





在科学研究中,文献调研是至关重要的环节。根据美国国家科学基金会的统计,科研人员花费在查找和消化科研资料上的时间占全部科研时间的 51%。尽管查阅式和搜索式检索仍是主流方法,但随着大语言模型的快速发展,越来越多的人开始利用人工智能方法进行文献调研。
作为 AI for Science 基础设施的“替代文献的数据库与知识库”的创新项目之一,Science Navigator 1.0 由北京科学智能研究院、墨奇科技、深势科技、中国科学院计算机网络信息中心、催化剂+ 等机构联合开发。该平台不仅极大提升了科研人员的工作效率,也为科学探索铺就了全新的路径。

从实际科研需求出发,我们发现仍有许多需求未被满足。例如,学科交叉已成为常态,这使得我们对内容交叉检索的需求更加迫切。与以往仅使用关键词检索不同,我们对内容交叉检索的要求更高。
今天的大语言模型能够有效提升检索的交叉性,但也存在一些问题,如幻觉现象和答非所问。基于科学研究的严谨性,我们对内容溯源的需求愈发强烈。因此,Science Navigator 首先需要一个强大的数据库,能够有效管理上亿篇科研文献,高效存储和索引各种类型的数据,并确保查询的准确性。在评估了不同方案后, MyScale 的优势凸显,接下来将共同剖析其优势点。
Science Navigator 对向量数据库的需求
Science Navigator 是一个面向科研人员的 RAG 知识库问答系统,旨在覆盖超过2亿篇科研文献,为高校、材料、化工、生物医药等多个行业的科研人员提供高效的专业知识获取服务,从而显著提升研究效率。为实现这一目标,我们对向量数据库提出以下需求:
数据管理
数据查询的准确性
多租户数据隔离
最后,Science Navigator 需要支持多个行业和领域的用户群体,确保各用户的数据和服务独立,互不干扰,以更好地满足不同学科背景科研人员的个性化需求。这要求底层数据库具备灵活的多租户管理功能。
为什么选择 MyScale
Science Navigator 的目标是帮助科研人员快速获取准确的科研文献,而自然语言查询是实现这一目标的重要功能。为了支持自然语言查询,我们需要依赖 Text2SQL 和 SelfQuery 的技术。MyScale 基于 ClickHouse 构建,支持完整的 SQL 语法,并提供基于 LangChain 的结构化和非结构化查询结合的 SelfQueryRetriever,完美契合我们的需求。此外,MyScale 能像传统关系型数据库一样处理结构化数据,这使得开发者可以进行复杂的 SQL 查询、聚合和分析操作,同时用户也能通过自然语言提问,提升了系统的易用性,尤其是对不熟悉 SQL 的用户而言,降低了使用门槛。
在确保查询准确性和相关性方面,除了向量搜索,我们还需要向量与结构化数据的联合搜索。MyScale 的架构能够同时存储结构化和非结构化数据,并将向量搜索与结构化数据查询无缝集成。其联合搜索功能可以处理非结构化数据及相关元数据,增强对查询语义的理解,提供更丰富的搜索能力,从而提高搜索的相关性。此外,MyScale 的多租户管理功能支持多种策略,如基于表的多租户和基于元数据的管理策略,满足我们的灵活需求。
综上所述,我们调研了市面上的专用向量数据库和增加了向量插件的传统数据库,最终只有 MyScale 满足我们的所有需求,因此我们选择 MyScale 作为 Science Navigator 的底层数据库。
我们的解决方案
数据存储
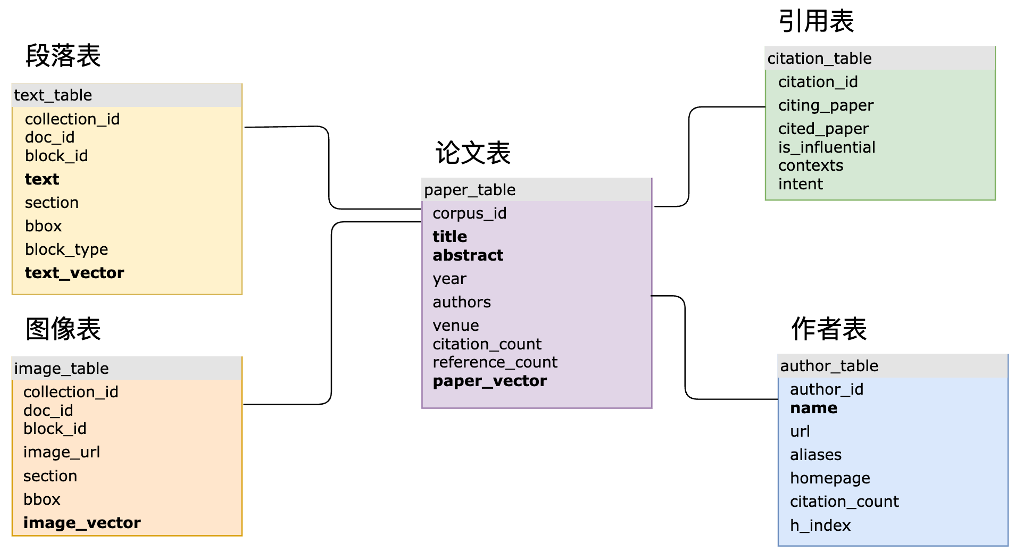
数据管理与检索
得益于 MyScale 的 SQL 支持,Science Navigator 能够将各种复杂的论文元数据存储在同一个数据库系统中。这包括论文之间的引用关系、各个学术刊物的详细信息、作者与论文之间的关联等。这种集中化的数据存储方式大大简化了数据管理流程,同时提高了查询效率。如上图所示,Science Navigator 在 MyScale 用多张关系型表格存储相关的论文数据,其中的 paper_table 保存了论文元数据,text_table 保存了 PDF 解析出来的全文数据,我们对其中的文本以及文本转成的向量创建了关键字倒排索引和向量索引。
对于从 PDF 中解析出来的图像,我们将 embedding 保存到了 image_table 中并创建向量索引。对于作者元数据的 author_table,我们只针对作者姓名创建关键字倒排索引。对于论文之间的引用关系,它们被直接保存在关系型表格 citation_table 中。
Science Navigator 的搜索功能充分利用了 MyScale 的混合搜索能力。用户可以同时使用向量搜索和关键词搜索,结合 SQL 查询来精确定位所需的学术资源。例如,可以轻松实现基于论文内容相似度、发表年份、引用次数等多维度的复杂查询。
在对话功能方面,MyScale 的 SQL 支持使得 Science Navigator 能够快速检索和组合各类相关信息,为用户提供全面而准确的回答。系统可以轻松关联论文内容、作者信息、引用网络等数据,生成深入的学术见解。
系统调优和维护
MyScale 带来的成果
大规模多模态数据存储:Science Navigator 是首个能利用嵌入向量实现对 2 亿篇论文的元数据和 300 万篇 arXiv 论文的全文内容进行语义搜索的论文检索系统。
实现大规模数据精准检索:Science Navigator 强大的自然语言对话式检索能力,能够迅速定位到科研工作者所需的精确信息,使得文献检索变得前所未有的简单和快捷。这一切得益于平台内置的 MyScale AI 数据库,与大语言模型的优势融合,等效实现了 3-6 倍参数量模型效果,训练和推理成本大幅降低。MyScale 为大模型提供了有效的记忆载体,满足科研文献知识库动态快速更新的特点,以及精准输出结果的需求,实现了低成本、高效率的信息存储,而且不占用模型空间。在 MyScale 的帮助下,Science Navigator 实现百亿级向量与海量结构化数据的毫秒级检索,使科研人员平均文献搜索时间缩短90%以上,对专业领域复杂问题仍能保持 95% 以上的问答精度。
成本控制:在兼顾高精度和高效能的前提下,MyScale AI 数据库采用独特的 MSTG 向量索引算法,将原始向量存储在 NVMe SSD 上。与纯内存的 HNSW 向量索引算法相比,内存消耗减少了 16 倍,总成本降低了 90% 以上。
Science Navigator 不仅仅是一个为科研工作者量身打造的 AI 平台,它更是一个全新的科研生态系统。从知识提取工具到前沿进展追踪工具,从科研灵感的生成器到文献综述写作工具,Science Navigator 开放了绝大部分能力的API接口,使用者可以在这个平台的基础上构建自己的应用和智能体,以满足科研复杂的个性需求。
未来,我们将继续深化与 MyScale 的合作,添加更多行业的高质量科研文献,持续优化系统系能,成为广大科研人员强大且易用的知识文献导航器。
访问 Science Navigator:https://sci-navi.com/
相关资讯

