




「故障排除步骤」
「什么是“log file sync”等待?」 当用户会话提交事务时,该会话生成的所有重做记录都需要从内存刷新到重做日志文件,以确保该事务对数据库的更改变为永久性的。在提交时,用户会话将通知 LGWR(日志写入器)将日志缓冲区(包含当前未写入的重做记录,包括该会话的重做记录)写入重做日志文件。LGWR 知道其写入请求已完成后,将通知用户会话已完成。用户会话在等待 LGWR 通知其已完成写入期间会显示为“log file sync”等待。
「初步诊断“log file sync”等待时应收集哪些信息?」 初步分析“log file sync”等待时,以下信息很有帮助:
来自表现正常时间段的 AWR(自动工作负载库)报告,以作为合理性能的基准进行比较
发生“log file sync”过多等待时的 AWR 报告
注意:这两个报告应为10-30分钟的时间段。
LGWR 跟踪文件(包括 12.2 及更高版本中的 LGnn 跟踪)
LGWR 跟踪文件将显示重做写入时间过长期间的警告信息
「什么原因导致“log file sync”等待时间过长?」 在从用户进程通知 LGWR 写入重做信息到 LGWR 通知用户进程重做已从日志缓冲区写入磁盘(本地重做日志和可选地同步模式下的远程备用数据库)并唤醒用户进程接收通知的任何阶段,都可能发生“log file sync”事件等待。
常见原因包括:
影响 LGWR IO 性能的问题
过度的应用程序提交
以下将详细描述这些原因及其排查方法:
「影响 LGWR IO 性能的问题」 我们主要需要回答的问题是“LGWR 在写入磁盘时是否慢?”。以下步骤可帮助确定是否存在这种情况。比较“log file sync”的平均等待时间与“log file parallel write”的平均等待时间。“log file parallel write”等待事件是 LGWR 在重做实际写入期间等待的时间。事件持续时间显示 IO 部分操作的等待时间。
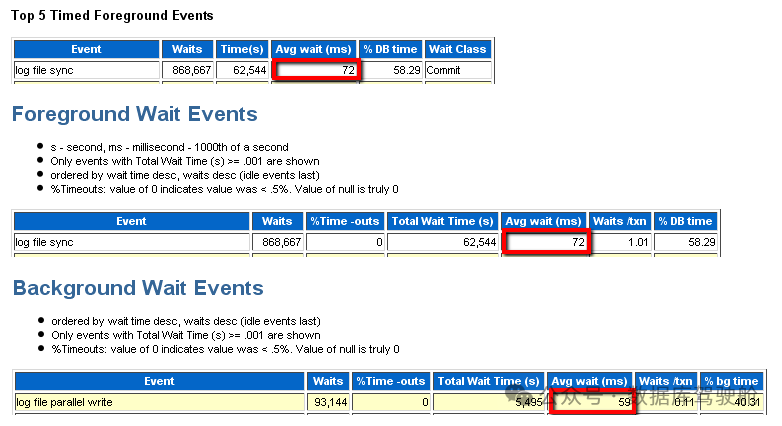
结合“log file sync”查看此事件可以显示同步操作中有多少时间花在 IO 上,同时也能推断出多少处理时间花在 CPU 上。 如果“log file sync”和“log file parallel write”的等待时间都很高,这表明大部分等待时间是由于等待重做写入(IO)。应检查 LGWR 的 IO 性能。通常,“log file parallel write”平均时间超过 20 毫秒表示 IO 子系统存在问题(对于有大量磁盘缓存和/或无移动部件的现代存储系统,如 SSD、NVRAM 等,典型时间可能要小得多)。
「建议」
与系统管理员合作检查存放重做日志文件的文件系统/逻辑卷,以提高 IO 性能。
避免将重做日志文件放在需要计算奇偶校验的旧一代或不太先进的 RAID 技术(如 RAID-5 或 RAID-6)上,写入多个磁盘时前端缓存或缓冲很少,以及缺乏专用 CPU 资源来掩盖该开销。
避免将重做日志放在旧一代固态硬盘(SSD)上。虽然一般来说,固态硬盘的写入性能平均良好,但它们可能会经历写入高峰,这会大大增加某些“log file sync”等待时间,导致性能波动或短暂的数据库挂起。(应测试,因为即使 IO 响应时间不均匀,SSD 的性能在某些情况下仍然可以接受)
Oracle 工程系统(Exadata、SuperCluster 和 Oracle Database Appliance)已优化为更有效地利用 SSD 及相关新技术。
「IO 峰值(或突发 IO)对“log file sync”等待的影响」 日志写入器(LGWR)倾向于以小突发写入活动而非大块 IO 工作(这是更常见的情况)。大多数磁盘未设置为很好地处理小突发活动,这可能导致 IO 等待。但由于平均而言,磁盘工作正常(它们只是不适应突发活动),IO 供应商可能会报告磁盘没有问题。这与系统上的其他 IO 活动一起,可能意味着 IO 性能随着时间的推移不一致,可能出现较高 IO 峰值,然后是较低 IO 时段(这些突发可能导致所谓的 IO 异常值)。当平均值出来时,峰值信息在大量较低的 IO 数字中“丢失”,但这些峰值可能导致需要写入的日志数据积压,表现为“log file sync”等待时间较长,但“log file parallel write”的平均等待时间在正常 IO 容忍范围内。
如果您看到“log file sync”等待时间较长,但“log file parallel write”的平均等待时间在正常 IO 容忍范围内,这可能是因为有 IO 峰值未在平均值中显示出来。一个地方可以查看的是 AWR 的等待直方图部分。您还可以使用类似 OSWatcher(参见:文档 301137.1)的工具识别 IO 峰值,并尝试将其与“log file sync”峰值相关联(可能稍后)。如果确定 IO 峰值,与存储供应商合作解决突发活动。
「检查 LGWR 跟踪」 即使“log file parallel write”的平均等待时间在正常范围内,仍可能有写入时间较长的峰值,这会影响“log file sync”等待。从 10.2.0.4 开始,当重做写入时间超过 500 毫秒时,LGWR 跟踪文件中会记录消息。这是一个相当高的阈值,因此没有消息并不一定意味着没有问题。
*** 2023-10-26 10:14:41.718
Warning: log write elapsed time 21130ms, size 1KB
(set event 10468 level 4 to disable this warning)
*** 2023-10-26 10:14:42.929
Warning: log write elapsed time 4916ms, size 1KB
(set event 10468 level 4 to disable this warning)
注意:如果这些峰值之间间隔很长,它们可能对“log file parallel write”影响不大。但是,如果有数百个会话在等待“log file parallel write”完成,“log file sync”总等待时间可能会很高,因为等待时间会乘以数百个会话。因此,值得调查日志写入器高峰 IO 的原因。
「建议」
与系统管理员合作检查在该时间段内还发生了什么可能导致 LGWR 写入磁盘的峰值。
在发生减速时对 LGWR 进程进行跟踪,可能有助于确定时间去向。
注意:这些警告对预防潜在问题特别有用。即使平均等待时间没有显示一般问题,通过突显 IO 性能的极端峰值,DBA 可以获得 LGWR 遇到间歇性问题的有用指示。这些问题可以在引起中断或类似问题之前解决。
「检查重做日志是否足够大」 每次重做日志切换到下一个日志时,都会执行一次“log file sync”操作,以确保在开始下一个日志之前一切都已写入。标准建议是日志切换最多每 15 到 20 分钟发生一次。如果切换频率高于此,则会有更多的“log file sync”操作,意味着各个会话需要更多的等待时间。
检查 alert.log 中的日志切换时间
例子:
Thu Jun 03 14:57:01 2011
Thread 1 advanced to log sequence 2501 (LGWR switch)
Current log# 5 seq# 2501 mem# 0: /opt/oracle/oradata/orcl/redo05a.log
Current log# 5 seq# 2501 mem# 1: /opt/oracle/logs/orcl/redo05b.log
Thu Jun 03 14:59:12 2024
Thread 1 advanced to log sequence 2502 (LGWR switch)
Current log# 6 seq# 2502 mem# 0: /opt/oracle/oradata/orcl/redo06a.log
Current log# 6 seq# 2502 mem# 1: /opt/oracle/logs/orcl/redo06b.log
Thu Jun 03 15:03:01 2011
Thread 1 advanced to log sequence 2503 (LGWR switch)
Current log# 4 seq# 2503 mem# 0: /opt/oracle/oradata/orcl/redo04a.log
Current log# 4 seq# 2503 mem# 1: /opt/oracle/logs/orcl/redo04b.log
以上例子显示日志切换每 2 到 4 分钟发生一次,频率比推荐的高 5 倍以上。您还可以检查 AWR 报告中的日志切换平均时间。
「建议」
增加重做日志的大小
「过度的应用程序提交」 在这种情况下需要回答的问题是“应用程序是否提交过于频繁?”如果是,频繁的提交活动会导致性能问题,因为提交会将重做从日志缓冲区刷新到重做日志,这会导致“log file sync”等待。要识别潜在的高提交率,如果“log file sync”的平均等待时间远高于“log file parallel write”的平均等待时间,这意味着大部分等待时间不是由于等待重做写入,因此慢 IO 不是问题的原因。多余的时间是 CPU 活动,通常是由于过度提交引起的争用。此外,如果“log file sync”的平均等待时间低,但等待次数多,则应用程序可能提交过于频繁。比较用户提交和用户回滚与用户调用的平均值:在 AWR 或 Statspack 报告中,如果“user calls/(user commits+user rollbacks)”的平均用户调用次数小于 30,则表示提交过于频繁:
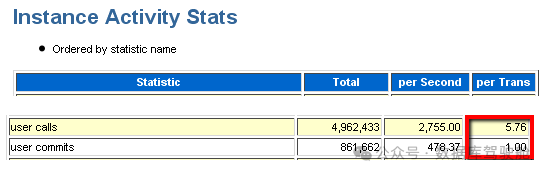
例子:在上面的例子中,我们看到每次提交平均有 5.76 次用户调用,这被认为很高 - 约为推荐值的 5 倍。经验法则,我们应期望每次提交至少有 25 次用户调用。当然,这取决于应用程序设计。
「建议」
如果有许多短时事务,看看是否可以将事务分组,以减少单独的提交操作次数。由于每次提交都需要确认相关重做已写入磁盘,额外的提交会显著增加开销。尽管提交可以被 Oracle “捎带”,通过批处理事务减少总体提交次数可以带来非常有益的效果。
查看是否有处理可以使用 COMMIT NOWAIT 选项(在编写应用程序代码使用前务必理解其语义)。
查看是否有活动可以安全地使用 NOLOGGING UNRECOVERABLE 选项。
「其他可能相关的等待事件」 检查 AWR 报告,看看是否有其他与 LGWR 相关的事件也显示占用了大量时间,这可能为找出问题原因提供线索。应检查前台和后台事件。例如,以下 AWR 显示其他前台和后台等待事件等待时间较长,这可能实际表明将重做日志传输到远程位置存在问题,导致前台进程等待“log file sync”。


「自适应日志文件同步」 自适应日志文件同步在 11.2 引入。控制该特性的参数 _use_adaptive_log_file_sync 在 11.2.0.1 和 11.2.0.2 版本中默认设置为 false。在 11.2.0.3 中,默认设置为 true。启用后,Oracle 可以在两种方法之间切换:
post/wait,传统的写入完成通知方法
轮询,一种新的方法,前台进程检查 LGWR 是否已完成写入。
「建议禁用该特性」
alter system set "_use_adaptive_log_file_sync"=false sid='*' scope=spfile;
「结语」
通过优化事务处理、提高磁盘 I/O 性能、调整日志文件大小和参数,以及分离重做日志和数据文件,你可以有效地减少 log file sync
等待时间,提高 Oracle 数据库的性能。希望本文的内容能帮助你解决实际问题,让你的数据库跑得更快、更稳。如果你有任何问题或建议,欢迎在评论区留言,我们会及时回复!
「欢迎关注我们的公众号,获取更多技术分享与经验交流。」
