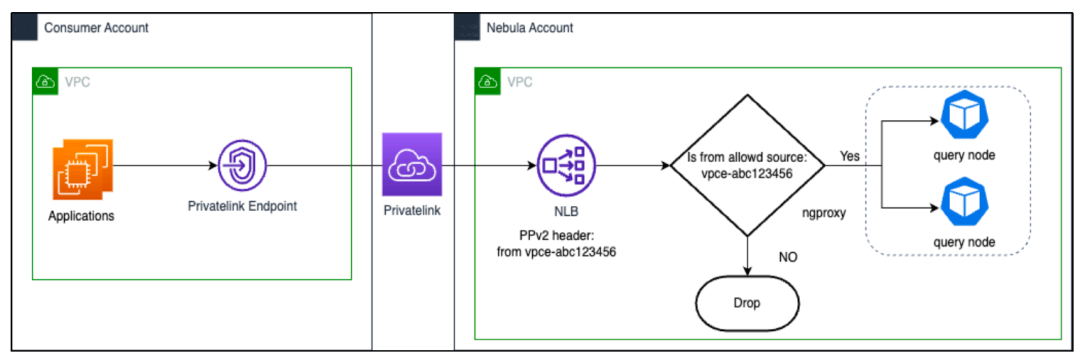
目前我们为用户提供两种网络连接方式:网络白名单和 Privatelink 私网连接。
为了确保网络安全并简化配置步骤,我们在数据库实例与网络负载均衡(NLB)之间引入了代理服务 ngproxy,充分利用了 NLB 提供的功能。NLB 支持在通过的每个报文上设置 PPv2 header,ngproxy通过解析报文可以知晓用户端的 endpoint ID 与在控制台设置的 ID 是否一致,不匹配则会拒绝请求。同样的原理也适用于公网访问的白名单,只有当源地址与白名单中的地址匹配时,才会被允许通过。
备份和恢复
数据备份是防止数据丢失的第一道防线。无论是因为硬件故障、软件错误、数据损坏还是人为操作失误,备份都可以确保数据的安全。
我们为用户提供手动备份和定时备份两种方式,将备份数据上传到亚马逊云科技的对象存储Amazon S3。我们没有采用基于云存储快照的备份恢复方案,因为基于 SST 的备份恢复速度比云存储快照更快,而且不需要依赖云厂商的基础服务。需要注意的是,在进行数据备份时 DDL 和 DML 语句将会被阻塞,因此建议在业务低峰期执行备份操作。
备份数据目录结构:
backup_root_url/- BACKUP_2024_08_20_16_31_43├── BACKUP_2024_08_20_16_31_43.meta├── data│ └── 10.0.0.12:9779│ └── data0│ └── 5│ ├── data│ │ ├── 000009.sst│ │ ├── 000011.sst│ │ ├── 000013.sst│ │ ├── CURRENT│ │ ├── MANIFEST-000004│ │ └── OPTIONS-000007│ └── wal│ ├── 1│ │ ├── 0000000000000000001.wal│ │ └── 0000000000000000005.wal.....│ ├── 30│ │ ├── 0000000000000000001.wal│ │ ├── 0000000000000000004.wal│ │ └── 0000000000000000005.wal└── meta├── __disk_parts__.sst├── __edges__.sst├── __id__.sst├── __indexes__.sst├── __index__.sst├── __last_update_time__.sst├── __local_id__.sst├── __parts__.sst├── __roles__.sst├── __spaces__.sst└── __tags__.sst- BACKUP_2024_08_20_19_02_35
左右滑动查看完整示意
恢复数据时采用恢复至新实例的方案,这样可以充分利用云上资源弹性扩展的优势,在指定某个时间点的备份集后快速拉起一个新的数据库实例,用户在验证新的数据库实例工作正常后可以释放掉旧实例。
高可用性
针对那些对服务可靠性要求极高的用户,我们提供了跨可用区容灾解决方案。
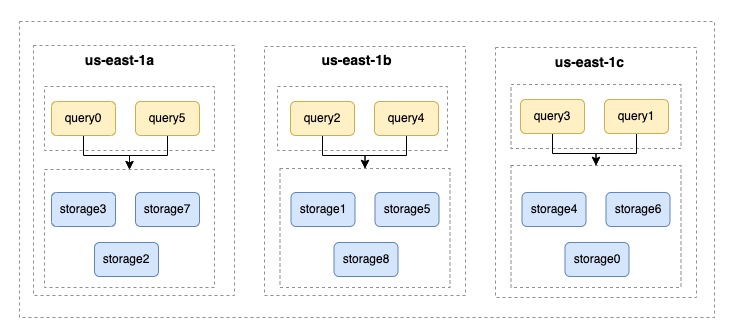
在 NebulaGraph 中 Zone 是服务节点的集合,它将多个 Storage 节点划分成可管理的逻辑区域,实现资源隔离。同时,平台服务会控制 Query 节点访问指定的 Zone 内的副本数据,从而降低跨可用区通信产生的网络延时与流量成本。
管理有状态服务跨可用区的一个主要挑战是存储卷的区域亲和性问题。为了解决这个问题,我们采取了在每个可用区放置一个 NodeGroup 的方法。这样一来,就可以避免新扩容的 Node 可能被错误地安排在不正确的可用区中,从而导致 Pod 无法被调度的情况发生。
根据过往用户案例中的经验,我们还支持在某个可用区单独扩容的方案。云原生社区类似 HPA 的方案,只解决了扩容后的数量问题,但是无法扩容到指定区域。根据每个区域承载的业务流量进行扩展,可以有效地提高服务质量。如果某个区域观察到 QPS 突然激增,数据平面的弹性伸缩服务将允许在此区域缩放 Query 节点。
云上实战
在开通订阅后开始创建数据库,接下来演示访问数据库的几种方式:
可视化工具
从 Database 列表选中某个实例,进入 Data->Graph 图空间管理,点击 Explorer Graph 进入可视化应用。
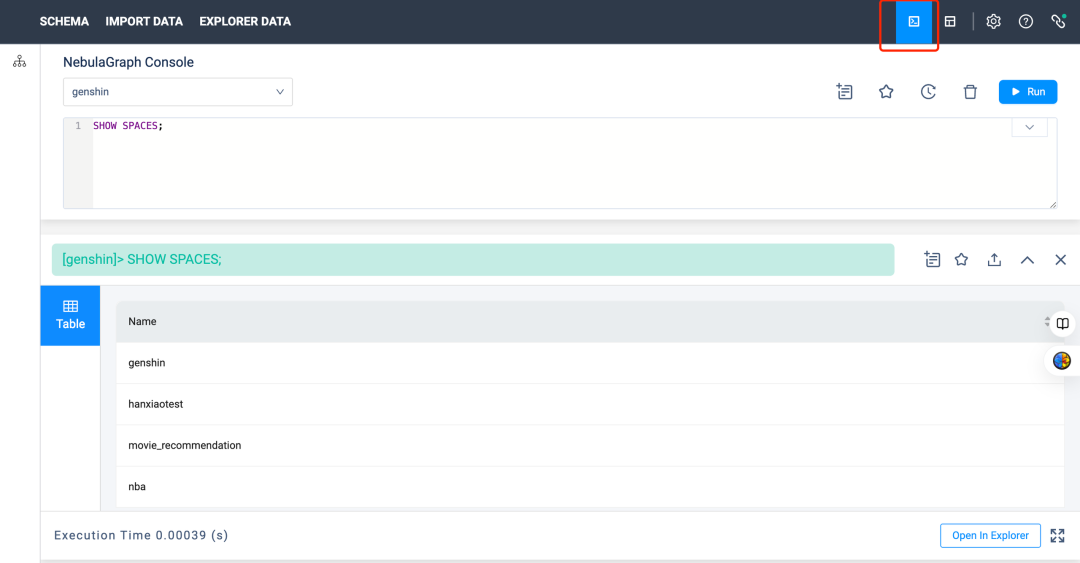
点击右上角的 Console 打开控制台便可以执行 GQL 语句的查询。
网络白名单
在数据库实例的 Overview 页面点击 Connect,选中 Public 方式。
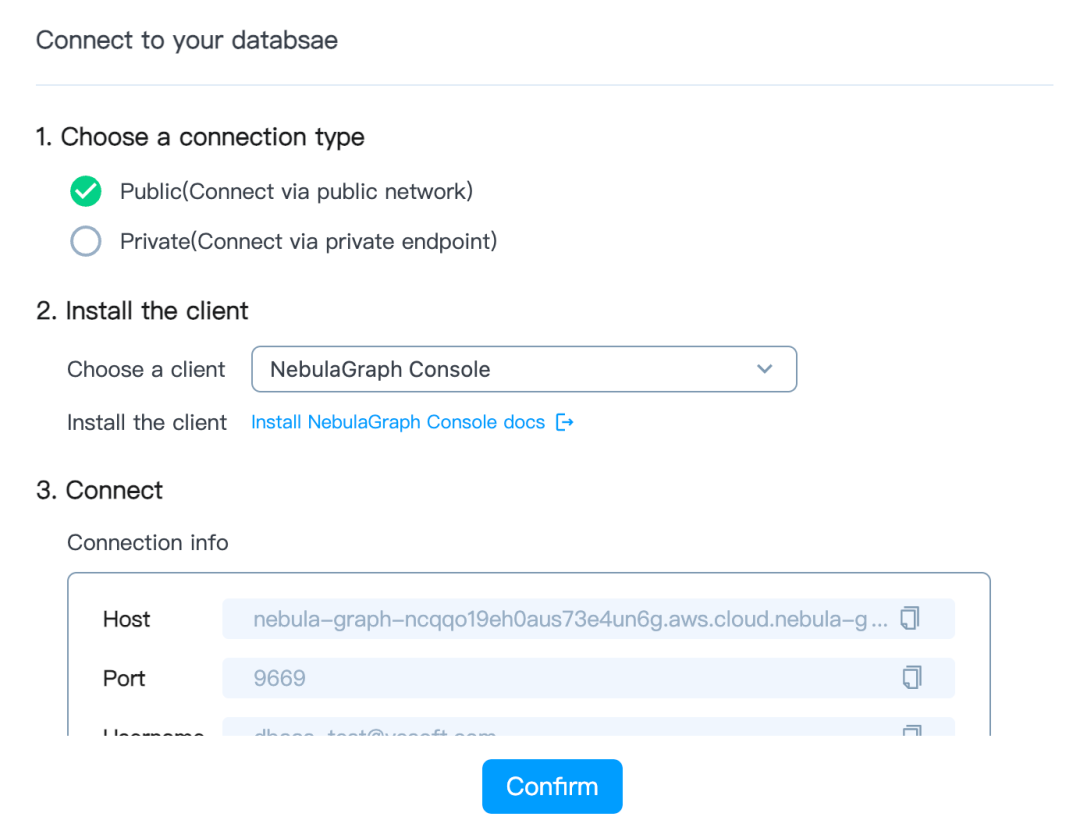
在没有配置网络白名单时,数据库实例无法直接从公网访问。
$ ./nebula-console -addr nebula-graph-ncqqo19eh0aus73e4un6g.aws.cloud.nebula-graph.io -port 9669 -u dbaas-test@vesoft.com -p $PASSWORD -enable_sslWelcome!(dbaas-test@vesoft.com@nebula) [(none)]> show spaces;+------------------------+| Name |+------------------------+| "genshin" || "hanxiaotest" || "movie_recommendation" || "nba" |+------------------------+Got 4 rows (time spent 602µs/222.883326ms)Mon, 02 Sep 2024 16:52:39 CST
左右滑动查看完整示意
Privatelink 私网连接
按照 Create Private Link Endpoint 的配置步骤,确定业务所在的 VPC ID 和 Subnet ID。
运行命令创建 Endpoint:
aws ec2 create-vpc-endpoint --vpc-id <YOUR-VPC-ID> --region us-east-2 --service-name com.amazonaws.vpce.us-east-2.vpce-svc-04f25889c855f891b --vpc-endpoint-type Interface --subnet-ids <YOUR-SUBNET-IDs>
左右滑动查看完整示意
登录亚马逊云科技控制台查看 Endpoint 状态:
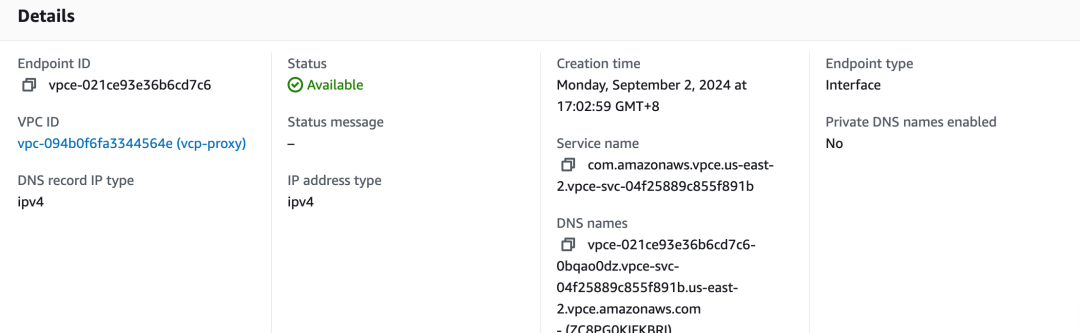
在业务 VPC 内测试访问是否正常。
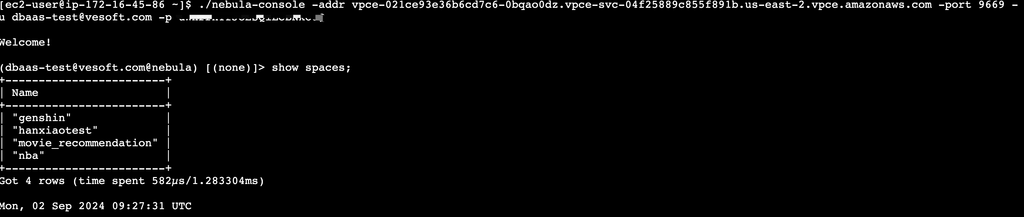
接下来大家可以按照自己的业务需求通过官方生态工具在云上进行数据维护。
总结与展望
本文介绍了基于云原生理念在亚马逊云科技上的服务落地 NebulaGraph 全托管云服务的架构细节,着重阐述如何通过亚马逊云科技的产品为用户带来实质利益,为用户在云端使用 NebulaGraph 提供兼具成本和弹性优势的全新解决方案。
在确保服务质量的同时,我们将继续探索各种可能性,降低用户成本并提高易用度。我们的目标是让用户只需为其使用的资源付费,将成本概念贯彻到每一个细节中。
目前 NebulaGraph Cloud Beta 版本试用活动正在火热进行中,每月最高消费控制在1美元以内,大家可以通过以下链接注册账号。

左右滑动查看更多
欢迎对 NebulaGraph Cloud 感兴趣的小伙伴进群解锁更多 DBaaS 相关内容。

✦
如果你觉得 NebulaGraph能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦
✦

扫码添加
可爱星云
技术交流
资料分享
NebulaGraph 用户案例集
案例推荐:
知识图谱案例:
苏宁基于 NebulaGraph 构建知识图谱的大规模告警收敛和根因定位实践
金融风控案例:
图数据库 Nebula Graph 在 BOSS 直聘的应用
360数科:基于 NebulaGraph 打造智能化的金融反欺诈系统
NebulaGraph 助力金蝶征信产业图谱深挖企业关系链,实现银行批量获客
智能运维案例:
58 同城基于 NebulaGraph 一键部署运维架构的实践
苏宁基于 NebulaGraph 构建知识图谱的大规模告警收敛和根因定位实践
大数据/图平台:
OPPO:通过 NebulaGraph 建设全局图数据库平台
数据治理:
微众银行:利用 NebulaGraph 进行全局数据血缘治理的实践
安全:
