




点击关注公众号,干货第一时间送达

看了好几篇干货了吧
该耍耍了!
不然学了跟没学一个样。
这篇文章,来演示大数据开发中的经典案例:wordcount。
话不多说,Let go!
一、MapReduce 编程规范
1,mapreduce常用数据类型:
| Java类型 | Hadoop Wriable类型 |
|---|---|
| Boolean | BooleanWritable |
| Byte | ByteWritable |
| Int | IntWritable |
| Float | FloatWritable |
| Long | LongWritable |
| Double | DoubleWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
2,Map阶段
(1)用户自定义的Mapper要继承自己的父类。
(2)Mapper的输入数据是KV对的形式。
(3)Mapper中的业务逻辑写在map()方法中。
(4)Mapper的输出数据是KV对的形式。
(5)map()方法(MapTask进程)对每一个<K,V>调用一次
3,Reduce阶段
(1)用户自定义的Reducer要继承自己的父类。
(2)Reducer的输入数据类型对于Mapper的输出数据类型,也是KV。
(3)Reducer中的业务逻辑写在reducer()方法中。
(4)ReduceTask进程对每组相同k的<K,V>组调用一次reduce()方法。
4,Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象。
按照上述规范,开始编写 wordcount 案例代码。
二、wordcount 案例编写
需求分解:

1,创建IDEA工程,引入依赖,引入日志
(友情提示 :小编在之前的文章:Hadoop 系列(十)HDFS_API 操作,演示过HDFS_API,里面有详细介绍过IDEA如何搭建hadoop工程,需要的小伙伴可以点击翻看一下,这里不再赘述)
:小编在之前的文章:Hadoop 系列(十)HDFS_API 操作,演示过HDFS_API,里面有详细介绍过IDEA如何搭建hadoop工程,需要的小伙伴可以点击翻看一下,这里不再赘述)
2,Mapper代码编写
public class WordcountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
//定义map阶段输出数据key
private Text outK = new Text();
//定义map阶段输出数据value
private IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1,获取一行数据
String line = value.toString();
//2,切割
String[] words = line.split(" ");
//3,遍历
for (String word : words) {
//4,设置输出key
outK.set(word);
//5,把输出数据kv写入上下文环境
context.write(outK,outV);
}
}
}
3,Reducer代码编写
public class WordcountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
//定义reduce阶段输出数据value
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
//1,遍历map阶段传过来的相同key的数据值,进行累加
// (1,1)
for (IntWritable value : values) {
sum += value.get();
}
//2,设置最终输出数据value
outV.set(sum);
//3,写入上下文环境
context.write(key,outV);
}
}
4,Driver代码编写
public class WordcountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1,获取Job(如果我们采用本地模式,可以不用配置hadoop集群地址)
Configuration conf = new Configuration();
Job job = Job.getInstance();
//2,设置jar包路径
job.setJarByClass(WordcountDriver.class);
//3,管理Mapper和Reducer
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//4,设置map输出类型KV
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5,设置最终输出数据类型KV
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6,设置输入路径和输出路径
FileInputFormat.setInputPaths(job,new Path("D:\\hadoop\\mapreduce\\input"));
//输出路径不能存在,否则会报异常
FileOutputFormat.setOutputPath(job,new Path("D:\\hadoop\\mapreduce\\output"));
//7,提交
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
5,数据准备
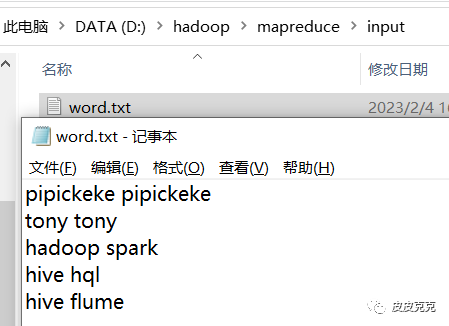
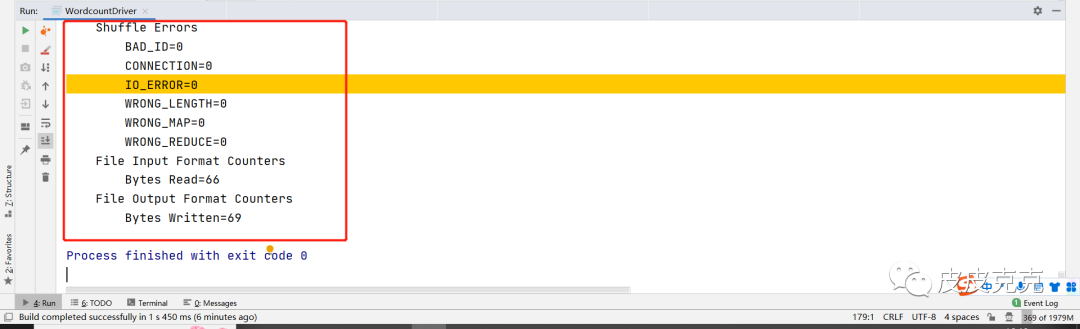
6,测试
执行 driver 里面的 main()方法:控制台日志打印正常
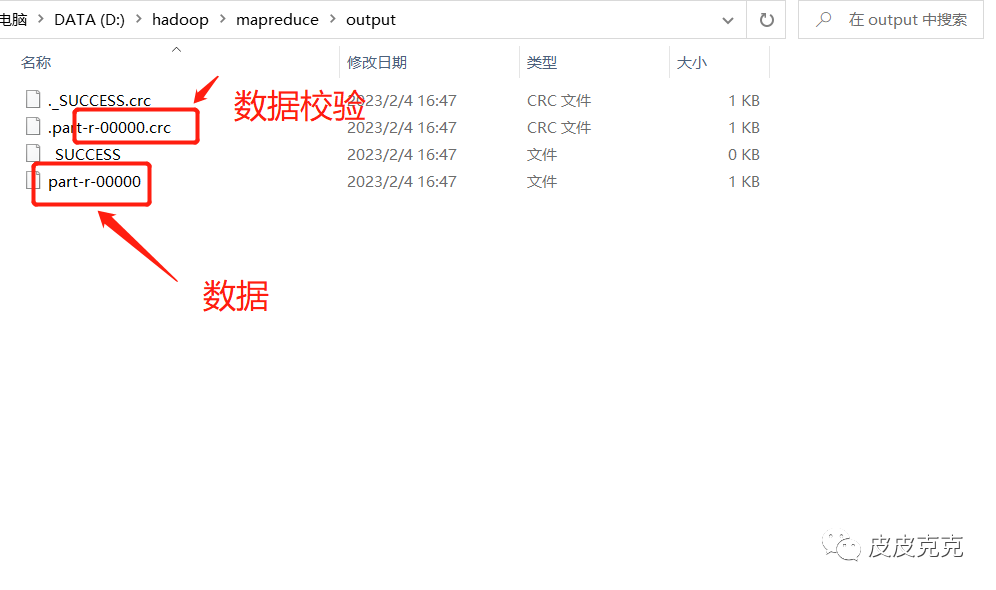
查看输出路径:生成 output文件夹,里面有生成的crc校验码+数据
查看输出数据:
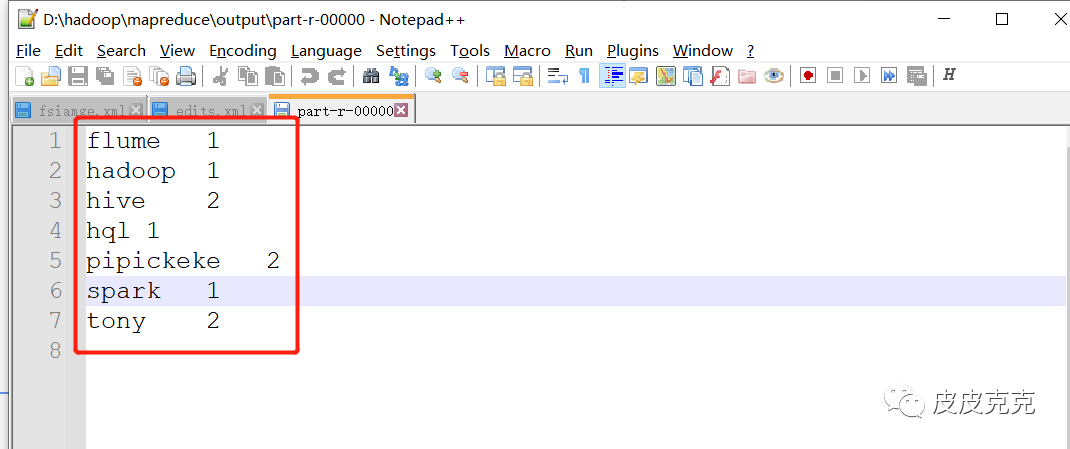
是正确计算的结果

