





前言
IT知识刺客最近的更新慢了,以前还能周更。现在都要拖到两周更一次了。
并非我变懒了,主要是PG Shared Pool的开发进入关键期。另外,吕老师又要上课了。吕老师每年要给北京大学硕士研究生一年级下学期的同学们,讲述《开源软件开发基础与实践--- PostgreSQL开源开发实践》课程。
授课和写公众号目的一样,为基础软件开发领域的知识普及,做些事情。我不希望我们的基础软件一直只停留在炒作什么单机分布式这种莫明其妙概念的阶段。
写一个更快的memcpy,能做到吗?有必要吗?
第一感觉,能做到。Glibc的memcpy毕竟要讲究通用性。写一个通用的、在任何场景下都比memcpy快的super memcpy,这个很难。
但如果把“通用”性的限制去除,比如,只为数据库,甚至只为数据库中部分场景,写一个更快的memcpy,也不是什么难事。
第二个问题,有必要吗?
对于数据库这样的基础软件,能更快一点总是好事。如果能做到,为什么不呢!
Memcpy中有非常多的分枝语句,用于根据不同内存块大小情况下,采用不同的拷贝方式。
分枝语句对CPU的影响其实十分巨大,分支语句多,性能就上不去。
glibc中的memcpy,在分枝语句优化上是下足了功夫的。但这一块,我们以后再说。
对于数据库,很多时候都是在明确知晓内存块大小情况下,调用memcpy。而且,内存块大小为16字节对齐、32字节对齐的情况也不少。
比如,数据库的块(或称为页)大小为8KB(MySQL为16K),数据库中有很多8K这样的大内存块拷贝。而且源地址、目标地址,都是64字节对齐的。
针对这个特定的场景,来个定制版的memcpy_8k,无需考虑不同内存块大小、内存块对齐等等情况,一定能比memcpy快上好多。
理想往往丰满,现实通常骨感。
让我们一步步感受下现实的骨感。希望在这个过程中,能为你带来有用的知识。
// 32字节倍数memcpyvoid vage_memcpy(void *dest, void *src, unsigned int size){__asm__ __volatile__("mov %1, %%rbx\n\t" // dest值传入rbx"mov %2, %%rcx\n\t" // src传入rcx"VAGE_LOOP:\n\t" // 循环开始"mov (%%rbx), %%r8\n\t" // load 源地址数据到 r8"mov %%r8, (%%rcx)\n\t" // r8 store 到目标地址"add $8, %%rbx\n\t" // 源地址向后加8字节"add $8, %%rcx\n\t" // 目标地址向后加8字节"sub $8, %0\n\t" // size 减8字节"jne VAGE_LOOP\n\t" // size 不为0向上跳转至循环开始处:"=r"(size):"r"(dest),"r"(src),"0"(size):"rbx","rcx","r8");return ;}
一个循环,每次从源地址处读8字节数据,写入目标地址。就这样。
这里有一个基础知识点,x64的CPU,数据不能从源直接到目标。一定要先读入CPU内的寄存器,再从寄存器写入目标。
如果从源直接到目标,就叫DMA了。X64也不是不能DMA方式的memcpy,但挺麻烦的,而且性能也不好,优点当然就是省CPU。如何DMA的memcpy我们以后单写一篇(比如Intel,可以通过I/OAT DMA实现,心急的同学可以先自行百度)。
(所以,看了这里的描述,你对DMA的理解,有没有更清晰)
先不管DMA方式的memcpy了,我这个基础版supper memcpy完全使用汇编,并不是汇编比C语言更快。多数时候,gcc编译出的代码,都好于直接上汇编。
此处使用汇编的目的,是为了更统一。有可能我这里编译出的代码,和你哪里不一样。导致实测结果五花八门。
在真正的项目中,我还是建议用你使用称手的语言,需要的时候再内嵌汇编。
再来看看测试vage_memcpy的代码:
int work(void *dest, void *src, unsigned int size){__u64 begin = 0, end = 0;register int i, j;struct timeval tv1, tv2;gettimeofday(&tv1, 0);begin = rdtsc();for (i=0; i<100; i++){register char *d, *s;d = (char *)dest;s = (char *)src;for (j=0; j<12800; j++){vage_memcpy((void*)d, (void*)s, 8192);//memcpy(d, s, 8192);d += 8192;s += 8192;}}end = rdtsc();gettimeofday(&tv2, 0);printf("TSC: %ld \n", (end-begin));printf("%d.%ld - %d.%ld = %f\n", tv2.tv_sec, tv2.tv_usec, tv1.tv_sec, tv1.tv_usec, (tv2.tv_sec - tv1.tv_sec) * 1000 + ((float)tv2.tv_usec - (float)tv1.tv_usec)/1000);return 1;}
Work中有个两层的循环,内层循环调用12800次vage_memcpy,每次从src向dest拷贝8K数据,然后src和dest向后偏移8K字节。内层循环完成100MB数据的拷贝。
外层循环是让内层循环,循环100次。
仅此而已,简单吧。但相关的基础知识一点都不简单。
work函数以8K为单位,重复拷贝1,280,000次,一千多万次。但由于内存块大小固定,每次都是拷贝8K,这十分有利于CPU内的分枝预测。因此这种测试方式下,虽然glibc的memcpy有很多的分枝判断,但也会十分的高效。
另外,以8K为块大小,循环多次,完成100M的拷贝。由于地址是线性向下不断增加,这又会被CPU的“硬件预取”单元发现。如此有规律的Load内存,CPU的硬件预取会十分高效的提前把数据从内存读入各级Cache。因此软的预取指令,不会有什么效果。
上面两个基础知识点的意思是,这个测试虽然简单,但却是实打实的测试内存吞吐量。分枝、软预取,都不会影响测试结果。
下面看看在这实打实的内存吞吐量测试下,我的第一版supper memcpy,比glibc的memcpy如何!

V1版supper memcpy只有10行内嵌汇编代码。
Glibc memcpy有几百行。
你能猜一下VS的结果吗?
[root@localhost ff]# gcc -g memcpy1.c -o supper_v1[root@localhost ff]#
[root@localhost ff]# ./supper_v1 0 1TSC: 105888115381710120926.253354 - 1710120922.936056 = 3317.297852
(加这两个参数是为了对比NUMA下的表现)
共使用了10,588,811,538周期,四舍五入,105.89亿个周期。3317.3毫秒。
可以换-O2编译试试,我试的结果差
不多。毕竟主体部分已经是内嵌汇编了,编译器优化空间不多。
好,下面glibc memcpy上场。
[root@localhost ff]# gcc -g memcpy1.c -o memcpy_g1[root@localhost ff]#
[root@localhost ff]# ./memcpy_g1 0 1TSC: 79727266751710121954.748895 - 1710121952.251174 = 2497.720947
// 32字节倍数memcpyvoid vage_memcpy(void *dest, void *src, unsigned int size){__asm__ __volatile__("mov %1, %%rbx\n\t" // dest值传入rbx"mov %2, %%rcx\n\t" // src传入rcx"VAGE_LOOP:\n\t" // 循环开始"mov (%%rbx), %%r8\n\t" // load 源地址数据到 r8"mov 8(%%rbx), %%r9\n\t" // load 源地址数据到 r8"mov 16(%%rbx), %%r10\n\t" // load 源地址数据到 r8"mov 24(%%rbx), %%r11\n\t" // load 源地址数据到 r8"mov %%r8, (%%rcx)\n\t" // r8 store 到目标地址"mov %%r9, 8(%%rcx)\n\t" // r8 store 到目标地址"mov %%r10, 16(%%rcx)\n\t" // r8 store 到目标地址"mov %%r11, 24(%%rcx)\n\t" // r8 store 到目标地址"add $32, %%rbx\n\t" // 源地址向后加8字节"add $32, %%rcx\n\t" // 目标地址向后加8字节"sub $32, %0\n\t" // size 减8字节"jne VAGE_LOOP\n\t" // size 不为0向上跳转至循环开始处:"=r"(size):"r"(dest),"r"(src),"0"(size):"rbx","rcx","r8","r9","r10","r11");return ;}
[root@localhost ff]# gcc -g memcpy1.c -o supper_v2[root@localhost ff]#
[root@localhost ff]# ./supper_v2 0 1TSC: 80101093581710122778.736003 - 1710122776.226570 = 2509.433105
这台机器的CPU是skylake-client微架构。在另一台致强服务器版CPU上(skylake-server),测得结果如下:
supper v1:4753毫秒
三:SIMD矢量化的加速度
前文已经说过,既然软件预取不会在这个场景下取得更好的效果。第三版的supper memcpy就只能上SIMD了。
// 32字节倍数memcpyvoid vage_memcpy(void *dest, void *src, unsigned int size){__asm__ __volatile__("mov %1, %%rbx\n\t" // dest值传入rbx"mov %2, %%rcx\n\t" // src传入rcx"VAGE_LOOP:\n\t" // 循环开始"vmovdqa (%%rbx), %%ymm0\n\t" // load 源地址数据到 矢量寄存器ymm0"vmovdqa %%ymm0, (%%rcx)\n\t" // ymm0 store 到目标地址"add $32, %%rbx\n\t" // 源地址向后加32字节"add $32, %%rcx\n\t" // 目标地址向后加32字节"sub $32, %0\n\t" // size 减32字节"jne VAGE_LOOP\n\t" // size 不为0向上跳转至循环开始处:"=r"(size):"r"(dest),"r"(src),"0"(size):"rbx","rcx");return ;}
这里有一个新的限制,传入vage_memcpy的dest、src,不能跨CacheLine,它们得是32字节对齐的。这是vmovdqa指令的要求。
如果不想有对齐的限制,也可以换成vmovdqu指令,最后一个字母是u。SIMD指令集这些指令,名字起的真随意。
我这里仍使用对齐的vmovdqa指令,是因为在数据库中,对齐内存并没有那么困难、不可实现。
下面,看V3版的效果吧。
[root@localhost ff]# gcc -g memcpy1.c -o supper_v3[root@localhost ff]#
[root@localhost ff]# ./supper_v3 0 1TSC: 79875689451710124656.411502 - 1710124653.909130 = 2502.372070
glibc memcpy是2497.7毫秒,V3版supper memcpy是2502.4毫秒。几乎和glibc一样了,还是略慢一点点。
这里值得注意的是,V3版的SIMD,和循环展开的普通指令版(V2版),速度基本是一样的。V2版是2509.4毫秒。
这说明从内存吞吐上说,普通指令也能高效的利用带宽。不一定非要上SIMD。
但是,还没到下结论的时候。SIMD版V3,如果也循环展开一下呢!吞吐量会不会更高?
// 128字节倍数memcpyvoid vage_memcpy(void *dest, void *src, unsigned int size){__asm__ __volatile__("mov %1, %%rbx\n\t" // dest值传入rbx"mov %2, %%rcx\n\t" // src传入rcx"VAGE_LOOP:\n\t" // 循环开始"vmovdqa (%%rbx), %%ymm0\n\t" // load 源地址数据到 矢量寄存器ymm0"vmovdqa 32(%%rbx), %%ymm1\n\t""vmovdqa 64(%%rbx), %%ymm2\n\t""vmovdqa 96(%%rbx), %%ymm3\n\t""vmovdqa %%ymm0, (%%rcx)\n\t" // ymm0 store 到目标地址"vmovdqa %%ymm1, 32(%%rcx)\n\t""vmovdqa %%ymm2, 64(%%rcx)\n\t""vmovdqa %%ymm3, 96(%%rcx)\n\t""add $128, %%rbx\n\t" // 源地址向后加32字节"add $128, %%rcx\n\t" // 目标地址向后加32字节"sub $128, %0\n\t" // size 减32字节"jne VAGE_LOOP\n\t" // size 不为0向上跳转至循环开始处:"=r"(size):"r"(dest),"r"(src),"0"(size):"rbx","rcx");return ;}
[root@localhost ff]# gcc -g memcpy1.c -o supper_v4[root@localhost ff]#
[root@localhost ff]# ./supper_v4 0 1TSC: 77819362621710125670.234367 - 1710125667.796416 = 2437.950928
四舍五入,2438毫秒。
这个速度,已经超过glibc memcpy了。glibc memcpy是2497.7毫秒。
其实多次测试后对比,两者基本上一样。
看来,glibc memcpy,其内部应该也是SIMD+循环展开。
不过这个循环展开+SIMD,比不循环展开也只不过提升了2%到3%的性能。这么一点点的提升,其实只是因为循环展开后,总的指令数量变少了。对于内存的吞吐量上,其实没一点帮助的。
本来拷贝8K,一次循环32字节,共256次循环。循环展开后,一次循环拷贝128字节,需64次循环。
拷贝相关的Load/Store指令并没有减少,但循环的判断、跳转,从256次减少到64次。
前面不是说了吗,条件跳转语句,对性能影响很大的。减少了四分之三的循环判断、跳转,性能提升2%到3%,这很正常。
但2%、3%的影响,似乎不能说”影响很大“啊。
这是因为这些循环判断、跳转都很有规律,分枝预测几乎不会失误,因此影响不大。如果是那种无规律的条件跳转,对性能的影响大到超乎想像。这个后面我单开系列再讲。
有个问题不知道你注意到没,为什么SIMD+循环展开不能提升内存吞吐量了?
很简单,因为我测试的这几款CPU,L1的吞吐,就是每周期32字节。
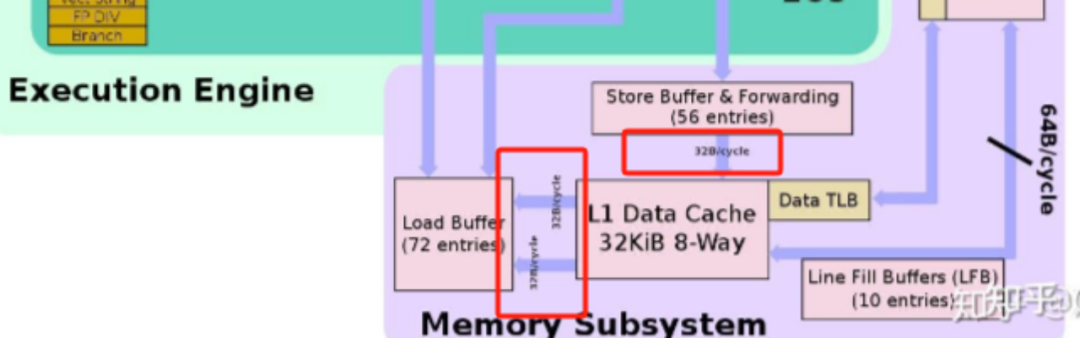
这是Intel Skylake微架构图,网上有高清无码的,自己找吧。
从我这个普清版中,也能看到,L1D Cache的读、写,每周期就是32B。
V3版的supper memcpy,SIMD,无循环展开,循环中指令也不多,基本上每次循环都能执行一条Load和Store。带宽已经被占满了,循环展开也不会提升性能了。
但我们看V1版的supper memcpy:
"VAGE_LOOP:\n\t" // 循环开始A "mov (%%rbx), %%r8\n\t" // load 源地址数据到 r8B "mov %%r8, (%%rcx)\n\t" // r8 store 到目标地址C "add $8, %%rbx\n\t" // 源地址向后加8字节D "add $8, %%rcx\n\t" // 目标地址向后加8字节E "sub $8, %0\n\t" // size 减8字节F "jne VAGE_LOOP\n\t" // size 不为0向上跳转至循环开始处
由于B依赖A,第一周期,具备执行条件的指令只有A1、C1和EF1。
(D1可以被执行,加法部分可以完成,但加32的结果不会写入rcx寄存器)
第二周期,具备执行条件的是:A2、C2、EF2。
……
后面会有约一半的周期因为访存的延时而STALL,会让Load和Store在一周期内执行,这不是关键。关键是就算一次循环可以执行一条Load和一条Store,也只能拷贝8字节啊。离32字节的带宽上限,还有很大的差距。所以循环展开才有意义。
通过上面的描述,主要是说明这个循环展开,可是水很深。不懂别乱展,展了没用。想恰到好处的展,是挺体现功力的。
从V2版,普通指令的循环展开版开始,内存的吞吐量就已经到头了。
但一层层的循环,循环展开后一堆load/store指令,还可以优化。
五:glibc memcpy的大招
[root@localhost ff]# gcc -g memcpy1.c -o memcpy_g2 -O2[root@localhost ff]#
[root@localhost ff]# ./memcpy_g2 0 1TSC: 66783436481710126979.690625 - 1710126977.598423 = 2092.201904
从2400、2500毫秒,下降到2092.2毫秒。提速的原因,反汇编一下就能看到:
。。。。。。0x0000000000400c02 <+114>: add $0x2000,%ecx0x0000000000400c08 <+120>: shr $0x3,%ecx0x0000000000400c0b <+123>: cmp %rax,%r80x0000000000400c0e <+126>: rep movsq %ds:(%rsi),%es:(%rdi)0x0000000000400c11 <+129>: jne 0x400bd0 <work+64>0x0000000000400c13 <+131>: sub $0x1,%r9d0x0000000000400c17 <+135>: jne 0x400bc8 <work+56>
省去了函数调用的跳转,而且-O2对work函数中的两层循环也进行了优化,指令数进一步减少。最后的结果就是,效率果然更高了。
memcpy_g2版不应该算是glibc memcpy了吧。毕竟这已经不是glibc memcpy更快,而是gcc优化编译的结果。其实内存的吞吐量上,还是没啥提升的。
放在这里是为了给读者朋友提个醒,要提升性能、吞吐,可不只SIMD一条道。SIMD造成减速的情况也是不少的。当你不完全了解一个东东时,最好的方式就是不使用它。
也就是说,V2版的普通指令+循环展开,就已经达到了内存吞吐量的极限了。没想到这么早就达到人生巅峰了,V2版不知道有没有在唱:无敌是多少寂寞。
但是,终极BOSS要来了。
// 32字节倍数memcpyvoid vage_memcpy(void *dest, void *src, unsigned int size){__asm__ __volatile__("mov %1, %%rbx\n\t" // dest值传入rbx"mov %2, %%rcx\n\t" // src传入rcx"VAGE_LOOP:\n\t" // 循环开始"vmovdqa (%%rbx), %%ymm0\n\t" // load 源地址数据到 矢量寄存器ymm0"vmovntdq %%ymm0, (%%rcx)\n\t" // ymm0 store 到目标地址"add $32, %%rbx\n\t" // 源地址向后加32字节"add $32, %%rcx\n\t" // 目标地址向后加32字节"sub $32, %0\n\t" // size 减32字节"jne VAGE_LOOP\n\t" // size 不为0向上跳转至循环开始处:"=r"(size):"r"(dest),"r"(src),"0"(size):"rbx","rcx");return ;}
"vmovntdq %%ymm0, (%%rcx)\n\t" // ymm0 store 到目标地址
这里的指令vmovntdq,V3版使用的是vmovdqa,主要是多了个nt。“nt”是指non-temporal,非临时。我保证你通过这个“非临时”搞不清楚它是干啥的。
它的意义很简单,就是绕过L1、L2、L3 Cache。如果是nt store,就是从寄存器直接写入内存,不再一级级的先写到L1,再写到L2,再写到L3,再到Memory。“nt load”也是,绕过各级Cache,直接从内存到寄存器。
不过通常把这个称为nt hint,nt提示。就是告诉CPU我想用nt方式访存,但是否真正的绕过Cache,绕过那级Cache,CPU将视情况而定。
好了,指令介绍过了,看这个终极BOSS的效果吧。
[root@localhost ff]# gcc -g memcpy1.c -o supper_boss[root@localhost ff]#
[root@localhost ff]# ./supper_boss 0 1TSC: 53684156751710135751.451335 - 1710135749.769500 = 1681.834961
循环展开版超级BOSS可以再提升1%至2%的性能,提升效果有点鸡肋。但也不能说没效果。看情况选择吧。
另有一个注意事项,超级BOSS版本中,load指令并没使用nt load,仍是普通的load。只有Store使用了NT Store。因为在多个微架构平台测试中,nt load并没有提升性能,但nt store对于性能提升还是极有帮助的。
memcpy_g2版的memcpy,gcc的-O2把memcpy优化没了,换成了“rep movsq”指令。这个版本就不讨论了。memcpy_g1版,也就是glibc memcpy,成绩是2497.7毫秒。
超级BOSS版是1681.8毫秒,是glibc memcpy的67%,性能提升33%。也可以说,超级BOSS版的吞吐量,提升了33%。
还有一点,超级BOSS的源内存,使用了普通的Load,会进入Cache。但目标内存使用了nt store,不进入Cache。如果在随后马上访问目标内存的话,Cache一定是不命中的。
不过,既然是拷贝,源、目标是一样的,如果是随后马上访问内存,为什么不访问源呢。
总的来说,超级BOSS对于数据库的开发,还是十分有意义的,毕竟33%的性能提升,挺不错了。
NT Store还有一个问题,一致性。
对于核间的数据一致性,nt store和普通Store是一样的。
也就是说,如果你使用glibc memcpy前、后,加了mfence类屏障指令,在超级BOSS版memcpy前或后也要加屏障指令。如果glibc memcpy没加,超级BOSS也不需要加。
如果不跨核,下面情况下会不会有问题:
Mem_1在L1/L2/L3 Cache中,对mem_1进行nt Store。由于绕过Cache,数据直接写入内存。然后发起读mem_1操作,因为它本来在Cache中,此时会不会到Cache中读旧的数据?
答案是:不会。NT Store会让对应层级Cache中的mem_1失效的。
关于NT Store对核间和同核一致性的影响,我们设计了一个精巧的测试程序进行验证,后面再写一篇分享给大家。

