排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
GPDB HashAgg算法 | 第3期 | 版本6的spill溢出磁盘解秘
GPDB HashAgg算法 | 第3期 | 版本6的spill溢出磁盘解秘
yanzongshuaiDBA
2024-09-09
148
GPDB HashAgg
算法
|
第
3
期
|
版本
6
的
spill
溢出磁盘解秘
上期我们介绍了版本
12
的
spill
场景下
hashagg
如何进行操作,本期接着介绍下
GPDB
版本
6
是怎么操作的,它是否和版本
12
的原理一样?当然不一样,和版本
12
将不在当前
hash
表分组的元组溢出到磁盘不同,它是将当前
hash
表溢出到磁盘,然后再将元组插入到腾出空间的
hash
表中。
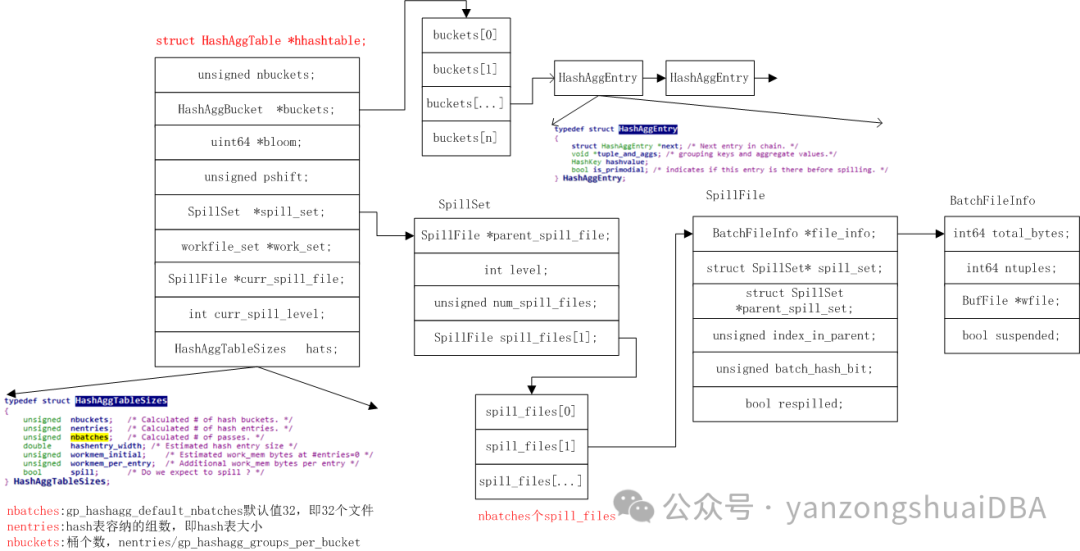
1、hash表的管理
Hash
表的结构为
HashAggTable
,由聚合算子执行状态结构
AggState
管理。和
PgSQL12
版本不同的是,他只有一个
hash
表。
SpillSet
用来管理溢出文件,
HashAggTableSizes
有
hash
表一些信息:
nbatches
为临时文件个数,由配置项
gp_hashagg_default_nbatches
控制,默认
32
;
nentries
为
hash
表容纳的组数,即
hash
表大小;
nbuckets
为
hash
表的桶数,
nentries/gp_hashagg_groups_per_bucket
。
HashAggBucket
用来管理
Hash
桶,每个成员为
HashAggEntry
,存有分组值和分组聚合值、
hash
值;若发生
hash
冲突,则通过链表的形式串在一起。
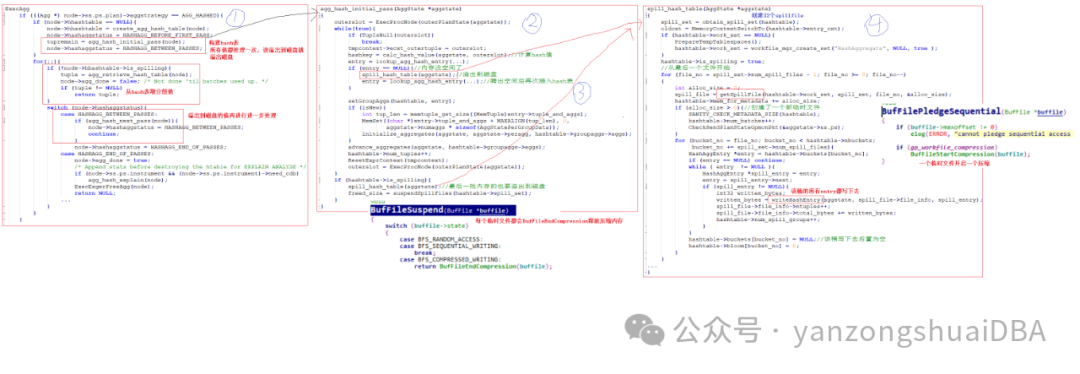
2、hash表spill机制
2.1 spill写
1)
首先通过
agg_hash_initial_pass
构建
hash
表,会将所有值都处理一遍,若内存中放不下,则将
hash
表溢出写磁盘腾出空间后,继续构建
hash
表。处理完成后(溢出磁盘场景),所有值都在磁盘临时文件中进行了分组。实际上,每个
hash
桶映射到一个文件中,若
hash
桶数大于临时文件个数,则多个
hash
桶会映射到一个文件中。如此,最后相当于将元组进行了一次粗略分组,写到各个临时文件中
2)
agg_hash_initial_pass
的
spill_hash_table
函数就是将
hash
表溢出到磁盘,然后通过
lookup_agg_hash_entry
继续插入
hash
表
3)
最后一批
hash
表内存中的数据
(hashtable->is_spilling)
也需要溢出磁盘,不过此时会调用
suspendSpillFiles->BufFileSuspend
函数将每个临时文件通过
BufFileEndCompression
释放压缩内存
4)
spill_hash_table
函数首先通过
obtain_spill_set
创建
32
个
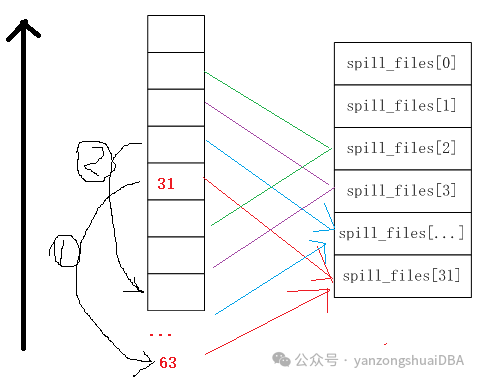
spillfile
,然后通过如下方式写磁盘:从最后一个
spill
文件号开始依次向前遍历,比如先将
31
号桶写到
spill_files[31]
中,然后再将
31+32=63
号桶也写到
31
号,向后按照
31
的步长写桶;写完后再向前遍历,即处理
30
号桶,再按照上面方式写磁盘。写一个临时文件时,若开启压缩的话,会调用
BufFilePledgeSequential->BuffileStartCompression
开启压缩
需要注意的是:使用的是
zstd
压缩算法,虽然性能不错,但是比较耗内存,不论向该文件写多少内容,大概一个文件都需要
1.3MB
,当临时文件特别多的时候,内存耗费就相当大了;而且这个内存还是
zstd
内部的,不受
GPDB
的内存管理,会造成操作系统的
OOM
2.2 spill读
通过
agg_hash_next_pass->agg_hash_reload
依次加载所有临时文件,重新构建
hash
表,将分组值进一步进行精确划分。当然,若是当前文件加载的时候,又发生溢出磁盘,则需要再次将其
hash
表写磁盘,当然这时候的写磁盘需要将上次中的一个
spill_files
的东西进一步划分后,再将
hash
表写磁盘。
读之前,需要
reset_agg_hash_table
通过该文件的记录数重新规划
hash
表大小,这样的话,上一次的
hash
表同一个文件的内容再次
hash
后会根据新
hash
表大小将不同分组进一步分散到不同
hash
桶,而不是仍旧在同一个
hash
桶。
GPDB6
的加载是遍历
spillfiles
数组来将各个文件依次加载并进一步
hash
。
和
PgSQL12
方式最大区别:
PgSQL12
是总是保持内存
hash
表的一批分组值,内存不够时,将元组值按照
hash
值溢出到临时文件,处理一圈元组后,就可以将当前内存中的
hash
表分组输出;而
GPDB6
则需要将所有值全部溢出磁盘,最终形成一个临时文件,将其加载内存构建好
hash
表,并且没有再次溢出磁盘时才会输出分组值。总体来说,
GPDB6
的输出时机比较靠后,而
PgSQL12
的输出间隔相对较小。也就是
PgSQL12
的算法还是比较具有优势的。
临时文件
hash函数
hash
文章转载自
yanzongshuaiDBA
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨