看到知乎一个问题,CPU线程数和核心数有什么关系。CPU线程数,这是一个专有名词,也可以叫“CPU超线程数”。我怀疑题主把它和操作系统线程搞混了。都是线程,所谓一笔写不出俩线程,还的确挺容易搞混的。
超线程吗,就是CPU内的多线程呗。其实,真相并不止于此。操作系统线程,你可以使用pthread_create()创建,man一下:[root@oracledb ~]# man pthread_create
就能看到相关说明和简单的例子。我们不详述了,这个基本都懂。我们后文称pthread_create(或类似函数)创建的,为“操作系统线程”。而CPU的线程数,因为也有“线程”二字,它好像也可以指操作系统线程,但更准确,它就是指CPU的超线程,也是我们常说的逻辑CPU。一般CPU超线程数为2,也可以说CPU的线程数为2,就是一个物理Core,又可以当两个逻辑Core来用。在一些资料中,也把超线程为2,称为CPU线程数为2。可是,别看人家叫“逻辑Core、逻辑CPU”,可一点都不“逻辑”,人家可是正儿八经“物理”的。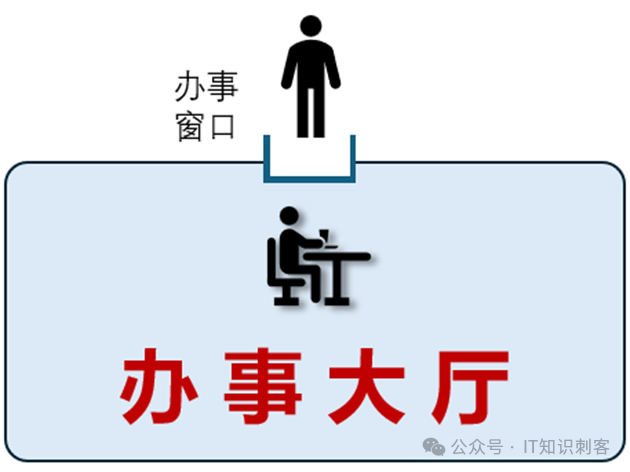
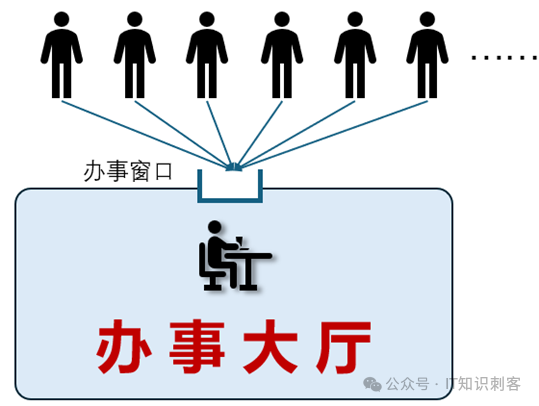
图1
我把CPU中的“计算单元”等内部组件比作图1的办事大厅,办事大厅有个对外的窗口,大家排着队,在窗口这儿办事。注:
计算单元是啥,先不必计较,就是CPU内完成计算、逻辑等的物理电路部分。
“办事”的时候,只能一个一个的来,两个人不能在一个“办事窗口”同时办事。
如果后面办事大厅中工作人员的时间允许,允许两个人同事办事,要怎么办呢?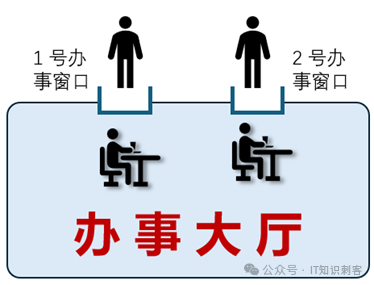
对于CPU来讲,和程序直接对接的,首先是那些个通用寄存器,比如rax、rbx、……,包括状态寄存器eflags等等。还有SIMD(Intel CPU)的寄存器,xmm0~15/ymm0~15/zmm0~15。 SIMD寄存器是包含关系,比如zmm0的低256位是ymm0,低128位是xmm0。增加一个窗口的成本是很高的,像SIMD寄存器,都很大,如果是AVX512,一个zmm寄存器512位,64字节。16个zmm寄存器还挺大的。而且,除了对外的窗口(通用寄存器),办事大厅内部,也要进行些物理改造。这个就有点太偏CPU底层了,我简单说下,你有个大概的印象就好。比如CPU内,内存的读、写都要放在内存排序区中。从内存读的指令,被放在Load Buffer中(简称LB,LB队列),向内存写的指令,被放在Store Buffer中。因为SB、LB中的读写要排序,两个程序的读、写,没必要一起排序,各排各的就好。简而言之,一句话:两个对外的“窗口”不能共享一个SB、LB。SB、LB也要准备两套。等等吧,除了通用寄存器、SB/LB两队列,还有些其他的内部组件,要分开。总之,就是前面的窗口要两套、里面有些集成电路,也要分成两套。所以,逻辑Core,还真不是逻辑。人家是有真东西的,是真要在Core中加上一堆物理的集成电路,才能把一颗Core,当两颗用。你可以理解为,一条公路本来只能一个人用,现在要允许两个人同时用,那就要装个红绿灯啥的,以免两个人起冲突。所以,超线程出的逻辑CPU,并不是纯“逻辑”,人家是有真东西的。图3相当于操作系统线程,每个人在一个窗口前办事儿。每个人10厘秒,无论事儿办完没办完,轮到下一个人办。这其实也部分解答了另一个问题,“操作系统线程数可以很多,为什么CPU的超线程数不能太高?”通常超线程数都是2,也就是一个物理Core变两个逻辑Core。为什么不能多搞点?因为和操作系统线程不一样。从现代CPU的角度上说,操作系统多线程是纯软的,是没有成本的(当然,线程数太多影响性能)。CPU线程数是需要在CPU中增加额外的集成电路的,是有成本的。而且,CPU就那么大块地方,“办事窗口”和LB/SB占的地方多了,计算单元、分枝预测、各级Cache 等等,能占的地方就少了。这在经济学中有一个词:机会成本。那么,对于目前为2的超线程数2来说,机会成本是否值得?要回答这个问题,先要搞清楚CPU超线程的主要目的是啥!CPU在运行时,常会因为一些事情被阻塞,这里通常用术语STALL表示CPU流水线阻塞。一次读、写内存,通常需要100到500个时钟周期。而每个时钟周期,都可以有一到多条基本运算完成。比如整型数的加、减法,可以认为只需要一个时钟周期。注:
CPU是流水线的,每个时钟周期都可以有1条、甚至4或更多条基本运算完成。但一条基本运算并不能在一个时钟周期内完成。
打个比方吧,普通的指令,相当于在一条直路上跑,if/swith/while这些,相当于拐弯,访存,相当于等红灯。CPU在执行某个进/线程指令时,遇到Cache Miss,发起访存。当访存过多时,就会STALL。在STALL期间,这个进/线程还在运行中,别的进/线程并不能使用这颗CPU的资源。不能因为我访问了次内存,就把我切出CPU,是吧。但因为访存的STALL,又会让CPU一下子空闲好久,这不是有点浪费吗,CPU的超线程技术就出现了。为一颗CPU添加“窗口”、LB/SB等电路,但共享后面的计算、逻辑等单元,一颗CPU变两颗CPU,一颗CPU在STALL时,另一颗CPU可以使用全部的计算、逻辑等单元。如果两颗逻辑CPU都不STALL,计算、逻辑等单元就分开,一人一半。注:
实事上,超线程CPU中,各种计算、逻辑等单元组件被分为静态单元与动态单元,静态单元只属于某一逻辑Core,即使它Stall,同一物理Core的另一逻辑Core也不能使用这些静态单元。动态单元就是两个逻辑Core间动态分配。
这样,CPU后端的计算、逻辑等单元的利用率,会大大提升。但在没有STALL时,毕竟计算、逻辑等单元要被分给两个逻辑CPU,性能还是会有所下降的。好,问题都解答完了,再延伸一下,我们的程序、软件,到底需不需要超线程?这个问题其实挺容易回答的,超线程是当有一个逻辑Core Stall时,那些在两个逻辑Core间动态分配的计算单元等,不会被浪费,另一个逻辑Core可以使用这些动态单元。如果一段程序,由于频繁的访存(L1/L2 Cache Miss)等原因,造成STALL很多,那超线程就是有必要的。如果程序的STALL很少,超线程的作用就不大,还会起到反作用。这里需要注意,超线程是否有助益,是取决于程序、软件的。但问题是,我怎么知道我的程序/软件,STALL多不多?Perf中为我们准备了非常多的性能数据,你可以“perf list”看一看:[root@oracledb ~]# perf list
List of pre-defined events (to be used in -e):
branch-instructions OR branches [Hardware event]
branch-misses [Hardware event]
bus-cycles [Hardware event]
cache-misses [Hardware event]
cache-references [Hardware event]
cpu-cycles OR cycles [Hardware event]
instructions [Hardware event]
ref-cycles [Hardware event]event]
……
这里面有好多来自于CPU的硬件计数器(也称性能计数器),所以CPU不同,数量也不同。像Intel/AMD,CPU内置的计数器多达数百个,可以提供近1000项性能资料。刚才不是说CPU内空间有限,各种组件集成电路规模多寡,都是有机会成本的吗,这么多计数器,也是有机会成本的。但这些顶级的CPU厂商,都认为性能计数器的机会成本是值得的。使用这些性能计数器,可以对程序进行Profiling,这个词叫它“画像”吧。如果一段程序是性能敏感性质的,使用CPU内性能计数器,可以对程序的运行状态,进行全方位的“画像”,了解它在CPU上运行时的真正情况。并在画像基础上,进一步优化。这往往可以使程序性能至少提升10%以上,多数程序的性能可以提升30%至100%。所以,在CPU中内置这么多计数器,让CPU“可观测”,其机会成本,是相当值得的。使用这些CPU硬件性能计数器,还有一个作用,可以观测程序到底写的好不好。好了,先不展开了,回到我们的主题,以下几个性能计数器,可以让我们一窥CPU运行时的STALL:cycle_activity.stalls_total:首先,最直接的一个,就是此计数器。stalls_total,这已经告诉我们了,它是衡量总的STALL周期数的。严谨点说,它是记录执行阶段流水线的STALL时钟周期数(忘了这句话吧,就当它是统计总STALL周期数的,也没任何问题)。cycle_activity.stalls_mem_any:它可以统计因内存而产生的STALL周期数。虽然这也没问题,但我还是严谨点说下吧,其实这个计数器的原理是这样的,在流水线进入执行阶段时,如果有某个时钟周期没有任何一条uOP被运行(即STALL),并且,有正在等待的内存访问(包括L1/L2/L3,和内存),那么此计数器就加一。同上,“严谨点说”这一段,你可以忽略。有人认为“访存”,是所有程序最主要的STALL原因,还创造了内存墙这个词。但对很多程序来说,还会有其他STALL的原因。通过计算stalls_mem_any在stalls_total中的比例,可以让你感受下内存墙影响到底有多大。Instructions:指令数。这个很简单,我去年曾用这个比较各个数据库在相同数据量下、执行相同SQL时的指令数。并总结为一个词:“油耗”。毕竟,同一逻辑的程序,如果Linux之神Linus用100行,你用1000行,你的油耗太高了。就像汽车,开同样10公里,你的油耗比Linus高10倍的话,你的车不如Linus(你写的代码不如Linus)比较的结果,各个国产数据库的油耗遥遥领先。其中最引人注目的,就是华为高斯,清场式领先。一会,你会再看到这个比较。cycles:周期数。即,时钟周期数。如果主频是4Ghz,4个时钟周期1纳秒。一个时钟周期0.25纳秒。我的测试目标,是OLTP型数据库应用,我以一条简单的SQL为例:select * from vage2 where id1=?perf stat -einstructions:u,cycles:u,cycle_activity.stalls_total:u,cycle_activity.stalls_mem_any:u -p 28477
其中 28477 ,为进程号。如果是MYSQL、华为OpenGauss,这里要改为“-t 线程号”。“:u”,代表只在指令是用户态时才进行计数。其实就是去除操作系统的影响。步2:在28477进程的Session中,执行SQL:postgres=# execute cs(1);
id1 | id2 | c1 | c2
-----+-----+----------+---------
1 | 101 | AAAAA111 | aaaaaa1
(1 row)
prepare cs(int) as select * from vage2 where id1=$1;
并且已经执行execute cs(1)多次。我是统计Cache Plan的效果。因为不使用Cache Plan的话,指令数等太多,很多指标会更差。步3:回到perf中,Ctrl+C,就能看到效果了:[root@oracledb ~]# perf stat -einstructions:u,cycles:u,cycle_activity.stalls_total:u,cycle_activity.stalls_mem_any:u -p 28477
^C <-------按Ctrl+C
Performance counter stats for process id '28477':
60,054 instructions:u # 0.17 insn per cycle
357,168 cycles:u
302,468 cycle_activity.stalls_total:u
122,362 cycle_activity.stalls_mem_any:u
1.007995611 seconds time elapsed
[root@oracledb ~]# perf stat -einstructions:u,cycles:u,cycle_activity.stalls_total:u,cycle_activity.stalls_mem_any:u -p 1350
^C
Performance counter stats for process id '1350':
63,792 instructions:u # 0.18 insn per cycle
344,998 cycles:u
296,039 cycle_activity.stalls_total:u
146,859 cycle_activity.stalls_mem_any:u
1.155029629 seconds time elapsed
还有遥遥领先的国产数据库:
[root@localhost ~]# perf stat -einstructions:u,cycles:u,cycle_activity.stalls_total:u,cycle_activity.stalls_mem_any:u,L1-dcache-loads:u -t4504
^C
Performance counter stats for thread id '4504':
262,662 instructions:u # 0.15 insn per cycle
1,681,672 cycles:u
1,411,605 cycle_activity.stalls_total:u
614,187 cycle_activity.stalls_mem_any:u
1.959583056 seconds time elapsed
我把数据都写进一个表格:
| PG15.7 | Oracle
11.4 | Open Gauss
5.0 |
Instructions | 60,054 | 63,792 | 262,662 |
Cycles | 357,168 | 344,998 | 1,681,672 |
cycle_activity.stalls_total | 302,468 | 296,039 | 1,411,605 |
cycle_activity.stalls_mem_any | 122,362 | 146,859 | 614,187 |
高斯不出意外的遥遥领先,相同数据量、相同逻辑的SQL,单从指令数上,从原生PG多4倍。这是使用了CachePlan的结果,否则,高斯的指令数比原生PG高7倍以上(这说明高斯把很大精力花在优化器上)。PG和Oracle,则相差不多,分别使用了35万多、34万多个时钟周期。talls_total呢,多达30万周期上下。85%的时钟周期,都在STALL。高斯虽然指令数多、周期多,但单从STALL周期数上看,也是85%左右的时钟周期在STALL(准确是83.9%)。三种数据库在执行一条简单OLTP型SQL时,STALL周期都占总周期数的80%以上。就像上班时,你的80%以上时间,都在因为等待一些资源,而是空闲状态。提高效率的方法只有一个吗,再给你加点工作,让你在等待资源时、可以去忙别的工作。前面用1000字左右,介绍了perf,现在回到我们的主题,还记得前面的结论吗,CPU的超线程,是为了在STALL期间,让另一个逻辑Core可以有效的利用CPU内的硬件资源。你看数据库的STALL这么多,所以对于OLTP型小SQL来说,超线程是有利于提升CPU内资源利用率的。再展开点说一下,stalls_mem_any在stalls_total中的占比,Oracle勉强50%,PG只有40%,高斯是43%。所以说,对于OLTP SQL,所谓“内存墙”,也并不是那么的高。最后,好多人都说就算对数据库来说,超线程也是有害无益,这好像跟我测试的结果相反,真实原因,是现在的数据库内核,并没有考虑CPU层级的硬件特性,纯靠编译器和操作系统,并不能发挥出超线程等CPU内特性的真正潜力。