





本文难度有点高了,特别是后面测试部分。我全当总结了,写在这里,那天我自己还能看。
书接前文。
我们已经逐渐逼近NUMA的真相。
但,很多时候,知道真相是要付出代价的。
快递站(Core)和A/B两仓库(内存控制器)间的不平衡,是天然存在、且无法解决的。这一点,本文反复强调。
在面对这些不平衡时,操作系统/MMU都做了什么,这是我们需要了解的。
本篇,将为你彻底揭开NUMA的秘密。
并且,设计一个实验,让我们实际动手,测量NUMA、感受NUMA(就这一块有点难)。毕竟,光说不练假把式吗(假把式其实也不错,并不影响什么)。
操作系统、CPU中的MMU和内存控制器,三方联合,在编址上做做文章,让你分配的内存,均匀的来自所有NUMA节点(让高志垒的快递,均匀的分布在A/B两个仓库),这就是上一篇中提到的交织模式。
通过交织模式的介绍,我们要明确一点,对我们来说,一个物理地址对应那个NUMA节点,这个是已经固定好的。
比如第一篇中提到的,物理地址:XXXXB浦东新区石桥路28弄。
这个物理地址对应的仓库是固定的,左起第5位的“B”,已经说明它对应B号仓。
要改变这一点,除非改变内存控制器的编址规则,它负责根据物理地址,实际的发起内存访问。
内存控制器的编址规则,应该是无法改变的。
我们能控制的,就是MMU和操作系统这部分,虚拟地址向物理地址的转换过程。通过让虚拟地址映像到不同物理地址,实现虚拟地址对应不同NUMA节点内存。
比如虚拟地址16383,和16384。按在普通页大小(非大页)、交织模式下,有两个仓库(内存控制器)时,第13个二进制位是NUMA编号,那么如下图:
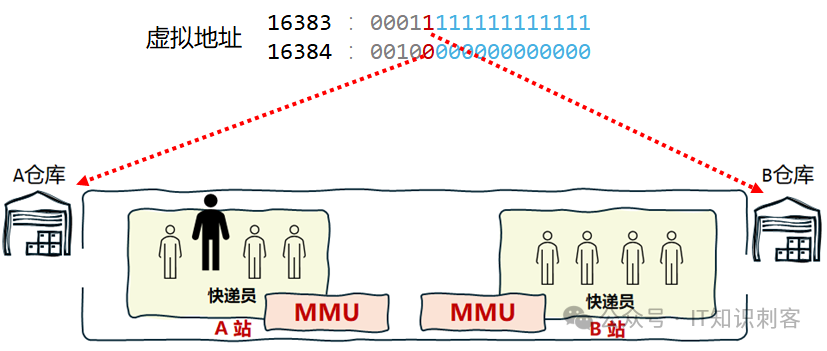
地址16383在B仓,16384在A仓。
只要修改操作系统/MMU的编址规则,虚拟地址对应的物理地址就会变化,它对应的NUMA节点也会相应变化。
下面我们继续用快递站作为例子。第一篇讲到过:
A/B两个仓库,分别对应浦西、浦东。
假设浦西一共1,048,576家住户,浦东也是,1,048,576家住户。
每个4096家住户在一个小区中。浦东/浦西,分别有256个小区。
如果将第25个二进制位,设为代表仓库号的位,快递的分配将是怎么的?
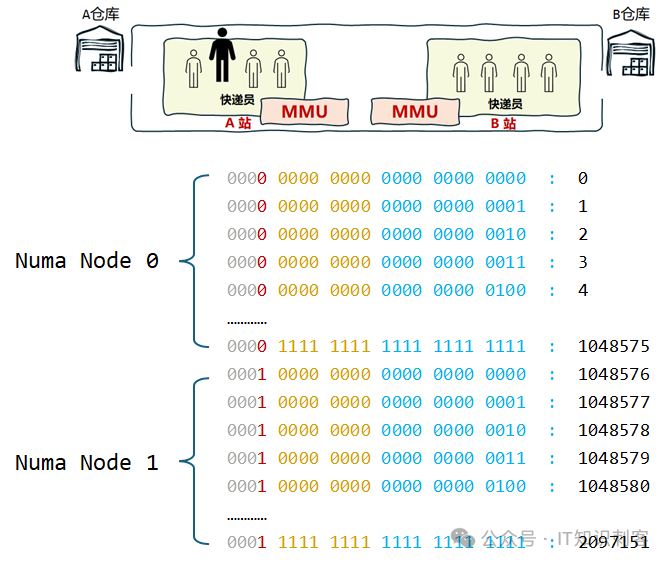
如上图,第25位是仓库号。
那么,虚拟地址0至1048575的快递,都在A仓(即,Numa Node 0),对应浦西的每一户人家。前文说了,浦西共1,048,576家住户。
浦东也是1,048,576家住户,从虚拟地址1048576至2097151,是浦东的所有住户(对应B仓,即Numa节点1)。
当把仓库号从13位,改到第25位时,快递(即,要存到内存的数据,也就是内存)的分配不再是交织。而是会集中在一个Numa节点中。
这是缺省的分配方式,也被称为localalloc。
分 配内存时,操作系统总是在进程所在Core的NUMA节点(也称当前节点)上分配内存;如当前节点内存不足,再从其他节点分配。
你可以使用numactl --localalloc,通知操作系统,你要使用这种缺省的分配方式。
除了localalloc、interleave,numactl还可以使用preferred和membind,统一做个总结吧:
Numa的内存策略
•localalloc:总是在当前节点上分配内存;如当前节点内存不足,再从其他节点分配。Default即此策略
•preferred :倾向于在特定节点上分配内存,当指定节点的内存不足时,操作系统会在其他节点上分配
•membind:只能在传入的几个节点上分配内存,当指定节点的内存不足时,内存的分配就会失败
•interleave:内存会在传入的节点上依次轮询,当指定节点的内存不足时,操作系统会在其他节点上分配
(以上所说节点,均指NUMA节点)
更多numactl的使用,自行AI或百度吧。
除了使用numactl,我们也可以在BIOS中开启、关闭NUMA。这是让人产生最大误解的地方,因为BIOS的很多设置直接和硬件相关,很多人认为BIOS中关闭NUMA,就真的没有NUMA了。
但这是不可能的。又要上这张图了,
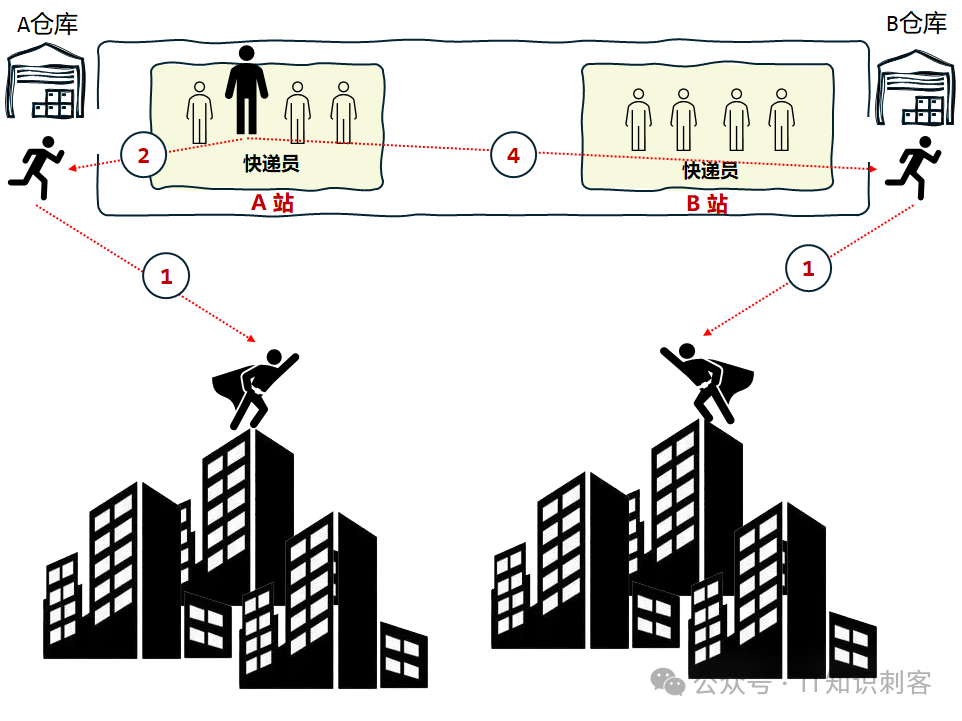
Core(快递员就是Core)和仓库(内存控制器)的不对等性,是物理问题。你在BISO关掉,怎么可能就没有这种不对等性呢!
事实上,在BIOS中关闭NUMA后,操作系统和MMU将以更细的粒度“交织”。
有资料上说,是以256字节为粒度,0-255对应NUMA 0,256-511对应NUMA 1,512-767对应NUMA0,……,以此类推。
这个交织的粒度,我没有验证,因为我的测试机不能随便重启。但我相信是这样的。
只要“交织”的粒度足够的细(不能小于一个CacheLine,64字节),程序的访存就会一次快、一次慢、一次快、一次慢,平均就是不快也不慢,好像是没有了NUMA。
总结一下吧:
lBIOS开启NUMA:将使用localalloc模式,总是在当前节点上分配内存;如当前节点内存不足,再从其他节点分配。大多数情况下,它是默认值。
lBISO关闭NUMA:将使用细粒度交织模式。以几个CacheLine(到底是几个还需要验证)大小为单位交织。
l如果使用numactl: 以numactl为准。
l如果程序使用set_mempolicy(),以set_mempolicy()为准。
好,基础知识也差不多了,写个程序测测吧,光说不练假把式。
(FBI警告:从这里开始上强度了啊)
理论归理论,实际情况到底什么样,还是要动动手,才知道。
我有两个NUMA节点。
NUMA Node 0,对应CPU 0-7,16-23
NUMA Node 1,对应CPU 8-15,24-31
BIOS中NUMA为默认值,localalloc模式。总是在当前节点上分配内存;如当前节点内存不足,再从其他节点分配。
这种模式下,申请一大块内存,如果这块内存足够大,根据localalloc模式的规则,它会跨两个NUMA节点。
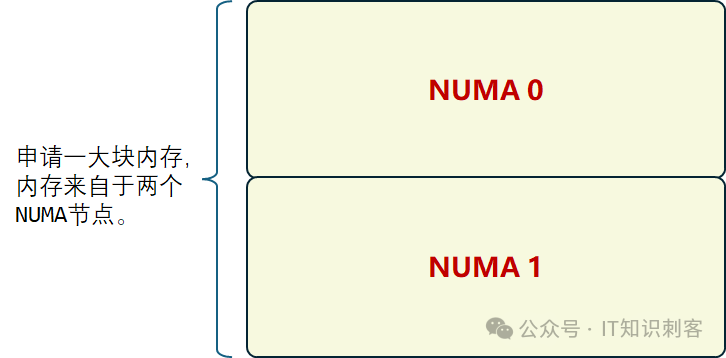
我们反复强调,NUMA只是操作系统和MMU在编址上做做手角,在虚拟地址映射到物理地址这个环节,让虚拟地址映射到不同内存控制器(即不同的NUMA节点)。
操作系统和MMU所能控制的,只是编址。所以,在BIOS是默认值时,上图就是成立的,我只要申请的内存块足够大,超过了一个NUMA节点Free内存的上限,OS一定会从另一个NUMA节点上分配内存。也就是,我所申请的内存块,虚拟地址一部分映射到NUMA 0,另一个部分映射到NUMA 1。
如果进程在CPU 0上运行,它会尝试从NUMA 0上分配所有内存。NUMA 0上内存不够了,再从NUMA 1中分配。
然后,我按如下的方式,访问内存:
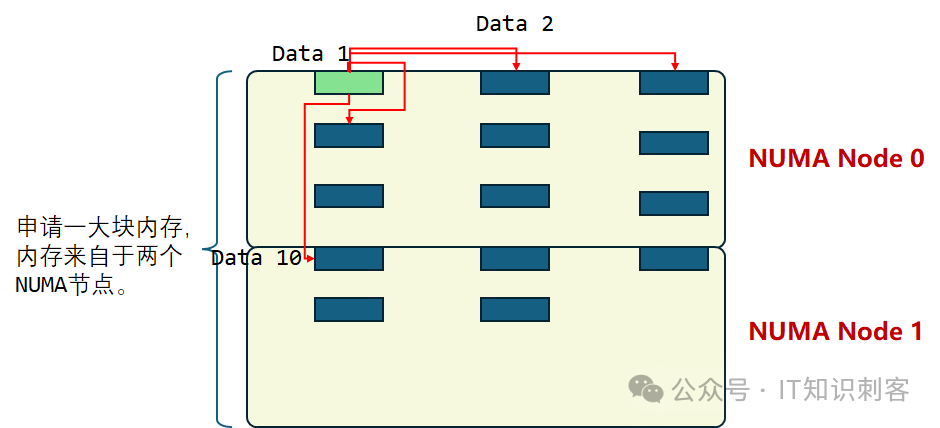
Data 1,存储一个类似“基址“的信息。读出Data 1,加上一个偏移,比如32768(32K)字节,得到Data 2地址,访问Data 2。
相当于Data 1指向Data 2。只是相当于啊,Data 1中,只是基址,并不是Data2的指针。
我的目的,是让对Data2的访问,依赖于Data 1。只在从Data 1中读到数据了(读操作完成),才能加上偏移,得到Data 2地址。
这样,Data1、Data2的Load,不能并行执行。
CPU内部有很多并行的,叫指令级并行,ILP,有时候会影响测试结果,要想办法避免。
(Data 1,Data 2)是一对依赖的访问,我称之为一个地址对。之后,再进行(Data 1,Data3)。
Data 1和Data3也是一对依赖的访问,从Data 1中得到基址,加偏移,得到Data3地址,和(Data1,Data2)这一对一样。
每一对地址对内,都有依赖,不能并行。但如果地址对间没有依赖,CPU的ILP也会乱序的并行执行。阻止它们乱序也很简单,在(Data 1,Data 2)和(Data 1,Data 3)间,增加依赖。
具体就是在访问地址对(Data 1,Data 2)后,增加些迷惑CPU的指令,让CPU以为后面(Data 1,Data 3)中,Data 1的地址,要根据Data 2的Load结果计算出来。
具体怎么迷惑CPU,我写在示例代码中了。
总之,(Data 1,Data 2)、(Data 1,Data 3)、(Data 1,Data 4)……,这些地址对间,也有依赖,不能并行。
如上图,从(Data 1,Data 2)直到(Data 1,Data 9),地址对中的两个地址都在一个NUMA节点。但从(Data 1,Data 10)开始,Data 1在NUMA节点0,Data 10在NUMA节点1。这个地址对的访问延迟,一定要远远大于(Data 1,Data 2)到(Data 1,Data 9)。
测试原理讲清楚了,还有一点小技巧,使用大页内存控制所需要的内存量。
主机全部内存有点大,但大页的大小是我们能控制的。

我一共分配了1000个2M的大页。NUMA Node 0还有311个大页Free,NUMA 1还有13个,才26MB。
我如果在NUMA 1上分配内存,分配30MB内存,前26MB一定来自于当前节点,NUMA 1,后面4MB就来自于NUMA 0了。这30MB,就是我们前文说的,跨NUMA节点的内存。
我这样运行我的测试程序:
./nnuma1_2 8 9 32768 2200
8:使用系统调用sched_setaffinity(),指定初始化时的CPU。包括分配内存,内存初始化。
9:同样使用sched_setaffinity(),指定运行时的CPU(就是不断的访问地址对)。
32768:地址对的间隔。32K*n。
2200:一共循环2200次,也就是一共2200个地址对。
8,是分配内存、初始化的CPU号。它属于NUMA 1。NUMA 1只剩13个大页了。我的测试程序分配了70MB内存,前26MB来自于NUMA 1。后面的来自于NUMA 0。
测试结果如下:
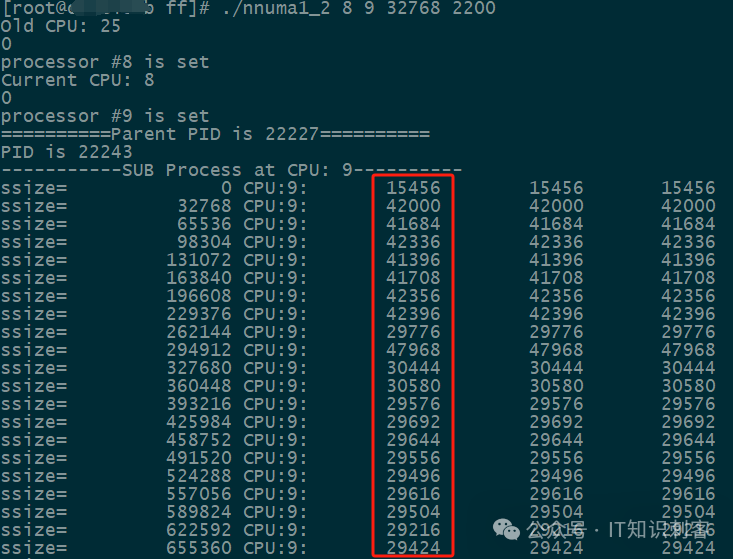
红框中那一列,就是访问地址对的周期数。为了避免波动的影响,这里是100次读的平均值。
(访问100次地址对,那不就有Cache的影响了吗,放心,Cache的影响已经被排除了)
我一共分配了70MB内存,如下图:
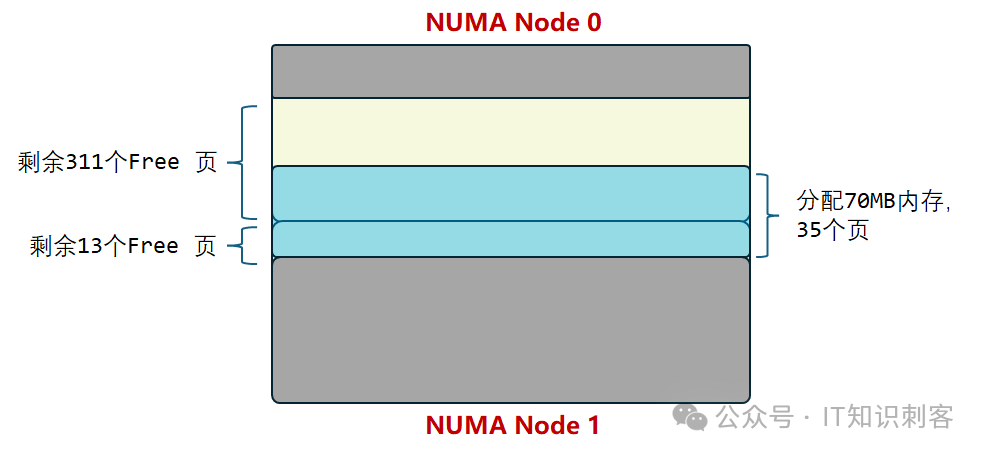
(注,分配得到的70MB内存块,只是在虚拟地址上连续,在物理地址上,它们大概率并不完全连续)
初始化阶段,使用sched_setaffinity(),在CPU 8上初始。CPU 8属于NUMA Node 1,也就是在NUMA Node 1上分配70MB内存。
但NUMA Node 1上只有13个Free的大页了,所以,最终分配得到的70MB内存块,跨了NUMA 1和NUMA 2两个节点。
程序的执行阶段,又使用sched_setaffinity(),转到CPU 9,CPU 9也是NUMA Node 1,对CPU 9来说,访问前26MB内存的地址对,延迟会低一些,因为Data 1和Data N都在同一Numa节点。
超过26MB后,地址对中Data1在NUMA 1,Data N在Numa 0,延迟会大大增加。
一共2200个地址对,我把结果放入Excel,生成如下图表:
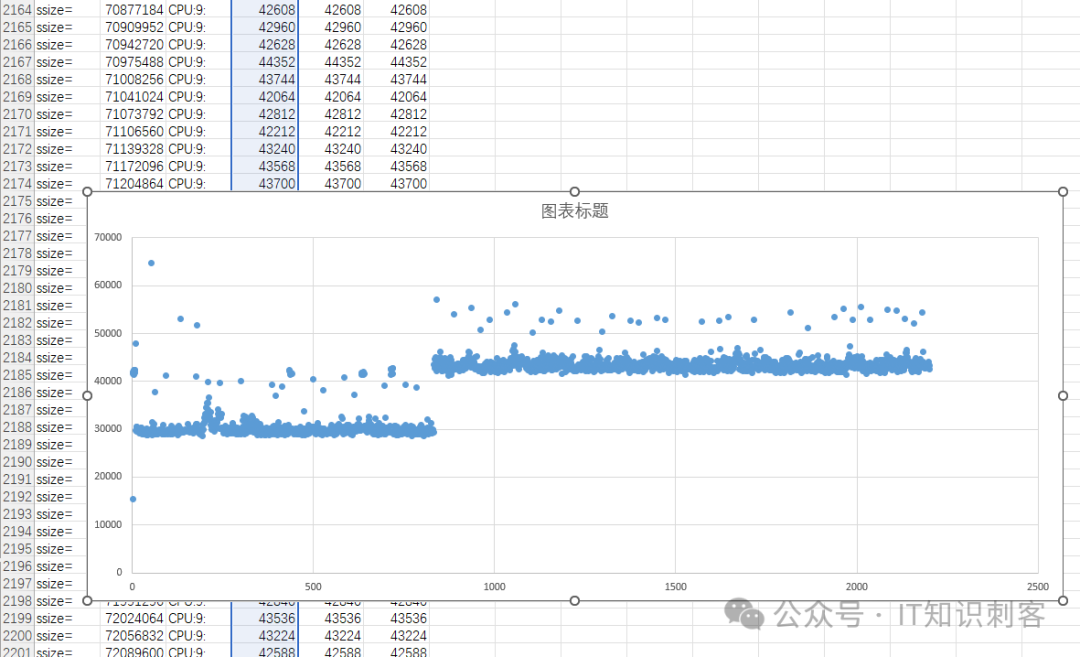
不得不说,Excel这种小型数据库功能是真强。生成散点图后,一眼就能看到NUMA的影响。
延迟陡然上升的拐点,是第833个地址对处。之后的Load,Data 1是内存块起始处,处于NUMA 1;Data N是NUMA 0了,所以延迟大大上升。
可以认为每个地址对重复100次。实际上为了避免Cache命中,做了些调整,但仍可以认为是对同一地址对重复了100次Load。这里主要强调一点,Cache命中的影响,被排除了,所有地址对的load,都是从内存Load。
第833个地址对前,地址对的两个,都是在同一NUMA节点,100次循环,共200次内存Load,一共耗时,从图上看在30,000周期上下,除以200,一次同NUMA内存Load,150个周期。我机器的主频是2.1GHz,150个时钟周期,1纳秒/2.1 * 150,一次同NUMA的内存访问,71纳秒。
833个地址对后,地址对中的前一个,在NUMA 1,另一个在NUMA 0,跨了NUMA节点。总延迟,在散点图上看,在43,000周期上下,就以43,000周期为准吧。
跨NUMA的访存延迟怎么计算,不要直接43,000除以200啊。因为发起访存指令的是CPU 9,它属于NUMA 1。地址对中前一个地址,就在NUMA 1。后一个地址在NUMA 0。
我们已知同NUMA节点时的平均访存延迟是150个周期,43,000-150*100,先把地址对中,不跨NUMA节点的Load去掉,再除以100,最终结果这样计算,(43000-150*100)/100.,得 280个时钟周期,130纳秒。
但其实这280个周期中,有20个周期左右,在处理SNOOP的东东。实际的访存延迟,是在260周期左右,120纳秒到130纳秒间。
注:
这块CPU使用基于目录的SNOOP,20个周期为SNOOP操作的延迟。
所以,你看,跨了NUMA节点,延迟并没有翻倍,但从71纳秒到120-130纳秒,离翻倍也不远了。
另需注意,我这是两个NUMA节点,NUMA节点越多,差异越大,翻个几倍,都是正常的。
另外,我们再看看第833个地址对:
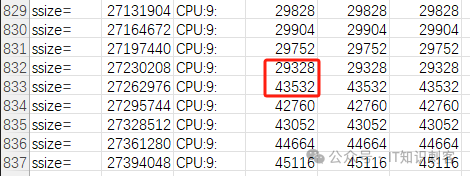
从833这里开始,延迟大大增加,说明开始跨NUMA节点了。
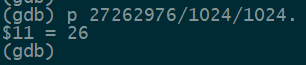
这里的Size是地址对的间距,用它除一下:27262976/1024/1024,正好26MB。NUMA 1上只剩13个Free的大页,也就26MB。后面的内存都是来自于NUMA 0的内存。
这次测试的结果,基本分析完了(还有提了一嘴的SNOOP部分,这个IT知识刺客另开新篇分析)
然后,刚才是“./nnuma1_2 8 9 32768 2200“这样执行的,在CPU 8上分配内存、初始化,在CPU 9上运行测试。
现在,改成这样:./nnuma1_2 8 1 32768 2200。在CPU 8上分配内存、初始化,在CPU 1上运行测试。相当于在NUMA 1中分配内存、初始化,在NUMA 0的CPU中测试。结果如下:
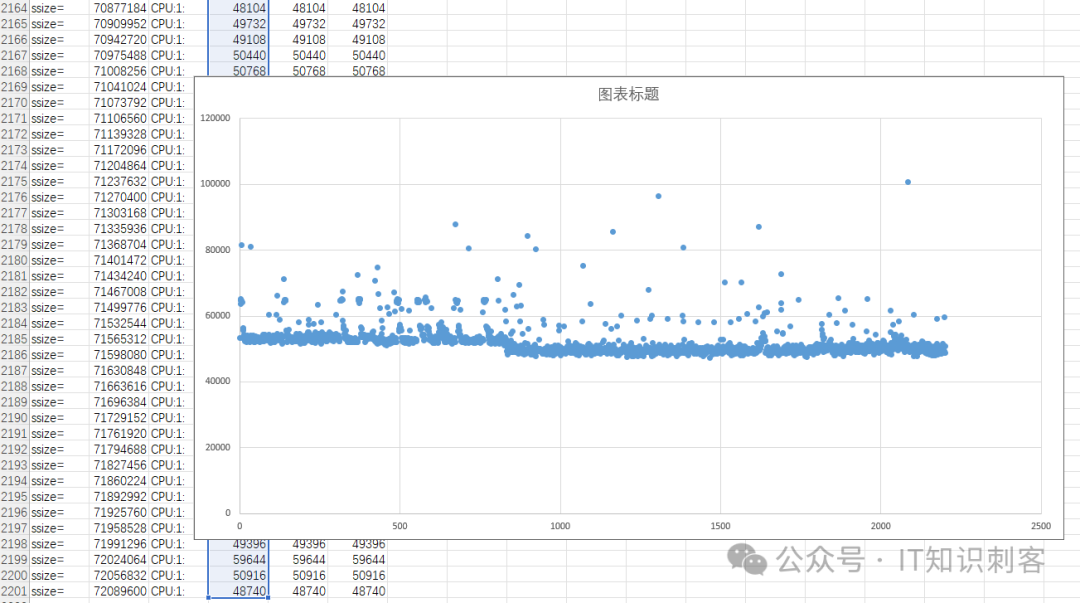
拐点仍在第833个地址对。
但是前832个地址对慢,因为前面26MB内存,来自于NUMA 1,和运行测试的CPU 1,不属一个NUMA节点。
看时间,前832个地址的延迟在52,000周期上下。每个地址对100次循环,两次跨NUMA内存访问。
这样计算下来,一次内存读取操作,延迟260周期,120多纳秒。和前面的分析是一致的。
第833个地址对后,延迟在49,000周期上下。地址对的第一个地址在内存块起始部分,对于CPU 1来说,跨了NUMA节点。但地址对的第二个地址,和CPU 1就是同一NUMA节点了。
所以49,000 - 26,000 – 15,000 ,还剩8,000周期。平均到200次内存读诹,每次40个周期。这40个周期是SNOOP消耗的。
SNOOP实在有点超肛了,以后单开新篇去讲它。而且我们的测试程序,只能感知到SNOOP,要精确的测量SNOOP,还需要专门设计测试程序。
好了,本篇就到这儿吧。
其实这个测试程序能测量的多少非常多,它的核心部分如下:
for(i=0; i<=loop_number_1; i++){ssize = i * step_size;sum_tsc = 0;max_tsc = 0;min_tsc = 0x7fffffffffffffff;for(j=0; j{begin = rdtsc();__asm__ __volatile__("mov %2, %%r13\n\t" 增加一个循环,两层循环。定为100"lea %0, %%r8\n\t" // 内存块开始地址"TOP_LOOP:\n\t""mov $256, %%rax\n\t""mull %%r13d\n\t""add %%rax, %%r8\n\t""mov %3, %%r12\n\t" // 循环次数 如果为2,就是一对地址。这里将保持为2。"LOOP1:\n\t""mov (%%r8), %%r14\n\t" // 读一对地址中的A"add %1, %%r14\n\t" // 读取A的结果,加 i * 64"add %%r14, %%r8\n\t" // 得到一对地址中的下一个地址:B。(依赖)"sub $1, %%r12\n\t" // 循环"jne LOOP1\n\t" // 向上跳转"sub %%r14, %%r8\n\t" // 读取A的结果,加 i * 64"sub %%r14, %%r8\n\t" // 读取A的结果,加 i * 64"sub %%rax, %%r8\n\t" // 以上三行迷惑CPU,在地址对间产生依赖"sub $1, %%r13\n\t""jne TOP_LOOP\n\t"::"m"( *arr ),"r"(ssize),"i"(100),"r"(loop_number_2) //立即数1:循环次数 立即数2:步进:"rax","rdx","r8","r12","r13","r14");end = rdtsc();end = end - begin;sum_tsc += end;max_tsc = (max_tsc > end ? max_tsc : end);min_tsc = (min_tsc < end ? min_tsc : end);}fprintf(stderr, "ssize=%15ld ", ssize);fprintf(stderr, "CPU:%d:%12ld %12ld% 12ld\n", cur_cpu, sum_tsc/RUN_NUM, min_tsc, max_tsc);
全部代码,我找个地放发上来啊。
理解了这个测试程序,和测试结果,就真正的理解NUMA了。
