今天为大家分享一篇通过稀疏的上下文选择来加速RAG推理的工作,该论文由DeepMind, gooogle, UCLA, 蒙特利尔大学联合发表。 Accelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection
论文地址: https://arxiv.org/abs/2405.16178
1.论文概述
检索增强生成技术(RAG)通过结合外部上下文表现出了强大的性能。然而,外部上下文导致喂入大模型的token数量呈线性增长,导致延迟急剧增加。因此,论文提出了一种新的RAG范式:Sparse RAG, 试图通过稀疏性来降低推理时间。具体来说,SparseRAG对检索出来上下文并行的进行评估,筛选出与问题最相关的上下文,然后将该上下文联合问题作为输入喂入大模型以生成答案。2.核心内容
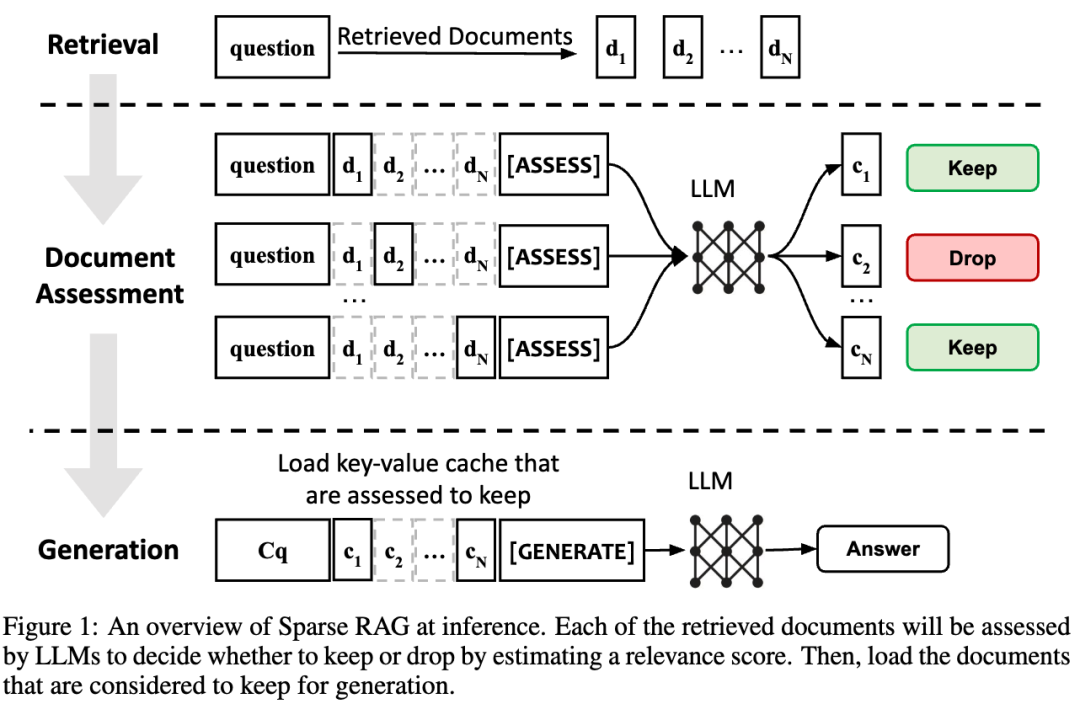 Sparse RAG的推理架构如上图所示。具体可以分为三个阶段: 1. 检索阶段(Retrieval):从外挂的语料库中检索出与问题最相关的N个文档,这个过程与典型的RAG过程相同。2. 文档评估(Document Assessment):将N个文档分别与问题进行组合形成N个评估单元,将这N个评估单元喂入模型,该模型为每个单元进行打分。分数表示文档与问题的相关度,分数越高表示对问题的贡献度越大。最终根据打分情况丢掉不相关的文档。在论文中,使用的评估模型是PALM2和Gemini。这一个阶段是文章的核心贡献,也是降低推理延迟的主要来源。 3. 生成:将上一个阶段得分高的文档的kv 进行加载进行推理生成答案。为了更精准的评估每个文档与问题的关联度,论文分为了两个阶段:训练和推理。首先通过一个训练过程提升评估模型的精度,然后再用于推理过程。
Sparse RAG的推理架构如上图所示。具体可以分为三个阶段: 1. 检索阶段(Retrieval):从外挂的语料库中检索出与问题最相关的N个文档,这个过程与典型的RAG过程相同。2. 文档评估(Document Assessment):将N个文档分别与问题进行组合形成N个评估单元,将这N个评估单元喂入模型,该模型为每个单元进行打分。分数表示文档与问题的相关度,分数越高表示对问题的贡献度越大。最终根据打分情况丢掉不相关的文档。在论文中,使用的评估模型是PALM2和Gemini。这一个阶段是文章的核心贡献,也是降低推理延迟的主要来源。 3. 生成:将上一个阶段得分高的文档的kv 进行加载进行推理生成答案。为了更精准的评估每个文档与问题的关联度,论文分为了两个阶段:训练和推理。首先通过一个训练过程提升评估模型的精度,然后再用于推理过程。3.总结
这篇论文提出了用Sparse RAG来解决输入长度和延迟增加的挑战。Sparse RAG 可以有效地管理检索到的文档的KV缓存,从而使 LLM 能够专注于高度相关的token。这种选择性注意机制不仅可以减少推理过程中的计算负担,还可以通过过滤掉不相关的上下文来提高生成质量。这篇工作相当于后检索优化,对从语料库检索出来的上下文进行再次约减。
👆 关注 AI 搜索引擎,获取更多专业技术分享 ~





