




背景
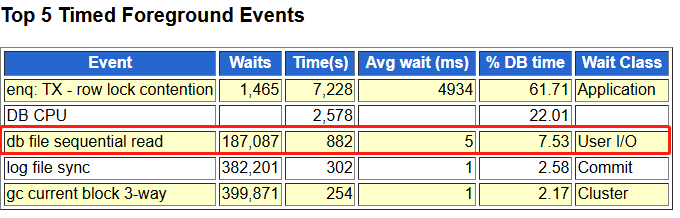
在每天的AWR报告巡检中发现一性能SQL情况,发现 db file sequential read等待事件消耗在User I/O,再看SQL有个UPDATE语句16.81%的IO消耗,然后再查看这张表的数据达到了9亿+,大表还自关联,头痛来袭。
- Db File Sequential Read:等待从磁盘中将块读取到中的过程,进行单块读产生的等待事件:
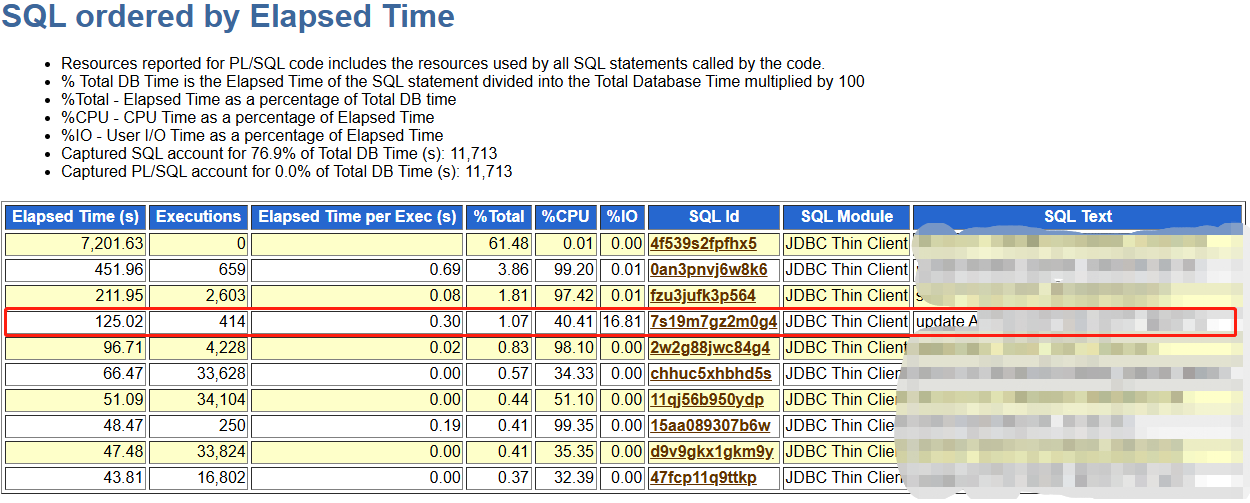
性能SQL(已做脱敏处理)
- SQL需求解析:更新订单ID为:“2024091309581000101”近7天订单状态为N的数据,每次处理5000条记录。
- 问题:开发把简单的SQL复杂化了,多加了个子查询,而且是9亿+的表。
update BUFFER_TMP
set STATUS='Y' , LAST_UPADTE_TIME=sysdate
where STATUS='N'
and ID='2024091309581000101'
and TRAN_TIME>=sysdate-7
and TRAN_SEQ in (select TRAN_SEQ from BUFFER_TMP
where ROWNUM<5001 and STATUS='N'
and ID='2024091309581000101' );
- 变装SQL
update BUFFER_TMP
set STATUS='Y' , LAST_UPADTE_TIME=sysdate
where STATUS='N'
and ID='2024091309581000101'
and TRAN_TIME>=sysdate-7
and ROWNUM<5001;
变装前后性能对比(测试)
- 表结构:
create table BUFFER_TMP
(......略)
partition by range (TRAN_TIME) -- 分区字段
subpartition by list (STATUS) -- 子分区字段
-- 表数据库:9亿+
SQL> select count(*) from BUFFER_TMP ;
COUNT(*)
----------
905107731
- 刷新内存
SQL> ALTER SYSTEM FLUSH SHARED_POOL;
System altered.
SQL> ALTER SYSTEM FLUSH BUFFER_CACHE;
System altered.
- 执行计划对比
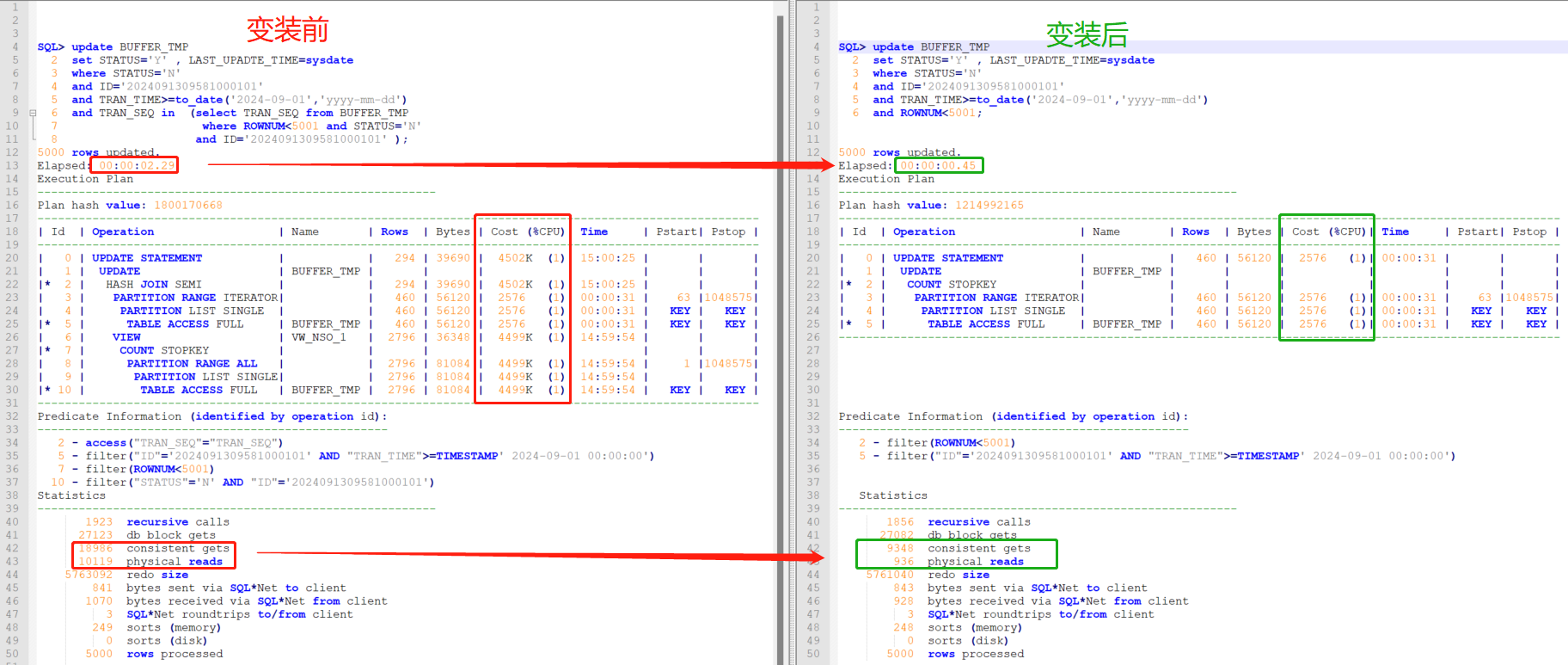
逻辑读:18986/9348 = 2.03
物理读:10119/936 = 10.81
COST:4502K/2576 = 1747.67
执行时间:00:00:02.29 下降至:00:00:00.45
解读:从IO表现来分析,逻辑读提高2+倍、物理读提高10+倍。Cost提升了1747+倍,执行时间提高近原来的SQL对表进行了2次全表扫,变装后仅全表扫了1次。从这3点来看变装后的SQL要比原SQL更优。
使用过程完成对固定数据的更新,对比效率
- 数据量说明:在9亿+的表更新40w+的数据
-- 需要更新的数据:40w+
SQL> select count(*) from BUFFER_TMP where STATUS= 'N' and ID='2024091309581000101' and TRAN_TIME>=to_date('2024-09-01','yyyy-mm-dd');
COUNT(*)
----------
462896
执行原SQL匿名块:
SQL> SET SERVEROUTPUT ON;
SQL> -- 刷新内存
SQL> ALTER SYSTEM FLUSH SHARED_POOL;
System altered.
Elapsed: 00:00:00.11
SQL> alter system flush buffer_cache;
System altered.
Elapsed: 00:00:00.10
SQL> -- 变装前
SQL> DECLARE
2 var_num int;
3 i int ;
4 BEGIN
5 select count(*) into var_num from BUFFER_TMP where STATUS = 'N' and ID='2024091309581000101' and TRAN_TIME>=to_date('2024-09-01','yyyy-mm-dd');
6 for i in 1..trunc(var_num/5000)+1 loop
7 update BUFFER_TMP
8 set STATUS='Y' , LAST_UPADTE_TIME=sysdate
9 where STATUS='N'
10 and ID='2024091309581000101'
11 and TRAN_TIME>=to_date('2024-09-01','yyyy-mm-dd')
12 and TRAN_SEQ in (select TRAN_SEQ from pay.BUFFER_TMP
13 where ROWNUM<5001 and STATUS='N'
14 and ID='2024091309581000101' );
15 commit;
16 end loop;
17 commit;
18 dbms_output.put_line('完成循环:'||'='||to_char(mod(var_num,5000)+1) || '次');
19 EXCEPTION
20 WHEN OTHERS THEN
21 dbms_output.put_line('失败');
22 END;
23 /
完成循环:=93次
PL/SQL procedure successfully completed.
Elapsed: 00:01:37.72
-- 数据已全部更新:STATUS = 'N' 为0
SQL> select count(*) from BUFFER_TMP where STATUS = 'N' and ID='2024091309581000101' and TRAN_TIME>=to_date('2024-09-01','yyyy-mm-dd');
COUNT(*)
----------
0
Elapsed: 00:00:00.27
数据恢复: STATUS= ‘Y’ => STATUS=‘N’
SQL> update BUFFER_TMP set STATUS='N' where STATUS= 'Y' and ID='2024091309581000101' and TRAN_TIME>=to_date('2024-09-01','yyyy-mm-dd');
462896 rows updated.
Elapsed: 00:00:12.35
SQL> commit;
Commit complete.
Elapsed: 00:00:00.05
执行变装后SQL匿名块:
SQL> SET SERVEROUTPUT ON;
SQL> -- 刷新内存
SQL> ALTER SYSTEM FLUSH SHARED_POOL;
System altered.
Elapsed: 00:00:00.17
SQL> ALTER SYSTEM FLUSH BUFFER_CACHE;
System altered.
Elapsed: 00:00:00.10
SQL> -- 变装后
SQL> DECLARE
2 var_num int;
3 i int ;
4 BEGIN
5 select count(*) into var_num from BUFFER_TMP where STATUS = 'N' and ID='2024091309581000101' and TRAN_TIME>=to_date('2024-09-01','yyyy-mm-dd');
6 for i in 1..trunc(var_num/5000)+1 loop
7 update BUFFER_TMP
8 set STATUS='Y' , LAST_UPADTE_TIME=sysdate
9 where STATUS='N' and ID='2024091309581000101' and TRAN_TIME>=to_date('2024-09-01','yyyy-mm-dd') AND ROWNUM<5001;
10 commit;
11 end loop;
12 commit;
13 dbms_output.put_line('完成循环:'||'='||to_char(mod(var_num,5000)+1) || '次');
14 EXCEPTION
15 WHEN OTHERS THEN
16 dbms_output.put_line('失败');
17 END;
18 /
完成循环:=93次
PL/SQL procedure successfully completed.
Elapsed: 00:01:16.80
-- 数据已全部更新:STATUS = 'N' 为0
SQL> select count(*) from pay.BUFFER_TMP where STATUS = 'N' and ID='2024091309581000101' and TRAN_TIME>=to_date('2024-09-01','yyyy-mm-dd');
COUNT(*)
----------
0
Elapsed: 00:00:00.30
测试小结
- 匿名块执行循环93次,每次更新5000条记录,执行时间变装前(Elapsed: 00:01:37.72)变装后(Elapsed: 00:01:16.80)时间相差21s,整体的提升并不明显,但整体SQL更加简洁;
测试查询(加索引)效率
select count(*) from BUFFER_TMP t
where STATUS='N'
and ID='2024091309581000101'
and TRAN_TIME>=to_TIMESTAMP('2024-09-01','yyyy-mm-dd')
and ROWNUM<5001;
- 创建索引:9亿数据建索引耗时半小时
SQL> create index idx_buffer_tran_time_id on buffer_tmp (tran_time,id,status) local;
Index created.
Elapsed: 00:34:07.45
- 执行计划对比
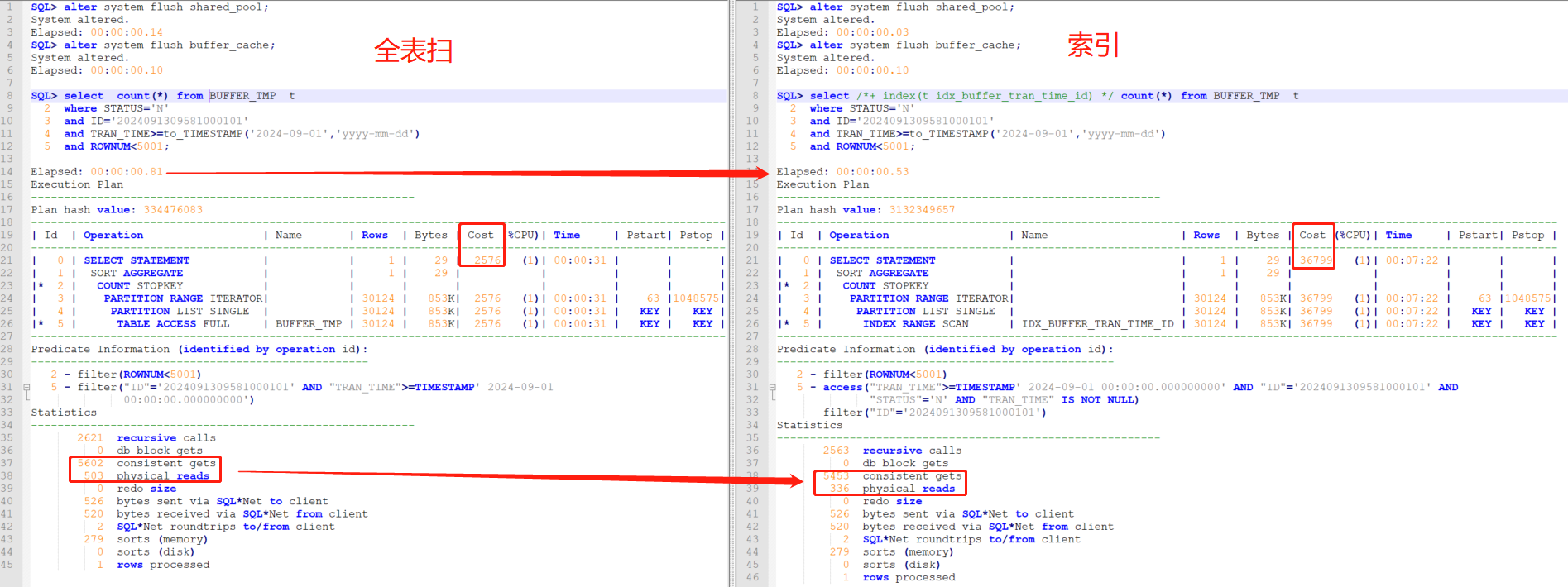
测试小结
- 加索引确认能让物理、逻辑IO都降下来了,执行耗时:Elapsed: 00:00:00.81 下降:Elapsed: 00:00:00.53;
- Cost 2576 上升至 Cost 36799 因此优化器选择了全表扫;
- 疑问:执行计划显示走索引明显比全表扫要快,但优化器还是根据cost 选择了全表扫描,cost计算是不是有问题?后续用10053事件观察一下;未完待续
总结
- 1、此次SQL的写法问题一般是因为开发对update 能否支持rownum条件不太了解导致;
- 2、从执行计划来看效率前后对比应该会有好几倍,但实际效果并没有达到;
- 3、加索引并不能解决所有性能问题,具体问题具体分析,然后再用具体手段;
欢迎赞赏支持或留言指正

最后修改时间:2024-10-13 10:58:05
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
