




前言
运维同事在工作中有导入文本数据到磐维数据库中的需求,今天整理出来方便大家使用时参考。
创建测试表和文本文件
磐维数据库中创建测试表
testdb=# create table emp(name varchar(20),age int,salary number);
CREATE TABLE
创建文本文件
[omm@node1 ~]$ cat data.txt
John,30,50000
Jane,25,60000
使用copy命令导入/导出数据
通过 COPY 命令实现在表和文件之间拷贝数据。COPY FROM 从一个文件拷贝数据到一个表,COPY TO 把一个表的数据拷贝到一个文件。
注意事项:
- COPY 只能用于表,不能用于视图。
- COPY TO 需要读取的表的 select 权限,copy from 需要插入的表的 insert权限。
- 如果声明了一个字段列表,COPY 将只在文件和表之间拷贝已声明字段的数据。如果表中有任何不在字段列表里的字段,COPY FROM 将为那些字段插入缺省值。
- 如果声明了数据源文件,服务器必须可以访问该文件;如果指定了 STDIN,数据将在客户前端和服务器之间流动,输入时,表的列与列之间使用 TAB键分隔,在新的一行中以反斜杠和句点(.)表示输入结束。
- 如果数据文件的任意行包含比预期多或者少的字段,COPY FROM 将抛出一个错误。
- 数据的结束可以用一个只包含反斜杠和句点(.)的行表示。如果从文件中读取数据,数据结束的标记是不必要的;如果在客户端应用之间拷贝数据,必须要有结束标记。
- COPY FROM 中\N 为空字符串,如果要输入实际数据值\N ,使用\N。
- COPY FROM 不支持在导入过程中对数据做预处理(比如说表达式运算、填充指定默认值等)。如果需要在导入过程中对数据做预处理,用户需先把数据导入到临时表中,然后执行 SQL 语句通过运算插入到表中,但此方法会导致 I/O 膨胀,降低导入性能。
- COPY FROM 在遇到数据格式错误时会回滚事务,但没有足够的错误信息,不方便用户从大量的原始数据中定位错误数据。
- 目标表存在 trigger,支持 COPY 操作。
- COPY 命令中,生成列 不能出现在指定列的列表中。使用 COPY… TO 导出数据时,如果没有指定列的列表,则该表的所有列除了生成列都会被导出。COPY… FROM 导入数据时,生成列会自动更新,并像普通列一样保存。
语法格式
- 从一个文件拷贝数据到一个表。
COPY table_name [ ( column_name [, ...] ) ]
FROM { 'filename' | STDIN }
[ [ USING ] DELIMITERS 'delimiters' ]
[ WITHOUT ESCAPING ]
[ LOG ERRORS ]
[ LOG ERRORS DATA ]
[ REJECT LIMIT 'limit' ]
[ [ WITH ] ( option [, ...] ) ]
| copy_option
| [ FIXED FORMATTER ( { column_name( offset, length ) } [, ...] ) ]
| [ TRANSFORM ( { column_name [ data_type ] [ AS transform_expr ] } [, ...]
) ];
- 把一个表的数据拷贝到一个文件。
COPY table_name [ ( column_name [, ...] ) ]
TO { 'filename' | STDOUT }
[ [ USING ] DELIMITERS 'delimiters' ]
[ WITHOUT ESCAPING ]
[ [WITH] ( option [, ...] ) ]
| copy_option
| [ FIXED FORMATTER ( { column_name( offset, length ) } [, ...] ) ];
COPY query
TO { 'filename' | STDOUT }
[ WITHOUT ESCAPING ]
[ [WITH] ( option [, ...] ) ]
| copy_option
| [ FIXED FORMATTER ( { column_name( offset, length ) } [, ...] ) ];
说明:
option中的FORMAT 'format_name' :数据源文件的格式。取值范围:CSV、TEXT、FIXED、BINARY。
- CSV 格式的文件,可以有效处理数据列中的换行符,但对一些特殊字符处理有欠缺。
- TEXT 格式的文件,可以有效处理一些特殊字符,但无法正确处理数据列中的换行符。
- FIXED 格式的文件,适用于每条数据的数据列都比较固定的数据,长度不足的列会添加空格补齐,过长的列则会自动截断。
- BINARY 形式的选项会使得所有的数据被存储/读作二进制格式而不是文本。 这比 TEXT 和 CSV 格式的要快一些,但是一个BINARY 格式文件可移植性比较差。
缺省值:TEXT
示例:
# 使用copy命令从文件中导入数据到测试表emp中
testdb=# copy emp FROM '/home/omm/data.txt' WITH (delimiter'|',IGNORE_EXTRA_DATA 'on');
COPY 2
testdb=# select * from emp;
name | age | salary
------+-----+--------
John | 30 | 50000
Jane | 25 | 60000
# 使用copy命令把测试表emp中的数据导出到文件中,header表示将表头导出
testdb=# copy emp to '/home/omm/data1.txt' WITH (delimiter',',format 'csv',header);
COPY 2
testdb=# \q
[omm@node1 ~]$ cat data1.txt
name,age,salary
John,30,50000
Jane,25,60000
# 使用copy命令把测试表emp中的部分列导出到文件中
testdb=# copy emp(name,salary) to '/home/omm/data2.txt' WITH (delimiter',',format 'csv');
COPY 2
testdb=# \q
[omm@node1 ~]$ cat data2.txt
John,50000
Jane,60000
使用gsql元命令 \copy导入/导出数据
gsql 工具提供了元命令\copy 进行数据导入/导出。
注意事项:
- \COPY 只适合小批量,格式良好的数据导入,不会对非法字符进行预处理,也无容错能力。导入数据应优先选择 COPY。
- \COPY 可以指定数据导入时的客户端数量,从而实现数据文件的并行导入,目前并发数范围为[1, 8]。
- \COPY 支持分批导入:对导入数据的总行数进行分批,用户可以手动指定每批数据的行数(batch_size)。
- \COPY 命令格式详情参考《PanWeiDB V2.0.0管理员指南》 -> 使用 gsql 元命令导入数据。
- \COPY 并行导入目前存在以下约束
– 不支持临时表、二进制文件以及事务内的并行导入。
– 数据导入支持 AES128 加密时不支持并行导入。
– 在这些情况下,即使指定了 parallel 参数,仍然会走非并行流程。
\copy 语法格式:
\copy { table [ ( column_list ) ] | ( query ) } { from | to } { filename | stdin | stdout | pstdin | pstdout }
[ with ] [ binary ] [ delimiter [ as ] 'character' ] [ without escaping ] [ null [ as ] 'string' ]
[ csv [ header ] [ quote [ as ] 'character' ] [ escape [ as ] 'character' ]
[ force quote column_list | * ] [ force not null column_list ] ] [ batch_size n ] [ show_line_number ] [ compatible_illegal_chars ]
在任何 gsql 客户端登录数据库成功后,可以使用该命令进行数据的导入/导出。但是与 SQL 的 COPY 命令不同,\COPY 命令读取/写入的文件只能是 gsql客户端所在机器上的本地文件,而非数据库服务器端文件;所以,要操作的文件的可访问性、权限等,都是受限于本地用户的权限。
示例:
# 使用\copy命令从文件中导入数据到测试表emp中
testdb=# \copy emp FROM '/home/omm/data.txt' WITH (delimiter',',IGNORE_EXTRA_DATA 'on');
# 检查数据
testdb=# select * from emp;
name | age | salary
------+-----+--------
John | 30 | 50000
Jane | 25 | 60000
# 使用\copy命令把测试表emp中的数据导出到文件中
testdb=# \copy emp to '/home/omm/data1.txt' WITH (delimiter',');
testdb=# \q
[omm@node1 ~]$ cat data1.txt
John,30,50000
Jane,25,60000
使用pw_bulkload 导入数据
pw_bulkload 就是批量加载工具,可以加载表数据,批量加载可以提升加载的效率和性能。
语法格式
Dataload: pw_bulkload [dataload options] control_file_path
Recovery: pw_bulkload -r [-D DATADIR]
编辑数据文件
[omm@node1 ~]$ cat bulkload.txt
1,a
2,b
编辑控制文件
[omm@node1 ~]$ vi bulkload.ctl
INPUT = /home/omm/bulkload.txt
TYPE = CSV
DELIMITER = ,
OUTPUT = public.test1
ERROR_RECOVERY = YES
创建插件和目标表
CREATE EXTENSION pw_bulkload;
create table test1(id int primary key,col text);
使用 pw_bulkload 导入数据
[omm@node1 ~]$ pw_bulkload -d testdb bulkload.ctl
执行结果
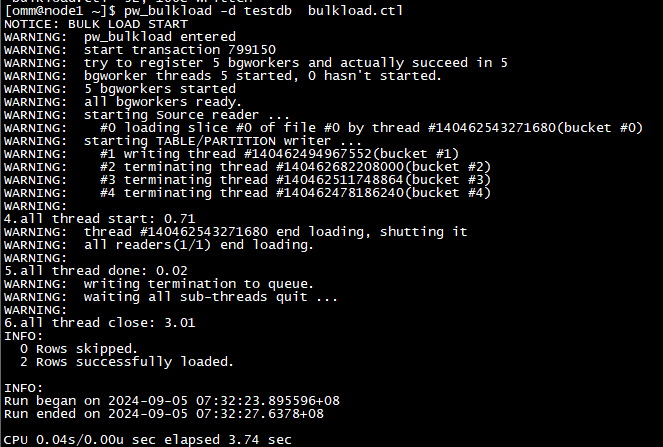
验证数据
testdb=# select * from test1;
id | col
----+-----
1 | a
2 | b
(2 rows)
使用load data导入数据
查询表中现有数据
testdb=# select * from emp;
name | age | salary
------+-----+--------
John | 30 | 50000
Jane | 25 | 60000
编写数据文件
[omm@node1 ~]$ vi data3.txt
John1|50|90000
Jane1|55|80000
导入数据
load data infile '/home/omm/data3.txt'
into table emp
columns terminated by '|' lines terminated by '\n'
(name,age,salary);
执行结果

验证数据
testdb=# select * from emp;
name | age | salary
-------+-----+--------
John | 30 | 50000
Jane | 25 | 60000
John1 | 50 | 90000
Jane1 | 55 | 80000
(4 rows)
注意:load data实际上使用的时copy命令,所以只支持导入数据库服务器端的文件,而不是gsql客户端所在机器上的文件。如果用gsql客户端远程连接数据库执行导入会报下面的错误:

通过JDBC驱动的CopyManager接口导入数据
CopyManager接口适用于大规模数据导入。具体请参考磐维数据库管理员指南或者开发者指南。
总结
从文件中导入数据到磐维数据库中以及反向操作都是常用的功能,具体使用语法及场景请参考《磐维数据库开发者指南》或者《磐维数据库管理员指南》相关章节。
最后修改时间:2024-09-06 12:07:43
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
