前言
全球经济持续放缓,降本增效逐渐成为大多数客户的主要诉求。阿里云瑶池旗下的云原生数仓AnalyticDB MySQL(以下简称ADB)从一开始就提供了弹性模式供用户更方便、更省钱的使用数据库。去年ADB推出了Multi-Cluster弹性方案,优化了在线资源组的弹性模式使用体验。今年针对job资源组,进一步提出了DynamicAllocation弹性模型,能够在事前自动预估资源用量,在执行过程中智能扩缩,并基于资源热池优化弹性效率,解决了查询启动慢的问题。

某日,小张接到了老板的任务,要分析上个月的销售情况。于是小张高兴地打开了ADB控制台,准备提交一条离线查询。小张看了官网的文档后发现需要手动给查询指定资源量,但小张并不是数据库方向的专家,于是只能被迫反复查阅官网的架构介绍和资源规格说明文档,最后才小心翼翼推算出了需要的资源量。好不容易提交查询后,小张猛地发现查询迟迟不开始执行,只能提心吊胆地反复刷新页面,过了将近半分钟,查询终于开始执行了,小张擦了擦额头上的汗。又过了半个月,老板询问小张,为什么上个月数据库开支远远超出预期,小张看了看平均资源使用量,发现并不是很高,于是在百思不得其解的情况下给值班提交了工单。以上是很多客户在使用离线查询过程中遇到的共性问题,每次值班过程中总能感受到工单文字背后客户即将爆发的不满。因此,为提升客户体验,ADB推出了智能化弹性模型,并优化了弹性效率,期望能解决客户痛点问题。离线查询,适用于高吞吐场景,是OLAP数仓的主要能力之一。在ADB中,主要以job资源组的方式提供。在job型资源组中,采取了per-query的资源调度模式,即控制节点会给每条查询分配独立的资源以供使用,不同查询之间资源隔离。早先的job查询,跟很多其他产品一样,采取了用户自定义资源使用量的方式。在查询执行之前,用户需要给这条查询指定使用的资源量总大小以及资源类型。比如用户执行了总ACU是17Core,单个节点的规格是4Core,那么就会分配4个4Core的计算节点用于查询。
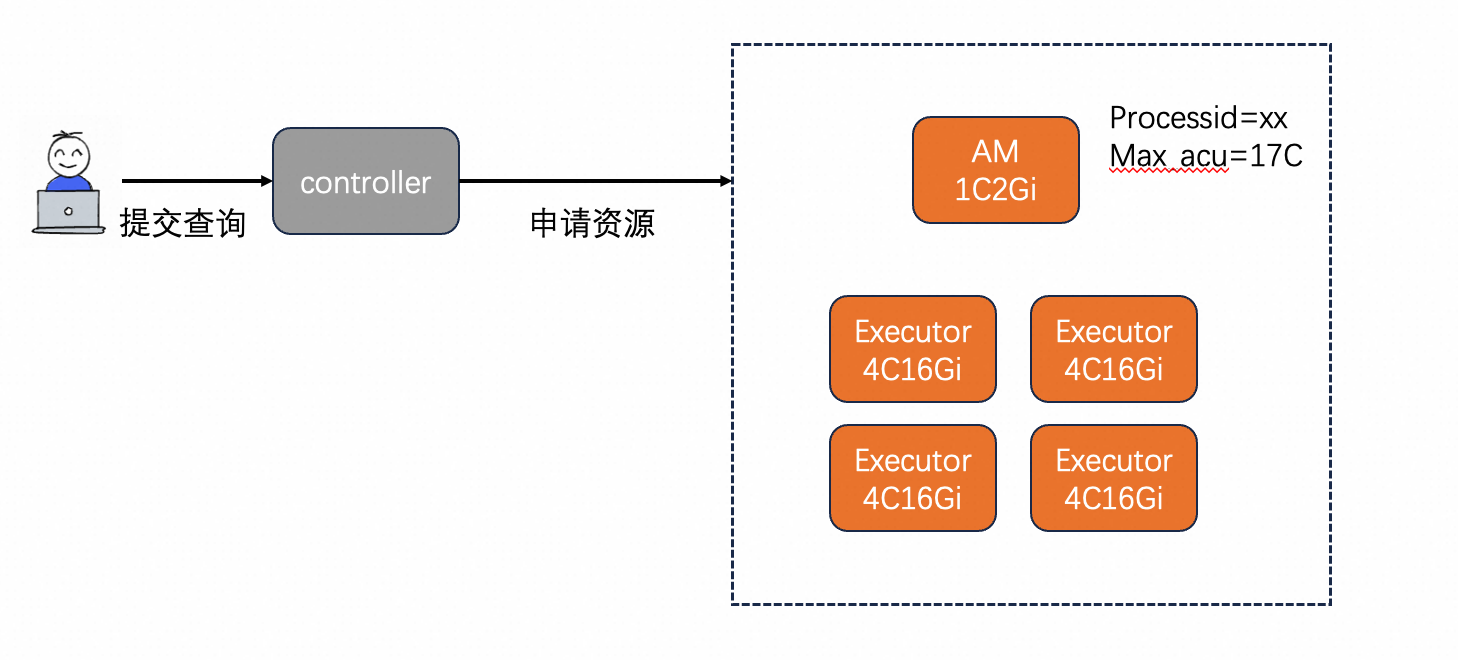
注:每条查询额外需要拉起一个1Core的AppMaster节点用于计划生成和任务调度。
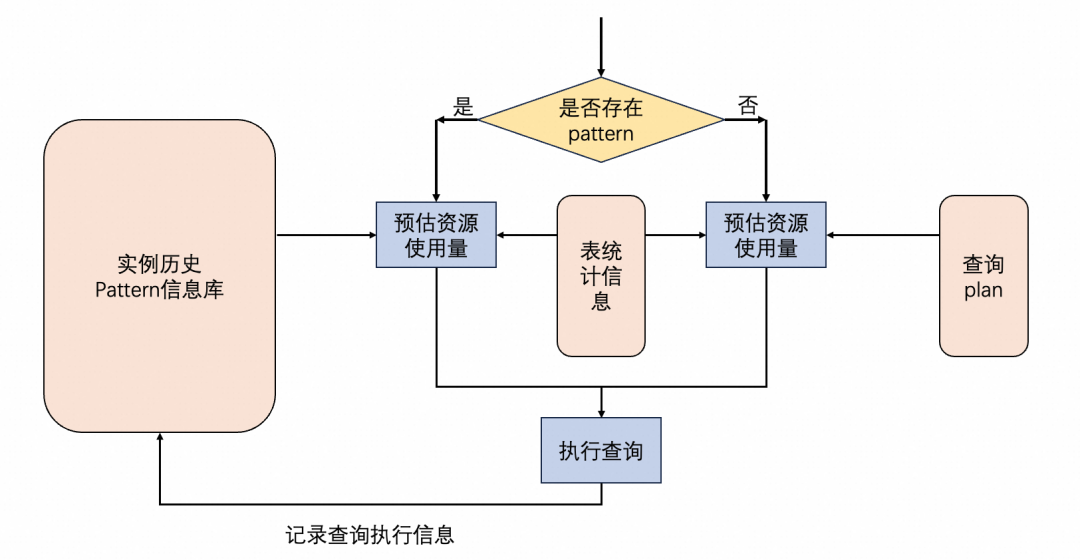
自动资源预估,又称autoWLM。会根据用户以往的查询及资源使用,训练出一个用户专属的机器学习模型。该模型是一个混合模型,会首先判断查询是否是已有pattern的查询。如果是,就根据以往的查询数据和现在的表统计信息预测资源使用量。如果不是,就会根据表统计信息和优化器解析出的查询计划来预估资源使用量。
对于未知的查询pattern,在执行过几次后,会自动记录历史pattern信息库。因此在经过几轮执行-训练的快速迭代后,新的pattern也会转化为已知的pattern,并且走左边的预估链路以便获得更好的预估效果。
使用自动资源预估后,用户不再需要手动执行查询的资源使用量,全部交给模型预估即可。动态资源申请,与原先申请完资源必须要等到查询结束才能释放的弹性模型不同,会自动的根据指定的资源使用量(模型评估 or 用户手动指定)做自动的资源伸缩。首先会计算出min最小资源使用量,step资源伸缩步长,而max最大资源使用量则是指定的资源使用量。在执行过程中,会定期做一次判断,根据此时的实际并发和负载,自动判断此时是否需要伸缩。每次伸缩以step步长为大小,保持在[min,max]的区间内。在并发或负载较低的阶段,查询并不需要持有max的资源量,只需要持有很少一部分资源。而job模式的计费会按照资源的实际使用计费,此时可以有效降低job查询的成本。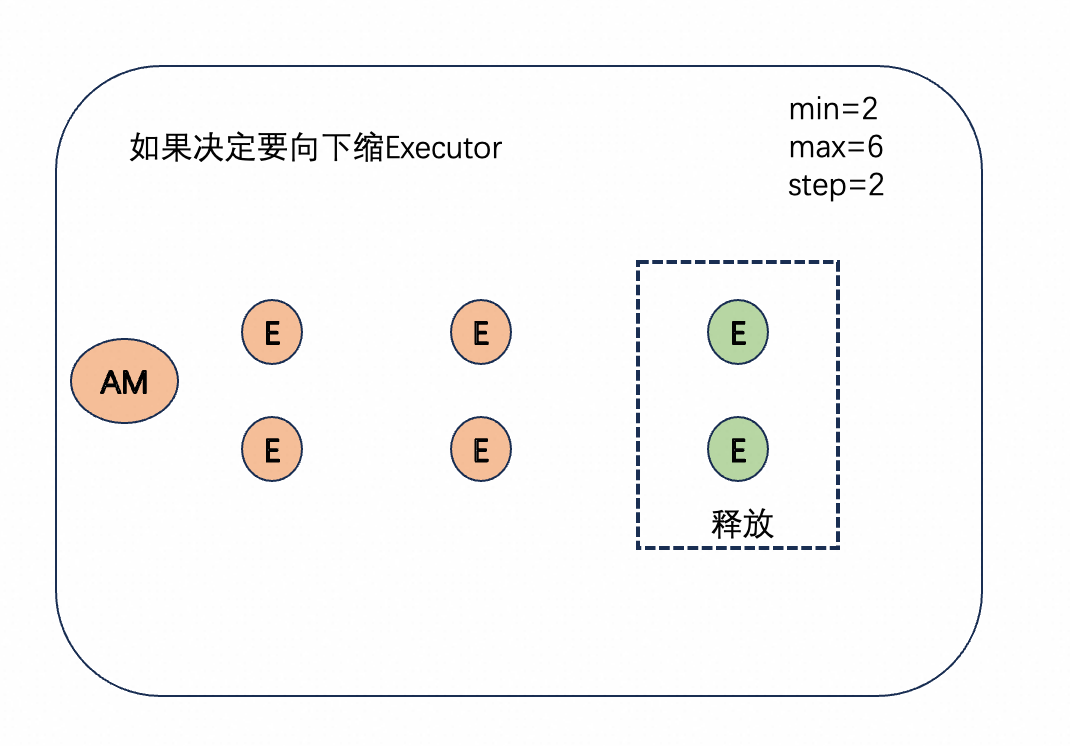
上图是一个缩容时的示意图,当判断满足缩容的条件时,会按照step的大小选择对应数量的executor,然后释放pod。在节点释放后,该节点的计费也随之暂停。▶︎ 延迟调度
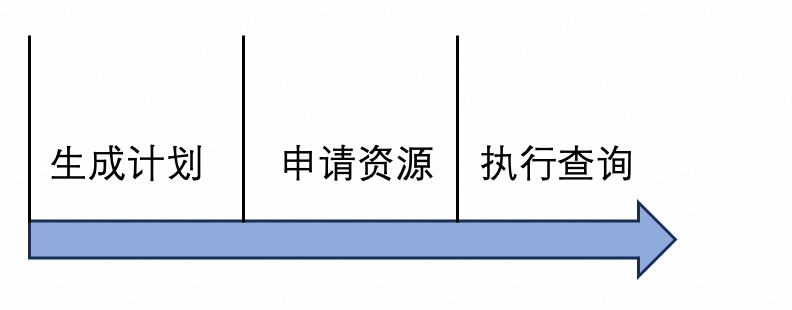
job模式默认使用Batch调度,为避免大查询的OOM问题,会强制落盘,这也导致其执行效率劣于MPP调度。对于中小查询来说,不太可能出现内存不足,而又比较看重执行效率,此时MPP调度会是更好的选择。MPP和Batch的另一个显著区别是,MPP调度为了尽可能提高节点的资源使用率,会根据节点个数切分计划,因此需要等到节点全部申请完成才能开始调度;而Batch只需要有一个节点申请完成即可开始调度。开启延迟调度后,ADB会自动根据查询的资源使用和时间预估,分辨出查询是否属于中小查询。如果是,就会自动切换到MPP调度,等到资源都申请完成后才开始调度。弹性效率是Serverless领域永远绕不开的话题。再精确再智能的资源调度,如果每次扩容或者缩容都需要大量的时间,最终的资源调度效果一定也不会很好。此外,对于job查询这种per-query的资源调度,每条查询都需要在用户提交后再申请资源,这也同样受到弹性效率的影响,如果弹性效率很低,那往往用户一条简单的点差也需要大量的时间,这无疑会影响ADB的使用体验。上图是一条job查询在提交后,在数据库内核的生命周期包括三步:生成计划、申请资源、执行查询。影响弹性效率最关键的就在于申请资源这一步。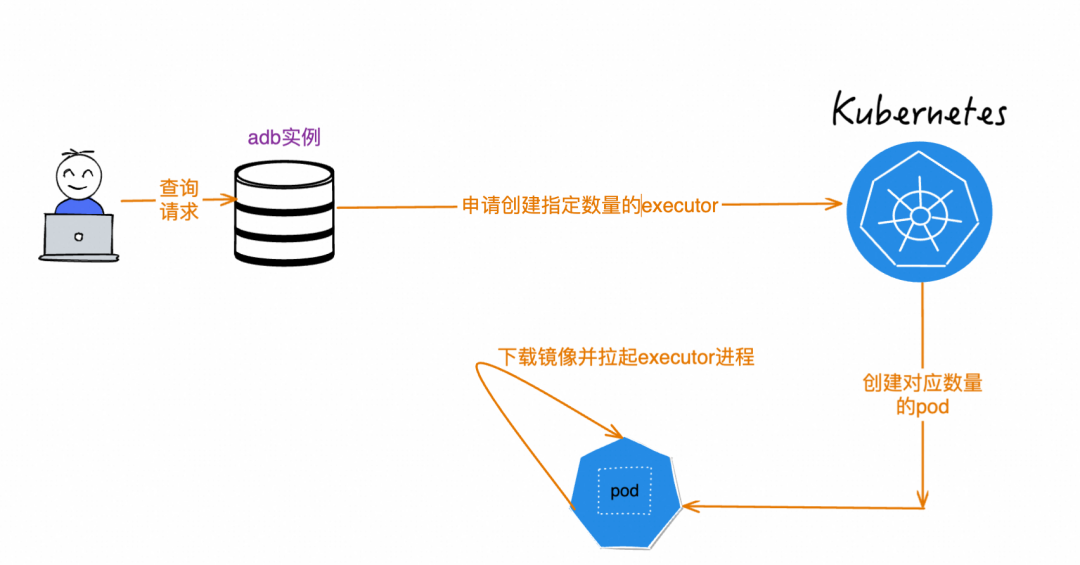
原先的申请采用了直接从k8s服务申请pod的方式。每次在查询请求到来时,会根据查询指定的资源量,申请对应数目的pod,然后在pod上启动ADB的服务。池化是计算机领域的一个热门概念,通过实现的预热启动一批资源,在实际使用时不再需要额外的申请时间,而是直接使用即可,比如经常使用的线程池就使用了池化的思想。ADB的资源热池也用到了池化的思想。在每一个Region都构建资源热池,在其中预热地启动一批executor节点。会并行构建多个不同版本的资源热池,以支持实例版本不同的客户。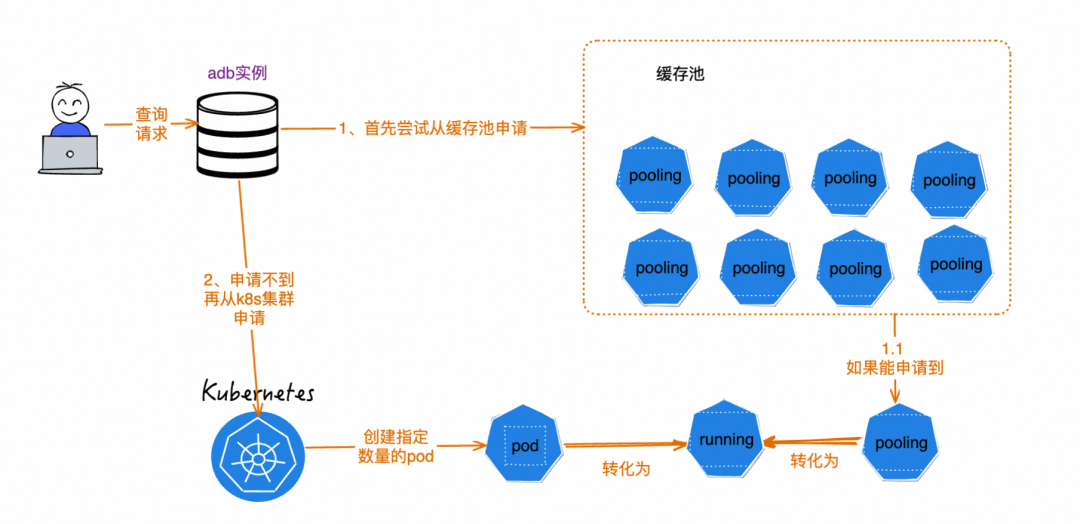
如果有用户实例接收到job查询后,控制节点不再直接向k8s集群申请资源,而是先尝试询问资源热池,是否有与实例版本一致的节点,如果有,就直接使用热池中的节点,如果没有,再尝试从k8集群申请资源。缓存池在成功申请之后,会补出对应数量的节点,维持缓存池大小的稳定。RT:RunningTime,查询的执行时间。
ACU时:ACU(ADB Compute Unit)是ADB产品用于统一计量计费的单位,1ACU时即为1ACU执行一小时,用于表示资源的消耗用时。下述的1ACU为1Core2GB。点查,指只扫描少量数据的查询。这类查询计划简单,执行耗时也很多,往往都在1s内。因此在job模式下,可以说这类查询的时间跟资源申请的耗时有关。使用点查,可以比较直观的感受到弹性效率的变化。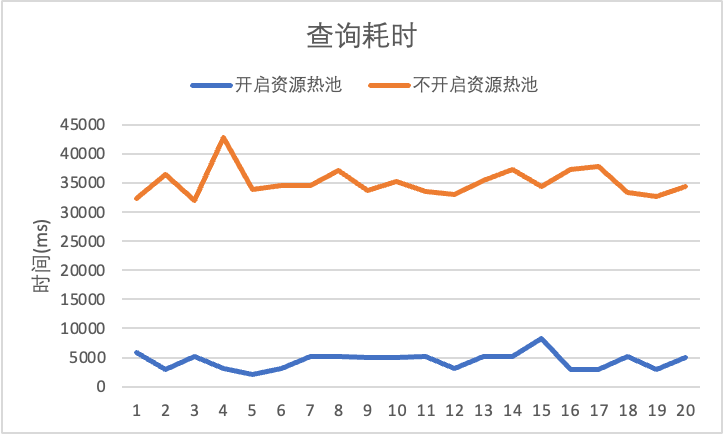
上图是测试了20条点查在开启或不开启资源热池的情况下的耗时。其中,开启资源热池后,资源申请耗时降低约30s,中小查询的性能提升最高可达88%。通过自动资源预估,用户不在需要手动指定资源使用量,提交查询后,交由autowlm根据过往查询的历史信息,通过一个机器学习模型,计算出一个合理的查询的资源预估量。
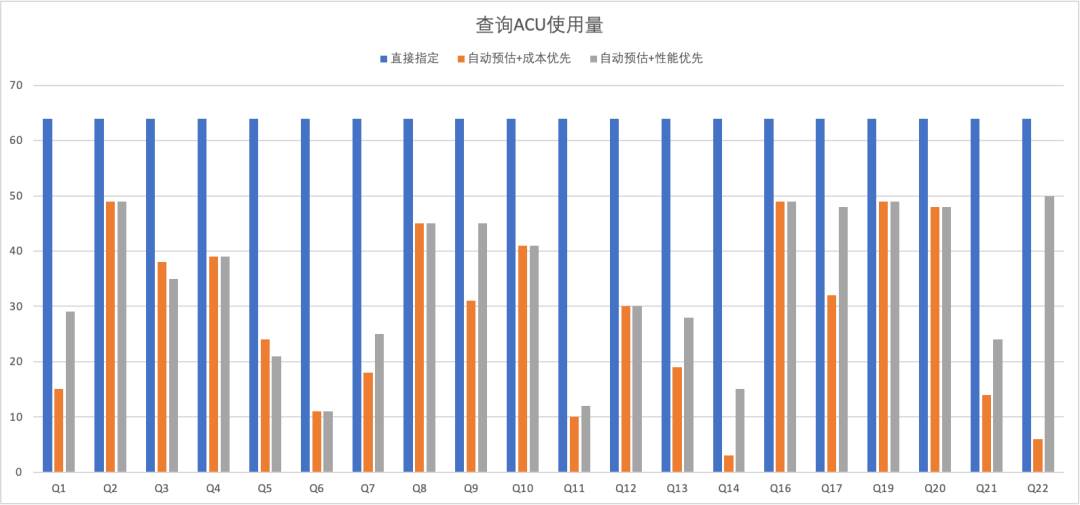
上图是tpch1T的数据集下,使用自动预估前后的查询使用量对比。如果用户直接指定,将使用默认64ACU的方式执行所有查询。反之,如果使用自动预估。出于用户更方便使用的考虑,会提供一个滑块,用户可以自由的决定是成本优先还是性能优先。无论是哪一种,自动预估都能根据不同的查询负载给出合理的资源使用量。
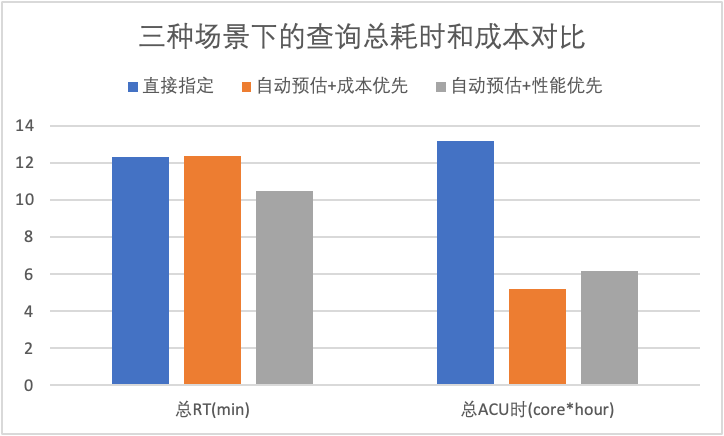
在成本优先模式下,所有查询的总耗时RT与直接指定持平,成本上(即总ACU时)会有降低约60.5%。在性能优先模式下,所有查询的总耗时RT会降低15%,但与此同时,成本也依然能节约53.2%。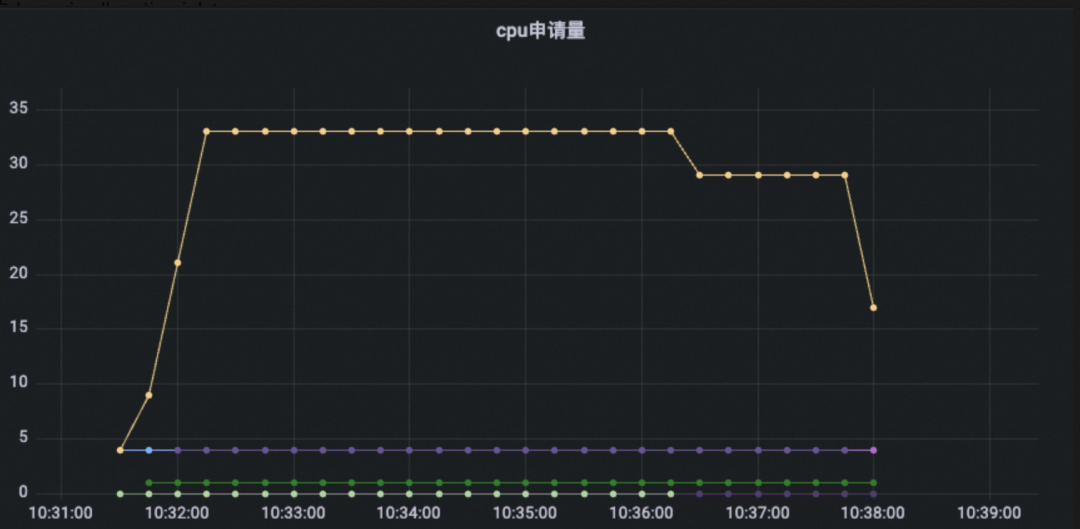
上图是一个典型的使用了DynamicAllocation智能扩缩的查询的资源使用量,可以看到在查询使用初期,由于实际负载一直能打满资源量,所以一直在弹起资源,然后满负载的运行了一段时间。在查询快结束的时候,由于受到需要写入的数据源的并发限制,资源需求量下降,所以自动的缩容了一部分资源,直到查询执行结束。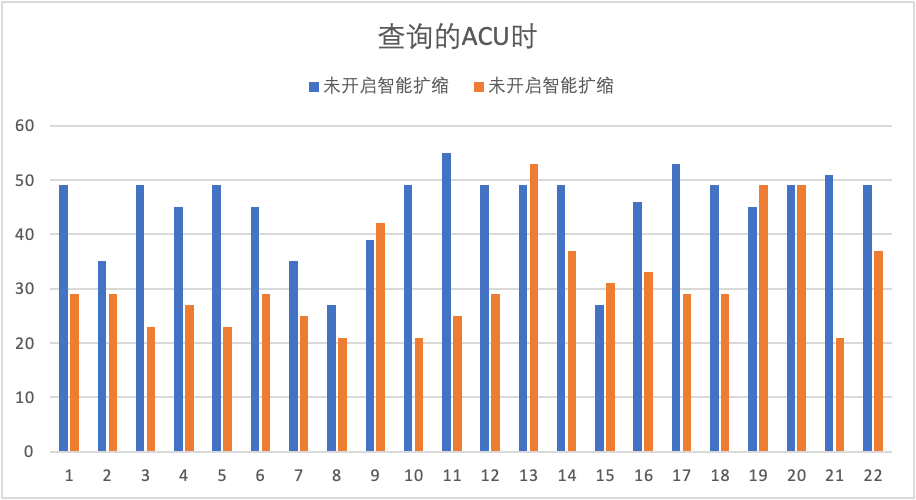
基于tpch100g测试,得到了上图所示的ACU消耗。能看到在开启智能扩缩之后,绝大多数的查询的负载都显著降低。相较于开启前,智能扩缩让所有查询的总ACU耗时降低30.4%。相较于之前的弹性模型,新的智能化弹性模型在以下三个方面都有极大提升:
自动投递:基于负载预估,智能区分大小查询,小查询自动投递到在线资源组,大查询投递到离线资源组,实现成本和性能的平衡。结果报表:在控制台增添一个查询级别的报表,让用户可以更好地了解到单条查询的耗时和ACU消耗。多级滑块:在现有自动预估能力的基础上,拆分出多级滑块,能更自由的选择成本和性能的平衡,适配不同客户的需求。