




关于波克城市和作者

业务背景
数据血缘系统的建设有助于清晰地识别数据之间的依赖关系和影响范围。在数据出现问题时,可以快速定位问题源头,有效减少错误诊断和修复的时间,保证业务的连续性和数据的准确性。 数据血缘分析为数据管理提供了透明度,使得数据的利用更加合规,尤其是在遵守日益严格的数据保护法规(如 GDPR 或 CCPA)的背景下。 数据血缘系统通过详细记录数据的每一次处理和传输,增强了数据安全性,让我们能够对潜在的数据泄露和非授权访问进行有效预防。通过这种方式,数据血缘系统不仅提升了数据的可用性和可靠性,也增强了企业对数据资产的掌控能力,从而支撑了数据驱动决策的实施,提升了企业的竞争力。
技术选型
踩坑总结
Part.01
环境搭建阶段


在每个节点上分别查看 NebulaGraph 的运行状态,发现有两个节点的服务没有正常启动。



Part.02
数据写入阶段

def hashCode(value):h = 0for c in value:h = (31 * h + ord(c)) & 0xFFFFFFFFreturn h if h < 0x80000000 else h - 0x100000000
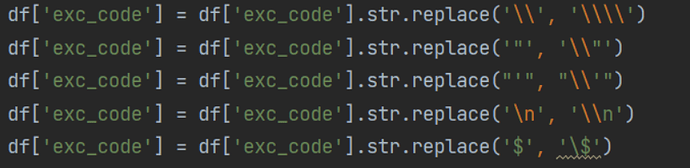
最终,在正式环境下,将 VID 类型修改为定长字符串 FIXED_STRING(128),以 库名+表名的拼接作为 VID。



Part.03
数据查询阶段
CREATE TAG INDEX IF NOT EXISTS database_index_0 on table_node(database_name(15), table_name(20));REBUILD TAG INDEX database_index_0;
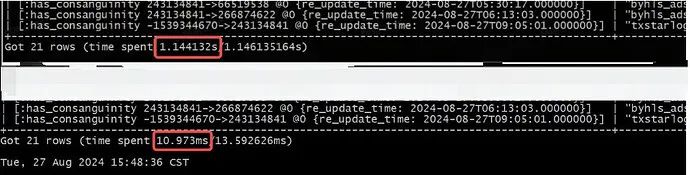
MATCH// 查询指定节点及其属性(n:table_node{database_name:"byhls_ods",table_name:"app_login_log"}) AS target_node,// 查询该节点的所有上游节点(边的起始点)(upstream:table_node)-[:has_consanguinity]->(n) AS upstream_nodes,// 查询该节点的所有下游节点(边的终点)(n)-[:has_consanguinity]->(downstream:table_node) AS downstream_nodesRETURNtarget_node.database_name AS database_name,target_node.table_name AS table_name,COLLECT(DISTINCT upstream) AS upstream_nodes,COLLECT(DISTINCT downstream) AS downstream_nodes
总结反思
✦
如果你觉得 NebulaGraph能帮到你,或者你只是单纯支持开源精神,可以在 GitHub 上为 NebulaGraph 点个 Star!每一个 Star 都是对我们的支持和鼓励✨
https://github.com/vesoft-inc/nebula
✦
✦

扫码添加
可爱星云
技术交流
资料分享
NebulaGraph 用户案例集
文章转载自NebulaGraph 技术社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
