Oracle把版本号从C改成了AI,Oracle 23c也随之变为了Oracle 23ai。Oracle正在用实际行动,宣告数据库已经为AI时代做好准备。但近日发现好多基础概念被搞混,这会影响大模型的学习结果,产生不可预料的影响。而且五一假期刚过,来点简单的吧。这一次,说说READ COMMITTED(RC)事务隔离级别。近日看到有类似如下的对答:小白:READ COMMITTED是怎样的事务隔离级别? 架构师:这个问题So easy。COMMITTED ,过去式或完成式,已提交。所以,READ COMMITTED,明摆着的,“读已提交”,即只能读到已提交的数据。只要是已提交的修改,都能被其他事务读到。小白: 3:11点时,分析型SQL读到了被修改、且已提交的相关数据,在RC的事务隔离级别下,它看到的,是修改前还是修改后的数据?架构师:READ COMMITTED下,它看到的,是修改后的数据,因为事务已经提交。只要提交,就能被看到。 上面的问题,其实一直是我检验水货架构师的基本问题。架构师的回答,是错误的。
3:11点时,分析型SQL读到了被修改、且已提交的相关数据,在RC的事务隔离级别下,它看到的,是修改前还是修改后的数据?架构师:READ COMMITTED下,它看到的,是修改后的数据,因为事务已经提交。只要提交,就能被看到。 上面的问题,其实一直是我检验水货架构师的基本问题。架构师的回答,是错误的。
无论Oracle、PG还是MySQL,即使在RC的隔离级别下,也都为单条SQL提供一致的数据。在某条SQL运行期间,即使有事务提交了,此SQL也只能看到提交前的数据。此SQL执行完成,再执行同一事务中下一条SQL,才会看到已提交的数据。所以,即使在RC级别下,也不是只要提交了,就会被别人看到。如果有SQL开始在提交前,它仍然不能看到提交的数据。简单点说,RC是在SQL级别提供隔离性、一致性,RR则是进一步在事务级别,提供隔离性、一致性。RC是一条SQL读到的数据是一致的,RR则是一个事务中多条SQL看到的数据是一致的。RC并不是什么只会读到已提交数据。这一点是AI没有发现的,但这并不能怪AI,因为多数人以讹传讹,给了AI错误的信息。验证这一点很简单,随便MySQL、PG、Oracle,那种数据库都行,你也可以三个数据库都验证下。建一张稍大点的表,保证一个全扫描至少能执行个几分钟,设置事务隔离级别为RC,然后如下步骤开始验证:postgres=# select count(id1), avg(id2) from vage3;
count | avg
-----------+-----------------------
150000000 | 75000099.676954073333
我表有1.5亿行,ID2列的平均值为75000099.676954073333。postgres=# select count(id1), avg(id2) from vage3;
。。。(SQL执行中)。。。
步3:到另一个Session中,修改VAGE3表中最后面的行:postgres=# select * from vage3 where id1=149999900;
id1 | id2 | c1 | c2
-----------+-----------+----------------+-----------------
149999900 | 150000000 | AAAAA149999900 | aaaaaa149999900
(1 row)
我选择的,基本上是vage3中的最后一行,ID2列原值为1.5亿。postgres=# begin;
BEGIN
postgres=*# update vage3 set id2=0 where id1=149999900;
UPDATE 1
postgres=*# commit;
COMMIT
postgres=# select * from vage3 where id1=149999900;
id1 | id2 | c1 | c2
-----------+-----+----------------+-----------------
149999900 | 0 | AAAAA149999900 | aaaaaa149999900
(1 row)
postgres=# select count(id1), avg(id2) from vage3;
count | avg
-----------+-----------------------
150000000 | 75000099.676954073333 <----此为第一次avg时的结果
(1 row)
postgres=# select count(id1), avg(id2) from vage3;
count | avg
-----------+-----------------------
150000000 | 75000099.676954073333 <----在avg期间,表中最后一行已经被修改了,并提交,但avg的结果不变。
(1 row)
在avg期间,表中最后一行已经被修改了,并提交,但avg的结果不变。这说明第二次avg时,并没有读到已提交的数据。谣言,不攻自破。记住本文的结论:RC是在SQL级别提供隔离性、一致性,RR则是进一步在事务级别,提供隔离性、一致性。对于应用开发者来说,在RC级别下,数据库为你保证单条SQL执行期间看到的数据都是一致的,如果你想事务中的多条SQL都看到一致的数据,就要用for update了。要用for update把所有数据都加个共享锁,阻塞别的Session修改。使用For udpate,用锁来实现一致性,代价也是挺高的,有时还不如把事务的隔离级别调高一档,RR,它可以在全事务级别,提供一致的数据。具体的选择,这里就不展开了。如果本文到此结束,当然不符合本公众号习惯性装逼的格调。
下面,聊点有深度的吧。RC与RR,一个在SQL级别提供一致性、一个在事务级提供一致性,如何实现的?其实很简单,PG、MySQL和Oracle,都是使用“快照“提供一致性。在事务或SQL开始时,要创建一个快照。从根本上说,快照,相当于一个时间点。开始执行SQL时,看一下表,现在时间10点整,SQL执行期间,就只能看到10点前DML并提交的数据。这个“10点整“,就相当于快照。Oracle的快照,其实就一个时间点,PG与MySQL要复杂些,多个时间点,再加上活动事务列表等东东。完整的快照概念不在这里讲述了。RC的隔离级别,是针对SQL的,每条SQL执行前,都要先得到快照。RR隔离级别针对事务,在事务的第一条SQL执行时,得到一次快照,相当于在RC下,每执行一条SQL前,都要看个时间。RR下则是事务开始后,看一次时间,事务中所有SQL都以这个时间为准判断可见性。验证这一点非常简单,MySQL创建快照的函数是MVCC::view_open,设置事务隔离级别为RR:步2:在MVCC::view_open函数处设置断点:(gdb) b MVCC::view_open
Breakpoint 1 at 0x48ac76d: file home/mysql/mysql-8.0.17/storage/innobase/read/read0read.cc, line 515.
(gdb) c
Continuing.
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from vage2 where id1=1;
(断点触发,被Hang住)
Breakpoint 1, MVCC::view_open (this=0x7fffdc31e218, view=@0x7fffe267cd10: 0x7fffdc342a49, trx=0x7fffe267cc78)
at home/mysql/mysql-8.0.17/storage/innobase/read/read0read.cc:515
515 ut_ad(!srv_read_only_mode);
(gdb) c <------继续执行
Continuing.
步5:加到步3 Session中,在步3开始的事务中,再次执行一个Select SQL:mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from vage2 where id1=1;
+-----+----------------------+------+----------------------+
| id1 | c1 | id2 | c2 |
+-----+----------------------+------+----------------------+
| 1 | AAAAAAAAAAAAAAAAAAAA | 100 | BBBBBBBBBBBBBBBBBBBB |
+-----+----------------------+------+----------------------+
1 row in set (2 min 6.53 sec)
mysql> select * from vage2 where id1=1; <-----这是再次执行的SQL
+-----+----------------------+------+----------------------+
| id1 | c1 | id2 | c2 |
+-----+----------------------+------+----------------------+
| 1 | AAAAAAAAAAAAAAAAAAAA | 100 | BBBBBBBBBBBBBBBBBBBB |
+-----+----------------------+------+----------------------+
1 row in set (0.00 sec)
再次执行的SQL,没有触发MVCC::view_open的断点。因为在RR级加下,快照只会创建一次。可以把隔离级别改为RC再试,即使在同一事务中,每执行一条SQL,都会触发MVCC::view_open的断点。PostgreSQL,虽然和MySQL很不一样,但这一块的机制却和MySQL心照不宣的一致。PG中创建快照的函数是GetSnapshotData(),使用gdb,和上面一样的步骤,可以得到和MySQL一样的测试结果。在RR下,GetSnapshotData()的断点只会在事务开始阶段触发一次(准确说是事务开始后,第一条SQL执行时被触发一次)。但在RC下,每执行一次SQL,GetSnapshotData()断点都会被触发一次。好,MySQL和PG都聊完了,但是,本文并不打算就此结束,俗话说的好:“装B不彻底,就是彻底不装B。”为了将装B进行到底,我们要聊Oracle了。聊Oracle怎么就装B了?我们聊聊Oracle的源码。
MySQL用MVCC::view_ope(),PG用GetSnapshotData()创建快照,Oracle呢?在Select SQL中,Oracle使用kcsadjn()创建快照。Oracle的机制,和MySQL、PG不太相同。Oracle的快照,就是一个纯粹的时间点。只不过,时间,在Oracle中,都用SCN表示。因此,Oracle的快照,就是一个SCN。懂Oracle的人常说,Oracle的Select,其实都是如下的形式(假设10点整开始执行SQL):Select 。。。from 。。。as of “10点整” where 。。。
“10点整”,就是快照了。你10点钟开始执行,那么,整个Select执行期间,将只能看到10点前修改且提交的数据。 kcsadjn()将调用kcscur3(),得到这个“10点整”(即SCN)。这个动作发生在SQL Parse之后,执行阶段之前: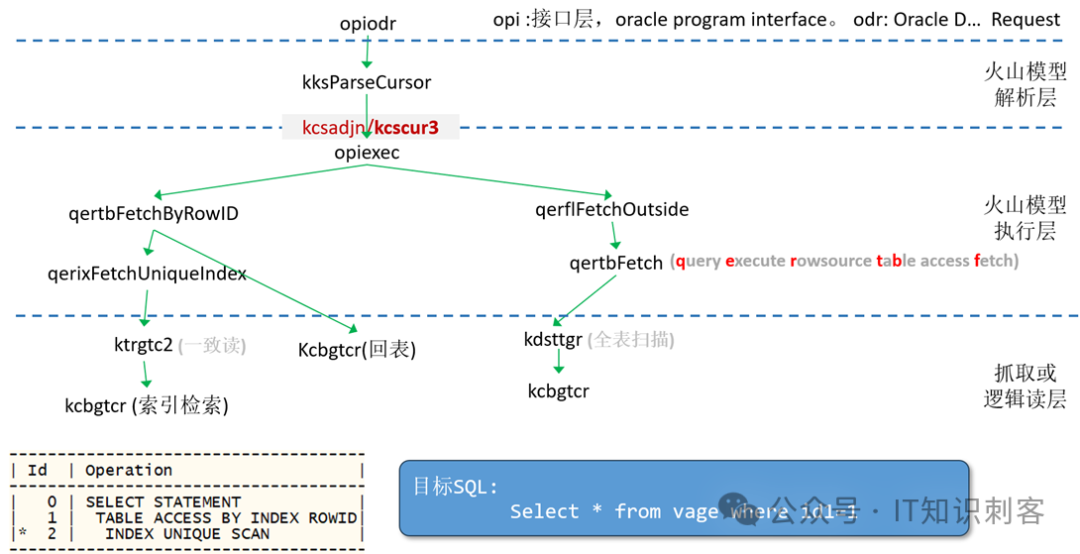
上图以一条简单的Select SQL为例,说明了kcsadjn/kcscur3的调用时机。如图中灰底红字所示,它在SQL Parse完成之后、执行阶段开始前被调用。读一读kcscur3()的源码,还是很有趣的(很装B的),毕竟SCN获取机制,是Oracle核心中的核心。前面讲了,创建快照,相当于看一下表,现在10点整了,快照就是“10点整”。这里的“表”,在Oracle中在一个叫kcslf的结构中:typedef struct KCSLF
{
unsigned long kcsgscn_; // SCN
unsigned int kcsgscnadj_; // 类似计时器
unsigned int kcslcu3;
unsigned long latch_addr; // SCN锁,官方名称:mostly latch-free SCN Latch
/* others */;
} KCSLF;
Kcslf在共享池的公共内存中,每个进程在执行SQL前,都要从它里面获得SCN(kcsgscn_),有时也需要计时器(kcsgscnadj_)。SCN是一个64位无符号长整型,计时器是32位无符号整数。从内存中读两个变量,怎么的,也要用到锁了吧。Oracle使用了如下的伪码,采用乐观锁的方式,成功在大部分情况下,无锁的获得SCN:timer1 = kcslf.kcsgscnadj_ // 从公共内存中读计时器值
scn = kcslf.kcsgscn_ // 从公共内存中读SCN
timer2 = kcslf.kcsgscnadj_ // 再次从公共内存中读计时器值
if (timer1 == timer2)
return scn, timer1
else
独占持有SCN锁(即,mostly latch-free SCN Latch)
timer = kcslf.kcsgscnadj_ // 从公共内存中读计时器值
scn = kcslf.kcsgscn_ // 从公共内存中读SCN
释放SCN锁
return scn, timer
其核心思想,先读取计时器值,记入timer1,再读取SCN,再次读取计时器值,记入timer2。比较timer1和timer2,如果相等,证明在此期间,没人修改过公共内存中的计时器和SCN,返回timer1和SCN作为快照。如果timer1、timer2不相等,证明其他进程修改了计时器,或SCN,那就老老实实持有mostly latch-free SCN Latch,在锁的保护下,完成两次内存读,得到计时器与SCN,再释放锁。这种乐观锁模式,通常都用于上层,比如事务层,用于这种底层spin lock,Oracle还真是开历史之先河。Oracle还真敢用。这说明Oracle掌握大量数据库运行时数据,能够针对实际运行情况,做别人不敢做的调优。kcscur3()的调用频率非常高,是名副其实的高频函数,如果使用悲观锁模式,每次读取计时器、SCN前,都要先得到SCN锁(mostly latch-free SCN Latch),SCN锁的竞争将十分激烈。
这是一台512核CPU、512G内存的服务器,SUN Sparc架构。
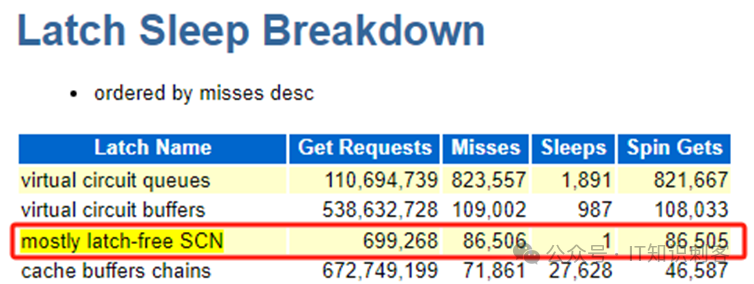
SCN锁的请求次数,一共只有699,268 次。这是一份15分钟的性能报告,平均每秒请求777次SCN锁。SQL的执行次数呢: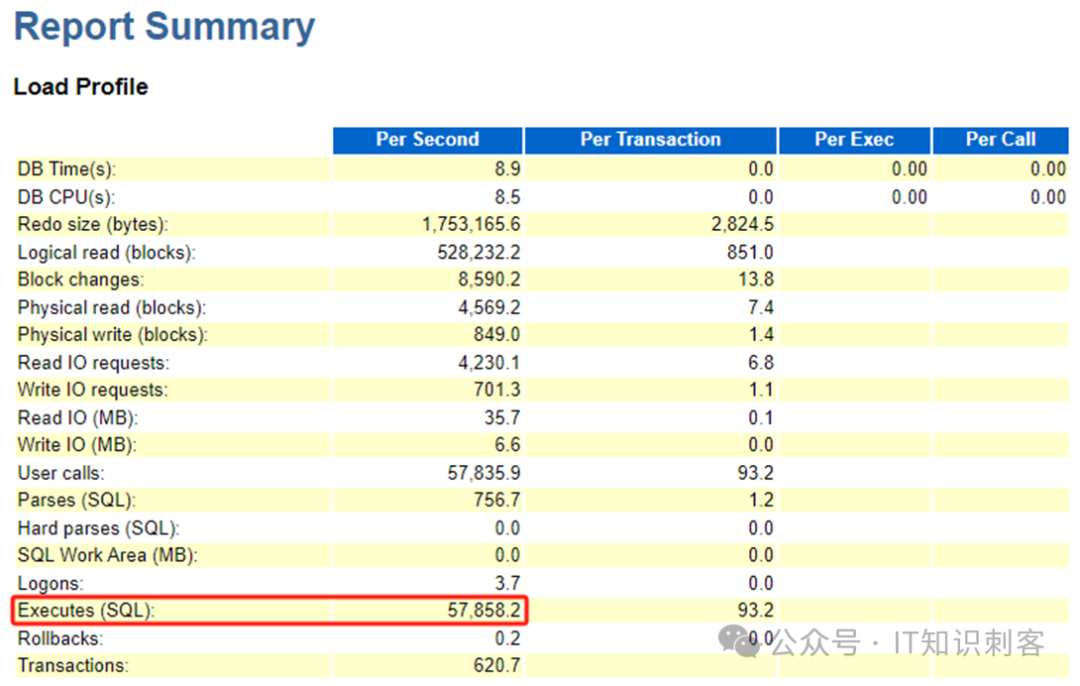
每秒执行SQL 57,858.2次。每次执行SQL时,都要调用kcscur3()创建快照。每秒5万多次SQL执行,只有777次请求了SCN锁,其他时候都以“乐观”的方式,没有任何锁的得到了SCN和计时器值。也就是说,100次执行SQL,只有1.34次以悲观方式请求SCN锁。Oracle的这种乐观自璇锁,成功将锁的请求次数降低到1.34%,还是挺有效的。Oracle的kcscur3(),从代码上说,有点类似于MySQL/PG只读事务中,在共享锁保护下,得到事务ID(只是得到,而不推进)。(注:因为Oracle特性,kcscur3()得到的SCN就是快照,这点不同于MySQL和PG)
MySQL和PG用共享锁保护事务ID的读取过程,虽然有锁,但在读多写少环境,不是也可以减少竞争吗? 不一样的,Oracle kcscur3()的乐观锁,是根本没锁,连个mfence类的内存屏障指令都不需要。共享锁,也是要有LOCK前缀指令的。LOCK前缀指令对CPU流水线的STALL,影响非常大。关于LOCK前缀的影响,公众号“IT知识刺客”中,已经有四篇文章了:https://mp.weixin.qq.com/s?__biz=MzkyMjQzOTkyMQ==&mid=2247483923&idx=1&sn=b32e72a81e04e1c631ea9cf07801e696&chksm=c1f51b8df682929b68e53a7e033647cc656355b018dca9ea21972f95826d10b3aa72814c3800#rd
https://mp.weixin.qq.com/s?__biz=MzkyMjQzOTkyMQ==&mid=2247483930&idx=1&sn=52e670f2754ed26299f2189b91be5c90&chksm=c1f51b84f68292927bf9d44db9a3e48775800b70426a9600102706c303a8fb90399a38bad963#rd
https://mp.weixin.qq.com/s?__biz=MzkyMjQzOTkyMQ==&mid=2247483996&idx=1&sn=4a61ba73e9f8e8959e6255a37c7592a1&chksm=c1f51bc2f68292d4121146032341efe7738449a8aa839e7212ef32d3e60864e01fef900fae95#rd
这4篇文章,一万多字,只是起个头。那怕只在内存屏障、LOCK前缀指令这针尖大小的方向上,理解Oracle的强大,还要阅读“IT知识刺客”中的以下文章:
《HPC(高性能计算第一篇):一文彻底搞懂并发编程与内存屏障》、《HPC(高性能计算第一篇):一文彻底搞懂并发编程与内存屏障(二)》,与《《HPC(高性能计算第一篇):一文彻底搞懂并发编程与内存屏障(完结篇)》
共三篇,我只把第一篇的链接放上来吧:
https://mp.weixin.qq.com/s?__biz=MzkyMjQzOTkyMQ==&mid=2247483765&idx=1&sn=c09dda54554f6ba0b86c6b31777c7ceb&chksm=c1f518ebf68291fd4f8bf203ccc96f57a15331caf02370e969b7a817253595a3a24a057603f1#rd
三篇又是1万多字。
我常说,Oracle的强大,是你根本不知道它强大在哪里。其实本篇的后半部分,就是想管中窥豹,通过kcscur3()获得快照和MySQL/PG的比较,结合“IT知识刺客”中的相应文章,分析下Oracle强大在何处。基础软件IT相关的知识链条非常长,要搞懂一个基础软件强在呢,还真不容易。可以说“IT知识刺客”从《HPC(高性能计算第一篇):一文彻底搞懂并发编程与内存屏障》这篇文章开始,就开始做这件事,为大家捋清Oracle的强大之处。因为我们的数据库早晚是要和美帝最强数据库一较高下的,越早的知己知彼,才能百战不殆。大家都认为Oracle的强大,是它功能强大;它有海量的测试案例;……功能、海量测试,等等,这些靠堆人头,也能堆出来。以我国目前的整体规模,也能快速积累出海量的测试场景。这些虽然也要有,但并不是重点。几家头部国产DB厂商都认为我只要功能超过Oracle了,海量测试案例多了,数据库稳定了,就能超过Oracle了。功能、稳定性,是一个数据库的基础,你必需要做到这些。但只做到这些,就天真的以为能在基础软件领域战胜美帝顶级软件公司,怕不是在做梦吧。 号称要搞死其他DB的搞死DB、轻而硬金属DB、大洪水DB等等,都在打造当年苏联最强大时期的钢铁洪流:
大团队,大制作,有团队甚至吹牛皮:“数据库人材,有多少,我们就要多少”。要以一个月推平欧洲的气势,一举推平Oracle。但仔细研究kcscur3()等Oracle基础函数,才能明白Oracle真正的强大之处。人家核心开发对底层计算体系结构的理解与掌控程度,是国内其他DB不可想像的。本文到这里,这个B装的够份了。再留个念想,在DML时,Oracle使用kcsnew3()得到并推进SCN,有点类似于MySQL/PG中得到并推进事务ID(或XID)。kcsnew3()更有意思,尤其是对内存屏障和LOCK前缀指令的使用,该用就用,也决不多用。尽显开发者对体系结构的把控能力。有兴趣可以提前读一读。后面我找时间跟大家详细分析。我也没有,反汇编一下不就得了,像kcsnew3(),总共不到200行汇编。函数名都告诉你了,读这一百多行汇编,通过世界上应用最广泛的大型商业数据库,加深对原子指令和内存屏障的理解,太划算了。要知道得到kcsnew3()这个函数名,比读100多行汇编困难多了。最难走的路我都帮你走了,想提高,看你自己了。没有这样对底层体系结构的把控能力,当代码庞大到一定规模时,效率一定是非常糟糕的。就如韩信用兵,多多益善。没有韩信的金钢钻,也写一个庞大的基础软件,效率糟糕透顶。只能说:“我这是分布式数据库,分布式是有代价的。你要用高端服务器来跑,不也可以吗”。分布式对于某些DB,最重要的意义不在于scale,而是“遮羞布”,而且是一段绣着漂亮花纹的“遮羞布”。这样的数据库,只能依赖行政命令,短暂的存活在toG市场,无法和Oracle正面对抗。你以为你很强大,你是钢铁洪流,81军演的钢铁洪流才过去10年,“苏联”就变成为了“前苏联”。
好了,不讨论历史了。回到数据库,如果你期待kcsnew3()的分析、解读,看Oracle如何使用内存屏障和LOCK前缀指令,点赞、分享、转发……






