




1、Vertica 和低延迟使用场景
Vertica 通常用于运行时间较长的分析查询。但是,您还可以使用 Vertica 处理低延迟应用场景,其查询通常在十秒内运行。低延迟查询通常用于用户需要实时或接近实时响应的情况,例如使用仪表板应用程序的用户。
通常,低延迟应用程序也具有高并发要求。在这种情况下,Vertica 集群的吞吐量(以每秒查询数衡量)是需要着重关注的指标。
请参考本文档中的建议来进行优化。
2、平台和硬件建议
对于低延迟应用场景,建议使用裸机或物理硬件,不建议使用虚拟机。
虚拟机和云平台并不是低延迟应用场景的理想平台。虚拟化软件在运行 Vertica 所需的软件堆栈中添加了另一层。该堆栈中的每一层都会增加延迟。因此,堆栈中的层数越少越好。
为了实现低延迟,请使用尽可能少的节点数,但至少需要三个节点才能保持容错能力。
有关 VMWare 和调整延迟敏感工作负载的详细信息,请参阅 vSphere VM 中延迟敏感工作负载性能调整的最佳实践。
2.1 存储建议
使用企业级直连存储而不是存储区域网络 (SAN)。这样做通常会加快数据检索速度。使用 SAN 存储可能会增加查询延迟。
2.2 硬件设置
对于金属裸设备,请在 Windows 操作系统上配置 BIOS 以获得最佳性能,如以下步骤所述:
1、系统配置 > BIOS/平台配置 (RBSU) > 电源管理 > 电源配置文件。
2、选择最高性能。
3、在 /etc/grub.conf 文件中,通过在命令行中附加以下内容来修改内核条目:
Intel_idle.max_cstate=0 processor.max_cstate=0.
2.3 在 Amazon Web Services (AWS) 上使用 Vertica 的建议
不建议在云平台上部署 Vertica 来实现低延迟应用场景。如果您选择 AWS 等云平台,以下是您应该遵循的一些最佳实践。
AWS 提供两种存储选项:
- 弹性块存储(Elastic Block Store, EBS)
- Ephemeral storage(临时存储)
EBS 存储与 SAN 存储一样,不是本地的,而临时存储是(Ephemeral storage)实例的本地存储。对于低延迟应用程序,您应该使用临时存储(Ephemeral storage)。从临时存储写入或读取数据比 EBS 存储更快,因为存储距离实例更近。有关 AWS 最佳实践的更多信息,请参阅《Vertica on Amazon Web Services 指南》。
虽然 AWS 最佳实践建议用户使用 8 磁盘、EBS 软件 Raid-0 阵列,但这对于低延迟查询来说并不理想。使用单个 EBS 卷可以实现更低的延迟。
按如下优先级顺序选择存储类型:
- Ephemeral storage(临时存储)
- 单个EBS卷
- 8 磁盘、EBS 软件 Raid-0 阵列
2.4 vnetperf 工具
使用 vnetperf 工具来测试主机的网络性能。该工具可以测量网络延迟。对于低延迟查询,最大 RTT(往返时间)延迟为 200 微秒。您可以通过最小化网络跃点数来最小化 RTT 延迟。
vnetperf 工具测试结果的示例如下:
test | date | node | index | rtt latency (us) | clock skew (us)
latency| 2015-06-18_11:33:28,873| 10.54.10.227| 1 | 182 | 55
latency| 2015-06-18_11:33:28,873| 10.54.10.228| 2 | 183 | -98
3、单节点查询
您可以设计工作负载以使用单节点查询来帮助实现低延迟。要使用单节点查询,您必须以不同的方式设计投影和查询谓词。
如果您使用单节点查询,则使用尽可能少的节点数的建议不适用。 下图显示了如何在包含所需数据的单节点上高效执行查询。
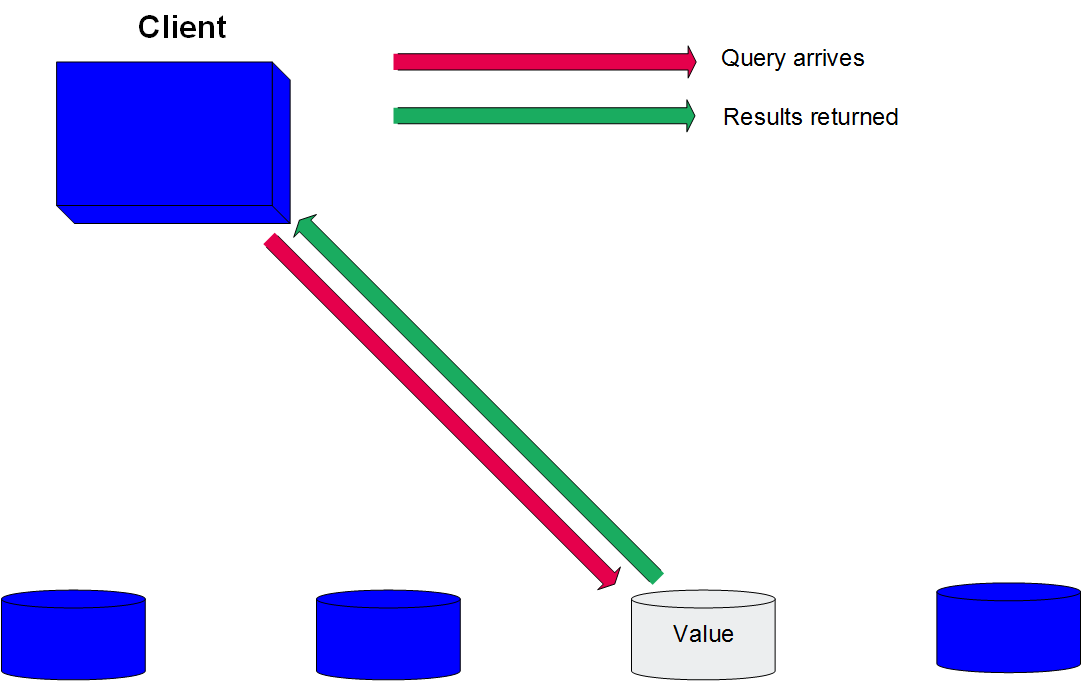
4、查询优化
您可以使用以下任一方法优化查询以实现更低的延迟:
- 使用 WHERE 子句。投影的排序顺序必须与 WHERE 子句匹配。有关详细信息,请参阅 Vertica 文档中的选择排序顺序:最佳实践。
- 在投影定义子句中使用适当的分段来最小化节点之间的网络流量,并使所有节点均等加载。
- 只要在查询中需要大型聚合 (GROUP BY),就可以使用实时聚合投影(live aggregate projections)。有关详细信息,请参阅 Vertica 文档中的创建实时聚合投影。
- 使用宽表优化数据库的连接性能。宽表会增加存储占用空间。然而,它通过减少关联从而降低了延迟。
5、应用配置
您可以使用以下方法配置 Vertica 数据库以实现更低的延迟:
- 使用 JDBC 连接池可以减少客户端和服务器之间重复打开网络连接的开销。为每个请求打开一个新连接需要时间且成本高昂。当请求传入时,Vertica 会将请求分配给池中预先存在的连接。如果没有空闲连接,Vertica 将创建一个新连接。当请求完成时,连接返回到池中,等待另一个请求。使用 JDBC 连接池可以消除每次发出新请求时验证连接所需的时间。这降低了查询的延迟,因为它减少了连接所需的时间。
- 如果您有终止空闲 TCP 连接的中间防火墙或负载平衡设备,请禁用空闲连接终止。位于客户端和数据库之间的防火墙或其他网络硬件会增加延迟。
- 在非工作时间或非高峰负载时间加载数据。数据加载后,运行 ANALYZE_STATISTICS 函数以使表统计信息保持最新。在非工作时间运行数据加载可以防止对低延迟查询的干扰。
- 在低延迟查询未运行时运行更新、删除和 ETL 作业。
- 使用本机连接负载平衡在集群中的所有节点之间均匀分布数据。这样做有助于防止主机因客户端连接数量过多而造成负担。有关详细信息,请参见 Vertica 文档中的关于本机连接负载平衡。
6、资源管理
资源管理器控制系统资源以提供稳定且可预测的结果。资源管理器使用资源池来灵活管理查询可用的资源。
6.1 资源池参数
在低延迟应用场景应减少查询使用的线程数。返回少量行的低延迟查询可以通过较少的并行性(较少的线程)执行更好的性能。 EXECUTIONPARALLELISM 配置参数控制用于处理任何单个查询的线程数。
您还可以通过限制为每个查询分配的内存量来降低延迟。您通常可以将此方法用于使用哈希运算符(例如 JOIN 和 GROUPBY)的查询。 PLANNEDONCURRENCY 配置参数控制查询内存预算。您应该为查询提供理想性能所需的确切内存量。您可以计算低延迟查询需要多少内存。然后,在一个小范围内尽可能准确地设置资源池内存。
如果您系统的 CPU 为性能瓶颈,则应该设置并发的硬性上限。此限制应等于或小于 Vertica 节点上的处理器数量。调整 EXECUTIONPARALLELISM 和 PLANNEDCONCURRENCY 的值,使两个值的乘积等于或小于可用物理 CPU 的数量。
6.2 内存管理
MEMORYSIZE 参数控制该资源池可用的最小内存量(独占内存)。可将该值设置为接近实际所需的内存量。还可以设置 MAXMEMORYSIZE 值来控制资源池通过从 GENERAL 池借用内存可以增长的最大大小。应将 MEMORYSIZE 和 MAXMEMORYSIZE 值设置在尽可能接近低延迟查询所需的实际内存的范围内。
在某些情况下,两个查询都需要内存或其他资源。为了获得最佳结果,您应该将低延迟查询场景分配给具有较高优先级的资源池。
在 Vertica 中,查询在执行的前两秒内获得最高的优先级。您可以通过更改运行低延迟查询的资源池的 RUNTIMEPRIORITYTHRESHOLD 来更改两秒优先级时间。
但是,仅针对低延迟查询才这样做;在其他场景中请勿更改 RUNTIMEPRIORITYTHRESHOLD。
6.3 案例
以下是使用本文档中讨论的概念来调整低延迟的典型过程的示例。要正确调整,您应该创建一个综合基准,以便在该过程的每个步骤中,您都可以验证调整参数对查询基准的影响。
使用如下场景。 meter_data 表包含住宅客户用电量的时间点。
DROP TABLE meter_data cascade;
CREATE TABLE meter_data
(
data_id int NOT NULL,
meter_id char(32) NOT NULL,
reading_ts timestamp NOT NULL,
reading_value float NOT NULL
)
;
CREATE PROJECTION meter_data_p1
(
data_id,
meter_id,
reading_ts,
reading_value
)
AS
SELECT data_id,
meter_id,
reading_ts,
reading_value
FROM meter_data
ORDER BY reading_ts
SEGMENTED BY HASH(meter_id) ALL NODES KSAFE 1;
/*
COPY meter_data FROM '/home/skeswani/mem_mgmt/data1.txt.bz2' BZIP;
COPY meter_data FROM '/home/skeswani/mem_mgmt/data2.txt.bz2' BZIP;
COPY meter_data FROM '/home/skeswani/mem_mgmt/data3.txt.bz2' BZIP;
*/
以下是资源调整示例所需的初始设置:
DROP RESOURCE POOL dashboard_pool;
CREATE RESOURCE POOL dashboard_pool;
CREATE USER dashboard_user;
GRANT USAGE ON RESOURCE POOL dashboard_pool TO dashboard_user;
ALTER USER dashboard_user RESOURCE POOL dashboard_pool;
GRANT ALL on meter_data TO dashboard_user;
以下查询是从 Web 仪表板运行的。此查询显示给定日期的最高仪表读数,并呈现一个图表,显示该日期和时间的峰值使用情况。
SELECT reading_ts, reading value
FROM meter_data
WHERE reading_ts between '2005-05-01' and '2005-05-02'
ORDER BY reading_value desc limit 1;
以下是一个综合并发查询基准测试,用于验证本示例中的资源池调整。
该基准测试同时运行 15 个查询,就像 Web 仪表板一样。在调整资源池时,您应该在每次更改后重新运行基准测试,以验证每个步骤运行工作负载的总持续时间是否更好。持续时间以第一个查询开始和最后一个查询结束之间的时间来衡量。
[username@ip-address mem_mgmt]$ cat benchmark.sh
#!/bin/bash
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-01' and '2005-05-02' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-02' and '2005-05-03' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-03' and '2005-05-04' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-04' and '2005-05-05' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-05' and '2005-05-06' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-06' and '2005-05-07' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-07' and '2005-05-08' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-08' and '2005-05-09' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-09' and '2005-05-10' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-10' and '2005-05-11' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-11' and '2005-05-12' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-12' and '2005-05-13' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-13' and '2005-05-14' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-14' and '2005-05-15' order by reading_value desc limit 1;" &
vsql -U dashboard_user -c "select /* +label(dashboard) */ reading_ts, reading_value from meter_data where reading_ts between '2005-05-15' and '2005-05-16' order by reading_value desc limit 1;" &
wait
SELECT count(*),
min(start_timestamp),
max(end_timestamp),
(max(end_timestamp)-min(start_timestamp))SECOND(3) duration
FROM query_requests WHERE request_label='dashboard';
count | min | max | duration
-------+-------------------------------+-------------------------------+----------
15 | 2015-11-12 11:36:45.062353-05 | 2015-11-12 11:36:46.425296-05 | 1.363
示例中进行了以下调整:
投影经过优化,可以在 EXECUTIONPARELLELISM=1 时运行得更快:
ALTER RESOURCE POOL dashboard_pool EXECUTIONPARALLELISM 1;
由于仪表板一次显示 15 天的峰值使用情况,因此预计我们可以一次运行 15 个查询并期望快速响应:
ALTER RESOURCE POOL dashboard_pool PLANNEDCONCURRENCY 15;
对查询进行分析以查看它需要多少内存:
Profile select reading_ts, reading value from meter data where reading_ts between '2005-05-13' order by reading_value desc limit 1;
NOTICE 4788: Statement is being profiled
HINT: Select * from v_monitor.execution_engine_profiles where transaction_id=45035996273715510 and statement_id=1;
NOTICE 3557: Initiator memory for query: [on pool general: 127093 KB, minimum: 127093 KB]
NOTICE 5077: Total memory required by query: [127093 KB]
该查询使用了 128 MB 内存,因此内存范围最小分配为 128MB,上限为 256MB。但是,如果需要,查询可以从 general 池中借用更多。
MEMORYSIZE 和 MAXMEMORYSIZE 值是通过将查询的内存大小乘以计划并发数(分别为 128x15 和 256x15)来计算的。
ALTER RESOURCE POOL dashboard_pool MEMORYSIZE '1920M';
ALTER RESOURCE POOL dashboard_pool MAXMEMORYSIZE '3840M';
赋予资源池最高的优先级:
ALTER RESOURCE POOL dashboard_pool PRIORITY 100;
对于本示例,节点上有 32 个 CPU。限制 MAXCONCURRENCY 以免 CPU 过载。
ALTER RESOURCE POOL dashboard_pool MAXCONCURRENCY 32;
7、其他建议
执行以下任务以获得低延迟应用场景的最佳性能:
- 对于多次使用同一视图的查询,请使用 WITH 子句。这种方法可能有助于提高低延迟场景性能。
- 改写SQL将口径扁平化。如果低延迟查询不包含子查询,则性能会更好。 Vertica 尝试扁平化这些查询。查看查询计划以查看查询是否被扁平化。如果查询未扁平化,则重写查询并扁平化它可能有助于实现低延迟。
- 保证表上的统计数据是最新的。只有准确的统计信息才能使优化器为查询做出最佳的执行计划。

