




在 Vertica 数据库中,处于 DOWN 状态的节点不参与自该节点关闭以来提交的任何事务。重新启动 DOWN 节点后,该节点必须从伙伴节点恢复丢失的数据,然后才能转为 UP 状态。当节点处于 UP 状态时,它已完全恢复并准备好处理所有数据库事务。
本文主要讲解如下内容:
- Vertica 9.1 节点恢复过程
- 监控节点恢复的工具
- 诊断和解决节点恢复过程中出现的问题
1、节点恢复过程
Vertica 节点恢复分两个阶段执行:
- 恢复准备阶段:在此阶段,待恢复节点执行以下任务:
- 重新启动 Spread 守护进程
- 读取磁盘上的 Catalog
- 验证数据存储
- 加入集群
- 恢复阶段:在该阶段,待恢复节点:
- 接收加载到集群中的新数据
- 恢复节点处于 DOWN 状态期间丢失的数据
如果数据库节点处于RECOVERING状态,Tuple Mover可以在恢复过程中根据需要执行 Moveout 和 Mergeout 操作。 Tuple Mover 在恢复期间通过 Mergeout 进程合并 ROS 容器并防止发生 ROS Pushback 错误。
此外,Tuple Mover 执行 Moveout ,将数据从 WOS 移动到 ROS。这样做可以在恢复期间执行诸如涓流加载之类的任务,从而创建一个可持续的加载过程,生成更少的 ROS 容器。 Mergeout 和 Moveout 都可以提高节点恢复的性能。
下图给出了详细的工作流程,显示了节点恢复过程的所有阶段:
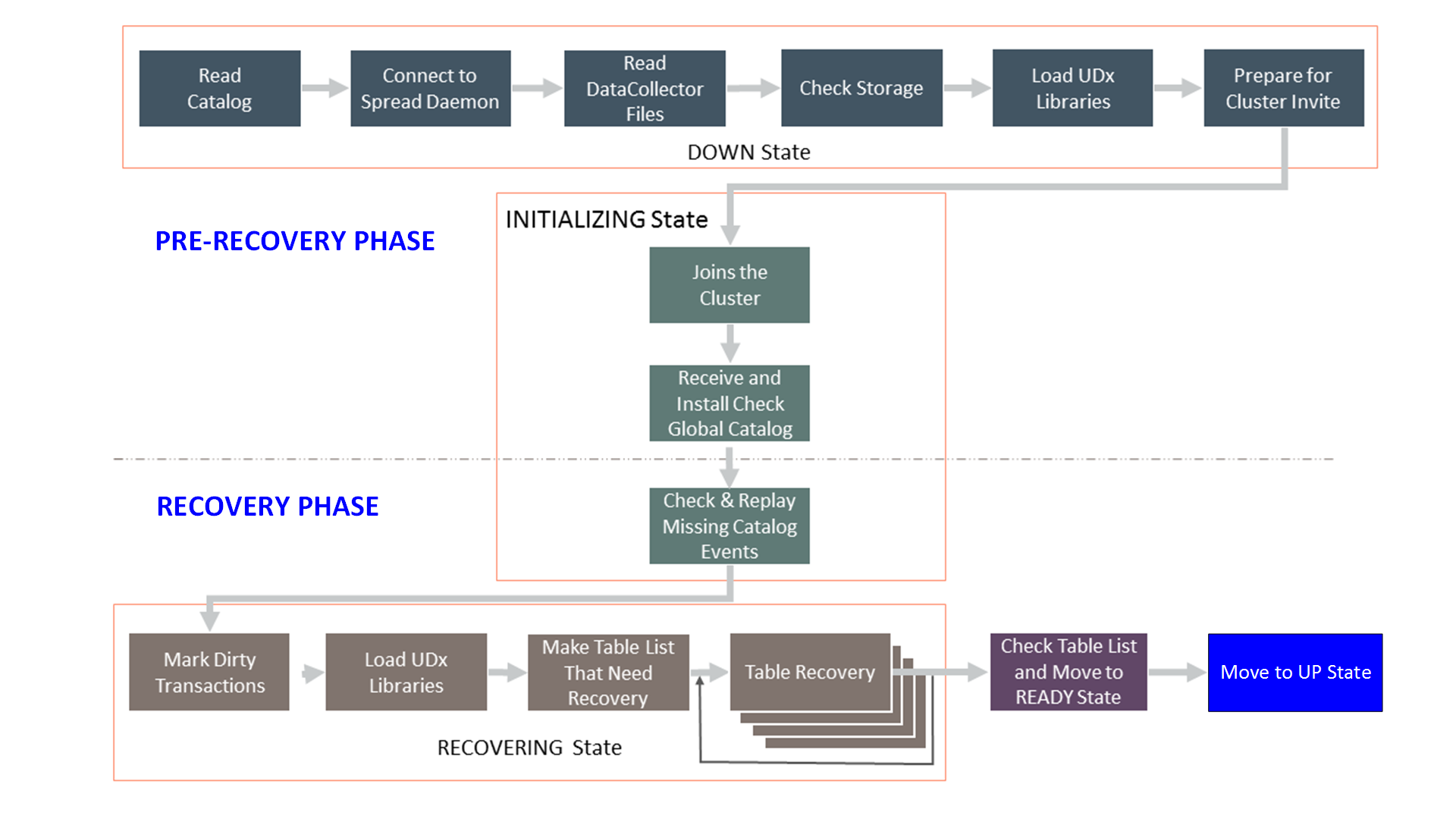
2、恢复准备阶段
恢复准备阶段在节点重新启动后立即开始,一直运行到宕机节点重新加入集群。要跟踪此阶段的节点进度,请监控位于 Catalog 目录中的 startup.log 文件。 startup.log 文件是 vertica.log 文件的子集。
预恢复阶段有以下几个阶段:
| 阶段 | 描述 |
|---|---|
| Reads the catalog | The recovering node reads the catalog checkpoints, applies the transaction logs, and indexes the catalog objects. 恢复节点读取 catalog 检查点、应用事务日志并为目录对象建立索引。 |
| Starts and connects to the spread deamon | Vertica starts the spread daemon on the recovering node and connects to spread daemon. However, if your database runs in large cluster mode, a subset of nodes known as control nodes run the spread daemon instead. Vertica 在恢复节点上启动 Spread 守护程序并连接到 Spead 守护程序。 但是,如果您的数据库在大型集群模式下运行,则在控制节点上运行 Spread 守护程序。 |
| Reads the DataCollector files | The recovering node creates an inventory of the DataCollector files. 恢复节点创建 DataCollector 文件的清单。 |
| Checks data storage | · The recovering node checks the data files specified in the catalog. It verifies the files for existence, permission, and correctness. · The recovering node removes the data files that are not referenced in the catalog. · 恢复节点检查 Catalog 中指定的数据文件。它验证文件的存在、权限和正确性。 · 恢复节点删除 Catalog 中未引用的数据文件。 |
| Loads UDx libraries | The recovering node loads the User Defined Extension (UDx) libraries. 恢复节点加载用户定义扩展 (UDx) 库。 |
| Prepares for Cluster Invite | The recovering node joins the spread group and broadcasts messages to the other nodes. The recovering node waits for an invitation from the other nodes to rejoin the cluster. 恢复节点加入 Spread 组并向其他节点广播消息。 恢复中的节点等待其他节点重新加入集群的邀请。 |
| Joins the cluster | Upon invitation, the node joins the cluster and the node state changes to the INITIALIZING state. 收到邀请后,节点加入集群,并且节点状态更改为 INITIALIZING 状态。 |
| Receives and install the new global catalog | The recovering node shares the catalog version with other nodes in the cluster. If the catalog version of the recovering nodes is lower than the nodes in the UP state, a node in the UP state sends the global catalog to the recovering node in the chunks of 1 GB. The recovering node installs the new catalog received from one of the UP nodes. 恢复节点与集群中的其他节点共享 Catalog 版本。 如果恢复节点的 Catalog 版本低于UP状态的节点,则处于UP状态的节点将全局 Catalog 以 1GB 的块的形式发送到恢复节点。 恢复节点安装从 UP 节点之一接收到的新 Catalog 。 |
3、恢复阶段
在恢复阶段,故障节点接收数据库中加载的新数据。故障节点还会从该节点的伙伴节点处同步宕机时丢失的数据。
您可以从以下系统表跟踪此阶段的进度:
- TABLE_RECOVERY_STATUS
- TABLE_RECOVERIES
- PROJECTION_RECOVERIES
恢复阶段有以下几个阶段:
| 阶段 | 描述 |
|---|---|
| Checks and replays missing catalog events | The recovering node checks for missing events and replays the missed events in the order in which they were committed. The Vertica catalog has a log of the following types of catalog events, the tables involved, and the epochs in which the events were committed. - Alter partition - Restore table - Replace node 恢复节点检查缺失事件并按提交顺序重播缺失事件。 Vertica Catalog 包含以下类型的事件、涉及的表以及提交事件的时期的日志。 - 修改分区 - 恢复表 - 替换节点 |
| Marks dirty transactions | Dirty transactions are uncommitted transactions that start before the beginning of the RECOVERY phase. During recovery, Vertica marks the dirty transactions, and the state of the recovering node state changes from INITIALIZING to RECOVERING. The node in RECOVERING state participates in all data load plans. 脏事务是在 RECOVERY 阶段开始之前启动的未提交事务。 在恢复期间,Vertica 会标记脏事务,恢复节点的状态会从 INITIALIZING 变为 RECOVERING。RECOVERING 状态的节点会参与所有数据加载。 |
| Loads UDx libraries | The recovering node loads the UDx libraries received from the nodes in the UP state. 恢复节点加载从处于 UP 状态的节点接收的 UDx 库。 |
| Makes list of tables that need recovery | The recovering node makes a list of tables that need recovery. 恢复节点列出需要恢复的表。 |
| Table Recovery | For step-by-step details about table recovery, see Steps for Table Recovery. As of Vertica 7.2.2, Vertica recovers more than one table concurrently. The number of tables that Vertica can recovery concurrently depends on: - The MAXCONCURRENCY of the resource pool RECOVERY - The number of projections per table As of Vertica 7.2.x, you can specify the order of table recovery. For more information, see Prioritizing Table Recovery in Vertica documentation. 有关表恢复的分步详细信息,请参阅 表恢复步骤。 从 Vertica 7.2.2 开始,Vertica 可同时恢复多个表。Vertica 可同时恢复的表数取决于: - 资源池 RECOVERY 的 MAXCONCURRENCY - 每个表的投影数 从 Vertica 7.2.x 开始,您可以指定表恢复的顺序。有关更多信息,请参阅 Vertica 文档中的 优先考虑表恢复。 |
| Check table list and move to READY state | If the list of tables that need recovery is now empty, Vertica changes the node state from RECOVERING to READY. If the list is not empty, Vertica retries the steps for recovery up to 20 times. If these repeated attempts fail, node recovery fails and the node state changes to DOWN. 如果待恢复表列表现在为空,Vertica 会将节点状态从 RECOVERING 更改为 READY。 如果列表不为空,Vertica 会重试恢复步骤最多 20 次。如果这些重复尝试失败,节点恢复将失败,节点状态将更改为 DOWN。 |
| Move to UP state | In the final step of the recovery phase, Vertica changes the state of the node from READY to UP. From this point, the recovering node accepts new connections and participates in all database plans. 在恢复阶段的最后一步,Vertica 将节点的状态从 READY 更改为 UP。从此时起,恢复节点将接受新连接并参与所有数据库计划。 |
3.1 表恢复步骤
3.1.1 重演 Catalog 事件
恢复节点重演待恢复表在节点处于 DOWN 状态时错过的 Catalog 事件。恢复节点检查恢复表的以下 Catalog 事件:
- Truncate table
- Add column
- Rebalance table
- Alter partition
- Drop partition
- Restore table
- Move partition
- Swap partition
- Database rollback
- Replace node
- Merge projection
3.1.2 历史恢复阶段
对于每个投影,Vertica 都会保留每个节点的 Checkpoint Epoch。Checkpoint Epoch 表示所有数据存储在磁盘上的时间点。
待恢复表上的 Projection 会恢复遗漏的历史数据。在此阶段,Vertica 会从 Projection 的 Checkpoint Epoch 恢复到当前 Epoch 的数据。数据恢复有三种方法:
- 如果投影的 Checkpoint Epoch 为 0,则节点使用按容器恢复方法恢复投影数据。在按容器恢复方法中,恢复节点会复制存储容器并从伙伴节点中删除向量。
- 如果投影的 Checkpoint Epoch 不为 0,则 Vertica 使用增量方法恢复投影数据。使用增量方法,Vertica 首先扫描伙伴投影的存储容器以获取所需的投影数据。然后,投影数据会根据需要进行排序,并写入恢复节点上的磁盘。增量方法仅恢复存储容器。
- 如果在故障节点停机时提交了任何删除向量,则使用 incremental-replay-delete 方法按照增量方法恢复删除向量。
Vertica 在历史恢复阶段不获取任何锁。
3.1.3 脏事务恢复
使用 RecoveryDirtyTxnWait 配置参数来控制故障节点等待脏事务提交的时间。
- 有时故障节点在恢复时会发现未提交的脏事务。默认情况下,节点会等待五分钟以提交这些事务。五分钟后,Vertica 恢复过程将终止所有未提交的脏事务。
- 脏事务提交后,故障节点将恢复通过脏事务加载的数据。Vertica 可以使用增量和 incremental-replay-delete 方法在此阶段进行数据恢复。在脏事务阶段不会获取任何锁。
3.1.4 Replay Delete 阶段
因为是不停业务进行节点恢复,所以在节点恢复期间,业务上可能会产生数据删除操作,且步骤 2 和 3 不会持有锁。
但是,在节点进入 RECOVERING 状态后启动的删除操作不会在恢复节点上创建删除向量。
Vertica 在 Replay Delete 阶段恢复那些丢失的删除向量。在此阶段,Vertica 持有恢复表的 T 锁,并使用 incremental-replay-delete 方法恢复丢失的删除向量。在此阶段,恢复节点还确定表在 Catalog 事件的最后一次重演中是否存在任何差异。如果恢复节点发现丢失的事件,则此表的恢复失败,并将表标记为“恢复失败”。然后,恢复节点将从步骤 1 开始在失败的表上重试整个表恢复过程。
Vertica 最多允许 20 次恢复尝试,然后节点恢复将失败。
3.1.5 完成表恢复
成功完成上述步骤后,Vertica 将表标记为已恢复,并将表从需要恢复的表清单中移出。从此时起,已恢复的表将参与所有 DDL 和 DML 操作。
3.2 表恢复案例
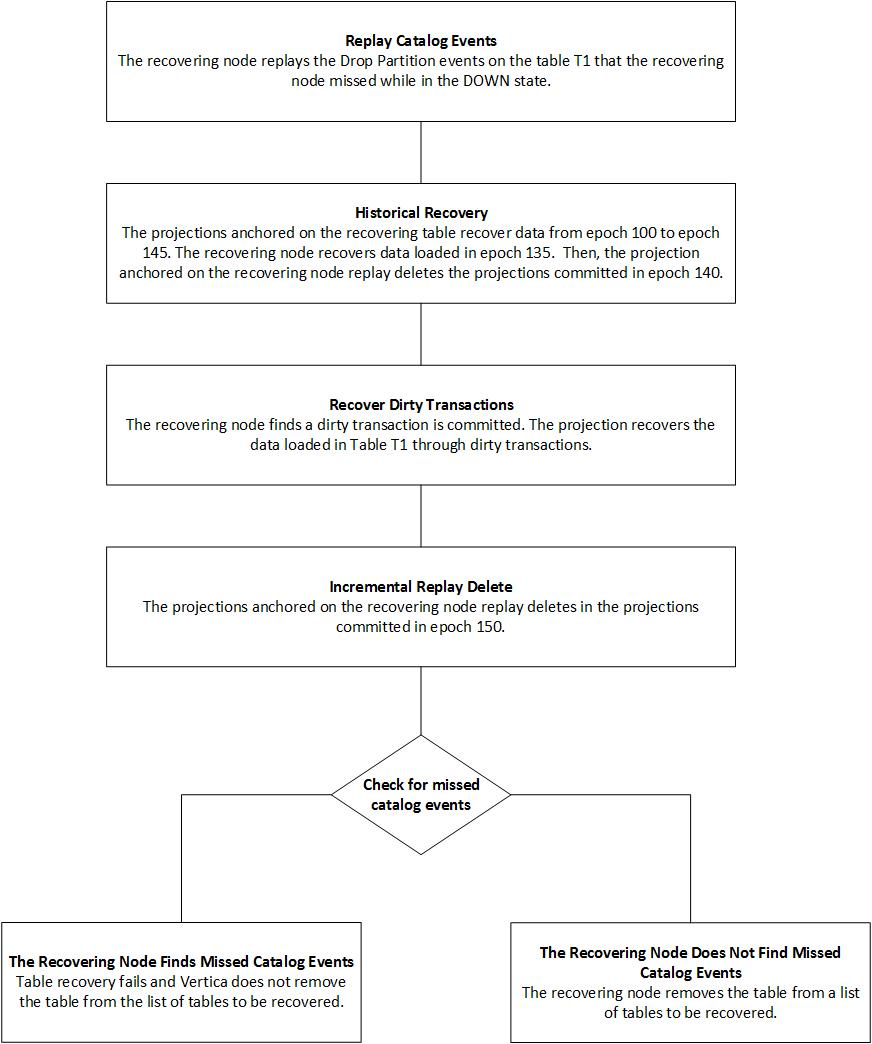
场景:
您有一个包含表 T1 的 6 节点集群。节点 5 在 epoch 100 时宕机。节点 5 宕机时,表 T1 的在该节点上的投影的 CheckPoint Epoch 为 99。
假设:
当节点 5 处于宕机状态时,Vertica 在表 T1 上执行了以下事务:
- 在 epoch 125 删除了表 T1 的分区。
- 在 epoch 135 加载了数据到表 T1 中。
- 在 epoch 140 从表 T1 中删除数据。
重新启动节点 5,并在 epoch 145 时节点的状态变为 RECOVERING。当节点进入 RECOVERING 状态时,Vertica 记录了一个脏事务,该事务往表 T1 中加载了数据。在脏事务恢复阶段,在 epoch 150 从表 T1 中删除了数据。
下图提供了表恢复不同步骤的详细信息:
4、监控节点恢复
当节点处于 DOWN 状态时,要监控恢复过程,请执行以下步骤:
4.1 通过运行以下命令来识别正在恢复的节点的状态
$ /opt/vertica/bin/admintools -t view_cluster DB | Host | State -----------+--------------+------------ mydatabase | 112.17.31.10 | UP mydatabase | 112.17.31.11 | UP mydatabase | 112.17.31.12 | INITIALIZING mydatabase | 112.17.31.17 | UP
4.2 如果节点状态为 DOWN 或 INITIALIZING,则使用 tail startup.log 监控恢复节点的进度
$ tail -f catalog-path/database-name/v_database-name_node_catalog/startup.log
在节点恢复期间,Vertica 会更新恢复节点的 startup.log。这些更新采用 JSON 信息块的形式,显示以下内容:
{
"goal" : 477688606,
"node" : "v_newdb2_node0003",
"progress" : 146732903,
"stage" : "Read DataCollector",
"text" : "Inventory files (bytes)",
"timestamp" : "2016-03-16 17:28:32.016"
}
请注意,当节点的状态为 DOWN 或 INITIALIZING 时,系统表 TABLE_RECOVERY_STATUS、TABLE_RECOVERIES 和 PROJECTION_RECOVERIES 中有关该节点的恢复状态不可用。
4.3 当节点状态为 RECOVERING 时,使用系统表跟踪节点的进度
要查看汇总状态,请运行以下查询:
=> SELECT * FROM TABLE_RECOVERY_STATUS;
要查看 TABLE 和 PROJECTION 恢复详细信息,请运行以下查询:
=> SELECT * FROM TABLE_RECOVERIES;
=> SELECT * FROM PROJECTION_RECOVERIES;
例如,如果采用按容器恢复的方式,在历史恢复阶段,您预计会在恢复系统表中看到以下内容。有关恢复阶段和恢复方法的详细信息分别显示在系统表 TABLE_RECOVERIES 和 PROJECTION_RECOVERIES 中。
=> SELECT * FROM TABLE_RECOVERIES;
node_name | table_oid | table_name | status | phase | thread_id | start_time | end_time | recover_priority | recover_error | is_historical
-----------+-------------------+------------+------------+------------+--------------+-------------------------------+----------+----------------------+-----------------+----------------
node02 | 45035996273819958 | public.t1 | recovering | historical | 7f3abf7fe700 | 2018-04-22 21:41:25.134359-04 | | -9223372036854775807 | | f
(1 row)
=> SELECT * FROM PROJECTION_RECOVERIES;
node_name | projection_id | projection_name | transaction_id | statement_id | method | status | progress | detail | start_time | end_time | runtime_priority
-----------+-------------------+-----------------+-------------------+--------------+-----------------------+----------+----------+-----------------+-------------------------------+-------------------------------+--------------------
node02 | 45035996273820032 | public.t1_b0 | 49539595901075518 | 1 | recovery-by-container | finished | | | 2018-04-22 21:41:25.146027-04 | 2018-04-22 21:41:25.166691-04 |
node02 | 45035996273820042 | public.t1_b1 | 49539595901075517 | 1 | recovery-by-container | running | | CopyStorage:0/0 | 2018-04-22 21:41:25.145689-04 | |
(2 rows)
如果恢复采用增量方式,系统表PROJECTION_RECOVERIES会显示以下内容:
=>SELECT * FROM PROJECTION_RECOVERIES;
node_name | projection_id | projection_name | transaction_id | statement_id | method | status | progress | detail | start_time | end_time | runtime_priority
-----------+-------------------+-----------------+-------------------+--------------+-------------+---------+----------+--------------------------+-------------------------------+----------+------------------
node02 | 45035996273824238 | public.t1_b1 | 49539595901075634 | 1 | incremental | running | 0 | Scan:0% Sort:0% Write:0% | 2018-04-22 21:42:07.151166-04 | |
node02 | 45035996273824228 | public.t1_b0 | 49539595901075633 | 1 | incremental | running | 0 | Scan:0% Sort:0% Write:0% | 2018-04-22 21:42:07.151473-04 | |
(2 rows)
当应用增量重放删除时,系统表 PROJECTION_RECOVERIES 可以提供以下详细信息:
=>SELECT * FROM PROJECTION_RECOVERIES;
node_name | projection_id | projection_name | transaction_id | statement_id | method | status | progress | detail | start_time | end_time | runtime_priority
-----------+-------------------+-----------------+-------------------+--------------+---------------------------+----------+----------+------------+-------------------------------+----------------------------------------------+------------------
node02 | 45035996273824238 | public.t1_b1 | 49539595901075634 | 1 | incremental-replay-delete | finished | | | 2018-04-22 21:42:07.151166-04 | 2018-04-22 21:42:11.976041-04 |
node02 | 45035996273824228 | public.t1_b0 | 49539595901075633 | 1 | incremental-replay-delete | running | 46 | Delete:0/4 | 2018-04-22 21:42:07.151473-04 | |
(2 rows)
当节点恢复进入脏事务恢复阶段时,系统表TABLE_RECOVERIES会捕获该阶段列的变化:
=> SELECT * FROM TABLE_RECOVERIES;
node_name | table_oid | table_name | status | phase | thread_id | start_time | end_time | recover_priority | recover_error | is_historical
-----------+-------------------+------------+------------+------------------+--------------+-------------------------------+------------------------------+----------------------+---------------+---------------------------
node02 | 45035996273825192 | public.t1 | recovering | historical dirty | 7f159f7fe700 | 2018-04-25 15:46:13.096937-04 | | -9223372036854775807 | | f
node02 | 45035996273825196 | public.t2 | recovered | | 7f16037fe700 | | 2018-04-25 15:46:13.09384-04 | -9223372036854775807 | |
(2 rows)
当节点恢复进入重播删除阶段时,您预计会看到阶段列成为 TABLE_RECOVERIES 系统表中当前的重播删除:
=>SELECT * FROM TABLE_RECOVERIES;
node_name | table_oid | table_name | status | phase | thread_id | start_time | end_time | recover_priority | recover_error | is_historical
-----------+-------------------+------------+------------+-----------------------+--------------+-------------------------------+----------+----------------------+---------------+---------------
node02 | 45035996273826218 | public.t1 | recovering | current replay delete | 7f60faffd700 | 2018-04-25 15:46:38.130421-04 | | -9223372036854775807 | | f
(1 row)
=> SELECT * FROM PROJECTION_RECOVERIES;
node_name | projection_id | projection_name | transaction_id | statement_id | method | status | progress | detail | start_time | end_time | runtime_priority
-----------+-------------------+-----------------+-------------------+--------------+---------------------------+----------+----------+------------+-------------------------------+----------------------------------------------+------------------
node02 | 45035996273826230 | public.t1_b1 | 0 | | | queued | | | | |
node02 | 45035996273826230 | public.t1_b1 | 49539595901075718 | 1 | incremental | finished | | | 2018-04-25 15:46:38.142405-04 | 2018-04-25 15:46:38.168844-04 |
node02 | 45035996273826220 | public.t1_b0 | 49539595901075719 | 1 | incremental | finished | | | 2018-04-25 15:46:38.142025-04 | 2018-04-25 15:46:38.168814-04 |
node02 | 45035996273826220 | public.t1_b0 | 49539595901075725 | 2 | incremental-replay-delete | running | 20 | Delete:0/4 | 2018-04-25 15:46:38.285413-04 | |
(4 rows)
4.4 在某些情况下会发生恢复失败。
恢复失败的四个常见原因可能是由于并发 DML 或 DDL 导致无法在重播删除阶段获取 T 锁、无法停止脏事务、无法应用目录事件以及检测到丢失的目录事件。如果节点状态为 RECOVERING 或 UP ,有两种方法可以检查正在恢复的节点上的恢复故障。一种是检查 TABLE_RECOVERIES 系统表中的 recover_error 列。例如,应用目录事件失败可能会在 TABLE_RECOVERIES 中显示,如下所示:
=>SELECT * FROM TABLE_RECOVERIES;
node_name | table_oid | table_name | status | phase | thread_id | start_time | end_time | recover_priority | recover_error | is_historical
-----------+-------------------+------------+-------------+-------+--------------+-------------------------------+-------------------------------+----------------------+--------------------+---------------
node04 | 45035996273845482 | public.t2 | error-retry | | 7f3551ffb700 | 2018-02-21 10:40:17.887369-05 | 2018-02-21 10:57:52.290204-05 | -9223372036854775807 | Event apply failed | t
node04 | 45035996273845460 | public.t1 | error-retry | | 7f35517fa700 | 2018-02-21 10:40:17.887322-05 | 2018-02-21 10:57:52.801538-05 | -9223372036854775807 | Event apply failed | t
(2 rows)
检查恢复失败并重试恢复节点的另一种方法是在 vertica.log 文件中使用以下关键字运行 grep 命令:
$ grep "incrCatchUpFailureCount" vertica.log
如果由于恢复失败而导致节点关闭,则只能依靠第二种方法来排查恢复失败的原因。
5、节点恢复故障处理
以下列表描述了最常见的故障排除用例和解决问题的建议:
5.1 案例一
症状:Spread 守护程序无法启动并连接到 Vertica。
描述:如果 Spread 守护程序无法启动,则节点恢复失败,并且恢复节点继续处于 DOWN 状态。
操作:检查恢复节点的 startup.log 文件或 vertica.log 文件。一些可能的解决方案如下:
- 验证恢复节点的 Catalog 目录中的 spread.conf 文件是否与集群中其他节点上的所有 spread.conf 文件相同。
- 验证 Catalog 目录中的 spread.conf 文件中恢复节点的 IP 地址是否正确。
- 从临时 (/tmp) 目录中删除文件 4803 并重新启动节点。
5.2 案例二
症状:恢复节点在恢复前阶段的“检查数据存储”阶段花费了异常长的时间。
描述:如果出现以下情况,恢复节点在恢复前阶段可能会花费异常长的时间:
- Catalog 很大,并且包含数百万个 ROS 文件。
- 恢复节点必须删除 Catalog 未引用的大量 ROS 文件。
操作:使用 startup.log 文件监控节点恢复进度。
5.3 案例三
症状:恢复节点出现错误并失败。
描述:错误消息为"Data consistency problems found; startup aborted."。
操作:要解决此问题,请使用 --force 标志从 admintools CLI 重新启动节点:
$ /opt/vertica/bin/admintools -t restart_node -d <database_name> --hosts <ip address> --force
5.4 案例四
症状:恢复节点正在等待加入集群的邀请。
描述:在以下情况下,恢复节点无法与集群中的其他节点通信,并且正在等待其他节点加入集群的邀请:
- 防火墙已启用或端口被阻止。
- 恢复节点属于不同的子网。
操作:要解决这些问题,请执行以下任务: - 使用
netcat [$ nc]验证与集群中其他节点的通信 - 如果恢复节点与集群中的其他节点属于不同的子网,请以点对点模式配置传播。
5.5 案例五
症状:由于 Catalog 事件,表恢复多次失败。
描述:对当前正在恢复的表执行如下操作(例如 TRUNCATE TABLE 或 DROP PARTITION)可能会导致表恢复失败。如果表在 20 次尝试后仍无法恢复,则 Vertica 恢复失败。多次失败的恢复尝试可能会延迟节点恢复。
操作:要解决此问题,请执行以下任务:
- 要跟踪恢复尝试,请使用以下命令:
$ grep "incrCatchUpFailureCount" vertica.log
例如,以下消息表明,Vertica 尝试了 17 次恢复节点。
[Recover] <INFO> incrCatchUpFailureCount: 17 failures, max 20- 如果您注意到上述步骤中有多次重试尝试,请停止积极执行目录事件的 ETL 进程。
5.6 案例六
症状:UPDATE 和 DELETE 语句运行时间异常长。
描述:如果恢复节点无法在恢复表上获取 T 锁超过五分钟,则表恢复失败。五分钟是 LOCKTIMEOUT 配置参数的默认设置。如果表在 20 次尝试后仍无法恢复,则 Vertica 恢复失败。多次失败的恢复尝试可能会延迟节点恢复。
操作:要解决此问题,请执行以下任务:
- 要跟踪恢复尝试,请使用以下命令:
$ grep “incrCatchUpFailureCount” vertica.log - 取消长时间运行的 DML 操作。

