今天分享的是上海人工智能实验室和几所高校合作发表在COLM2024的一篇文章 Corex: Pushing the Boundaries of Complex Reasoning through Multi-Model Collaboration
文章链接:https://arxiv.org/pdf/2310.00280
代码链接:https://github.com/QiushiSun/Corex
摘要
本篇文章提出了Corex框架,一个自主代理的LLM pipeline。通过多个LLM进行合作提升复杂任务的解决能力。Corex包含多种合作模式(如讨论、审查、检索),通过模拟人类行为,推动LLM代理的推理过程。文章通过四种不同类型的推理任务进行广泛实验,结果表明多个LLM代理协同工作可以产生优于现有基线的效果。框架
讨论模式
这个模式主要基于团队讨论的方法来增强LLMs之间的信息交换,从而提高它们的事实准确性。具体来说,这种方法将LLM代理随机分成两个小组——蓝队和绿队,并且还有一个代理作为裁判()。每个团队内部进行多轮的迭代讨论,在每一轮中,代理们会改进他们的推理链和预测。在每轮讨论结束时,两队会提交他们改进后的预测。如果两队的预测一致,则讨论顺利结束;如果有差异,则所有轮次的输出都会提交给裁判。裁判使用一个决策过程来评估整个讨论过程中各轮的推理链和预测的质量,最终做出综合评价和更为精准的决定。
审查模式
CoT方法以其解释的通用性和清晰度著称,但容易产生累积错误,并且通过提示提升文本质量的效果有限。另一方面,PAL通过程序保证了计算准确性,但可能存在LLMs误解问题的情况,导致虽然技术上正确但实际上误导性的程序生成,以及生成的代码中可能存在的bug,比如引用未定义的变量或执行除以零的操作。受到LLMs同行评审和软件工程中协作编码实践的启发,文中提出了一种多代理协作的方式-Review模式,来解决这些问题。在这个模式下,随机选择一个代理作为主要代理,负责形成初始解决方案集合 ,其中包括答案、推理链。随后,其他代理依次作为评审者对提供的或先前评审者修改过的解决方案进行严格的审查。每个评审者都会基于前一评审者的成果和反馈进行工作,从而逐步完善解决方案。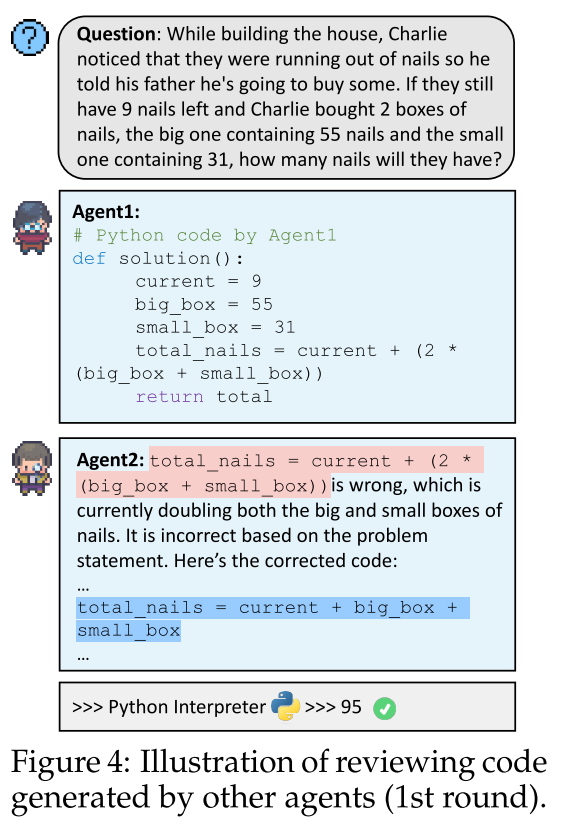
检索模式
在检索模式中,对于给定的问题,我们从个代理中随机选择一个代理作为检索者。剩下的个代理独立地解决这个问题,每个代理生成自己的推理链和相应的预测,形成了一个候选池。然后,检索者审查候选池中的每一个,评估ci与pi之间的忠实度,并根据这一评估为每一对赋予一个置信分数,范围在[0, 1]之间,记为,其中fr表示检索者的评估过程。最后,通过比较所有候选对的置信分数,选择具有最高置信度的推理链-预测对作为最忠实的回答,将作为问题q的最终答案。
总结
本文提出了一个多LLM代理的工作流程,区别于传统的代理间对话讨论的模式。提出了三种工作流程来解决复杂问题,在附录G中公开了相关的提示词。编者简介
李剑楠:华东师范大学硕士研究生,研究方向为向量检索。作为核心研发工程师参与向量数据库、RAG等产品的研发。代表公司参加DTCC、WAIM等会议进行主题分享。
👆 关注 AI 搜索引擎,获取更多专业技术分享 ~





