




关注+星标,干货第一时间送达

诸位,好久不见,甚是想念啊!
上周小编就来北京出差了,
在这边可能要待个把月,
真难顶!!
虽说这边的天气,干燥凉爽,
要比深圳的潮湿闷热好的不少,
但还是想家,想早点回去。
可能年纪大了,恋家了?
今天,咱们一起看个"登录问题"
这类问题吧,很常见!
在前面的文章,
小编演示了很多这样的题型。
不过,今天的题,
多了个 "间断",
有意思!
【温馨提示:建表语句及数据导入脚本,已经放在文章末尾】
一、需求场景
题目:
现有用户登录记录表login_events,要求统计各个用户最长的连续登录天数,间断一天也算作连续。
例如,一个用户在1,3,5,6 登录,则视为连续6天登录。
用户登录记录表login_events:
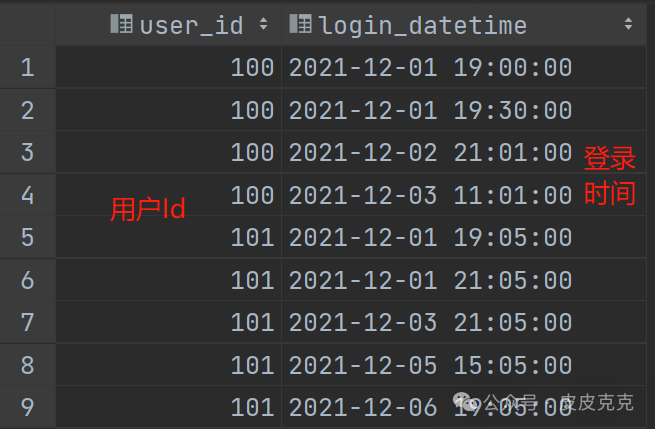
正确结果:
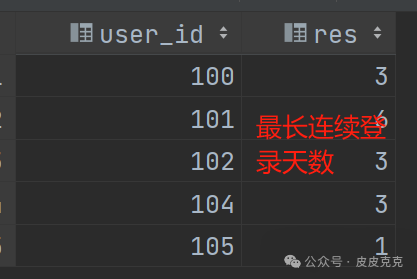
二、解决方案
演示工具:Hive-3.1.3 + DataGrip2022
如果只是 "连续登录",
那非常好办,
利用 "开窗排序",再计算个差值,
就可以了。
例如前面的文章:
皆如此。
但是,题目中 "间断一天也算作连续登录",
怎么办呢?
我们可以通过计算每次登录,
和其上次登录日期的差值,
对于差值超过2的,既认为不是连续登录了。
将这些连续登录的数据,
打标签,
利用标签分组,最后就可以计算最大连续登录天数了。
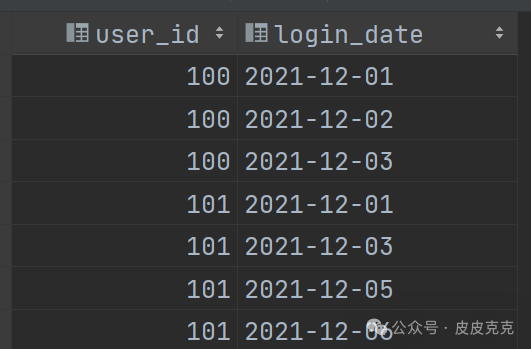
(1)按照user_id,登录日期分组,去重
select user_id,
date(login_datetime) as login_date
from login_events
group by user_id, date(login_datetime)
结果集:
(2)利用 lag() 函数,获取每次登录的前一次登录日期
select user_id, login_date,
lag(login_date,1,'1970-01-01') over (partition by user_id order by login_date) as last_login_date
from (
select user_id,
date(login_datetime) as login_date
from login_events
group by user_id, date(login_datetime)
)t1
结果集:
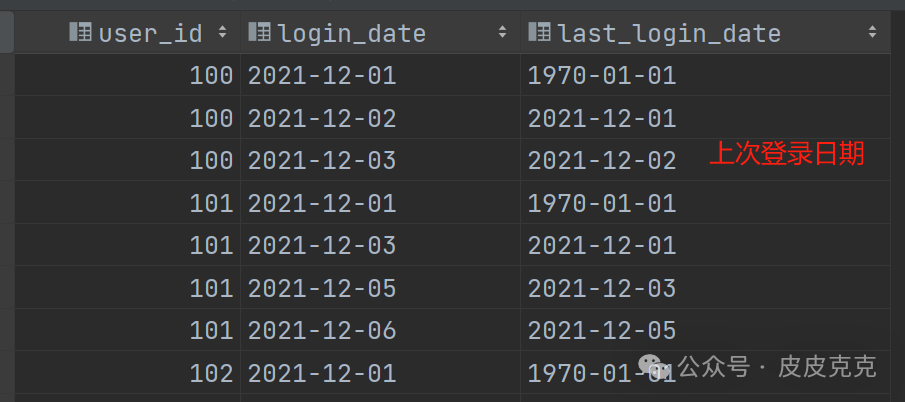
代码里面的:1970-01-01 主要是替换可能存在的null值。
另外,关于 lag() 函数:
语法格式:
LAG(column, offset[, default]) OVER ([PARTITION BY partition_expression, ...] ORDER BY sort_expression [ASC|DESC], ...)
参数:
column:指定要计算的列。offset:指定要向前查找多少行。
offset 的默认值为 1。
default:当偏移量超过可用行数时,指定要返回的默认值。默认值为 NULL。
PARTITION BY:可选项,用于按照指定的表达式进行分区。
ORDER BY:必须指定,用于根据指定的表达式排序。
这个不难理解吧?
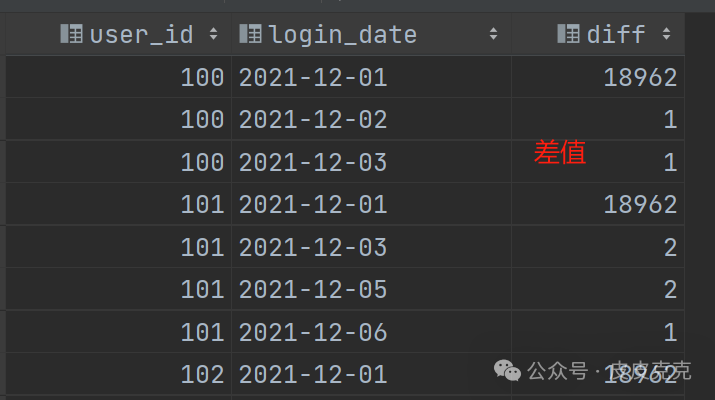
(3)计算每次登录日期,和上次登录日期的差值
select user_id,login_date,
datediff(login_date, last_login_date) as diff
from (
select user_id, login_date,
lag(login_date,1,'1970-01-01') over (partition by user_id order by login_date) as last_login_date
from (
select user_id,
date(login_datetime) as login_date
from login_events
group by user_id, date(login_datetime)
)t1
)t2
结果集:
(4)对差值diff,进行筛选,大于2的标记为1,其他标记为0
select user_id,login_date,
diff,
sum(`if`(diff>2,1,0)) over (partition by user_id order by login_date) as flag
from (
select user_id,login_date,
datediff(login_date, last_login_date) as diff
from (
select user_id, login_date,
lag(login_date,1,'1970-01-01') over (partition by user_id order by login_date) as last_login_date
from (
select user_id,
date(login_datetime) as login_date
from login_events
group by user_id, date(login_datetime)
)t1
)t2
)t3
结果集:
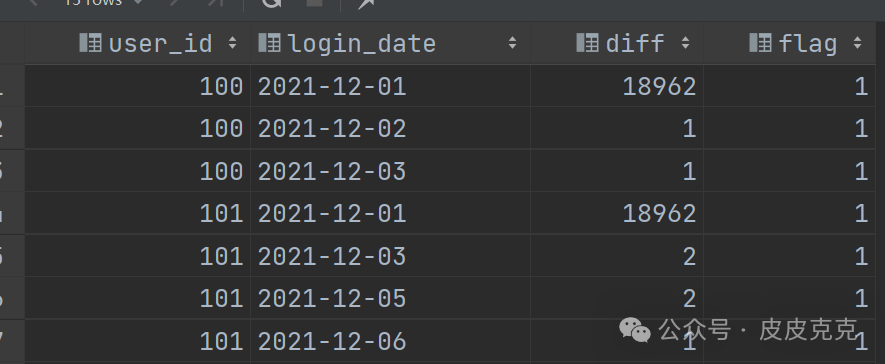
这里解释一下,
因为有:
`if`(diff>2,1,0)
作为标记,
如果有连续的天数,值统统都会标记为0,
然后搭配:
sum(`if`(diff>2,1,0)) over (partition by user_id order by login_date)
连续的登录,都会得出相同值:1
(5)利用标签分组统计,会得出连续登录的区间,计算起始和结束的差值
select user_id,
datediff(max(login_date), min(login_date)) + 1 as dt_mark
from (
select user_id,login_date,
concat(user_id,'_',flag) as mark
from (
select user_id,login_date,
diff,
sum(`if`(diff>2,1,0)) over (partition by user_id order by login_date) as flag
from (
select user_id,login_date,
datediff(login_date, last_login_date) as diff
from (
select user_id, login_date,
lag(login_date,1,'1970-01-01') over (partition by user_id order by login_date) as last_login_date
from (
select user_id,
date(login_datetime) as login_date
from login_events
group by user_id, date(login_datetime)
)t1
)t2
)t3
)t4
)t5
group by user_id,mark
结果集:
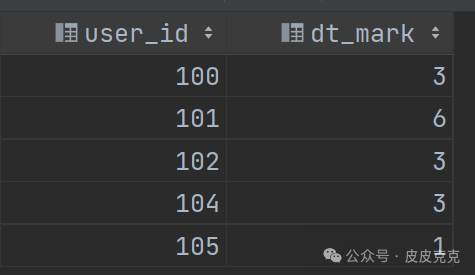
代码中的:
concat(user_id,'_',flag) as mark
就是打标签,方便后面的分组。
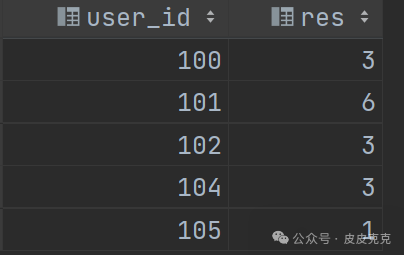
(6)对于可能用户存在多个连续区间,再多一层分组取max
select user_id,
max(dt_mark) as res
from (
select user_id,
datediff(max(login_date), min(login_date)) + 1 as dt_mark
from (
select user_id,login_date,
concat(user_id,'_',flag) as mark
from (
select user_id,login_date,
diff,
sum(`if`(diff>2,1,0)) over (partition by user_id order by login_date) as flag
from (
select user_id,login_date,
datediff(login_date, last_login_date) as diff
from (
select user_id, login_date,
lag(login_date,1,'1970-01-01') over (partition by user_id order by login_date) as last_login_date
from (
select user_id,
date(login_datetime) as login_date
from login_events
group by user_id, date(login_datetime)
)t1
)t2
)t3
)t4
)t5
group by user_id,mark
)t6
group by user_id
结果集:
三、源数据
用户登录记录表login_events:
create table login_events
(
user_id int comment '用户id',
login_datetime string comment '登录时间'
)
row format serde 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
stored as
inputformat 'org.apache.hadoop.mapred.TextInputFormat'
outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
location 'hdfs://mycluster/user/hive/warehouse/hql_test2.db/login_events'
tblproperties ('bucketing_version' = '2');
alter table login_events
set tblproperties ('comment' = '直播间访问记录');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (100, '2021-12-01 19:00:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (100, '2021-12-01 19:30:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (100, '2021-12-02 21:01:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (100, '2021-12-03 11:01:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (101, '2021-12-01 19:05:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (101, '2021-12-01 21:05:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (101, '2021-12-03 21:05:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (101, '2021-12-05 15:05:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (101, '2021-12-06 19:05:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (102, '2021-12-01 19:55:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (102, '2021-12-01 21:05:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (102, '2021-12-02 21:57:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (102, '2021-12-03 19:10:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (104, '2021-12-04 21:57:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (104, '2021-12-02 22:57:00');
INSERT INTO hql_test2.login_events (user_id, login_datetime) VALUES (105, '2021-12-01 10:01:00');
OK,这就是本期的内容了,下期再见!
