




什么是 'library cache: mutex X' 等待?
mutex是一种控制内存结构访问的机制,在多个区域使用,包括库缓存(library cache)。库缓存是一个内存区域,保存执行SQL所需的解析游标结构。'library cache: mutex X' 等待类似于早期版本中的库缓存等待,可能由许多问题引起(如应用问题、缺乏共享导致的高版本计数等),但本质上是某些东西持有互斥体时间过长,导致其他会话必须等待资源。如果保护库缓存结构的闩锁/互斥体存在争用,则说明解析系统存在压力。SQL解析时间变长,因为无法获得所需资源,从而延迟其他操作并整体上减慢系统速度。由于原因多样,找到正确原因非常重要,以便实施正确解决方案。
导致 'library cache: mutex X' 等待的原因:
「频繁的硬解析」:如果硬解析的频率极高,则可能会在此引脚上产生争用。
「高版本计数」:当版本计数过多时,需要检查一长串版本,可能会导致此事件的争用。
「无效化」:无效化是指从缓存中删除不再有效的游标的次数。当游标无效时,任何想要使用该游标的会话都需要等待加载有效版本。如果无效化过多或不必要,则可能会看到显著的 'library cache: mutex X' 等待。
「重载」:重载是指一个游标曾经存在于缓存中,但由于被淘汰等原因找不到了,必须重新编译并加载到库缓存中。高重载是不好的,因为它表明如果缓存设置适当以避免移除游标,本来不需要做这项工作的。如果游标被重载,那么会话无法抓取它进行工作,从而导致 'library cache: mutex X' 等待。
12c及更高版本中的事件名称:
在12c中,这些事件进一步分为三个独立事件:
「library cache: mutex X」 -- 处理对象
「library cache: bucket mutex X」 -- 处理库缓存哈希桶
「library cache: dependency mutex X」 -- 处理依赖项
如何诊断原因:
检查是否有任何变化:a. 负载增加?b. 应用程序、操作系统或中间层有任何变化?c. 操作系统有任何变化?
'library cache: mutex X' 等待是否有趋势:a. 是否在一天中的某个时间出现这种等待?b. 是否有某些触发因素?
在问题发生时运行AWR和ADDM,并获得基准进行比较以检查负载、参数变化和其他差异。建议在半小时到一小时的间隔内运行AWR和ADDM:
SQL> @$ORACLE_HOME/rdbms/admin/awrrpt.sql
SQL> @$ORACLE_HOME/rdbms/admin/addmrpt.sql
有时系统状态转储有助于匹配已知问题。例如,如果在AWR中没有明显的候选SQL,捕获系统状态中持有者或等待者进程可以帮助聚焦潜在问题。当进程似乎在 'library cache: mutex X' 上挂起时运行系统状态::
非RAC:
sqlplus "/ as sysdba"
oradebug setmypid
oradebug unlimit
oradebug dump systemstate 266
wait 90 seconds
oradebug dump systemstate 266
wait 90 seconds
oradebug dump systemstate 266
quit
RAC:
sqlplus "/ as sysdba"
oradebug setmypid
oradebug unlimit
oradebug setinst all
oradebug -g all hanganalyze 4
oradebug -g all dump systemstate 266
quit
5.错误堆栈:另一种获取进程信息的方法是使用错误堆栈。假设可以识别出一个阻塞者,生成错误堆栈将提供与系统状态类似的信息,但磁盘跟踪占用较少。一旦找到阻塞者的ospid,可以生成错误堆栈:
sqlplus
SQL> oradebug setospid <阻塞者的spid>
oradebug dump errorstack 3
<<等待1分钟>>
oradebug dump errorstack 3
<<等待1分钟>>
oradebug dump errorstack 3
exit
特别是,结果跟踪中的堆栈可以用来匹配已知问题。系统状态和错误堆栈不易阅读,因此可能需要打开服务请求以读取文件。
有时运行系统状态转储不切实际,因为它可能资源密集。因此,也可以在间隔内运行以下SQL:
select s.sid, t.sql_text
from v$session s, v$sql t
where s.event like '%mutex%'
and t.sql_id = s.sql_id
检查会话在等待什么。
如何检查诊断信息:
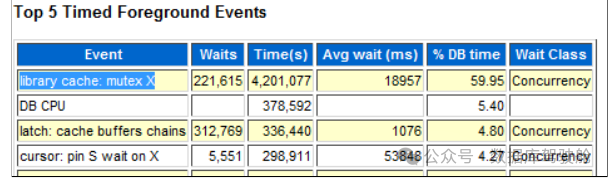
通常,在有问题的AWR中,顶级等待事件将是library cache: mutex X。
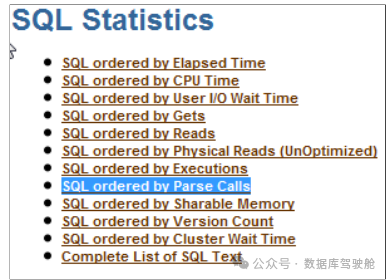
2. 首先从AWR中查找高解析和高版本计数。点击AWR主报告下的*SQL Statistics:

然后在SQL Statistics下点击“SQL ordered by Parse Calls”和“SQL ordered by Version Count”以查看相关信息:
检查是否有高解析调用。
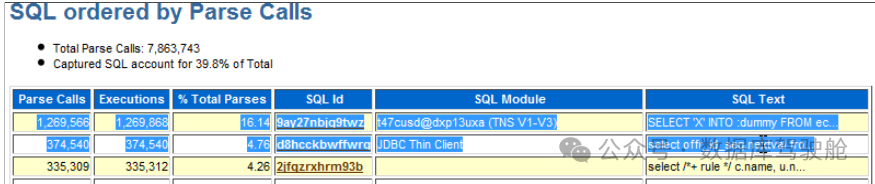
检查解析调用执行次数是否很高。理想情况下,解析与执行次数应较少。注意解析与执行次数相同,表明应用程序中游标未被很好地使用。一旦游标打开并解析,应保持打开状态。与应用程序开发人员沟通如何保持游标打开以重新执行SQL。
从列表中调查高版本计数的SQL。检查这些语句不共享的原因是否可以解决。
可能的解决方案:
检查高硬解析,因为这可能会导致SQL区域的重载。
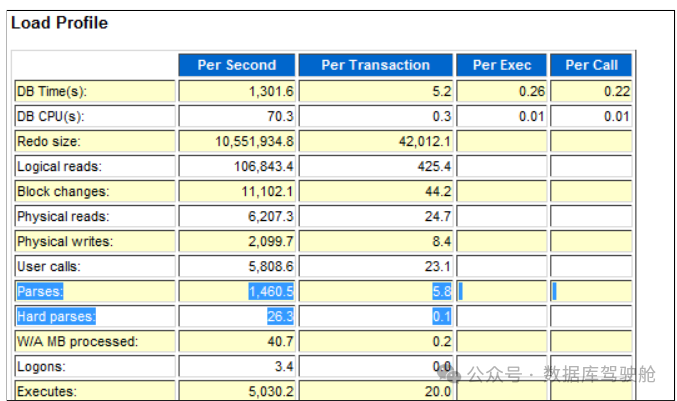
在负载配置文件下检查硬解析:这显示每秒26.3次硬解析,表明硬解析频率很高。检查应用程序是否在共享SQL。如果应用程序主要使用实际值,看看SQL是否可以通过使用绑定变量共享。
检查SQL区域中的高重载
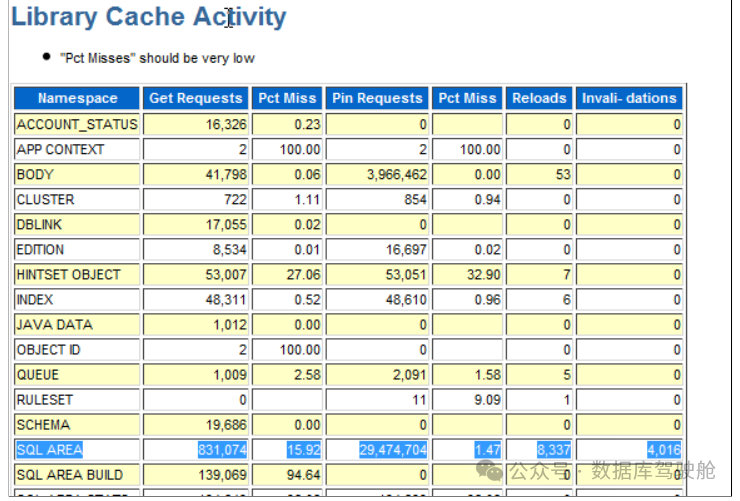
如果重载次数高,查看游标是否被高效共享(记住重载计数缓存中曾存在但现在不在的游标)。如果是,检查共享池或sga_target是否足够大;游标可能因为空间不足而被淘汰。记住,非高效共享意味着库缓存会被非可重用游标填满,这可能导致可重用游标被清除。当它们被重新执行时会导致重载。如果共享高效且共享池太小,共享的SQL语句会被淘汰,硬解析会增加。但大多数情况下,问题在于非高效共享。
检查库缓存活动中的无效化。如果无效化数量高,检查执行的DDL操作,如截断、删除、授权、dbms_stats等。
对于11g,确保cursor_sharing不为similar,因为它已被弃用,这也可能导致互斥等待
「结语」
通过优化 SQL 解析、减少库缓存对象竞争、优化 SQL 执行和调整内存配置,你可以有效地减少 library cache: mutex X 等待时间,提升 Oracle 数据库的性能。希望本文能为你解决实际问题提供帮助。如果你有任何问题或建议,欢迎在评论区留言,我们会及时回复。
「欢迎关注我们的公众号,获取更多技术分享与经验交流。」
