




今天分享的是一篇由英伟达发布的文章:
RankRAG: Unifying Context Ranking with Retrieval-Augmented Generation in LLMs
RankRAG:在大模型中统一检索增强生成与上下文排序

论文链接:https://arxiv.org/pdf/2407.02485v1
摘要
RankRAG框架
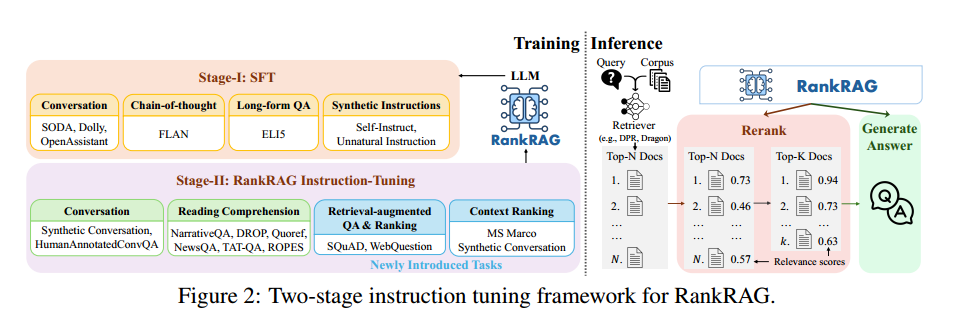
1.训练阶段
1.1 监督微调(SFT)
1.2 统一指令调优排序和生成
第一阶段的SFT数据: 这一部分是为了维护LLM的指令遵循能力。 丰富上下文的问答数据: 利用多个具有丰富上下文的问答任务来增强大语言模型(LLM)使用上下文进行生成的能力。训练数据集包括: 标准的问答和阅读理解数据集
对话式问答数据集
合成对话问答数据集
检索增强的问答数据: 为了提升模型对无关上下文的鲁棒性。作者采用了SQuAD和WebQuestions这两个数据集,这些数据集不仅包含答案上下文,还包括使用BM25检索到的最佳上下文。对于每个问题,作者将答案上下文与使用BM25检索到的最佳上下文结合,确保每个问题都能关联五个上下文。其中一些检索到的上下文可能不包含答案,这些被称为负样本。 上下文排序数据: 为提升LLM的上下文排序能力,作者使用了MS MARCO段落排序数据集。该数据集将问题-相关段落(q,c+)视为正例,而使用BM25检索到的困难负例段落(q,c-)视为负例。LLM需要根据问题判断段落是否与其相关,生成“True”或“False”。此外,由于针对对话问答的排名数据极为稀缺,作者利用对话问答对生成伪相关对,由于每个对话只与一个文档相关联,作者将每个文档切分为150字的片段。然后计算每个片段与真实答案之间的4-gram召回率,召回率高于0.5的片段被视为与对话相关,低于0.1的则被视为不相关。每个样本包含一个问题-上下文对用于该排序数据集。最终作者将两种数据结合,用于训练模型的上下文排序能力。 检索增强的排序数据: 为了提升模型同时评估多个上下文与问题相关性的能力,作者将SQuAD和WebQuestions中的答案上下文与BM25检索到的最佳上下文结合,确保每个问题能关联到五个上下文。其中包含答案的上下文被认为是相关的,训练LLM识别所有与问题相关的上下文。
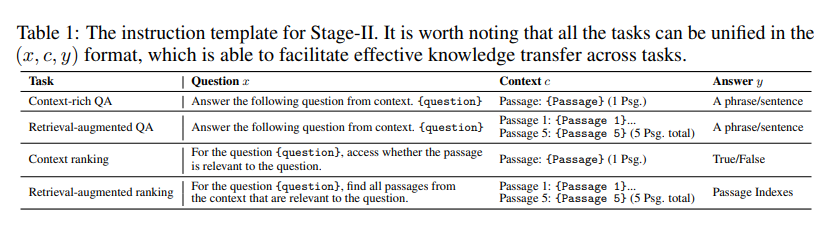
通过增加相对较少的排序数据,增强了LLM的排序能力。 通过将这些任务标准化为统一格式,它们可以相互增强。
2.推理阶段
检索器R首先从语料库中检索top-N上下文。 RankRAG模型计算问题与检索到的N个上下文之间的相关性分数,作为使用表1中的提示符生成答案为True的概率,然后对上下文重新排序,只保留前k个(k≪N)上下文,然后将其用作生成步骤的输入。 将top-k上下文与问题连接并反馈到RankRAG模型中,以生成最终答案。
总结
文章转载自向量检索实验室,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
