




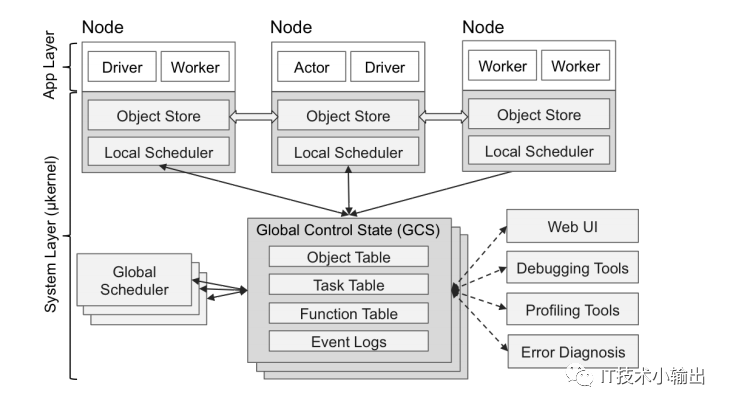
其中两个比较关键的部分:
1)全局状态存储 GSC(Global Control Store)。系统所有的控制状态存储在 GSC 中,这样系统其他组件可以是无状态的。不仅简化了对容错的支持(出现错误时,组件可以从 GSC 中读取最近状态并重新启动),也使得其他组件可以横向扩展(该组件的复制或碎片可以通过 GSC 状态共享)。
2)自底向上的分布式调度器。任务由 driver 和 worker 自底向上地提交给局部调度器(local scheduler)。局部调度器可以选择局部调度任务,或将任务传递给全局调度器。通过允许本地决策,降低了任务延迟,并且通过减少全局调度器的负担,增加了系统的吞吐量。
Flink + Ray:
使用flink为Ray上继承的Xgboost、tensorflow、sklean等提供实时数据,可对模型进行实时更新,增量训练。那么首要解决的其实就是数据打通问题。
从上面的架构图是可以看出来的,Ray的数据是存放在Object Store里的,那么将flink处理过的数据存放入object store中就可以解决这个问题,需要将数据类型转换成机器学习使用的数据类型才可以完全解决数据打通问题,下面以Flink_Xgboost_Ray为例:
原生版Xgboost:
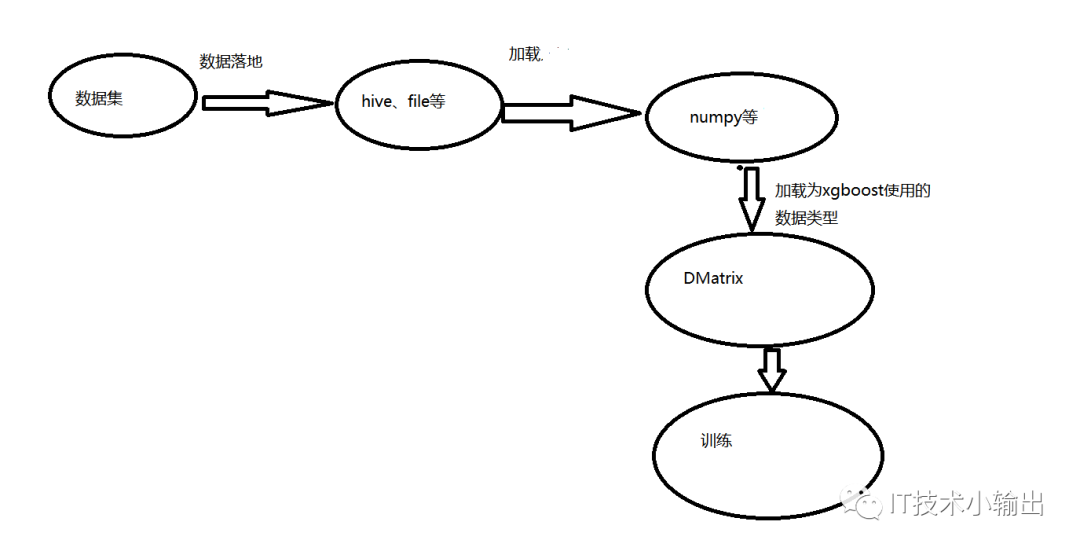
可以看到,使用的数据集需要先经过一次加载落地,再被numpy加载转换为DMatrix数据类型输出到模型训练,会有两次数据加载过程。
Flink_Xgboost_Ray:
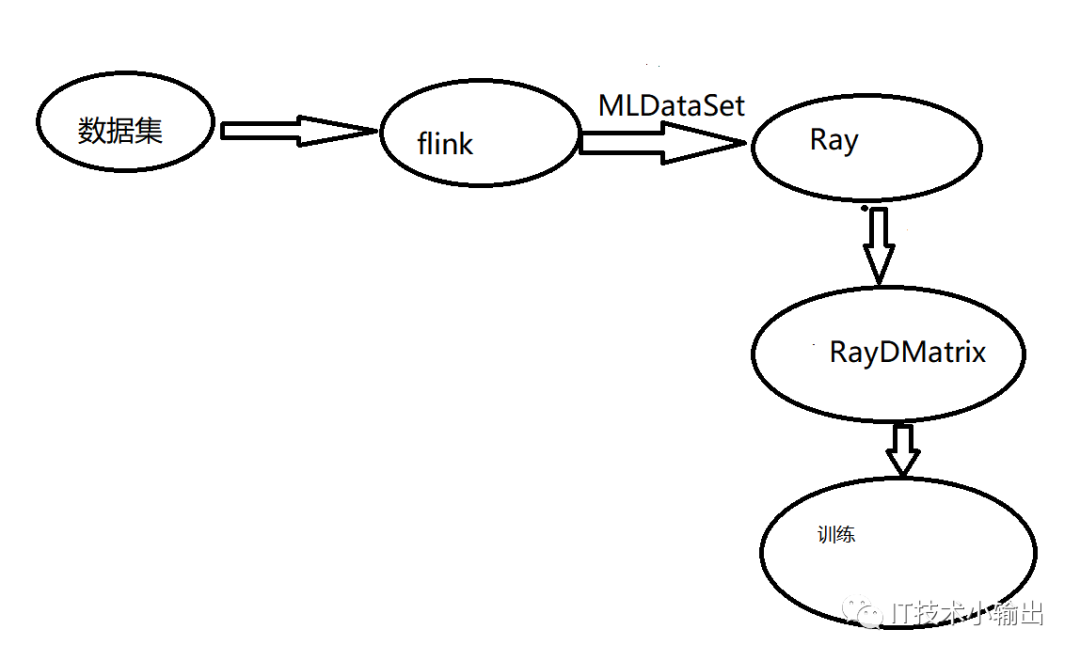
上图看起来和原生版的差不多,区别在于数据集比如说在kafka里,直接输入到flink中进行处理,flink处理之后的数据输出到Ray 的object store中转换为特定的数据类型。这里比原生版的少了一次数据加载落地的步骤,数据的加载落地是非要耗费资源的,省略这一步骤整个系统性能会得到很大的提升,特别是在实时场景下数据流很大的情况下。
Flink_Xgboost_Ray可以实现模型的增量训练和实时更新,实现了实时智能bigdata + AI。
并且FLIP-23是Apache flink没有完全开发完成的model server,可以基于此进一步开发model server,与ray集成。
