




春节假期结束,开工。
《数据库传奇:被忽略的历史》第一部,科德与巴赫曼双雄传奇,已经接近尾声,读故事比读技术文章有意思多了吧,角度够新颖吧。但读读技术文章,还是少不了的。
《数据库传奇:被忽略的历史》第五集,马上推出,创作不易,关注、点赞、分享,是对IT知识刺客最大的鼓励。
正文开始。
这篇文章,本是为了回答一个和“无锁”相关问题:
https://www.zhihu.com/question/374142552/answer/3401692614
正好前面写了三篇《基础软件开发新坑 -- 神秘的MESI和坑爹的LockFree》,用这个回答,做为“神秘的MESI和坑爹的LockFree”最终章吧。
图1
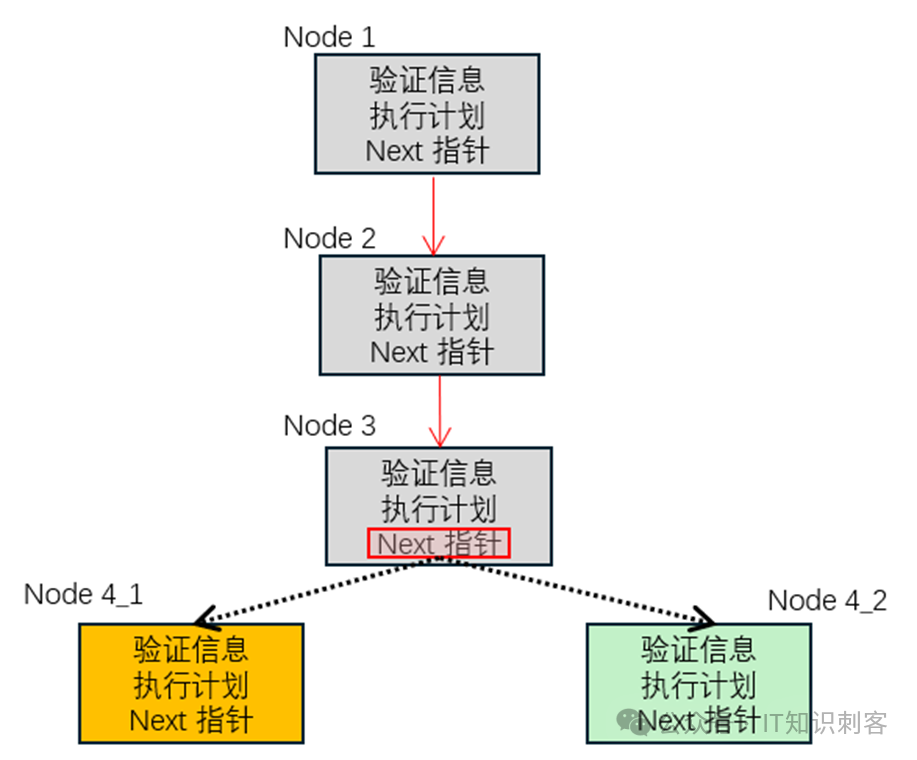
如图2,现在两个进/线程同时在Node 3后增加一个新节点,就算在保证Node 3的“Next指针“不跨CacheLine,写”Next指针“是原子的,不会出现我写了前4个字节,你写了后4个字节这种情况。
但如果没有锁保护,很有可能Node 4_1成功修改了Node 3的Next指针,认为自己已经加入链表。但马上Node 4_2也成功修改了Node 3,把自己加入链表。就如图2中情况。
Node 4_1、Node 4_2,都认为自己在Node 3后面,但只有一个人是真的在Node 3后面。这就会出现问题。
读、写明明都是原子的,为什么这里会出现问题?
因为这里不是原不原子的问题,这里的问题是”同步“。
两个进/线程在两个核上同时发起对Node
3中“Next指针”的写操作,这个写操作是原子的,不会出现一个人写了前一半、另一个人写后一半。
但是,当进/线程2修改Node 3中“Next指针”时,它并不知道进/线程1刚刚完成了Node 3中“Next指针”的修改。你刚修改了,但我还不知道,以为你没修改,这就是“同步”问题。
其实原子问题,本质上也是同步。一个Core写L1 的CacheLine时,为了保证对应的内存不会出现写了前一半,后一半被另外Core写了,Core间也是需要同步的。
但这个“同步”被优化了,MESI协议就是用来优化这个同步的,不会每次读、写都同步,只要必要的时候同步。
MESI这块,这里不展开了,我之前写过一个系列专门讲这个,《基础软件开发新坑 -- 神秘的MESI和坑爹的LockFree》,有兴趣到这里看吧:
https://mp.weixin.qq.com/s/bt2YVej-vXTHPA1Nfi_mHw
https://mp.weixin.qq.com/s/Rf5A8n60PSYnQ6uRE3lhfw
https://mp.weixin.qq.com/s/3HcsiQp6-4pCOSUKfWCqEw
还有一个系列,也和这个问题相关,《HPC(高性能计算第一篇):一文彻底搞懂并发编程与内存屏障》:
https://mp.weixin.qq.com/s/FOmUP9YcMORpPxqrz_Ravw
https://mp.weixin.qq.com/s/lKRzDjjBmXKlGKtzZQb2HA
https://mp.weixin.qq.com/s/vZDZGv1n6Ihz3A5sv7coZA
考虑到大家的时间都比较紧,我简单的、不太严谨的,结合这个问题说一下上面几篇文章的结论。
这里我们还把MESI保证的一致性,称为原子性。
继续说原子和同步。原子性无法保证图2这种情况,两个进/线程同时修改Node 3中的“Next指针”,在原子性的保证下,它们的修改一先、一后,都成功完成了,但后完成的覆盖了先完成的修改。
这里的关键就是,“后完成的覆盖了先完成的修改”。如何让“后完成的”在修改时,能感知到Node 3的Next指针已经被修改了?
CPU专门提供了一个指令,比如x64中有一个可以加LOCK前缀的“比较并交换”指令:
LOCK cmpxchg reg, (mem)
(关于LOCK前缀的作用、延迟的测量、对程序的影响,《基础软件开发新坑 -- 神秘的MESI和坑爹的LockFree》1至3篇有详细分析)
假设原来的链表尾:Node 3,其Next指针为0。
多个进/线程同时使用带有LOCK前缀的比较并交换,CPU内部的具体步骤如下:
1) 比较Next指针是否为0。
2) 如为0,将Next指针修改为指向Node 4_1,返回成功。
3) 如不为0,不做任何修改,返回失败。
(返回成功、失败是如何体现的,可以查查cmpxchg指令,太细节的就不在这里讲了,后面再写文章描述)
也就是说,带LOCK前缀的比较并交换,可以在修改指定内存前,感知到该内存是否已经被修改。比较Next指针是否为0,就是感知是否已经被修改的过程。
使用它,就可以完美解决问题。如下图:
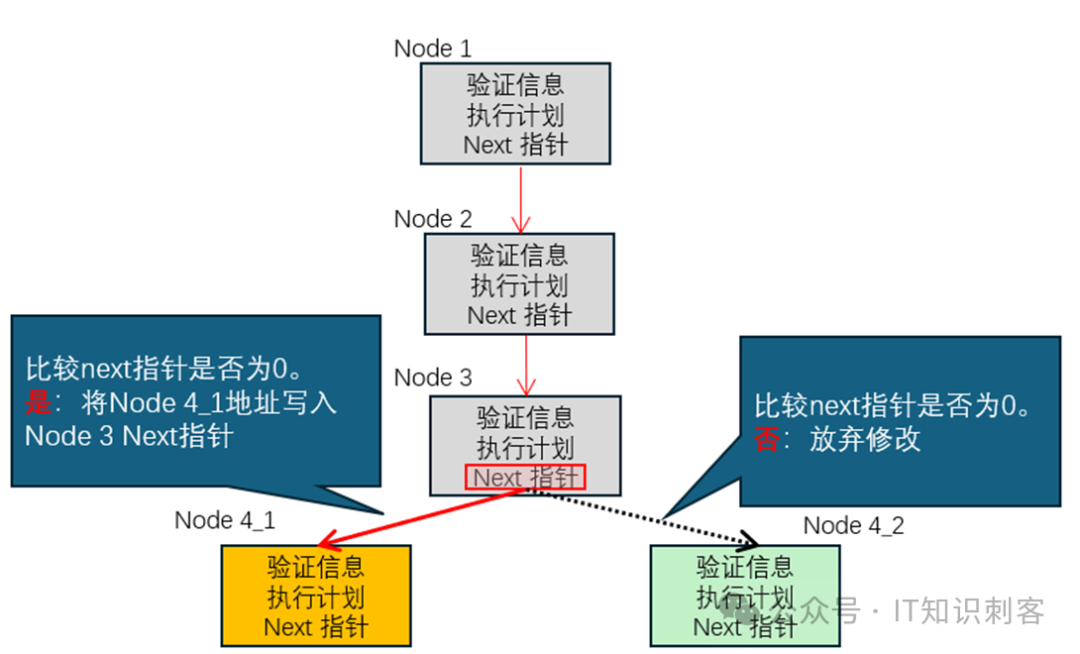 图3
图3
图4
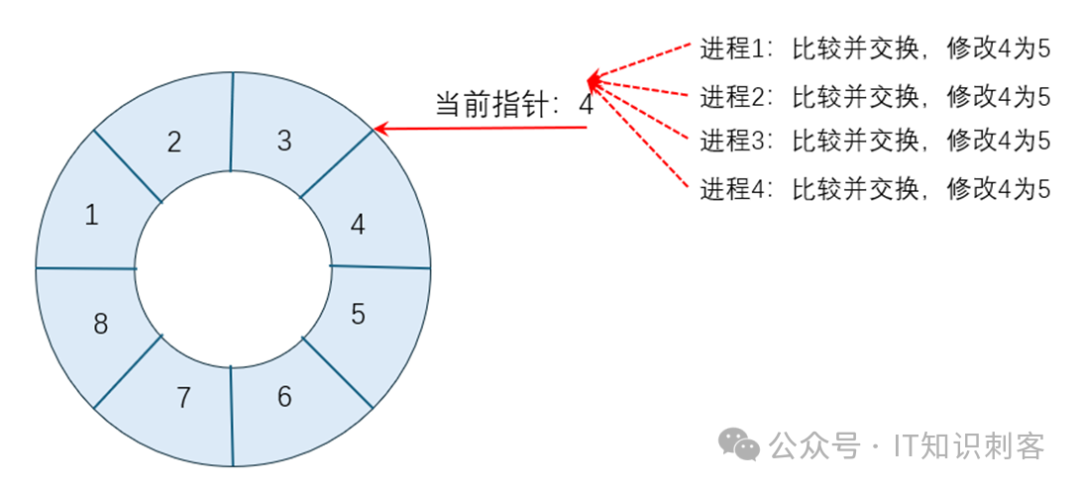
图5
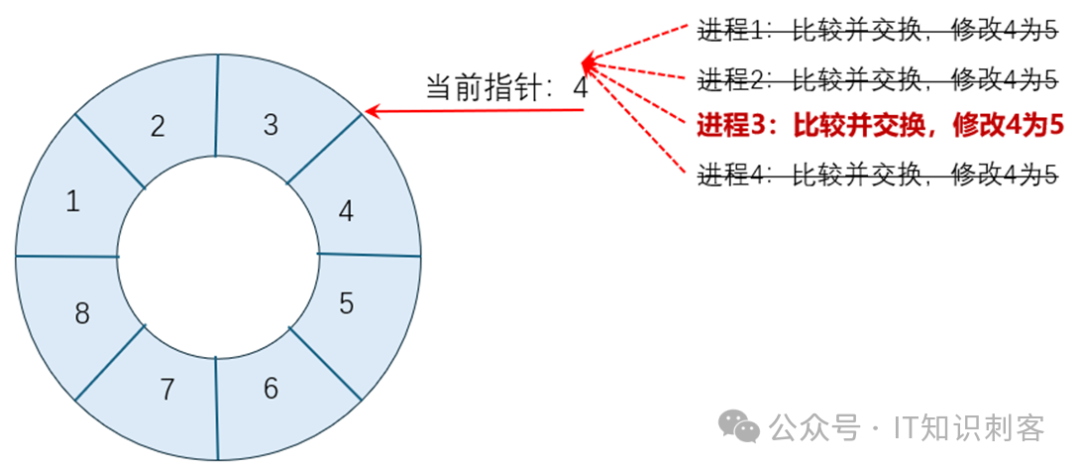
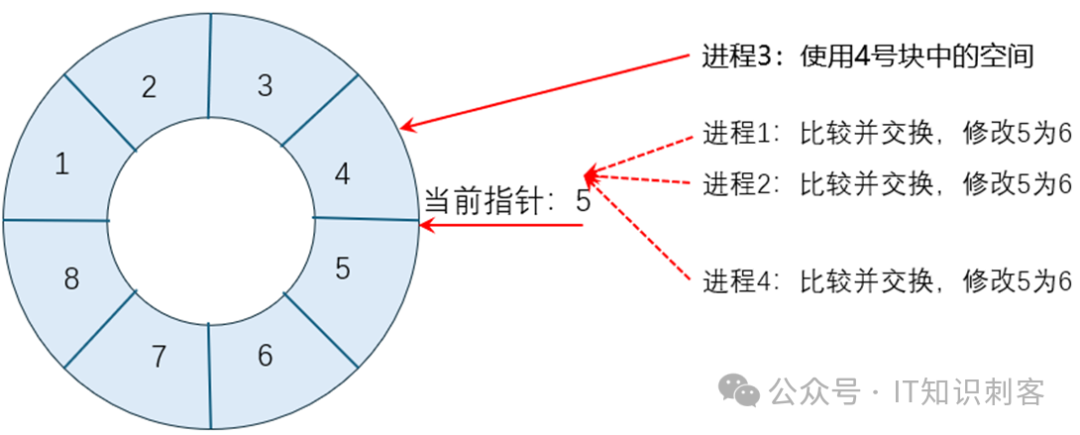
图7
其他三个进程继续抢着修改5为6。进程3开始使用4号块中的空间。
除了环状无锁,还有其他玩法,本质都是使用LOCK cmpxchg,在能感知到其他Core是否修改了目标内存情况下,完成目标内存的修改。
LOCK cmpxchg一次修改的内存,最多只能是8个字节,64个二进制位。
它的使用也十分有限,如果想并发的读、写超过64位,使用一条LOCK cmpxchg指令,无法保证一致性。
CPU一次读、写只能是64位(8字节),读、写超过8字节数据时,一定是多条指令,CPU不保证多条指令的原子性、一致性。这个时候,还是要使用“锁“。
锁的实现,也是通过LOCK cmpxchg。这里就不详细说了。
最后再强调一下,无锁也是要LOCK cmpxchg的(也有可能使用带LOCK前缀的其他指令),LOCK前缀的延迟很高,并不是使用了无锁,一切万事大吉,就低延迟、高性能了。
