




一、安装部署
1、集中式安装部署
以下列举几个常见容易忽略导致数据库安装失败的原因
1)检查操作系统确定其对应的安装包
2)python3环境-推荐使用yum安装python3
常见报错:
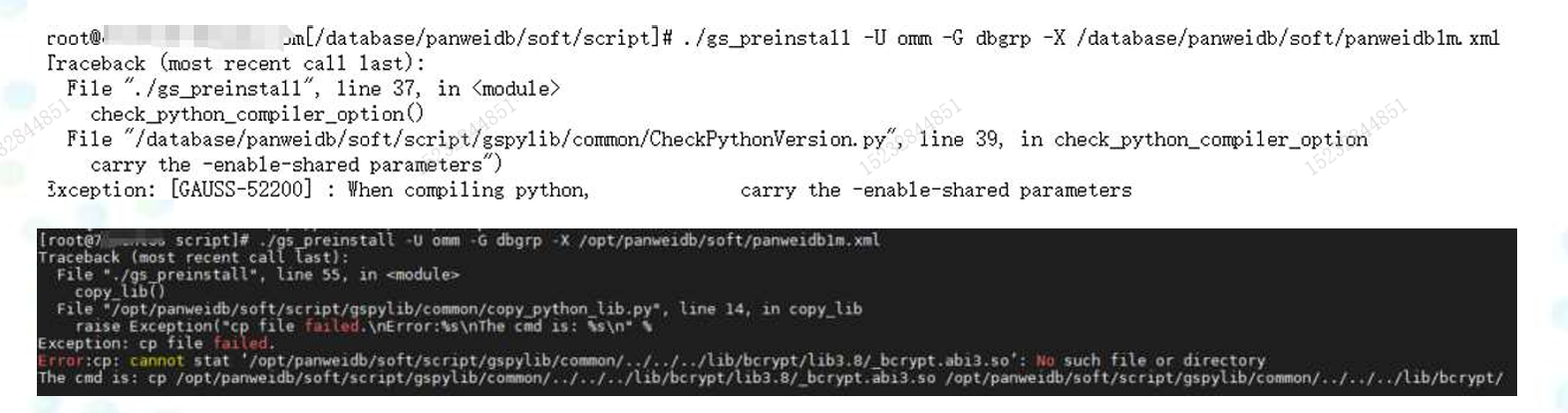
3)检查cpu指令集
rdtscp指令集(x86)执行
lscpu | grep rdtscp命令查看是否支持rdtscp指令集。bmi2指令集(CentOS)执行
lscpu |grep bmi2命令查看是否支持bmi2指令集。
2、分布式安装部署
问题现象:
安装部署时报错:
{
"ret":8000301
"msg":"Transport endpoint unreach"
}
问题排查:
ha日志:

通过以上log判断为etcd服务异常,手动启动etcd报错:
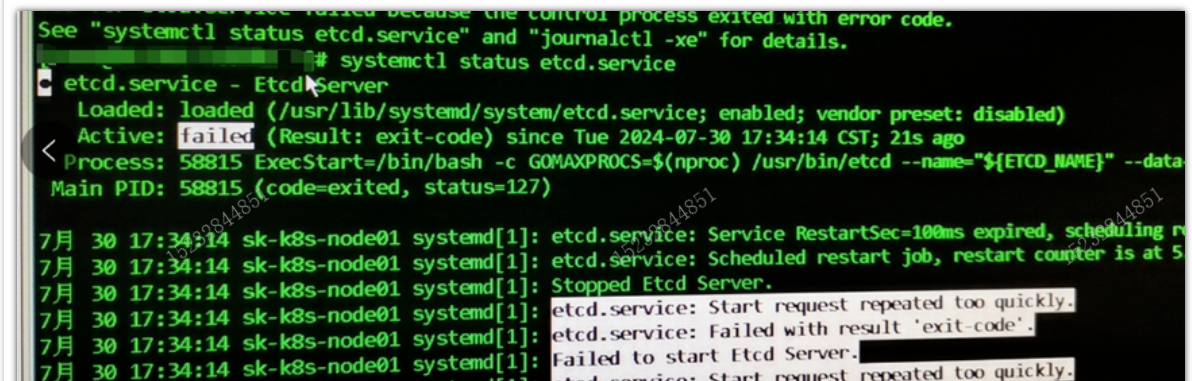
抓取对应的journalctl.log报错信息,定位为权限不足:

解决方法: 其中libcrypto.so.1.0.2k和libssl.s0.1.0.2k应该为755权限,但实际服务器上为750权限,通过以下命令进行授权
chmod 755 /usr/lib64/libssl.s0.1.0.2k
chmod 755 /usr/lib64/libcrypto.so.1.0.2k
授权后,重新安装部署成功,至此问题得到解决
常用命令:
etcd常用命令:
--查看etcd服务状态
etcdctl --endpoints=http://10.xx:2379 ls -r /service
--查看etcd成员
etcdctl --endpoints=http://10.xx:2379 member list
--查看etcd集群信息
etcdctl --endpoint http://10.xx:2379 ls /service/omm集群常用命令:
--启动集群
ha_ctl start all -l http://10.xxx:2379
--停止集群
ha_ctl stop all -l http://10.xxx:2379
--查看集群信息
ha_ctl monitor all -l http://10.xxx:2379 -H
二、license使用
1、Error happen when load license cannot write xxx
WARNING:Error happen when load license cannot write data to dir /etc/panweidb/license.

license目录无license文件或者数据库用户的权限问题
2、The trial has been expired ...
WARNING: The trial has been expired: xxxx, please ask administrator for license`
license文件过期
3、dtp升级到3.0后服务启动失败
问题现象:
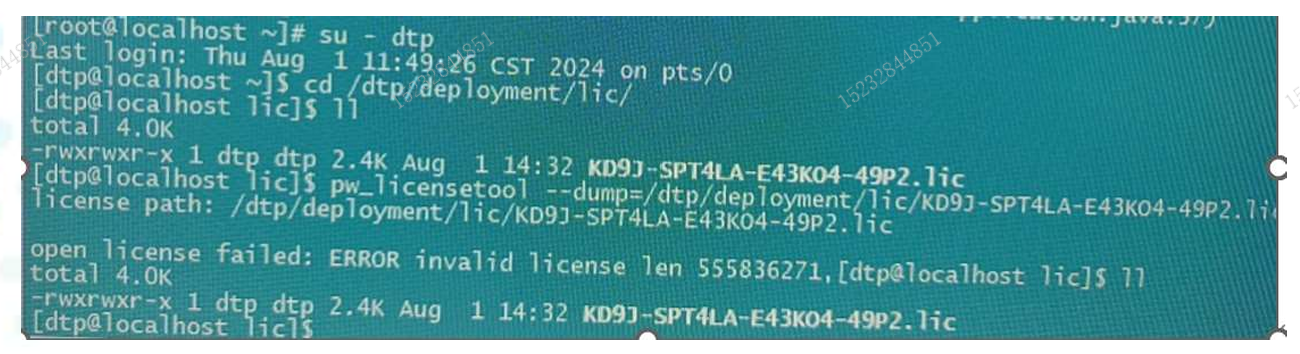
解决方案:
1)对依赖包创建软连接
cd /dtp/deployment/lib/so
ln -s /dtp/deployment/lib/so/libssl.so /dtp/deployment/lib/so/libssl.so.10
2)重启panwei-dtp
systemctl start panwei_dtp三、备份恢复-gs_probackup
1. 自定义表空间
备份:使用-E,--external-dirs来指定自定义表空间路径,多个自定义表空间用:隔开
恢复:--tablespace-mapping和--external-mapping
2. 备份超时
问题现象: 执行2min报错
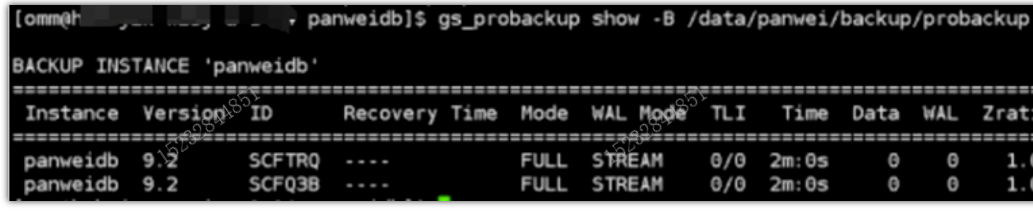
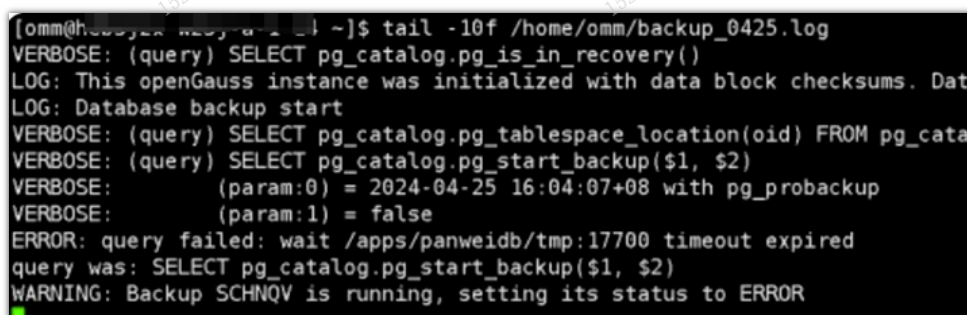
问题原因:-t rwtimeout 以秒为单位的连接的超时时间。默认是120s
解决方法:在执行gs_probackup时指定超时时间
3. 归档问题
问题现象: pg_stop_backup doesn't answer in 300 seconds, cancel it

排查思路:
1)首先检查归档是否开启show archive_mode;
2)归档路径是否正确show archive_dest;
3)归档路径是否存在
4)归档目录的读写权限
5)检查wal_sender_timeout参数配置是否配置正确
6)确认是否因为备份执行命令未放置后台执行导致超时crontab -e
四、JDBC使用
1、ERROR: relation "xxx" does not exist
业务查询不到表对象,报错如下:
ERROR: relation "xxx" does not exist ..
排查思路:
确认schema - currentSchema
确认该schema下是否存在该表
确认查询的该用户是否有权限查询该表
2、druid连接池,报错:buffer is empty
排查思路:
设置打开keepalive进行连接探活;
数据库参数:
session_timeout=0合理设置
connectTimeout&socketTimeout的值设置
testOnReturn=off
五、其他常见问题
Q0:cm_ctl start启动失败
排查思路:
1、查状态:当cm_ctl start 启动数据库集群有问题,先gs_om -t status --detail查看集群状态。
2、手动起数据库gs_ctl start -D 数据目录。如果是cmserver正常,数据库状态异常,启动数据库的异常节点。如果两个数据库节点都是down的状态,需要一个启动为主节点,-M primary;一个启动为备节点-M standby。如果主节点状态正常,只需-M standby启动备节点
3、按照启动输出中的报错信息排查问题
Q1:启动失败-Failed to start instance...
[GAUSS-51607]: Failed to start instance. Error: please check the gs_ctl log for failure details
建议根据提示查看gs_ctl日志和数据库日志pg_log进一步确定。(有遇到是由于CPU指令集导致的)
Q2:启动失败-Failed to read gaussdb.state: 0
Failed to read gaussdb.state: 0 Failed to set gaussdb.state with UNKNOWN_STATE
删除gaussdb.state文件或者将该文件size手动改为72,重新启动
Q3:启动失败-data directory xxx has ...
FATAL: data directory xxx has group or world access DETAIL: Permissions should be u=rwx (0700).
数据目录权限问题,需执行:chmod -R 700 数据目录
Q4:启动失败-could not create shared memory segment: No space left on device
FATAL: could not create shared memory segment: No space left on device
kernel.sem=kernel.sem = 250 6400000 1000 25600根据服务器内存大小调整shared_buffers
Q5:启动失败-the values of memory out of limit...
FATAL: the values of memory out of limit, the database failed to be started
根据服务器内存大小调整数据库的max_process_memory和shared_buffers参数
Q6:cached plan must not change result type
使用过程中业务查询报错:
cached plan must not change result type
原因:业务使用了prepare语句 与 数据库做了DDL操作
规避方法:
重启业务程序 杀掉数据库会话连接 deallocate the prepare
Q7:大小写问题
大小写相关参数:
lower_case_column_names-字段大小写敏感设置lower_case_table_names-表名称大小写敏感设置
Q8:column "bytes_" is of type bytea...
迁移后,JDBC向数据库中BYTEA字段插入数据时报错:
ERROR: column "bytes_" is of type bytea but expression is of type blob
JDBC连接串中的blobMode设置为off
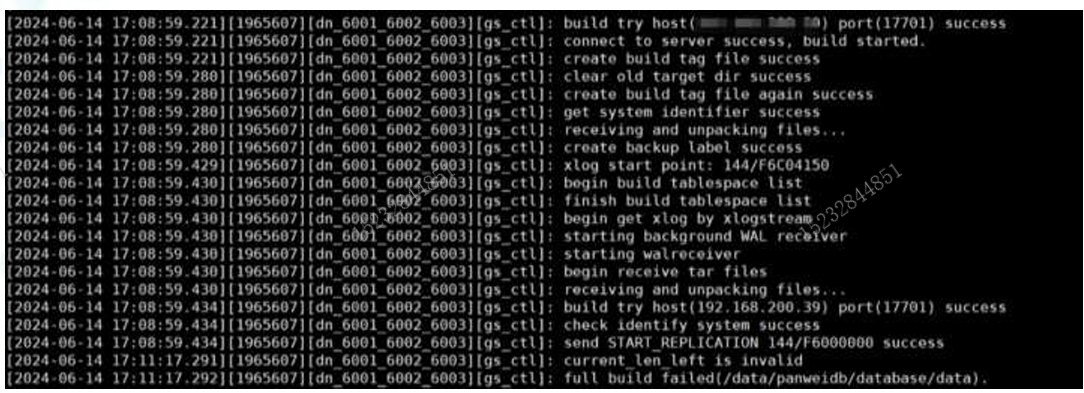
Q9:current_len_left is invalid
全量build失败:
current_len_left is invalid
总结:排查问题主要核心思路是查看相关日志的报错,根据报错去分析问题原因
